论文清单:一文梳理因果推理在自然语言处理中的应用
每天给你送来NLP技术干货!
©作者 | 肖之仪
单位 | 北京邮电大学
研究方向 | 因果推理、对话系统
来自 | PaperWeekly
这篇文章是由笔者根据自然语言顶级会议收录有关于因果推断的文献整理而成,内容包括论文的基本信息以及阅读笔记。

他山之石
1. Papers about Causal Inference and Language
https://github.com/causaltext/causal-text-papers
2. Causality for NLP Reading List
https://github.com/zhijing-jin/Causality4NLP_Papers
3. Causal Reading Group
https://github.com/fulifeng/Causal_Reading_Group
4. awesome-causality-algorithms
https://github.com/rguo12/awesome-causality-algorithms

因果工具
1. DoWhy: An end-to-end library for causal inference
https://microsoft.github.io/dowhy/#dowhy-an-end-to-end-library-for-causal-inference
2. Causal ML: A Python Package for Uplift Modeling and Causal Inference with ML
https://github.com/uber/causalml
3. pgmpy: Python Library for learning (Structure and Parameter), inference (Probabilistic and Causal), and simulations in Bayesian Networks.
https://github.com/pgmpy/pgmpy
4. CausalNex: A Python library that helps data scientists to infer causation rather than observing correlation.
https://github.com/quantumblacklabs/causalnex
5. CausalImpact: An R package for causal inference in time series
https://github.com/google/CausalImpact
6. CausalDiscoveryToolbox: Package for causal inference in graphs and in the pairwise settings. Tools for graph structure recovery and dependencies are included.
https://github.com/FenTechSolutions/CausalDiscoveryToolbox
7. causal-learn: Causal Discovery for Python
https://github.com/cmu-phil/causal-learn

数据集
e-CARE: a New Dataset for Exploring Explainable Causal Reasoning
https://arxiv.org/abs/2205.05849
https://github.com/waste-wood/e-care
数据集概览:

数据集示例:


综述类文章
A Review of Dataset and Labeling Methods for Causality Extraction
https://aclanthology.org/2020.coling-main.133
文献贡献总结如下:
1. 总结了因果关系的关系的概念并介绍了现有因果关系挖掘的工作;
2. 针对现有因果关系实验数据的缺陷和不足,对公开可用的数据集进行了总结,并从多个方面进行了分析;
3. 对现有针对序列标记的因果研究方法(the causal research method of sequence labeling)进行了全面的总结和分析。
值得关注的是,作者在文中对因果关系的语义作了相应的定义与介绍,文献中将因果单元(causal units)定义为以下四类,例子中的〈 e1 〉表示原因,〈 e2〉表示结果:
Word:「〈 e1 〉 Suicide 〈 /e1 〉 is one of the leading causes of 〈 e2 〉 death 〈 /e2 〉 .」
Phrase:「 〈 e1 〉 Financial stress 〈 /e1 〉 is one of the main causes of 〈 e2 〉 divorce 〈 /e2 〉.」
Clause:「〈 e1 〉 We play with a steady beat 〈 /e1 〉 so that 〈 e2 〉 dancers can follow it 〈 /e2 〉.」
Event:「〈 e1 〉 A car traveling from Guizhou to Guangdong collided head-on with a bus 〈 /e1 〉 results the 〈 e2 〉 ten people, six men and four women, including the driver, died at the scene 〈 /e2 〉 .」
同时作者也总结了在英文语境相下具有因果关系的连接词,如下表所示:

▲ Summary of common causal connectives in English
Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond
https://arxiv.org/abs/2109.00725
该综述文献将自然语言处理与因果关系的结合点划分成两个不同的研究方向,分别是因果效应评估(estimating causal effects)和因果关系驱动的自然语言处理方法。
文献概述如下:
1. 不同类型的因果推理问题及其挑战;
2. 面向文本数据和 NLP 方法所独有的统计和因果挑战;
3. 应用因果关系改进自然语言处理方法和文本效果估计中存在的问题。

在NLP任务建模种融合因果关系
Uncovering Main Causalities for Long-tailed Information Extraction (EMNLP 2021)
场景:Information Extraction
问题:由数据集的选择偏移带来的长尾分布可能会对数据集产生不正确的关联关系
https://arxiv.org/abs/2109.05213
https://github.com/HeyyyyyyG/CFIE
信息抽取旨在从非结构化的文本中提取出结构化的信息。在实际场景下,数据集由选择偏移带来的长尾分布可能会使得模型习得一些可疑的关联关系。
本文献提出的 CFIE 拟解决上述问题,具体贡献如下:
1. 对多种信息抽取任务(RE,NER 和 ED )构建统一的结构因果模型(structural causal model)并描述不同变量之间的因果关系;
2. 基于上述的结构因果模型,使用相应的语言结构生成反事实样本,以此在推理阶段更好的计算直接因果效应(direct causal effect);
3. 文献进一步提出一种消除偏倚的方法以提供更具鲁棒性的预测。

▲ Training and inference stages of CFIE for ED

▲ Causal effect estimation
CFIE 的模型设计如上图所示,分成如下五个步骤:
1. 构造 SCM 并训练模型;
2. 预测每个 token 结果;
3. 沿着 1st hop 语法书给 token 加上 mask 以此生成反事实的样本;
4. 计算 Total Direct Effect;
5. 计算 Main Effect。
Counterfactual Generator: A Weakly-Supervised Method for Named Entity Recognition (EMNLP 2020)
场景:命名实体识别
问题:命名实体识别的数据标注是一项劳动密集性、耗时且昂贵的任务且「实体」的上下文本和实体之间有许多可疑的关联关系
https://aclanthology.org/2020.emnlp-main.590.pdf
https://github.com/xijiz/cfgen
论文主要贡献如下:
1. 基于因果关系的视角描述了 NER 模型推断机制的理论基础,研究了模型输入特征与输出标签之间存在的可疑的关联关系;
2. 在对实体进行干预的基础上,论文在有限的观测样本中提出了一种弱监督的命名实体识别方法,在多个 NER 数据集上证明了方法能有效的提升模型性能。

▲ Structural Causal Models (SCMs) that describes the mechanism of the NER model inference.
作者为 NER 模型的推理机制构建了相应的 SCM 并以 DAG 的形式可视化,其中结点 G 表示混杂因子——既影响了实体结点 E的同时也影响了上下文结点 C,结点 X 则代表了由结点 E 和 C 所生成的输入实例,结点 Y 是 NER 模型的评估指标,如 F1 值。
作者通过平均因果效应 ACE(Average Causal Effect)来评估干预后的 treatment effect,值得注意的是上图中的 (b) 与 (c) 分别表示对上下文和实体进行干预,作者设计了一个新的评估指标—— RI(Relative Importance)来评估上下文和实体的表示对于 NER 模型推理阶段的重要性,在后续的实验分析模块,作者得出的结论是实体的表示对 NER 模型的推理更重要。

▲ An example of the workflow of the Counterfactual Generator on the medical dataset.
论文中的模型的流程如上图所示,分成三个步骤:
1. 从已有的本地数据中抽出实体集合;
2. 从实体集合中选取与待干预样本实体相同类别的实体进行替换从而生成反事实样本;
3. 通过使用原始数据训练的辨别器(discriminator)分辨新生成的反事实样本是否合理,若合理则将该样本加入到已有数据集内。
Counterfactual Off-Policy Training for Neural Dialogue Generation (EMNLP 2020)
场景:开放域对话生成
问题:由于潜在可能的回应数量过于庞大,开放域对话生成往往处于数据集不足的问题。
https://arxiv.org/abs/2004.14507
论文主要贡献如下:
1. 以「结构因果模型」对「对话生成模型」建模,从而在「对话生成模型」中融合「反事实推理」;
2. 论文中提出的模型所生成的反事实回应相较于其他标准的基于对抗学习从头开始生成的回应的质量要高得多;
3. 论文提出的方法与模型无关(model-agnostic),因此可以适配与任何基于对抗学习的对话生成模型。

▲ An example of generated responses given dialogue history between person A and B.
文中提出的「counterfactual off-policy training (COPT) approach」步骤如下:
1. 构造生成式对话模型的 SCM,将其描述为两个组成部分即——场景(scenarios)和因果机制(causal mechanisms);
2. 给出观测回复数据中推断的场景,COPT 将场景(scenario)以及对话历史(dialogue history)根据 SCM 生成相应的反事实回复;
3. 判别器评估生成的语句,并将相应的 reward 返还给第二步的生成器。

▲ An example of an SCM and an intervention.

▲ The architecture of our COPT approach.
Identifying Spurious Correlations for Robust Text Classification (EMNLP Findings 2020)
场景:文本分类
问题:文本分类器通常依赖于可疑的关联关系,通常这部分关系不会影响模型最终的准确性,因为关联关系同时出现在训练集和测试集中。但在测试集和训练集分布不同(dataset shift) 和 训练测试集只在小部分样本(algorithmic fairness)的情况下会影响模型准确性。
https://aclanthology.org/2020.findings-emnlp.308
https://github.com/tapilab/emnlp-2020-spurious
作者对一个电影评论数据集 [7] 使用词袋模型逻辑回归分类器,通过观测每个单词的系数可以评估该单词对文本模型的重要程度。

▲ Motivating example of spurious and genuine correlations in a sentiment classification task.
在上图中,作者展示了八个与模型高度匹配的词汇,其中类别 1 代表正向情感,类别 2 则表示负向情感。
不难发现,在正向情感方面,「spielberg」与「animated」看上去较为可疑,作者认为「spielberg」是一名非常成功的电影导演,在数据集中提及到他的电影评论往往是正向的,因此模型认为「spielberg」与正向情感强相关,但作者认为「spielberg」这个单词本身不应当是电影评论被判定为正向情感的原因,举个很简单的例子,倘若有一天导演拍摄了一部新片但口碑却不尽如人意,含有这类可疑的关联关系的模型则会误判评论。
因此,本文提出了一个监督文本分类方法旨在认出文本分类中的伪相关性和真相关性,文章提出的方法如下:
1. 用原始数据集训练分类器 f;
2. 从分类器 f 中提取出与每个类别强相关的若干个词汇;
3. 对前序步骤提取出来的每个词汇计算其真实或可疑的可能值;
4. 对第二步产生词汇的子集进行人工标注,并训练成词汇分类器 h;
5. 应用 h 标注剩余的单词去评估他们是否可疑。

对语言模型进行因果分析
Causal Analysis of Syntactic Agreement Mechanisms in Neural Language Models (ACL 2021)
场景:Syntactic Agreement Mechanisms
https://arxiv.org/abs/2106.06087
https://github.com/mattf1n/lm-intervention
作者想应用因果中介分析(causal mediation analysis)来观察预训练语言模型在「主谓一致」上的表现,探讨对不同的语法结构来说,语言模型中的的哪个神经元负责判断判断「主谓一致」。


因果关系挖掘
Everything Has a Cause: Leveraging Causal Inference in Legal Text Analysis (NAACL 2021)
场景:法律文本分析(Legal Text Analysis)
问题:现有的因果推断研究大多关注结构化数据,在类似法律文本这样的非结构化数据较少被关注。
https://arxiv.org/abs/2104.09420
https://github.com/xxxiaol/GCI/

▲ An example of generated causal graph for the charge fraud.
因果推理可以捕捉不同变量之间的因果关系,大多数现有工作专注于解决结构化数据,而从非结构化数据中挖掘因果关系则鲜少有学者涉足,本文献提出了一个全新的基于图的因果推断框架 CGI(Graph-based Causal Inference)——不用人为介入即可通过事实描述构造因果图,以此辅助法律从业者作出更好的判断。
文献通过「近似指控消歧」(similar charge disambiguation)任务来评估框架的性能,实验结果验证 GCI 不仅能够在多个近似指控的事实描述中捕捉细微差别,而且能提供解释性判决,在小样本的实验环境下 CGI 的表现优异。除此之外, CGI 中所包含的因果知识能够有效地与神经网络相结合,以此提供更好的性能和可解释性。
一言以蔽之,文献的主要贡献如下所示:
1. 文献提出了一个新的基于图的因果推断框架,可以自动地对非结构化数据进行因果推断;
2. 文献将 GCI 框架所得出的因果知识与神经网络相结合;
3. 文献通过「近似指控消岐」任务验证了 CGI 能从法律文本中捕捉到细微差别,且它能够进一步提升神经网络的可解释性。

▲ Overall architecture of GCI.
本文献提出的 GCI 模型通过Yake [10] ——一种基于文本特征全自动的提取文本关键字的方法从法律文本数据集中提取相应的关键因子,进而使用 GFCI(Greedy Fast Causal Inference)算法对上述步骤提取出来的关键因子进行因果发现,因为 GFCI 算法产出的结果是部分有向无环图而文本,而因果关系图应当是有向无环图,因此文献下一部对 PAG 进行采样并使用 ATE 来评估因果强度,最终得到一个 DAG 分类器。

▲ Two ways of integrating causal analysis and neural networks.
文献通过两种方式将因果发现的结果应用至神经网络,第一种是将因果强度限制 Attention 的权重,第二种将有向无环图拆解成若干因果链并作为 LSTM 的输入。

因果常识推理及其生成
Guided Generation of Cause and Effect (IJCAI 2020)
场景:文本生成
问题:对于各种人工智能任务来说,因果知识的习得至关重要,例如:因果图的构建、阅读理解和事件预测。
https://arxiv.org/abs/2107.09846
https://github.com/eecrazy/CausalBank
论文作出如下贡献:
1. 提出了开放式因果生成的任务:对任意格式的文本生产出其可能的原因与结果;
2. 构造了因果数据集 CausalBank,其包含有 3.14 亿个因果对(cause-effect pairs);
3. 拓展了词法限制的解码(lexically-constrained decoding),使其支持析取正向约束(disjunctive positive constraints)。

▲ Possible causes and effects generated by our model, conditioned on the input sentence “babies cry”.

▲ Our approach for generating plausible causes and effects
GLUCOSE: GeneraLized and COntextualized Story Explanations (EMNLP 2020)
场景:常识推理
问题:AI 系统能无法拥有常识推理的能力是因为有两个瓶颈:一是很难大规模的获得常识数据集,二是如何将常识融合至现有 AI 系统。
https://arxiv.org/abs/2009.07758
https://github.com/ElementalCognition/glucose/
文献介绍了 GLUCOSE 数据集,当给出一则短故事和故事中的一个句子 X,GLUCOSE 从十个维度会捕捉与 X 相关的因果解释。
这十个维度启发于人类认知心理学,覆盖了 X 通常隐含的原因和结果,如:事件、地点、所有物等等。

▲ Entries in the GLUCOSE dataset that explain the Gage story around the sentence X= Gage turned his bike sharply.
Counterfactual Story Reasoning and Generation (EMNLP 2019)
场景:反事实推理
问题:对于 AI 完备的系统来说,拥有反事实推理能力是一个充要条件,即当实际发生的事情改变时,模型能给出相应的结果。
https://arxiv.org/abs/1909.04076
https://github.com/qkaren/Counterfactual-StoryRW
在文献中,作者提出了一个新的任务,即基于故事理解和生成的反事实故事重写(Counterfactual Story Rewriting)。
任务的输入是原始故事和反事实条件,模型需要通过反事实推理重写故事以保证逻辑的一致性。
举个例子,如下图所示,左侧提供了原始故事版本,Pierre 喜欢万圣节,想要在万圣节扮演吸血鬼,因此他准备了相应的打扮,但假设 Pierre 想要扮演的是狼人,通过反事实推理,我们知道接下里的故事内容要于狼人相符。
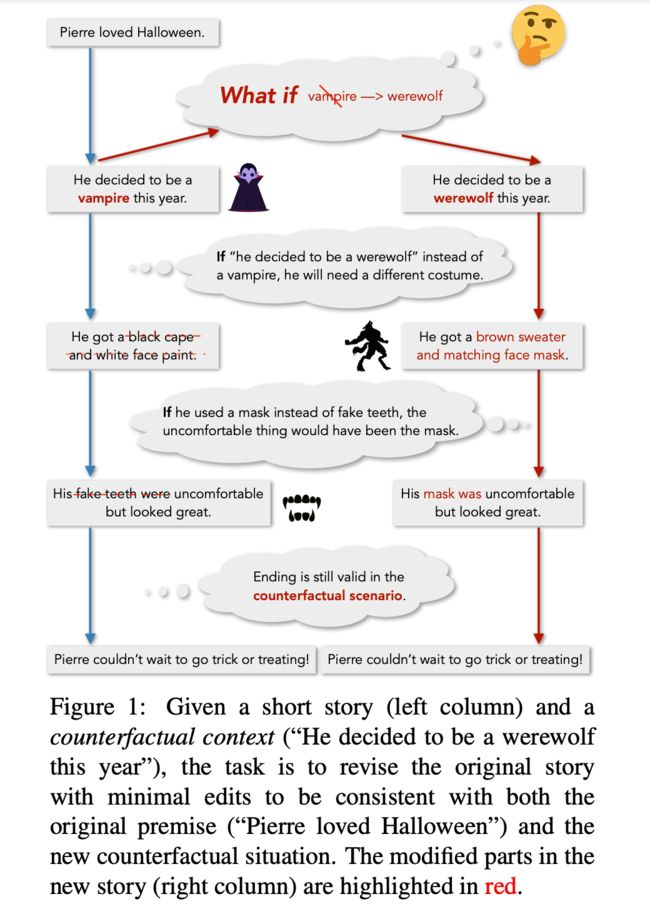
文献提出了 TIMETRAVEL 数据集,拥有 29849 个反事实事例,下图是数据集的标注过程。

▲ Data annotation process for the TIMETRAVEL dataset.

参考文献
[1] A Review of dataset and labeling methods for causality extraction https://aclanthology.org/2020.coling-main.133/
[2] Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond https://arxiv.org/abs/2109.00725
[3] Uncovering Main Causalities for Long-tailed Information Extraction https://arxiv.org/abs/2109.05213
[4] Counterfactual Generator: A Weakly-Supervised Method for Named Entity Recognition https://aclanthology.org/2020.emnlp-main.590/#
[5] Counterfactual Off-Policy Training for Neural Dialogue Generation https://aclanthology.org/2020.emnlp-main.276/
[6] Identifying Spurious Correlations for Robust Text Classification https://arxiv.org/pdf/2010.02458.pdf
[7] Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales https://aclanthology.org/P05-1015/
[8] Causal Analysis of Syntactic Agreement Mechanisms in Neural Language Models https://arxiv.org/abs/2106.06087
[9] Everything Has a Cause: Leveraging Causal Inference in Legal Text Analysis https://arxiv.org/abs/2104.09420
[10] Yake https://github.com/LIAAD/yake
[11] Guided Generation of Cause and Effect https://www.ijcai.org/Proceedings/2020/0502.pdf
[12] GLUCOSE: GeneraLized and COntextualized Story Explanations https://arxiv.org/pdf/2009.07758.pdf
[13] Counterfactual Story Reasoning and Generation https://arxiv.org/pdf/1909.04076.pdf
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
为什么回归问题不能用Dropout?
Bert/Transformer 被忽视的细节
中文小样本NER模型方法总结和实战
一文详解Transformers的性能优化的8种方法
DiffCSE: 将Equivariant Contrastive Learning应用于句子特征学习
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注~