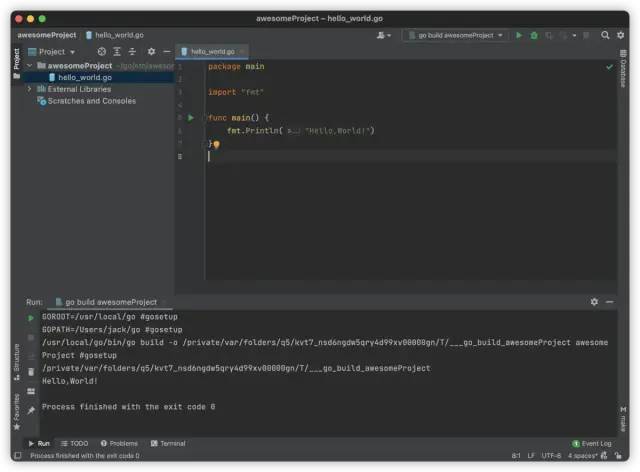
IDE :使用 GoLand is a cross-platform IDE built specially for Go developers。 https://www.jetbrains.com/go/
go 命令说明:
go
Go is a tool for managing Go source code.
Usage:
go [arguments]
The commands are:
bug start a bug report
build compile packages and dependencies
clean remove object files and cached files
doc show documentation for package or symbol
env print Go environment information
fix update packages to use new APIs
fmt gofmt (reformat) package sources
generate generate Go files by processing source
get add dependencies to current module and install them
install compile and install packages and dependencies
list list packages or modules
mod module maintenance
run compile and run Go program
test test packages
tool run specified go tool
version print Go version
vet report likely mistakes in packages
Use "go help " for more information about a command.
Additional help topics:
buildconstraint build constraints
buildmode build modes
c calling between Go and C
cache build and test caching
environment environment variables
filetype file types
go.mod the go.mod file
gopath GOPATH environment variable
gopath-get legacy GOPATH go get
goproxy module proxy protocol
importpath import path syntax
modules modules, module versions, and more
module-get module-aware go get
module-auth module authentication using go.sum
packages package lists and patterns
private configuration for downloading non-public code
testflag testing flags
testfunc testing functions
vcs controlling version control with GOVCS
Use "go help " for more information about that topic.
Hello World
源代码文件 hello_world.go :
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
命令行运行:
go run hello_world.go
输出:
Hello, World!
在 GoLang IDE 中效果如下:
Go 语言简介
概述
Go 是一个开源的编程语言,它能让构造简单、可靠且高效的软件变得容易。
Go是从2007年末由Robert Griesemer, Rob Pike, Ken Thompson主持开发,后来还加入了Ian Lance Taylor, Russ Cox等人,并最终于2009年11月开源,在2012年早些时候发布了Go 1稳定版本。现在Go的开发已经是完全开放的,并且拥有一个活跃的社区。
Go 语言特色
简洁、快速、安全 并行、有趣、开源 内存管理、数组安全、编译迅速
Go 语言用途
Go 语言被设计成一门应用于搭载 Web 服务器,存储集群或类似用途的巨型中央服务器的系统编程语言。
package main
import "fmt"
func main() {
fmt.Println(sum(1, 1))
}
func sum(a int, b int) interface{} {
return a + b
}
分支
package main
import "fmt"
func main() {
fmt.Println(max(1, 2))
}
func max(a int, b int) interface{} {
var max int = 0
if a > b {
max = a
} else {
max = b
}
return max
}
循环
package main
import "fmt"
func main() {
fmt.Println(sum1_n(100))
}
func sum1_n(n int) interface{} {
var sum = 0
for i := 1; i <= n; i++ {
sum += i
}
return sum
}
数组
package main
import "fmt"
func main() {
var a []int = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
fmt.Println(sumArray(a))
}
func sumArray(a []int) interface{} {
var sum = 0
for i := 0; i < len(a); i++ {
sum += a[i]
}
return sum
}
指针
package main
import "fmt"
func main() {
var a int = 20
/* 声明指针变量 */
var ip *int
fmt.Println(ip==nil)
/* 指针变量的存储地址 */
ip = &a
fmt.Println(ip==nil)
fmt.Printf("a 变量的地址是: %x\n", &a)
/* 指针变量的存储地址 */
fmt.Printf("ip 变量储存的指针地址: %x\n", ip)
/* 使用指针访问值 */
fmt.Printf("*ip 变量的值: %d\n", *ip)
}
//true
//false
//a 变量的地址是: c0000ae008
//ip 变量储存的指针地址: c0000ae008
//*ip 变量的值: 20
结构体 struct
package main
import "fmt"
func main() {
var b = Book{
"Go Programming",
"ken",
10000,
}
fmt.Println(b.title)
fmt.Println(b.author)
fmt.Println(b.id)
//Go Programming
//ken
//10000
}
type Book struct {
title string
author string
id int
}
/* 声明变量,默认 map 是 nil */
var map_variable map[key_data_type]value_data_type
/* 使用 make 函数 */
map_variable := make(map[key_data_type]value_data_type)
如果不初始化 map,那么就会创建一个 nil map。nil map 不能用来存放键值对。
package main
import "fmt"
func main() {
var ccmap = make(map[string]string)
ccmap["China"] = "北京"
ccmap["Italy"] = "罗马"
ccmap["Germany"] = "柏林"
for c := range ccmap {
fmt.Println(c, "Capital is ", ccmap[c])
}
c, contains := ccmap["American"]
if contains {
fmt.Println("American's capital is ", c)
} else {
fmt.Println("Not exist")
}
}
//Italy Capital is 罗马
//Germany Capital is 柏林
//China Capital is 北京
//Not exist
Go 优势与生态
Go 语言生态
当下使用 Go 语言开发的软件产品非常众多,而且知名的产品也不再少数,足见这门语言的强大:
软件
描述
链接
docker
家喻户晓的容器技术
github.com/moby/moby
kubernetes
容器编排引擎,google出品
github.com/kubernetes/kubernetes
etcd
分布式服务注册发现系统
github.com/etcd-io/etcd
influxdb
时序数据库
github.com/influxdata/influxdb
grafana
数据监控可视化看板
github.com/grafana/grafana
prometheus
开源监控系统
github.com/prometheus/prometheus
consul
分布式服务发现系统
github.com/hashicorp/consul
nsq
亿级消息队列
github.com/nsqio/nsq
TiDB
分布式数据库, go + rust 打造
github.com/pingcap/tidb
除了上述表格中列举的产品外, Go 语言还涉足于像区块链、微服务等场景,开源的框架也非常多,所以说 Go 语言是一门值得去学习的语言。
性能优势
Go 语言被称为是:"21世纪的C语言",虽然这个帽子戴的有点高,不妨这里给大家解读一下,其实这句话有两层含义:
第一层含义是: Go 语言的语法和C语言类似,如果你会C语言,上手会很快。但如果你不会C语言,其实也不用担心,比起C语言, Go 语言上手其实很简单。
第二层含义是: Go 语言的性能, Go 语言内置强大的并发模型 goroutine,它能让我们快速开发高并发web系统,并且在同样服务器资源的情况下, Go 语言表现出来的性能也是相当的优秀,这也是推荐大家选择选择 Go 语言的原因之一。
部署运维成本低
这是我选择 Go 语言的第二个原因。 Go 语言属于编译型语言,最终部署上线,我们只需要部署项目编译后的二进制文件即可,类比一下像 PHP 或 python 这种解释性语言在服务器上运行还需要安装相应的运行环境,而使用二进制代码方式使得部署变得更为简单,也不会存在多版本共享环境的兼容性问题,运维也变得非常容易。
编码格式统一
Go 语言官方内置了统一代码风格的工具 gofmt( IDE 一般都会内置集成), 用来规范大家代码风格,这对于需要多人协作项目尤为重要。
// Copyright 2011 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
/*
Package builtin provides documentation for Go's predeclared identifiers.
The items documented here are not actually in package builtin
but their descriptions here allow godoc to present documentation
for the language's special identifiers.
*/
package builtin
// bool is the set of boolean values, true and false.
type bool bool
// true and false are the two untyped boolean values.
const (
true = 0 == 0 // Untyped bool.
false = 0 != 0 // Untyped bool.
)
// uint8 is the set of all unsigned 8-bit integers.
// Range: 0 through 255.
type uint8 uint8
// uint16 is the set of all unsigned 16-bit integers.
// Range: 0 through 65535.
type uint16 uint16
// uint32 is the set of all unsigned 32-bit integers.
// Range: 0 through 4294967295.
type uint32 uint32
// uint64 is the set of all unsigned 64-bit integers.
// Range: 0 through 18446744073709551615.
type uint64 uint64
// int8 is the set of all signed 8-bit integers.
// Range: -128 through 127.
type int8 int8
// int16 is the set of all signed 16-bit integers.
// Range: -32768 through 32767.
type int16 int16
// int32 is the set of all signed 32-bit integers.
// Range: -2147483648 through 2147483647.
type int32 int32
// int64 is the set of all signed 64-bit integers.
// Range: -9223372036854775808 through 9223372036854775807.
type int64 int64
// float32 is the set of all IEEE-754 32-bit floating-point numbers.
type float32 float32
// float64 is the set of all IEEE-754 64-bit floating-point numbers.
type float64 float64
// complex64 is the set of all complex numbers with float32 real and
// imaginary parts.
type complex64 complex64
// complex128 is the set of all complex numbers with float64 real and
// imaginary parts.
type complex128 complex128
// string is the set of all strings of 8-bit bytes, conventionally but not
// necessarily representing UTF-8-encoded text. A string may be empty, but
// not nil. Values of string type are immutable.
type string string
// int is a signed integer type that is at least 32 bits in size. It is a
// distinct type, however, and not an alias for, say, int32.
type int int
// uint is an unsigned integer type that is at least 32 bits in size. It is a
// distinct type, however, and not an alias for, say, uint32.
type uint uint
// uintptr is an integer type that is large enough to hold the bit pattern of
// any pointer.
type uintptr uintptr
// byte is an alias for uint8 and is equivalent to uint8 in all ways. It is
// used, by convention, to distinguish byte values from 8-bit unsigned
// integer values.
type byte = uint8
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32
// iota is a predeclared identifier representing the untyped integer ordinal
// number of the current const specification in a (usually parenthesized)
// const declaration. It is zero-indexed.
const iota = 0 // Untyped int.
// nil is a predeclared identifier representing the zero value for a
// pointer, channel, func, interface, map, or slice type.
var nil Type // Type must be a pointer, channel, func, interface, map, or slice type
// Type is here for the purposes of documentation only. It is a stand-in
// for any Go type, but represents the same type for any given function
// invocation.
type Type int
// Type1 is here for the purposes of documentation only. It is a stand-in
// for any Go type, but represents the same type for any given function
// invocation.
type Type1 int
// IntegerType is here for the purposes of documentation only. It is a stand-in
// for any integer type: int, uint, int8 etc.
type IntegerType int
// FloatType is here for the purposes of documentation only. It is a stand-in
// for either float type: float32 or float64.
type FloatType float32
// ComplexType is here for the purposes of documentation only. It is a
// stand-in for either complex type: complex64 or complex128.
type ComplexType complex64
// The append built-in function appends elements to the end of a slice. If
// it has sufficient capacity, the destination is resliced to accommodate the
// new elements. If it does not, a new underlying array will be allocated.
// Append returns the updated slice. It is therefore necessary to store the
// result of append, often in the variable holding the slice itself:
// slice = append(slice, elem1, elem2)
// slice = append(slice, anotherSlice...)
// As a special case, it is legal to append a string to a byte slice, like this:
// slice = append([]byte("hello "), "world"...)
func append(slice []Type, elems ...Type) []Type
// The copy built-in function copies elements from a source slice into a
// destination slice. (As a special case, it also will copy bytes from a
// string to a slice of bytes.) The source and destination may overlap. Copy
// returns the number of elements copied, which will be the minimum of
// len(src) and len(dst).
func copy(dst, src []Type) int
// The delete built-in function deletes the element with the specified key
// (m[key]) from the map. If m is nil or there is no such element, delete
// is a no-op.
func delete(m map[Type]Type1, key Type)
// The len built-in function returns the length of v, according to its type:
// Array: the number of elements in v.
// Pointer to array: the number of elements in *v (even if v is nil).
// Slice, or map: the number of elements in v; if v is nil, len(v) is zero.
// String: the number of bytes in v.
// Channel: the number of elements queued (unread) in the channel buffer;
// if v is nil, len(v) is zero.
// For some arguments, such as a string literal or a simple array expression, the
// result can be a constant. See the Go language specification's "Length and
// capacity" p for details.
func len(v Type) int
// The cap built-in function returns the capacity of v, according to its type:
// Array: the number of elements in v (same as len(v)).
// Pointer to array: the number of elements in *v (same as len(v)).
// Slice: the maximum length the slice can reach when resliced;
// if v is nil, cap(v) is zero.
// Channel: the channel buffer capacity, in units of elements;
// if v is nil, cap(v) is zero.
// For some arguments, such as a simple array expression, the result can be a
// constant. See the Go language specification's "Length and capacity" p for
// details.
func cap(v Type) int
// The make built-in function allocates and initializes an object of type
// slice, map, or chan (only). Like new, the first argument is a type, not a
// value. Unlike new, make's return type is the same as the type of its
// argument, not a pointer to it. The specification of the result depends on
// the type:
// Slice: The size specifies the length. The capacity of the slice is
// equal to its length. A second integer argument may be provided to
// specify a different capacity; it must be no smaller than the
// length. For example, make([]int, 0, 10) allocates an underlying array
// of size 10 and returns a slice of length 0 and capacity 10 that is
// backed by this underlying array.
// Map: An empty map is allocated with enough space to hold the
// specified number of elements. The size may be omitted, in which case
// a small starting size is allocated.
// Channel: The channel's buffer is initialized with the specified
// buffer capacity. If zero, or the size is omitted, the channel is
// unbuffered.
func make(t Type, size ...IntegerType) Type
// The new built-in function allocates memory. The first argument is a type,
// not a value, and the value returned is a pointer to a newly
// allocated zero value of that type.
func new(Type) *Type
// The complex built-in function constructs a complex value from two
// floating-point values. The real and imaginary parts must be of the same
// size, either float32 or float64 (or assignable to them), and the return
// value will be the corresponding complex type (complex64 for float32,
// complex128 for float64).
func complex(r, i FloatType) ComplexType
// The real built-in function returns the real part of the complex number c.
// The return value will be floating point type corresponding to the type of c.
func real(c ComplexType) FloatType
// The imag built-in function returns the imaginary part of the complex
// number c. The return value will be floating point type corresponding to
// the type of c.
func imag(c ComplexType) FloatType
// The close built-in function closes a channel, which must be either
// bidirectional or send-only. It should be executed only by the sender,
// never the receiver, and has the effect of shutting down the channel after
// the last sent value is received. After the last value has been received
// from a closed channel c, any receive from c will succeed without
// blocking, returning the zero value for the channel element. The form
// x, ok := <-c
// will also set ok to false for a closed channel.
func close(c chan<- Type)
// The panic built-in function stops normal execution of the current
// goroutine. When a function F calls panic, normal execution of F stops
// immediately. Any functions whose execution was deferred by F are run in
// the usual way, and then F returns to its caller. To the caller G, the
// invocation of F then behaves like a call to panic, terminating G's
// execution and running any deferred functions. This continues until all
// functions in the executing goroutine have stopped, in reverse order. At
// that point, the program is terminated with a non-zero exit code. This
// termination sequence is called panicking and can be controlled by the
// built-in function recover.
func panic(v interface{})
// The recover built-in function allows a program to manage behavior of a
// panicking goroutine. Executing a call to recover inside a deferred
// function (but not any function called by it) stops the panicking sequence
// by restoring normal execution and retrieves the error value passed to the
// call of panic. If recover is called outside the deferred function it will
// not stop a panicking sequence. In this case, or when the goroutine is not
// panicking, or if the argument supplied to panic was nil, recover returns
// nil. Thus the return value from recover reports whether the goroutine is
// panicking.
func recover() interface{}
// The print built-in function formats its arguments in an
// implementation-specific way and writes the result to standard error.
// Print is useful for bootstrapping and debugging; it is not guaranteed
// to stay in the language.
func print(args ...Type)
// The println built-in function formats its arguments in an
// implementation-specific way and writes the result to standard error.
// Spaces are always added between arguments and a newline is appended.
// Println is useful for bootstrapping and debugging; it is not guaranteed
// to stay in the language.
func println(args ...Type)
// The error built-in interface type is the conventional interface for
// representing an error condition, with the nil value representing no error.
type error interface {
Error() string
}
XML Schema 是基于 XML 的 DTD 替代者。 XML Schema 可描述 XML 文档的结构。 XML Schema 语言也可作为 XSD(XML Schema Definition)来引用。 XML Schema 的作用是定义 XML 文档的合法构建模块,类似 DTD。 XML Schema: 定义可出现在文档中的元素 定义可出现在文档中的属性 定义哪个元素是子元素 定义子元素的次序 定义子元素的数目 定义元素是否为空,或者是否可包含文本 定义元素和属性的数据类型 定义元素和属性的默认值以及固定值
XML Schema 是 DTD 的继任者 我们认为 XML Schema 很快会在大部分网络应用程序中取代 DTD。 理由如下: XML Schema 可针对未来的需求进行扩展 XML Schema 更完善,功能更强大 XML Schema 基于 XML 编写 XML Schema 支持数据类型 XML Schema 支持命名空间
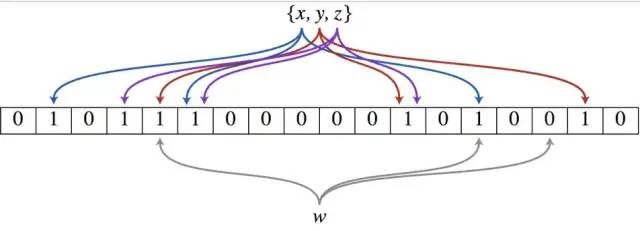
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
布隆过滤器添加元素
将要添加的元素给k个哈希函数
得到对应于位数组上的k个位置
将这k个位置设为1
布隆过滤器查询元素
将要查询的元素给k个哈希函数
得到对应于位数组上的k个位置
如果k个位置有一个为0,则肯定不在集合中
如果k个位置全部为1,则可能在集合中
布隆过滤器实现
下面给出python的实现,使用murmurhash算法
import mmh3
from bitarray import bitarray
# zhihu_crawler.bloom_filter
# Implement a simple bloom filter with murmurhash algorithm.
# Bloom filter is used to check wether an element exists in a collection, and it has a good performance in big data situation.
# It may has positive rate depend on hash functions and elements count.
BIT_SIZE = 5000000
class BloomFilter:
def __init__(self):
# Initialize bloom filter, set size and all bits to 0
bit_array = bitarray(BIT_SIZE)
bit_array.setall(0)
self.bit_array = bit_array
def add(self, url):
# Add a url, and set points in bitarray to 1 (Points count is equal to hash funcs count.)
# Here use 7 hash functions.
point_list = self.get_postions(url)
for b in point_list:
self.bit_array[b] = 1
def contains(self, url):
# Check if a url is in a collection
point_list = self.get_postions(url)
result = True
for b in point_list:
result = result and self.bit_array[b]
return result
def get_postions(self, url):
# Get points positions in bit vector.
point1 = mmh3.hash(url, 41) % BIT_SIZE
point2 = mmh3.hash(url, 42) % BIT_SIZE
point3 = mmh3.hash(url, 43) % BIT_SIZE
point4 = mmh3.hash(url, 44) % BIT_SIZE
point5 = mmh3.hash(url, 45) % BIT_SIZE
point6 = mmh3.hash(url, 46) % BIT_SIZE
point7 = mmh3.hash(url, 47) % BIT_SIZE
return [point1, point2, point3, point4, point5, point6, point7]
Sets or clears the bit at offset in the string value stored at key.
The bit is either set or cleared depending on value, which can be either 0 or 1.
When key does not exist, a new string value is created. The string is grown to make sure it can hold a bit at offset. The offset argument is required to be greater than or equal to 0, and smaller than 232 (this limits bitmaps to 512MB). When the string at key is grown, added bits are set to 0.
Warning: When setting the last possible bit (offset equal to 232 -1) and the string value stored at key does not yet hold a string value, or holds a small string value, Redis needs to allocate all intermediate memory which can block the server for some time. On a 2010 MacBook Pro, setting bit number 232 -1 (512MB allocation) takes ~300ms, setting bit number 230 -1 (128MB allocation) takes ~80ms, setting bit number 228 -1 (32MB allocation) takes ~30ms and setting bit number 226 -1 (8MB allocation) takes ~8ms. Note that once this first allocation is done, subsequent calls to SETBIT for the same key will not have the allocation overhead.
Data structures are nothing different. They are like the bookshelves of your application where you can organize your data. Different data structures will give you different facility and benefits. To properly use the power and accessibility of the data structures you need to know the trade-offs of using one.
$make install
cd src && /Library/Developer/CommandLineTools/usr/bin/make install
CC Makefile.dep
...
Hint: It's a good idea to run 'make test' ;)
INSTALL redis-server
INSTALL redis-benchmark
INSTALL redis-cli
Given a sorted linked list, delete all duplicates such that each element appear only once.
For example,Given 1->1->2, return 1->2.Given 1->1->2->3->3, return&
在JDK1.5之前的单例实现方式有两种(懒汉式和饿汉式并无设计上的区别故看做一种),两者同是私有构
造器,导出静态成员变量,以便调用者访问。
第一种
package singleton;
public class Singleton {
//导出全局成员
public final static Singleton INSTANCE = new S