PyTorch学习笔记(4)卷积、池化、非线性激活
文章目录
-
- 基本骨架
- 卷积操作
- 卷积层
-
- Conv2d介绍
- 什么是输入通道?
- 代码案例
- 池化层
-
- MaxPool2d介绍
- 代码案例
- 实际应用
- 非线性激活
-
- ReLU
- Sigmoid
- 代码案例
- 线性层
- 参考
基本骨架
只需要继承 Module 类,再实现相应的方法即可。
这里实现了一个极简的神经网络,即对输入值加一再输出。
from torch import nn
import torch
#一个简单的神经网络
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
def forward(self,input):
output = input+1
return output
test = Test()
x = torch.tensor(1.0)
output = test.forward(x)
print(output)
卷积操作
这里用 nn.functional 实现最基本的卷积运算。
nn 中的大多数 layer 在functional中都有一个与之对应的函数。
nn.functional中的函数与nn.Module的区别是:
nn.Module实现的层(layer)是一个特殊的类,都是由class Layer(nn.Module)定义,会自动提取可学习的参数
nn.functional中的函数更像是纯函数,由def functional(input)定义。但在进行训练时,最好使用 nn.module,比较方便。
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
print(input)
# 卷积核
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
#升纬
print(input.shape)
print(kernel.shape)
#进行一次卷积运算
output = F.conv2d(input, kernel, stride=1)
print(output)
#二维卷积
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
卷积层
卷积层的作用是提取输入图片中的信息,这些信息被称为图像特征,这些特征是由图像中的每个像素通过组合或者独立的方式所体现,比如图片的纹理特征,颜色特征。
卷积层有很多卷积核,通过做越来越多的卷积,提取到的图像特征会越来越抽象。
Conv2d介绍
Conv2d()使用在二维输入,另外还有Conv1d()、Conv3d(),其输入分别是一维和三维。
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: _size_2_t,
stride: _size_2_t = 1,
padding: _size_2_t = 0,
dilation: _size_2_t = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros' # TODO: refine this type
)
常用参数如下:
- in_channels:网络输入的通道数。
- out_channels:网络输出的通道数。
- kernel_size:卷积核的大小,如果该参数是一个整数 3,那么卷积核的大小是 3*3。(具体数值根据一定的分布随机生成)
- stride:是卷积过程中移动的步长,默认情况下是1。
- padding:填充,默认是0填充。
什么是输入通道?
RGB 图像,为 R,G,B 三通道图像,通道数为 3,也就是说有三个二维矩阵,对应的卷积核输入通道数也要为 3,这样才能一一对应做卷积运算。
详情请看:
神经网络输入的通道数
关于卷积神经网络中的“输入通道”和“输出通道”的概念
代码案例
对 CIFAR10 数据集进行卷积操作,并用 tensorboard 进行显示。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torch.nn import Conv2d
from torch import nn
dataset = torchvision.datasets.CIFAR10("./dataset_CIFAR10",train=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=3,kernel_size=3,stride=1,padding=0)
# kernel_size表示卷积核的尺寸,3即3*3 卷积核随机生成
def forward(self,x):
x = self.conv1(x)
return x
writer = SummaryWriter("./logs")
step = 0
tudui = Tudui()
for data in dataloader:
imgs,targets = data
output = tudui.forward(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
# torch.Size([64, 3, 30, 30])
writer.add_images("input",imgs,step) # 一定要加s!!!!!!!!!!!!
writer.add_images("output",output,step)
step += 1
pass
writer.close()
池化层
池化层的作用是对卷积层中提取的特征进行挑选,常见的池化操作有最大池化和平均池化。
具体有以下几个作用:
-
挑选不受位置干扰的图像信息。
-
对特征进行降维,提高后续特征的感受野,也就是让池化后的一个像素对应前面图片中的一个区域。
-
因为池化层是不进行反向传播的,而且池化层减少了特征图的变量个数,所以池化层可以减少计算量。
通常来说,CNN的卷积层之间都会周期性地插入池化层。
详情请看:
卷积神经网络中卷积层、池化层、全连接层的作用
池化
MaxPool2d介绍
下采样,又称降采样。可理解为缩小图像,减少矩阵的采样点数。
上采样,又称插值。可理解为放大图像,增加矩阵的采样点数。
nn.MaxPool2d即是进行下采样操作(最大池化),nn.MaxUnpool2d做上采样。
常用参数:
- kernel_size :表示做最大池化的池化核大小。
- stride :步长,默认值是 kernel_size。
- padding :填充。
- dilation :控制元素步幅。
- ceil_mode :如果等于 True,计算输出时,会使用向上取整,代替默认的向下取整的操作。(即在池化核无法完全覆盖时,仍然保留该值)

代码案例
import torch
from torch.nn import Conv2d, MaxPool2d
from torch import nn
# 池化即取最大值 用来减小数据量
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]],dtype=torch.float)
# 1 1 分别表示 batch_size = 1 和 channels = 1
input = torch.reshape(input, (1, 1, 5, 5))
# 如果是(-1,1,5,5) -1 则表示自动计算
# input = torch.reshape(input, (1, 1, 5, 5))
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
tudui = Tudui()
output = tudui(input)
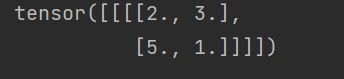
print(output)
做完一次最大池化后的结果:
实际应用
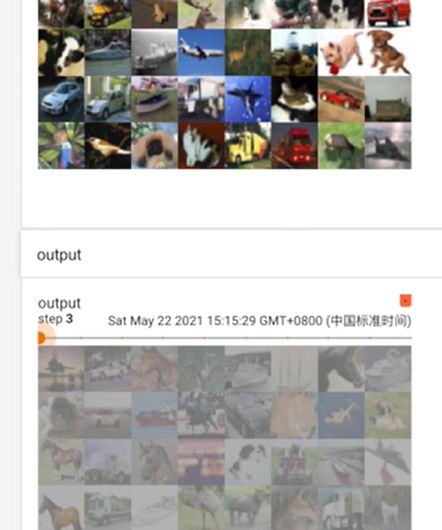
对 CIFAR10 的测试集进行最大池化处理,并用 tensorboard 进行展示。
import torch
import torch.nn.functional as F
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torch.nn import Conv2d, MaxPool2d
from torch import nn
# 最终效果图像 马赛克
dataset = torchvision.datasets.CIFAR10("./dataset_CIFAR10",train=False,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
writer = SummaryWriter("./logs")
step = 0
tudui = Tudui()
for data in dataloader:
imgs,targets = data
writer.add_images("max_input",imgs,step)
output = tudui(imgs)
writer.add_images("max_output",output,step)
step += 1
pass
writer.close()
可以明显看出有点马赛克的感觉,保留了一定的特征,数据量会大幅度减小。

非线性激活
比较常见的函数有两种:ReLU 和 Sigmoid。
目的:引入非线性特征,提高模型的泛化能力。
如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机(Perceptron)。如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
详情请看:非线性激活函数( Activation Function)
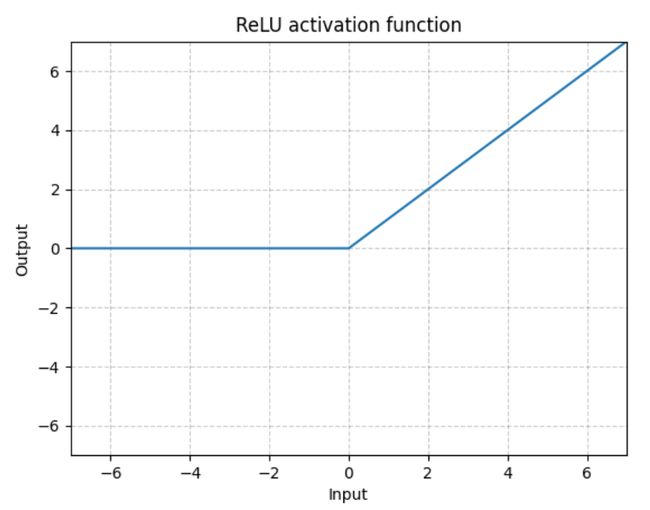
ReLU
大于 0 的值保留,小于 0 的截断为 0。
参数 inplace 是否更改原有变量。(一般不更改,这样还能查看原始数据)

Sigmoid
将值束缚在 0 到 1 的区间。
公式如下:
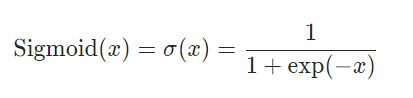
函数图像:

代码案例
import torch
import torch.nn.functional as F
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torch.nn import Conv2d, MaxPool2d, Sigmoid
from torch import nn
dataset = torchvision.datasets.CIFAR10("./dataset_CIFAR10",train=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.sigmoid1 = Sigmoid()
def forward(self,input):
output = self.sigmoid1(input)
return output
writer = SummaryWriter("./logs")
step = 0
tudui = Tudui()
for data in dataloader:
imgs,targets = data
writer.add_images("sig_input",imgs,step)
output = tudui(imgs)
writer.add_images("sig_output",output,step)
step += 1
pass
writer.close()
线性层
线性层即全连接层。每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
(例如在 VGG16 中,第一个全连接层有 4096 个节点,上一层 7x7x512 = 25088 个节点,则该传输需要 4096*25088 个权值,需要耗很大的内存。)
在图像分类中,经常使用全连接层输出每个类别的概率,也就是最后得到一个一维向量。
实际上就是乘一个权重矩阵,详情请看:
卷积神经网络(六)Linear 线性层但是乘多少次都是线性的,所以层与层之间还得加激活函数,这样才有非线性的性质,提高泛化的能力。

函数如下:
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
bias 表示要不要线性偏置。(ax+b中是否加b)
bias 是从分布中采样初始化,经过训练得最终结果的 。作为训练学习的参数之一,这是肯定得要的,否则结果很可能不理想。
具体参数理解请看:浅谈神经网络中的bias
import torch
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset_CIFAR10",train=False,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.linear1 = Linear(196608,10)
def forward(self,input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in dataloader:
imgs,targets = data
print(imgs.shape)
# torch.Size([64, 3, 32, 32])
output = torch.reshape(imgs,(1,1,1,-1))
print(output.shape)
# torch.Size([1, 1, 1, 196608]) 自动计算
output = tudui(output) # 该神经网络会将 196608 转为 10
print(output.shape)
# torch.Size([1, 1, 1, 10])
pass
当然也可以用 flatten() 直接变为一维的 196608。
output = torch.flatten(imgs)
参考
pytorch中nn.functional()学习总结
下采样与上采样
torch.nn.MaxPool2d详解