CV+Deep Learning——网络架构Pytorch复现系列——Detection(一:SSD:Single Shot MultiBox Detector 3.loss)
上一话
CV+Deep Learning——网络架构Pytorch复现系列——Detection(一:SSD:Single Shot MultiBox Detector 2.anchor) https://blog.csdn.net/XiaoyYidiaodiao/article/details/126418875?spm=1001.2014.3001.5502
https://blog.csdn.net/XiaoyYidiaodiao/article/details/126418875?spm=1001.2014.3001.5502
复现Object Detection,会复现的网络架构有:
1.SSD: Single Shot MultiBox Detector(√)
2.RetinaNet
3.Faster RCNN
4.YOLO系列
....
代码:
https://github.com/HanXiaoyiGitHub/Simple-CV-Pytorch-master.githttps://github.com/HanXiaoyiGitHub/Simple-CV-Pytorch-master.git
1.复现SSD
1.3Loss
要弄明白Loss,则需要理解Loss中的一些函数:encode,decode,point_form,center_size,intersect,jaccard,match, hard_negative_mining,log_sum_exp。
1.3.1encode编码
概述:利用ground truth(match)与生成的anchor产生预测的offset。
参数:
真实值 ![]()
先验框 ![]()
调节误差 ![]()
返回:
预测的offset![]()
程序:
![]()
![]()
![]()
![]()
代码
def encode(matched, anchors, variances):
"""
matched: (tensor) Coords of ground truth for each anchor in point-form, Shape: [num_anchors,4].
anchors: (tensor) Anchor boxes in center-offset form, Shape: [num_anchors,4].
variances: (list[float]) Variances of anchor boxes
:return:
encoded boxes (tensor), Shape:[num_anchors,4]
"""
# dist b/t match center and prior's center
g_cxcy = (matched[:, :2] + matched[:, 2:]) / 2 - anchors[:, :2]
# encode variance
# shape [num_anchors,2]
g_cxcy /= (variances[0] * anchors[:, 2:])
eps = 1e-5
# match wh /anchor wh
g_wh = (matched[:, 2:] - matched[:, :2]) / anchors[:, 2:]
g_wh = torch.log(g_wh + eps) / variances[1]
# return target for smooth_L1_loss
# [num_anchors,4]
return torch.cat([g_cxcy, g_wh], 1)1.3.2decode解码
概述:预测值loc与生成的anchor产生计算出的边界框真实值。
参数:
预测值![]()
先验框![]()
调节误差![]()
返回:
计算出的边界框真实值![]()
程序:
![]()
![]()
![]()
![]()
代码
def decode(loc, anchors, variances):
boxes = torch.cat((anchors[:, :2] + loc[:, :2] * variances[0] * anchors[:, 2:],
anchors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
boxes = point_form(boxes)
return boxes1.3.3point_form位置转换
概述:将![]() 转化为
转化为![]()
参数:
![]()
返回:
![]()
程序:
![]()
![]()
![]()
![]()
代码
def point_form(boxes):
"""
(cx,cy,w,h) -> (xmin,ymin,xmax,ymax)
boxes: (tensor) center-size default boxes from anchor layers.
:return:
(tensor) Converted xmin,ymin,xmax,ymax form of boxes.
"""
return torch.cat((boxes[:, :2] - boxes[:, 2:] / 2,
boxes[:, :2] + boxes[:, 2:] / 2), 1)1.3.4center_size位置转换
概述:将![]() 转化为
转化为![]()
参数:
![]()
返回:
![]()
程序:
![]()
![]()
![]()
![]()
代码
def center_size(boxes):
"""
(xmin,ymin,xmax,ymax) -> (cx,cy,w,h)
"""
return torch.cat((boxes[:, :2] + boxes[:, 2:]) / 2,
(boxes[:, 2:] - boxes[:, :2]), 1)1.3.5intersect(交集)
概述:如图 1Intersect计算的是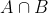 的面积。AB点右下角的最小值max_xy,AB点左上角的最大值min_xy,用torch.clamp来计算交集inter,返回inter面积。
的面积。AB点右下角的最小值max_xy,AB点左上角的最大值min_xy,用torch.clamp来计算交集inter,返回inter面积。
参数:
![]()
![]()
返回:
inter的面积:![]()
程序:
AB点右下角的最小值max_xy,AB点左上角的最大值min_xy,计算min_xy与max_xy的交集(torch.clamp)inter,计算inter的面积![]()
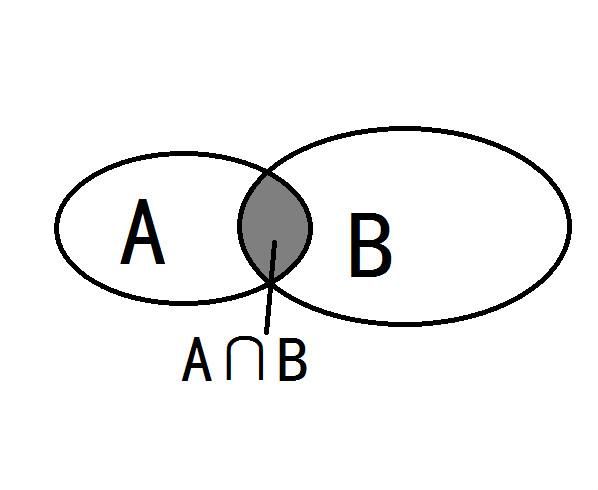 图 1
图 1
代码
def intersect(box_a, box_b):
"""
We resize both tensors to [A, B, 2] without new malloc:
[A,2] -> [A,1,2] -> [A,B,2]
[B,2] -> [1,B,2] -> [A,B,2]
box_a: (tensor) bounding boxes, Shape: [A, 4].
box_b: (tensor) bounding boxes, Shape: [B, 4].
:return:
(tensor) intersection area, Shape: [A, B].
"""
A = box_a.size(0)
B = box_b.size(0)
# RB
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
# LT
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
box_b[:, :2].unsqueeze(0).expand(A, B, 2))
inter = torch.clamp((max_xy - min_xy), min=0)
return inter[:, :, 0] * inter[:, :, 1]1.3.6jaccard(IoU)
概述:如图 2为IoU计算的示意图。
参数:
![]()
![]()
返回:
![]()
程序:
首先用1.3.5的算法计算![]() 与
与![]() 的交集,再接着计算
的交集,再接着计算![]() 的宽和高以此来计算
的宽和高以此来计算 面积,与计算
面积,与计算![]() 的宽和高以此来计算
的宽和高以此来计算 的面积,最后算出
的面积,最后算出![]()
 图 2
图 2
代码
def jaccard(box_a, box_b):
"""
A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
box_a: (tensor) Ground truth bounding boxes, Shape: [num_obj, 4]
box_b: (tensor) Anchor boxes from anchor layers, Shape: [num_obj, 4]
:return:
jaccard overlap: (tensor) Shape: [box_a.size(0), box_b.size(0)]
"""
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2] - box_a[:, 0]) *
(box_a[:, 3] - box_a[:, 1])).unsqueeze(1).expand_as(inter)
area_b = ((box_b[:, 2] - box_b[:, 0]) *
(box_b[:, 3] - box_b[:, 1])).unsqueeze(0).expand_as(inter)
union = area_a + area_b - inter
return inter / union
1.3.7match
概述:给图像中每个像素点,要么标注成背景,要么关联上一个ground truth (label) bbox 。
参数:
threshold: 每个像素点的conf小于一定的阈值就为背景,否则为前景
truths: Ground truth boxes
priors: 产生的anchor boxes
variances: 调节误差的偏移值
labels: 一张图像中的Ground truth label
loct: 每个像素匹配的(编码产生的)坐标
conft: 每个像素匹配的(预测产生的)置信度阈值
idx: 一张图像的index
返回:
无
程序:
首先利用之前的IoU函数计算出ground truth bboxes 与anchor (prior) bboxes的IoU,再将IoU按照anchor(prior)的从大到小排序并将其压缩,也将IoU按照truth的从大到小排序并将其压缩。若best_truth_idx[best_prior_idx[j]]=j,则开始匹配每个像素点match,阈值conf label+1(因为背景为0,前景从1开始计算),若阈值conf小于阈值threshold当成背景,再用match与anchor的编码得到(每张图像的loc)预测的offset,得到每张图像的conf。
代码
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
"""Match each prior box with the ground truth box of the highest jaccard
overlap, encode the bounding boxes, then return the matched indices
corresponding to both confidence and location preds.
Args:
threshold: (float) The overlap threshold used when mathing boxes.
truths: (tensor) Ground truth boxes, Shape: [num_obj, num_priors].
priors: (tensor) Prior boxes from priorbox layers, Shape: [n_priors,4].
variances: (tensor) Variances corresponding to each prior coord,
Shape: [num_priors, 4].
labels: (tensor) All the class labels for the image, Shape: [num_obj].
loc_t: (tensor) Tensor to be filled w/ endcoded location targets.
conf_t: (tensor) Tensor to be filled w/ matched indices for conf preds.
idx: (int) current batch index
Return:
The matched indices corresponding to 1)location and 2)confidence preds.
"""
# jaccard index
overlaps = jaccard(
truths,
point_form(priors)
)
# (Bipartite Matching)
# [1,num_objects] best prior for each ground truth
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
# [1,num_priors] best ground truth for each prior
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
best_truth_idx.squeeze_(0)
best_truth_overlap.squeeze_(0)
best_prior_idx.squeeze_(1)
best_prior_overlap.squeeze_(1)
best_truth_overlap.index_fill_(0, best_prior_idx, 2) # ensure best prior
# TODO refactor: index best_prior_idx with long tensor
# ensure every gt matches with its prior of max overlap
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
matches = truths[best_truth_idx] # Shape: [num_priors,4]
conf = labels[best_truth_idx] + 1 # Shape: [num_priors]
conf[best_truth_overlap < threshold] = 0 # label as background
loc = encode(matches, priors, variances)
loc_t[idx] = loc # [num_priors,4] encoded offsets to learn
conf_t[idx] = conf # [num_priors] top class label for each prior1.3.8hard_negative_mining
概述:困难负样本挖掘算法
参数:
loss: 每个样本的loss
labels: 标签
neg_pos_ratio: 负正样本比,一般为3
返回:正样本 | 负样本
程序:利用labels>0取出pos_mask,计算pos的个数,再通过pos的个数计算neg的个数(pos*neg_pos_ratio),再排除所有的正样本的loss,取负样本的所有loss,在对所有的负样本进排序选择前num_neg个负样本,最后返回 正样本 | 负样本
代码
def hard_negative_mining(loss, labels, neg_pos_ratio):
"""
It used to suppress the presence of a large number of negative prediction.
It works on image level not batch level.
For any example/image, it keeps all the positive predictions and
cut the number of negative predictions to make sure the ratio
between the negative examples and positive examples is no more
the given ratio for an image.
Args:
loss (N, num_priors): the loss for each example.
labels (N, num_priors): the labels.
neg_pos_ratio: the ratio between the negative examples and positive examples.
"""
pos_mask = labels > 0
num_pos = pos_mask.long().sum(dim=1, keepdim=True)
num_neg = num_pos * neg_pos_ratio
loss[pos_mask] = -math.inf
_, indexes = loss.sort(dim=1, descending=True)
_, orders = indexes.sort(dim=1)
neg_mask = orders < num_neg
return pos_mask | neg_mask1.3.9log_sum_exp
概述: log_sum_exp相当于使用(import torch.nn.funcational as F)F.log_softmax
参数:
x来自conf layers的 预测的置信度conf
返回:
torch.log(torch.sum(torch.exp((x-x_max),1,keepdim=True)+x_max
代码
def log_sum_exp(x):
"""Utility function for computing log_sum_exp while determining
This will be used to determine unaveraged confidence loss across
all examples in a batch.
Args:
x (Variable(tensor)): conf_preds from conf layers
"""
x_max = x.data.max()
return torch.log(torch.sum(torch.exp(x - x_max), 1, keepdim=True)) + x_maxnms可用torchvision.ops.nms代替。
Loss完整代码
首先看看版本一的代码,再对比版本二的代码,就能理解版本二的代码了。
版本一
import torch.nn as nn
import torch.nn.functional as F
import torch
from ssd.utils import box_utils
class MultiBoxLoss(nn.Module):
def __init__(self, neg_pos_ratio):
"""Implement SSD MultiBox Loss.
Basically, MultiBox loss combines classification loss
and Smooth L1 regression loss.
"""
super(MultiBoxLoss, self).__init__()
self.neg_pos_ratio = neg_pos_ratio
def forward(self, confidence, predicted_locations, labels, gt_locations):
"""Compute classification loss and smooth l1 loss.
Args:
confidence (batch_size, num_priors, num_classes): class predictions.
predicted_locations (batch_size, num_priors, 4): predicted locations.
labels (batch_size, num_priors): real labels of all the priors.
gt_locations (batch_size, num_priors, 4): real boxes corresponding all the priors.
"""
num_classes = confidence.size(2)
with torch.no_grad():
# derived from cross_entropy=sum(log(p))
loss = -F.log_softmax(confidence, dim=2)[:, :, 0]
mask = box_utils.hard_negative_mining(loss, labels, self.neg_pos_ratio)
confidence = confidence[mask, :]
classification_loss = F.cross_entropy(confidence.view(-1, num_classes), labels[mask], reduction='sum')
pos_mask = labels > 0
predicted_locations = predicted_locations[pos_mask, :].view(-1, 4)
gt_locations = gt_locations[pos_mask, :].view(-1, 4)
smooth_l1_loss = F.smooth_l1_loss(predicted_locations, gt_locations, reduction='sum')
num_pos = gt_locations.size(0)
return smooth_l1_loss / num_pos, classification_loss / num_pos版本二
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from models.detection.SSD.utils.box_utils import match, log_sum_exp
class MultiBoxLoss(nn.Module):
"""SSD Weighted Loss Function
Compute Targets:
1) Produce Confidence Target Indices by matching ground truth boxes
with (default) 'priorboxes' that have jaccard index > threshold parameter
(default threshold: 0.5).
2) Produce localization target by 'encoding' variance into offsets of ground
truth boxes and their matched 'priorboxes'.
3) Hard negative mining to filter the excessive number of negative examples
that comes with using a large number of default bounding boxes.
(default negative:positive ratio 3:1)
Objective Loss:
L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
Where, Lconf is the CrossEntropy Loss and Lloc is the SmoothL1 Loss
weighted by α which is set to 1 by cross val.
Args:
c: class confidences,
l: predicted boxes,
g: ground truth boxes
N: number of matched default boxes
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
"""
def __init__(self, num_classes,
overlap_thresh,
neg_pos,
neg_overlap,
neg_mining=True,
bkg_label=0,
prior_for_matching=True,
encode_target=False,
use_gpu=True):
super(MultiBoxLoss, self).__init__()
self.num_classes = num_classes
self.threshold = overlap_thresh
self.negpos_ratio = neg_pos
self.neg_overlap = neg_overlap
self.do_neg_mining = neg_mining
self.background_label = bkg_label
self.use_prior_for_matching = prior_for_matching
self.encode_target = encode_target
self.use_gpu = use_gpu
self.variance = [0.1, 0.2]
def forward(self, predictions, targets):
"""Multibox Loss
Args:
predictions (tuple): A tuple containing loc preds, conf preds,
and prior boxes from SSD net.
conf shape: torch.size(batch_size,num_priors,num_classes)
loc shape: torch.size(batch_size,num_priors,4)
priors shape: torch.size(num_priors,4)
targets (tensor): Ground truth boxes and labels for a batch,
shape: [batch_size,num_objs,5] (last idx is the label).
"""
loc_data, conf_data, priors = predictions
num = loc_data.size(0)
priors = priors[:loc_data.size(1), :]
num_priors = (priors.size(0))
num_classes = self.num_classes
# match priors (default boxes) and ground truth boxes
loc_t = torch.Tensor(num, num_priors, 4)
conf_t = torch.LongTensor(num, num_priors)
for idx in range(num):
truths = targets[idx][:, :-1].data
labels = targets[idx][:, -1].data
defaults = priors.data
match(self.threshold, truths, defaults, self.variance, labels,
loc_t, conf_t, idx)
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
# wrap targets
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t, requires_grad=False)
pos = conf_t > 0
num_pos = pos.sum(dim=1, keepdim=True)
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, reduction='sum')
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.view(-1, self.num_classes)
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# Hard Negative Mining
loss_c = loss_c.view(num, -1)
loss_c[pos] = 0 # filter out pos boxes for now
loss_c = loss_c.view(num, -1)
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio * num_pos, max=pos.size(1) - 1)
neg = idx_rank < num_neg.expand_as(idx_rank)
# Confidence Loss Including Positive and Negative Examples
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[(pos_idx + neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos + neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, reduction='sum')
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
N = num_pos.data.sum().float()
loss_l /= N
loss_c /= N
return loss_l, loss_c
if __name__ == '__main__':
from options.detection.SSD.train_options import cfg
loss = MultiBoxLoss(num_classes=cfg['DATA']['NUM_CLASSES'],
overlap_thresh=cfg['TRAIN']['MATCH_THRESH'],
neg_pos=cfg['TRAIN']['NEG_POS'],
neg_overlap=cfg['TRAIN']['NEG_THRESH'],
use_gpu=False)
p = (torch.randn(1, 100, 4), torch.randn(1, 100, 21), torch.randn(100, 4))
t = torch.randn(1, 10, 4)
tt = torch.randint(20, (1, 10, 1))
t = torch.cat((t, tt.float()), dim=2)
l, c = loss(p, t)
# loc loss: tensor(16.7761)
# conf loss: tensor(19.0522)
print("loc loss:", l)
print("conf loss:", c)loss的结果
loc loss: tensor(16.7761)
conf loss: tensor(19.0522)下一话
CV+Deep Learning——网络架构Pytorch复现系列——Detection(一:SSD:Single Shot MultiBox Detector 4.推理Detect) https://blog.csdn.net/XiaoyYidiaodiao/article/details/128683973?spm=1001.2014.3001.5501
https://blog.csdn.net/XiaoyYidiaodiao/article/details/128683973?spm=1001.2014.3001.5501
参考文献
[1] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.