pytorch学习笔记七:nn网络层——池化层、线性层
一、池化层
池化运算:对信号进行“收集” 并“总结”,类似于水池收集水资源,因而得名池化层。
- 收集:由多变少,图像的尺寸由大变小
- 总结:最大值/平均值
下面是最大值池化和平均值池化的示意图:
 最大值池化就是将滑动窗口中的最大值作为最终的结果;平均值池化是将滑动窗口的平均值作为最终结果。下面看一下pytorch中提供最大值和平均值池化的函数
最大值池化就是将滑动窗口中的最大值作为最终的结果;平均值池化是将滑动窗口的平均值作为最终结果。下面看一下pytorch中提供最大值和平均值池化的函数
1、nn.Maxpool2d
nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
功能:对二维信号(图像)进行最大值池化
参数:
- kernel_size:池化核尺寸
- stride:步长
- padding:填充个数
- dilation:池化核间隔大小
- ceil_mode:尺寸向上取整
- return_indices: 记录池化像素索引
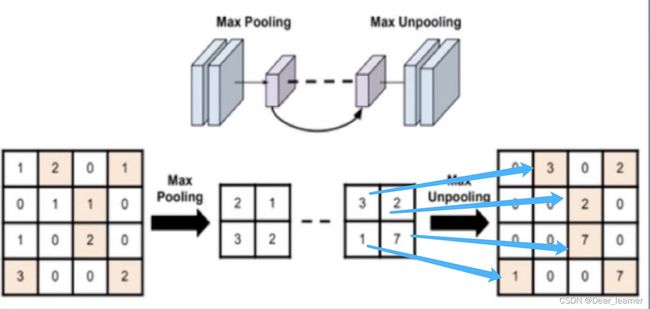
前面几个参数和卷积类似,最后一个参数常在最大值反池化的时候使用,返回的是滑动窗口中最大值所在位置的索引值,反最大值池化过程如下图所示:

左边图是4✖️4的图经过最大值池化后变为2✖️2,右边的图是反池化操作,将尺寸较小的图经过上采样变为尺寸较大的图,在反池化操作的过程中,小图中的值应该放到上采样后的图中的什么位置呢?这就需要最大值池化后的索引值,根据索引值将元素放到对应的位置,就得到了上图中最右边的图像。
下面来看一下最大值池化的效果:
# ================================= load img ==================================
path_img = os.path.join(os.path.dirname(os.path.abspath(__file__)), "lena.png")
img = Image.open(path_img).convert('RGB') # 0~255
# convert to tensor
img_transform = transforms.Compose([transforms.ToTensor()])
img_tensor = img_transform(img)
img_tensor.unsqueeze_(dim=0) # C*H*W to B*C*H*W
# ================ maxpool
flag = 1
# flag = 0
if flag:
maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2)) # input:(i, o, size) weights:(o, i , h, w)
img_pool = maxpool_layer(img_tensor)
# ================================= visualization ==================================
print("池化前尺寸:{}\n池化后尺寸:{}".format(img_tensor.shape, img_pool.shape))
img_pool = transform_invert(img_pool[0, 0:3, ...], img_transform)
img_raw = transform_invert(img_tensor.squeeze(), img_transform)
plt.subplot(122).imshow(img_pool)
plt.subplot(121).imshow(img_raw)
plt.show()
输出结果:
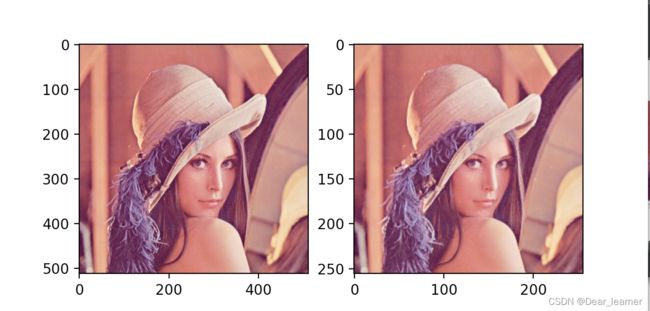
从输出的图像上基本看不出什么差别,但图像的尺寸减小了一半,因此池化层可以减小一些图像中的冗余信息。
2、nn.MaxUnpool2d

功能:对二维信号(图像)进行最大值池化上采样
参数:
kernel_size:池化核尺寸
stride:步长
padding:填充个数
这个参数和池化的类似,但在前向传播的时候需要传入indices,这个参数是指将输入的值放在上采样图片的哪个位置。
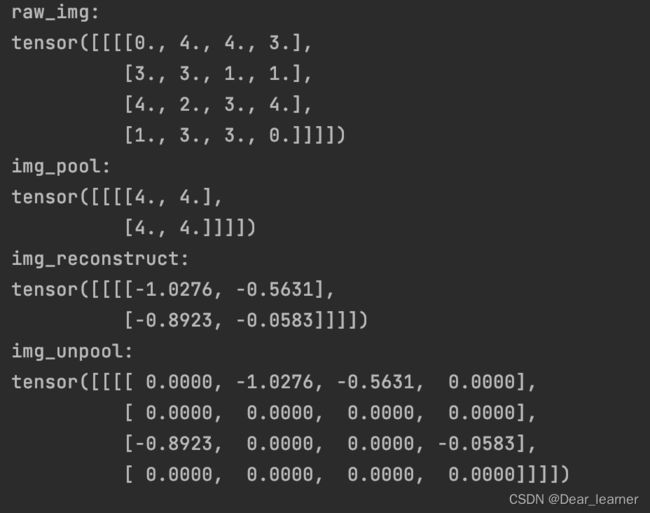
通过代码来看一下反池化操作的具体实现过程:
img_tensor = torch.randint(high=5, size=(1, 1, 4, 4), dtype=torch.float)
maxpool_layer = nn.MaxPool2d((2, 2), stride=(2, 2), return_indices=True)
img_pool, indices = maxpool_layer(img_tensor)
# unpooling
img_reconstruct = torch.randn_like(img_pool, dtype=torch.float)
maxunpool_layer = nn.MaxUnpool2d((2, 2), stride=(2, 2))
img_unpool = maxunpool_layer(img_reconstruct, indices)
print("raw_img:\n{}\nimg_pool:\n{}".format(img_tensor, img_pool))
print("img_reconstruct:\n{}\nimg_unpool:\n{}".format(img_reconstruct, img_unpool))
输出结果:
3、nn.AvgPool2d

功能:对二维信号(图像)进行平均值池化
参数:
count_include_pad: 填充值用于计算
divisor_override: 除法因子, 这个参数是求平均的时候那个分母,默认是有几个数相加就除以几,也可以通过这个参数设定
具体的实现过程:
img_tensor = torch.ones((1, 1, 4, 4))
avgpool_layer = nn.AvgPool2d((2, 2), stride=(2, 2), divisor_override=3) #求平均时分母为3
img_pool = avgpool_layer(img_tensor)
print("raw_img:\n{}\npooling_img:\n{}".format(img_tensor, img_pool))
输出结果:

二、线性层
线性层又称为全连接层,其每个神经元与上一层所有神经元相连,实现对前一层的线性组合,线性变换。
线性层的计算如下图所示:

每一层的输入是经过上一层的神经元的相乘相加得到,计算过程如下:

pytorch中代码的实现
nn.Linear(in_features, out_features, bias=True)
功能:对一维向量(信号)进行线性组合
参数:
- in_features: 输入节点数
- out_features: 输出节点数
- bias: 是否需要偏置,默认为True
计算公式:

inputs = torch.tensor([[1., 2, 3]])
linear_layer = nn.Linear(3, 4)
# 权值的初始化
linear_layer.weight.data = torch.tensor([[1., 1., 1.],
[2., 2., 2.],
[3., 3., 3.],
[4., 4., 4.]])
#偏置的初始化值
linear_layer.bias.data.fill_(0.5)
output = linear_layer(inputs)
print(inputs, inputs.shape)
print(linear_layer.weight.data, linear_layer.weight.data.shape)
print(output, output.shape)
输出结果:
