语义分割CVPR2019-ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation
ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation基于对抗熵最小化的语义分割领域适应方法
- 0.摘要
- 1.概述
- 2.相关工作
- 3.方法
-
- 3.1.直接熵最小化
- 3.2.利用对抗学习最小化熵
- 3.3. 联合使用类别占比率的先验知识
- 4.实验
-
- 4.1.实验细节
- 4.2.结果
- 4.3.讨论
- 5.结论
- 参考文献
论文地址
代码下载
0.摘要
语义分割是许多计算机视觉任务的关键问题。虽然基于卷积神经网络的方法在不同的基准上不断打破新记录,但将其推广到不同的测试环境仍然是一个重大挑战。在许多实际应用中,训练域和测试域中的数据分布之间确实存在很大的差距,这会导致运行时的严重性能损失。在这项工作中,我们解决了基于像素预测熵的有损失语义分割中的无监督域自适应任务。为此,我们提出了两种新的互补方法,分别使用(i)熵损失和(ii)对抗性损失。我们在两个具有挑战性的“合成–>真实”上演示了语义分割的最新性能,并表明该方法也可用于检测。
1.概述
语义分割是为图像中的所有像素分配类标签的任务。在实践中,分割模型通常是复杂的计算机视觉系统(如自动驾驶汽车)的支柱,这些系统在各种各样的城市环境中都要求很高的精度。例如,在恶劣天气下,系统必须能够识别道路、车道、侧边或行人,尽管他们的外观与训练集中的人大不相同。一个更为极端和重要的例子是所谓的“合成–>真实”设置[31,30]——训练样本是由游戏引擎合成的,测试样本是真实场景。目前的全监督方法[23,47,2]还不能保证对任意测试用例有很好的泛化。因此,在一个称为源的域上训练的模型,在另一个称为目标的域上应用时,通常会经历性能的急剧下降。
无监督域适应(Unsupervised domain adaptive, UDA)是一个研究领域,其目的是仅仅从源监督中学习目标样本上性能良好的模型。在最近的UDA方法中,许多方法通过减少跨域差异来解决这个问题,并在源域上进行有监督的训练。它们通过分别最小化源数据和目标数据的中间特征分布或最终输出的差异来接近UDA。使用最大平均差异(MMD)或对抗训练(10,42)可在单个[15,32,44]或多个水平[24,25]进行。其他方法包括自我训练[51]提供伪标签或生成网络来生成目标数据[14,34,43]。
半监督学习解决了一个密切相关的问题,即从只有一个子集的数据中学习。因此,它启发了UDA的几种方法,例如,自我训练,生成模型或职业平衡[49]。熵最小化也是半监督学习[38]的成功方法之一。
在本工作中,我们将熵最小化原则应用于UDA任务的语义分割。我们从一个简单的观察开始:只在源域上训练的模型往往产生过度自信,即低熵,而对于和源图像类似数据的预测则表现出不自信,即高熵,对类目标图像的预测。这种现象如图1所示。从源域得到的场景预测熵映射看起来就像在高熵激活的情况下沿目标边界的边缘检测结果。另一方面,对目标图像的预测是不确定的,导致非常嘈杂的高熵输出。我们认为,一种可能的方法是通过加强目标预测的高预测确定性(低熵)来弥合源和目标之间的领域差距。为此,我们提出了两种方法:使用熵损失的直接熵最小化和使用对抗熵损失的间接熵最小化。第一种方法对独立像素预测施加了低熵约束,而后者的目标是根据加权自信息对源和目标分布进行全局匹配我们的贡献总结如下:
- 对于语义分割UDA,我们提出利用熵损失来直接惩罚目标域的低自信预测。这种熵损失的使用不会给现有的语义分割框架增加显著的开销。
- 提出了一种新的基于熵的对抗训练方法,该方法不仅以熵最小化为目标,而且以源域到目标域的结构自适应为目标。
- 为了进一步提高在特定设置下的表现,我们提出两个额外的实验:(i)训练特定的熵范围和(ii)纳入类比先验。我们讨论了在实验和消融研究中的实际见解。
熵最小化目标将模型的决策边界推向预测空间中目标域分布的低密度区域。这样可以得到“更干净”的语义分割输出,更精细的对象边缘和更大的模糊图像区域被正确地恢复,如图1所示。本文提出的模型在几个UDA基准上的语义分割效果优于目前最先进的方法,特别是两个主要的合成–>真实基准,GTA5→Cityscapes和SYNTHIA→Cityscapes。
2.相关工作
无监督领域自适应是分类和检测领域研究的热点,近年来语义分割技术也取得了一些进展。领域适应性的一个非常吸引人的应用是在现实世界的任务中使用合成数据。这鼓励了几个具有相关数据集的合成场景项目的发展,如Carla [8], SYNTHIA[31]等[35,30]。
UDA的主要方法包括源目标特征分布差异最小化[10,24,15,25,42]、伪标签[51]自训练和生成方法[14,34,43]。在本工作中,我们特别感兴趣的是用于语义分割的UDA。因此,我们在这里只回顾了用于语义分割的UDA方法(更一般的文献综述见[7])。
针对UDA的对抗训练是目前研究最多的语义分割方法。它涉及两个网络。一个网络预测输入图像的分割映射,它可以来自源域或目标域,而另一个网络作为一个鉴别器,它从分割网络中提取特征映射,并试图预测输入的域。分割网络试图欺骗鉴别器,从而使来自两个域的特征具有相似的分布。Hoffman等人[15]是第一个将对抗方法应用于UDA语义分割的人。通过从源域传输标签统计信息,它们还具有特定于类别的适应性。[5]中使用了一种类似的全局和类的对齐方法,类的对齐是通过对网格的软伪标签进行对抗训练完成的。在[4]中,对抗训练用于空间感知适应以及蒸馏损失,以专门解决合成–>实域迁移。[16]使用残差网使源特征映射与目标的特征映射相似,然后将该特征映射用于分割任务。在[41]中,在输出空间上使用对抗方法,以便从跨域的结构一致性中获益。[32,33]提出了另一种使用对抗训练的有趣方法:他们对目标域图像进行两次预测,这是由两个分类器[33]完成的,或者在分类器[32]中使用dropout。考虑到这两种预测,训练分类器使分布之间的差异最大化,而训练网络的特征提取器部分使分布之间的差异最小化。
一些方法建立在生成网络的基础上,以源为条件生成目标图像。Hoffman等人提出了循环一致对抗领域适应(CyCADA),其中它们在像素级和特征级表示上都进行了适应。对于像素级的自适应,他们使用Cycle-GAN[48]根据源图像生成目标图像。在[34]中,学习生成模型,从特征空间重建图像。然后,对于域自适应,通过训练特征模块根据源特征生成目标图像,反之亦然。在DCAN[43]中,在发生器和分割网络中使用了通道的特征对齐。分割网络是在生成的带有源内容和目标风格的图像上学习的,源分割图作为目标的groundtruth。[50]的作者使用生成对抗网络(GAN)[11]来对齐源和目标嵌入。此外,它们还用一种保守的损失(CL)取代了交叉熵损失,这种损失惩罚了源例子中容易和困难的情况。CL方法正交于大多数UDA方法,包括我们的:它可以使任何使用交叉熵作为源的方法受益。
UDA的另一种方法是自我训练。其思想是使用集成模型的预测或模型的前一状态作为伪标签的数据,以训练当前的模型。许多半监督方法[20,39]使用自我训练。在[51]中,UDA采用自训练的方法进行语义分割,并在类平衡和空间优先的基础上进一步扩展。自我训练与我们在3.1节中讨论的熵最小化方法有一个有趣的联系。
在其他一些方法中,[26]通过多重损失使用对抗和生成技术的结合,[46]结合生成方法进行外观适应和对抗训练进行表征适应,[45]通过加强局部(超像素级)和全球标签分布的一致性,为UDA提出了一种课程式的学习。
熵最小化已经被证明对半监督学习[12,38]和聚类[17,18]是有用的。该方法最近也被用于分类任务[25]的领域自适应。据我们所知,我们是第一个成功地将基于熵的UDA训练应用于语义分割任务的竞争性能。
3.方法
在本节中,我们介绍了我们提出的两种熵最小化方法,使用(i)无监督熵损失和(ii)对抗训练。为了构建我们的模型,我们从现有的语义分割框架开始,并添加一个额外的用于领域适应的网络分支。图2说明了我们的体系结构。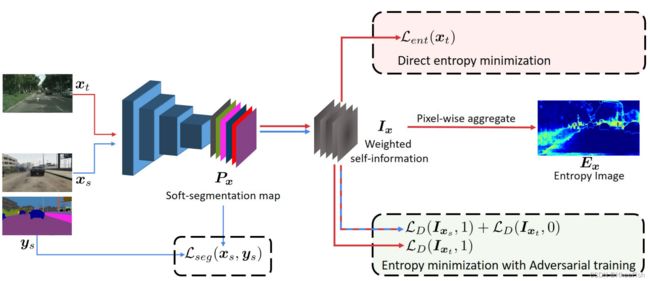
图2:方法概述。图中显示了我们对UDA的两种方法。首先,直接熵最小化使目标Pxt的熵最小,等价于最小化加权自信息映射的和。在第二种互补的方法中,我们使用对抗性训练来加强Ix跨领域的一致性。红色箭头用于目标域,蓝色箭头用于源。文中给出了熵映射的一个例子。
我们的模型是在源域上使用监督损耗进行训练的。形式上,我们考虑一组Xs⊂RH×W×3的源例子,以及相关的ground-truth C类分割图,Ys⊂(1,C)H×W。样本xs是一幅H × W的彩色图像,输入ys(H,W)=[ys(H,W,c)]关联地图ys提供像素(h, w)的标签为独热码向量。设F为语义分割网络,取图像x,预测c维“软分割图”F (x) = Px =[Px(w,h,c)]h,w,c。通过最后的softmax层,每个c维像素方向的矢量[Px(w,h,c)]c在类上表现为离散分布。如果一个类突出,分布是低熵的,如果分数是均匀分布的,从网络的角度来看,这是不确定的迹象,熵就很大。学习F的参数θF以最小化分割损失Lseg(xs, ys) =−∑Hh=1∑Ww=1∑Cc=1y(h,w,c)s(logP(h,w,c)xs)。在只对源域进行训练而不进行域自适应的情况下,优化问题为:
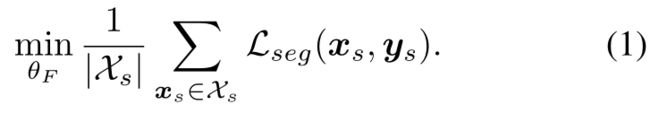
3.1.直接熵最小化
对于目标域,由于我们没有对于图像样本xt∈Xt的注释yt,所以我们不能使用(1)来学习F。有些方法使用模型的预测y∧t作为yt的替代。此外,该替代仅用于预测具有足够可信度的像素。我们不使用高自信的代理,而是提出约束模型,使其产生高自信的预测。我们通过最小化预测的熵来实现这一点。
我们引入熵损失Lent直接最大化目标域的预测确定性。在这项工作中,我们使用Shannon熵[36]。给定目标输入图像xt,熵映射Ext∈[0,1]H×W由归一化到[0,1]范围内的独立像素熵组成,(h,w)处像素的熵为:
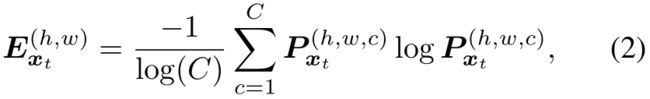
熵映射的一个例子如2所示。熵损失Lent定义为所有像素级别归一化熵的和:
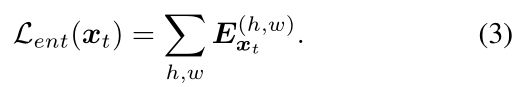
在训练过程中,我们联合优化源样本的监督分割损失Lseg和目标样本的无监督熵损失Lent。最终的优化问题表示为:
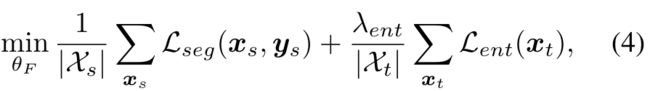
λent作为熵Lent的权重因子
与自训练存在的联系:伪标记是一种简单而有效的半监督学习方法。近年来,该方法已被应用于基于迭代自训练(ST)程序[51]的语义分割任务中。ST方法假设对目标样本进行高得分像素预测所得到的集合K⊂(1,H) × (1, W)是正确的,且概率较高。这样的假设允许使用交叉熵损失与伪标签的目标预测。在实践中,K是通过选择具有固定阈值或预定阈值的高分像素来构建的。为了与熵最小化联系起来,我们将ST方法的训练问题写为: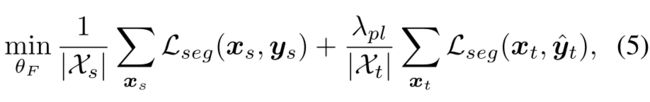
其中y∧t是xt的独热码类别预测,并且有:
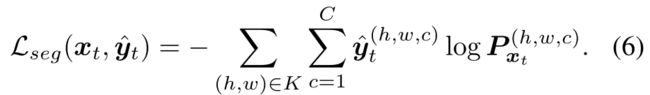
比较式(2-3)和(6),我们注意到我们的熵损失Lent(xt)可以被视为伪标签交叉熵损失Lseg(xt,y∧t)的软分配版本。与ST[51]不同,我们的基于熵的方法不需要复杂的调度过程来选择阈值。甚至,与ST假设相反,我们在4.3节中表明,在某些情况下,训练“困难的”或“最困惑的”像素会产生更好的性能。
3.2.利用对抗学习最小化熵
图2:方法概述。图中显示了我们对UDA的两种方法。首先,直接熵最小化使目标Pxt的熵最小,等价于最小化加权自信息映射的和。在第二种互补的方法中,我们使用对抗性训练来加强Ix跨领域的一致性。红色箭头用于目标域,蓝色箭头用于源。文中给出了熵映射的一个例子。
在式(3)中,输入图像的熵损失定义为独立像素预测熵的和。因此,这种损失的最小化忽略了局部语义之间的结构依赖关系。如[41]所示,对于UDA进行语义分割时,对结构化的输出空间进行适配是有益的。着基于源域和目标域在语义布局上具有很强的相似性。
在这一部分中,我们引入了一个统一的对抗训练框架,通过使目标的熵分布与源的熵分布相似来间接地最小化熵。这允许利用域之间的结构一致性。为此,我们将UDA任务定义为在加权自信息空间上使源和目标之间的分布距离最小。图2说明了我们的对抗学习过程。我们的对抗方法的动机是,经过训练的模型自然地产生低熵预测的源类图像。通过对齐目标域和源域的加权自信息分布,间接最小化目标预测熵。此外,由于适应是在加权自信息空间上进行的,我们的模型利用了从源到目标的结构信息。
具体来说,给定像素级类预测分数Px(h,w,c),自信息或“surprisal”[40]定义为−log Px(h,w,c)。实际上,(2)中的熵Ex(h,w)就是自信息Ec[−log Px(h,w,c)]的期望值。我们在由像素级向量Ix(h,w) = -Px(h,w,c)logPx(h,w,c)组成的加权自信息映射Ix上进行对抗自适应。这些向量可以看作是Shannon熵的消纠缠。然后,我们构造一个全卷积鉴别器网络D,参数θD以Ix为输入,产生域分类输出,即类别标为1(0)为源(目标)域。与[11]类似,我们训练识别器来区分来自源图像和目标图像的输出,同时训练分割网络来欺骗识别器。其中,让LD表示交叉熵域的分类损失。鉴别器的训练目标为:
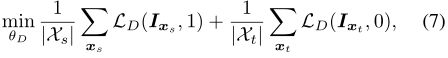
训练分割网络的对抗目标是:
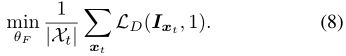
结合(1)和(8),得到最优化问题:
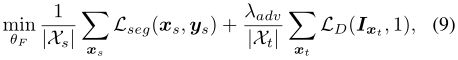
使用对抗项LD的加权因子λadv。在训练期间,我们使用(7)和(9)中的目标函数交替优化网络D和F。
3.3. 联合使用类别占比率的先验知识
熵最小化可能会偏向于一些简单的类。因此,有时用一些先验知识来指导学习是有益的。为此,我们基于类在源标签上的分布,使用一个简单的类先验。我们将源标签上每个类的像素数的ℓ1-归一化直方图计算作为类先验向量ps。现在,根据预测的Pxt,任何类别的预期概率与之前的类别ps之间的太大差异将受到惩罚,使用
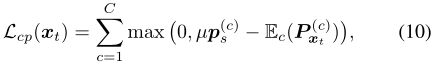
其中,µ∈[0,1]用于放松类先验约束。这解决了单个目标图像上的类分布不一定接近ps的事实。
4.实验
在本节中,我们将介绍我们的实验结果。第4.1节介绍了使用的数据集以及我们的训练参数。在4.2节和4.3节中,我们报告和讨论我们的主要结果。在4.3节中,我们讨论了基于熵的UDA检测的初步结果。
4.1.实验细节
数据集
为了评估我们的方法,我们使用具有挑战性的合成–>真实无监督领域适应设置。模型在完整注释的合成数据上进行训练,并在真实世界的数据上进行验证。在这样的设置中,模型可以在训练中获得一些未标记的真实图像。为了训练我们的模型,我们使用GTA5[30]或SYNTHIA[31]作为源域合成数据,并将Cityscapes数据集[6]的训练分割作为目标域数据。类似的设置以前也在其他作品中使用过[15,14,41,51]。
- GTA5→Cityscapes:GTA5数据集由24,966帧合成的视频游戏画面组成。图像提供了33个类的像素级语义标注。与[15]类似,我们使用了与cityscape数据集相同的19个类。
- SYNTHIA→Cityscapes:我们使用SYNTHIARAND-CITYSCAPES集合4和9400张合成图像进行训练。我们用SYNTHIA和cityscape中的16个公共类来训练我们的模型。在评估时,我们比较了[51]中使用的协议在16类和13类子集上的性能。
在这两个设置中,2975个未标记的城市景观图像被用于训练。我们用标准的平均-相交-合并(mIoU)度量[9]来衡量分割性能。对500张验证图像进行评估。
网络体系结构
我们使用Deeplab-V2[2]作为基础语义分割体系结构F。为了更好地捕捉场景上下文,最后一层的特征输出采用Atrous空间金字塔池(Atrous Spatial Pyramid Pooling, ASPP)。采样率固定为{6,12,18,24},类似于[2]中的ASPP-L模型。我们在两种不同的base deep CNN架构上进行了实验:VGG-16[37]和ResNet101[13]。在[2]之后,我们修改最后一层的stride和expand rate,以产生更密集、视野更大的feature map。为了进一步提高ResNet-101的性能,我们对来自conv4和conv5[41]的多级输出特征进行了自适应。
章节3.2中介绍的对抗网络D具有与DCGAN[28]中使用的相同的架构。加权自信息映射Ix通过4个卷积层转发,每个卷积层与一个固定负斜率为0.2的leaky-ReLU层耦合。最后,分类器层生成分类输出,指示输入是否对应于源域或目标域
实现细节
我们在实现中使用了PyTorch深度学习框架[27]。所有的实验都是在单个NVIDIA 1080TI显卡上完成的,内存为11 GB。除了3.2节中提到的对抗判别器外,我们的模型是使用随机梯度下降优化器[1]训练的,学习率为2.5 × 10−4,动量为0.9,权值衰减为10−4。我们使用学习速率为10−4的Adam优化器[19]来训练鉴别器。为了安排学习速率,我们遵循[2]中提到的多项式退火程序。
熵和对抗性损失的权重因子:为Lent设置权重,训练集的性能提供了重要的指标。当λent较大时,熵下降过快,模型强烈偏向于少数类。当λent选取在一定范围内时,性能较好,对精度值不敏感。因此,无论网络还是数据集,我们对所有的实验都使用相同的λent = 0.001。对于(9)中的重量λadv,也有类似的论点。我们在所有实验中都确定λadv= 0.001。
4.2.结果
我们将这些方法的实验结果与不同的基线进行比较。我们的模型在两个UDA基准中实现了最先进的性能。在接下来的内容中,我们展示了我们的方法在不同设置下的不同行为,即训练集和基础cnn。
GTA5→Cityscapes
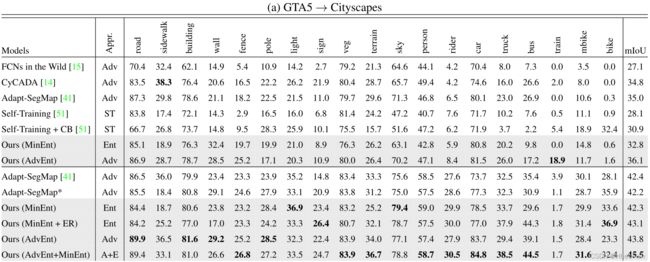
我们在表1中报告了Cityscapes验证集上的mIoU(%)语义分割性能。我们的第一种直接熵最小化方法,在表1-a中称为MinEnt,在基于VGG-16和resnet -101的cnn上都实现了与最先进的基线相当的性能。在没有和有类别平衡[51]的情况下,MinEnt比自我训练(ST)方法表现更好。与[41]相比,基于resnet -101的MinEnt显示出类似的结果,但没有采用鉴别器网络的训练。熵损失的轻开销使得训练时间大大减少。我们的熵方法的另一个优点是易于训练。事实上,训练对抗网络通常被认为是一项困难的任务,因为它不稳定。我们观察到一个更稳定的行为训练模型与熵损失。
有趣的是,我们发现在某些情况下,只有在一定范围内应用熵损失效果最好。这种现象是通过基于resnet -101的模型观测到的。事实上,通过训练熵值在每个目标样本前30%的像素,我们可以得到一个更好的模型。该模型在表1-a中称为MinEnt+ER。我们在GTA5→Cityscapes设置中使用这一策略获得了43.1%的mIoU。更多细节见第4.3节。
我们的第二种方法使用加权自信息空间上的对抗训练,即AdvEnt,在两个基础网络上显示出对基线的持续改善。一般来说,AdvEnt的工作效果比MinEnt好。在GTA5→CityscapesUDA设置中,AdvEnt达到了最先进的mIoU 43.8。这些结果证实了我们所认为的结构适应重要性。使用基于vgg -16的网络,与直接熵最小化相比,加权自信息空间的自适应带来了+3.3% mIoU的改进。对于基于resnet101的网络,改进较小,即+1.5% mIoU。我们推测,由于GTA5语义布局与Cityscapes中的语义布局非常相似,因此ResNet-101等具有高容量CNN基础的分割网络F能够从源样本的监督中学习到一些空间先验。对于像VGG-16这样的低容量基础模型,在结构化空间上进行额外的正则化与对抗训练是更有益的。
通过结合MinEnt和AdvEnt两个模型的结果,我们观察到与单个模型的结果相比,性能有了相当大的提升。该组合在Cityscapes验证集上实现了45.5%的mIoU。两个模型学习到的信息是互补的。事实上,虽然熵损失会惩罚独立像素级的预测,但对抗性损失更多地作用于图像级,即场景拓扑。与[41]类似,为了与其他UDA方法进行更有意义的比较,在表2-a中,我们展示了UDA模型与oracle之间的性能差距,即在Cityscapes训练集上接受全面监督的模型。与通过其他方法训练的模型相比,我们的单一和集成模型与oracle的mIoU差距更小。
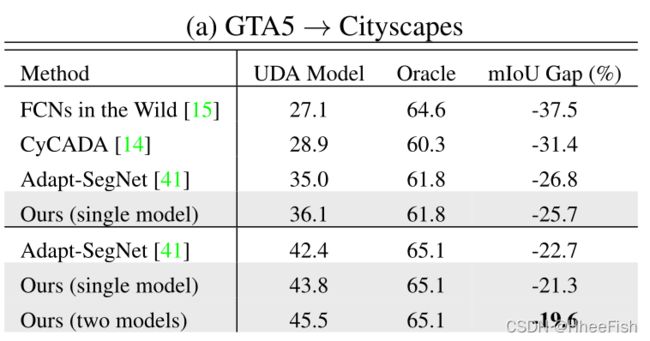
在图3中,我们展示了我们模型的一些定性结果。在没有域自适应的情况下,仅在源监控上训练的模型会产生有噪声的分段预测以及高熵激活,在某些类(如“building”和“car”)上有少数例外。尽管如此,仍然存在许多完全错误的自信预测(低熵)。另一方面,我们的模型能够在高置信度下产生正确的预测。我们观察到,总体而言,与MinEnt模型相比,AdvEnt模型实现了更低的预测熵。
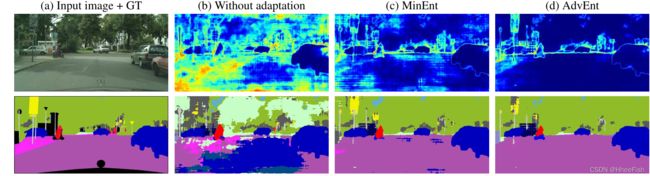
图3: GTA5中的定性结果→Cityscapes设置。列(a)显示了输入图像和相应的语义切分。列(b)、(c)和(d)显示了分割结果(底部)以及不同方法生成的预测熵图(顶部)。最好用彩色来观看。
SYNTHIA→Cityscapes
表1-b显示了城市景观验证集的16类和13类子集的结果。我们注意到,与GTA5和Cityscapes中的场景图像相比,SYNTHIA中的场景图像涵盖了更多不同的视点。这导致了我们的方法的不同行为。
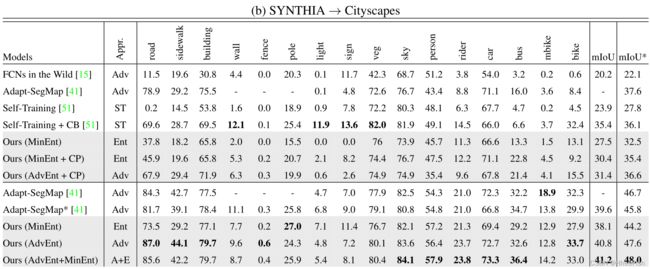
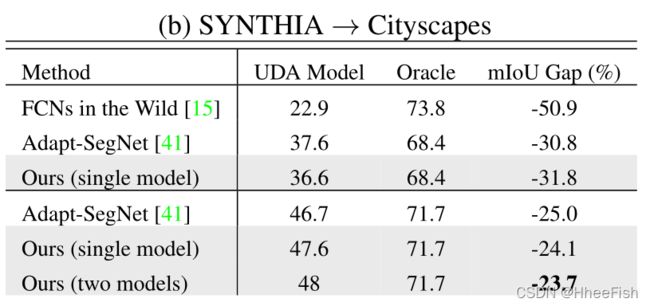
在基于VGG-16的网络上,MinEnt模型显示出与最新方法相当的结果。与自训练[51]相比,我们的模型在16类和13类子集上分别达到+3.6%和+4.7%。然而,与类别平衡自我训练等更强的基线相比,我们观察到类别“道路”显著下降。我们认为这是由于SYNTHIA和Cityscapes之间的巨大布局差距。为了解决这个问题,我们引入了源域的类别占比先验知识,如第3.3节所述。通过使用类别比率先验约束目标产出分布,如表1b中的CP所示,我们在16类和13类子集上将MinEnt提高了+2.9%mIoU。通过对抗性训练,我们有一个额外的增长1%。在基于ResNet-101的网络上,AdvEnt模型实现了最先进的性能。与[41]的再训练模型(即Adapt SegMap*)相比,该模型的出现将16类和13类子集的mIoUs分别提高了+1.2%和+1.8%。与上述GTA5结果一致,在SYNTHIA上训练的两个模型MinEnt和AdvEnt的集合在16类和13类子集上分别达到41.2%和48.0%的最佳mIoU。根据表2-b,我们的模型与oracle的mIoU差距最小。
4.3.讨论
第4.2节中的实验结果验证了我们方法的优势。为了进一步推动绩效,我们提出了两种不同的方法来规范两种特定环境下的培训。本节讨论我们的实验选择并解释其背后的直觉。
GTA5→Cityscapes:在特定的熵范围内训练
在此设置中,我们观察到使用基于ResNet-101的网络的模型挖掘的性能可以通过在特定范围内具有熵值的目标像素上进行训练来提高。有趣的是,最好的MinEnt模型是在每个目标样本的前30%最高熵像素上训练的,比普通模型增加了0.8%的mIoU。我们注意到,高熵像素是“最容易混淆”的像素,也就是说,分割模型在多个类之间是不确定的。一个原因是基于ResNet-101的模型在这种特定的环境下具有良好的通用性。因此,在“最令人困惑”的预测中,有相当数量的预测是正确的,但“置信度较低”。最小化这样一个集合上的熵损失仍然会推动模型朝着理想的方向发展。然而,这种假设并不适用于基于VGG-16的模型。
SYNTHIA→Cityscapes:使用类占比率先验知识
如前所述,SYNTHIA的布局和视角与城市景观Cityscapes明显不同。这种差异可能会对某些类造成非常糟糕的预测,然后通过最小化熵或将其用作自我训练中的标记代理来进一步鼓励这种预测。因此,它可能导致强烈的类偏差,或者在极端情况下,在目标域中完全缺少某些类。在前面添加类比率可以鼓励所有类的存在,从而有助于避免此类退化解。如第节所述。3.3,我们使用µ来放宽源类比优先级,例如µ=0表示无优先级,而µ=1表示强制执行精确的类比优先级。µ=1并不理想,因为这意味着每个目标映像都应该遵循源域的类比率。我们选择µ=0.5以使目标类比率与源类比率略有不同。
**UDA在目标检测中的应用 **
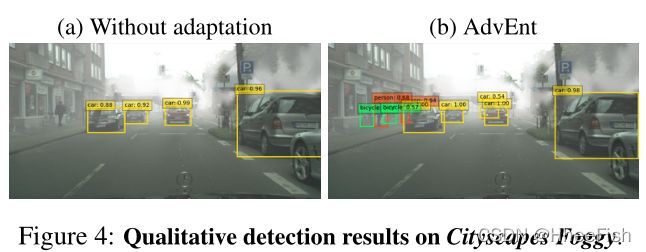
所提出的基于熵的方法不仅限于语义分割,而且可以应用于UDA的其他识别任务,如目标检测。我们在UDA目标检测装置Cityscapes中进行了实验Cityscapes→Cityscapes Foggy,与[3]中的相似。直接将熵损失和对抗性损失应用于现有检测架构SSD-300[22],与仅在源上训练的基线模型相比,显著提高了检测性能。就平均精度(mAP)而言,与14.7%的基线性能相比,MinEnt和AdvEnt模型的mAP分别为16.9%和26.2%。在[3]中,作者报告了27.6%mAP的性能稍好,使用更快的RCNN[29],这是一种比我们更复杂的检测体系结构。我们注意到,我们的检测系统在较低分辨率(即300×300)的图像上进行了训练和测试。尽管存在这些不利因素,我们对基线的改善(+11.5%使用AdvEnt地图)大于[3]中报告的改善(+8.8%)。这样一个初步的结果表明了基于熵的方法在UDA上进行检测的可能性。表3报告了每类IoU,图4显示了城市景观雾的定性结果。 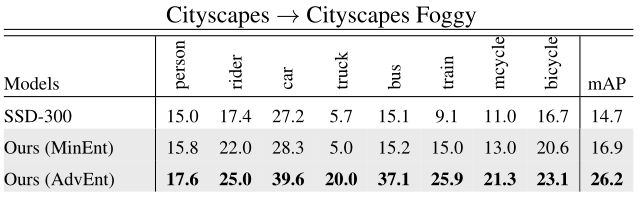
5.结论
在这项工作中,我们提出了两种互补的基于熵的语义分割方法。我们的模型在两个具有挑战性的“合成–>真实”基准上达到了最先进水平。两个模型的集成进一步提高了性能。在用于目标检测的UDA上,我们展示了一个有希望的结果,并且相信使用更健壮的检测架构可以获得更好的性能。
参考文献
[1] L. Bottou. Large-scale machine learning with stochastic gradient descent. In COMPSTAT. 2010. 5
[2] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. PAMI, 2018. 1, 5
[3] Y. Chen, W. Li, C. Sakaridis, D. Dai, and L. Van Gool. Domain adaptive faster R-CNN for object detection in the wild. In CVPR, 2018. 8
[4] Y. Chen, W. Li, and L. Van Gool. Road: Reality oriented adaptation for semantic segmentation of urban scenes. In CVPR, 2018. 2
[5] Y.-H. Chen, W.-Y. Chen, Y.-T. Chen, B.-C. Tsai, Y.-C. F. Wang, and M. Sun. No more discrimination: Cross city adaptation of road scene segmenters. In ICCV, 2017. 2
[6] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The Cityscapes dataset for semantic urban scene understanding. In CVPR, 2016. 5
[7] G. Csurka. Domain adaptation for visual applications: A comprehensive survey. Springer. 2
[8] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun. CARLA: An open urban driving simulator. In CoRL, 2017. 2
[9] M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The Pascal visual object classes challenge: A retrospective. IJCV, 2015. 5
[10] Y. Ganin and V. Lempitsky. Unsupervised domain adaptation by backpropagation. In ICML, 2015. 1, 2
[11] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, 2014. 3, 4
[12] Y. Grandvalet and Y. Bengio. Semi-supervised learning by entropy minimization. In NIPS, 2005. 3
[13] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. 5
[14] J. Hoffman, E. Tzeng, T. Park, J.-Y. Zhu, P. Isola, K. Saenko, A. Efros, and T. Darrell. CyCADA: Cycle-consistent adversarial domain adaptation. In ICML, 2018. 1, 2, 5, 6, 7
[15] J. Hoffman, D. Wang, F. Yu, and T. Darrell. FCNs in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016. 1, 2, 5, 6, 7
[16] W. Hong, Z. Wang, M. Yang, and J. Yuan. Conditional generative adversarial network for structured domain adaptation. In CVPR, 2018. 2
[17] H. Jain, J. Zepeda, P. Pérez, and R. Gribonval. Subic: A supervised, structured binary code for image search. In ICCV, 2017. 3
[18] H. Jain, J. Zepeda, P. Pérez, and R. Gribonval. Learning a complete image indexing pipeline. In CVPR, 2018. 3
[19] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, 2015. 5
[20] S. Laine and T. Aila. Temporal ensembling for semisupervised learning. arXiv preprint arXiv:1610.02242, 2016. 3
[21] D.-H. Lee. Pseudo-label: The simple and efficient semisupervised learning method for deep neural networks. In ICML Workshop, 2013. 3
[22] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed, C. Fu, and A. C. Berg. SSD: single shot multibox detector. In ECCV, 2016. 8
[23] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. 1
[24] M. Long, Y. Cao, J. Wang, and M. I. Jordan. Learning transferable features with deep adaptation networks. In ICML, 2015. 1, 2
[25] M. Long, H. Zhu, J. Wang, and M. I. Jordan. Unsupervised domain adaptation with residual transfer networks. In NIPS, 2016. 1, 2, 3
[26] Z. Murez, S. Kolouri, D. Kriegman, R. Ramamoorthi, and K. Kim. Image to image translation for domain adaptation. In CVPR, 2018. 3
[27] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in PyTorch. In NIPS Workshop, 2017. 5
[28] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016. 5
[29] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015. 8
[30] S. R. Richter, V. Vineet, S. Roth, and V. Koltun. Playing for data: Ground truth from computer games. In ECCV, 2016. 1, 2, 5
[31] G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. M. Lopez. The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In CVPR, 2016. 1, 2, 5
[32] K. Saito, Y. Ushiku, T. Harada, and K. Saenko. Adversarial dropout regularization. In ICLR, 2018. 1, 2
[33] K. Saito, K. Watanabe, Y. Ushiku, and T. Harada. Maximum classifier discrepancy for unsupervised domain adaptation. In CVPR, 2018. 2
[34] S. Sankaranarayanan, Y. Balaji, A. Jain, S. Nam Lim, and R. Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation. In CVPR, 2018. 1, 2
[35] A. Shafaei, J. J. Little, and M. Schmidt. Play and learn: Using video games to train computer vision models. In BMVC, 2016. 2
[36] C. E. Shannon. A mathematical theory of communication. Bell system technical journal, 1948. 3
[37] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. 5
[38] J. T. Springenberg. Unsupervised and semi-supervised learning with categorical generative adversarial networks. ICLR, 2016. 2, 3
[39] A. Tarvainen and H. Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semisupervised deep learning results. In NIPS, 2017. 3
[40] M. Tribus. Thermostatics and thermodynamics. van Nostrand, 1970. 4
[41] Y.-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker. Learning to adapt structured output space for semantic segmentation. In CVPR, 2018. 2, 4, 5, 6, 7
[42] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In CVPR, 2017. 1, 2
[43] Z. Wu, X. Han, Y.-L. Lin, M. Gokhan Uzunbas, T. Goldstein, S. Nam Lim, and L. S. Davis. DCAN: Dual channel-wise alignment networks for unsupervised scene adaptation. In ECCV, 2018. 1, 2, 3
[44] H. Yan, Y. Ding, P. Li, Q. Wang, Y. Xu, and W. Zuo. Mind the class weight bias: Weighted maximum mean discrepancy for unsupervised domain adaptation. In CVPR, 2017. 1
[45] Y. Zhang, P. David, and B. Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In ICCV, 2017. 3
[46] Y. Zhang, Z. Qiu, T. Yao, D. Liu, and T. Mei. Fully convolutional adaptation networks for semantic segmentation. In CVPR, 2018. 3
[47] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid scene parsing network. In CVPR, 2017. 1
[48] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. In ICCV, 2017. 2
[49] X. Zhu. Semi-supervised learning literature survey. Technical Report 1530, Computer Sciences, University of Wisconsin-Madison, 2005. 2
[50] X. Zhu, H. Zhou, C. Yang, J. Shi, and D. Lin. Penalizing top performers: Conservative loss for semantic segmentation adaptation. In ECCV, September 2018. 3
[51] Y. Zou, Z. Yu, B. V. Kumar, and J. Wang. Unsupervised domain adaptation for semantic segmentation via classbalanced self-training. In ECCV, 2018. 1, 2, 3, 4, 5, 6, 7