基于深度学习的篮球比赛战术数据自动采集及统计系统——3多目标跟踪
前言:
进行完目标检测后,我们就要进入第二个多目标跟踪模块,本人采用的多目标跟踪策略为deepsort深度分类算法,可以有效解决遮挡问题。因为在篮球运动中,遮挡问题是非常多的。
配置信息
还是缺什么库,自行导入什么库。我的配置过程还是比较顺利的。
基于yolov5+deepsort的多目标跟踪
参考文章:
YOLOv5+DeepSort多目标跟踪教程_yolov5 deepsort_爱学习的王同学#的博客-CSDN博客
deepsortv3.0版本下载路径:
文件 · v3.0 · mirrors / mikel-brostrom / Yolov5_DeepSort_Pytorch · GitCode
这里我结合了yolov5+deepsortv3.0的版本能够实现成功视频追踪,但是yolov5和其他版本的deepsort不能兼容,所以这两个版本对应很重要。
与目标检测一致,参考文章可以完成多目标跟踪,但是我要提两个重要的点。其中数据集的摆放和构建很关键,这一步走完,在按照他的步骤走才可以。
1.将yolov5文件夹放在下载好的deepsort主文件夹下,格式如下:
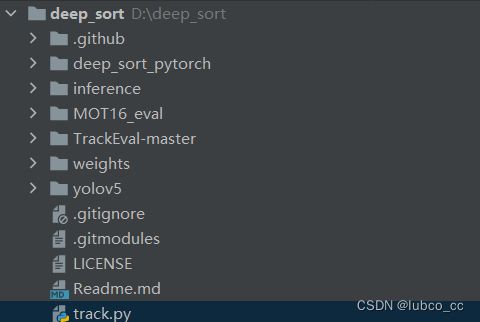
2.数据集的摆放与划分
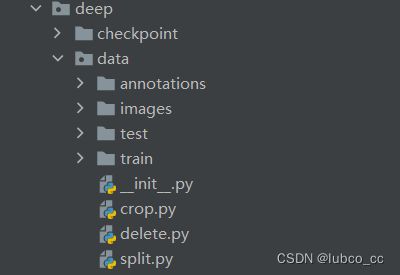
按数据集构建的文章摆放好数据集后,运行crop.py文件,可以进行图像切割处理,运行split.py可实现test和train的划分。这里提供源码
crop.py
import cv2
import xml.etree.ElementTree as ET
import numpy as np
import xml.dom.minidom
import os
import argparse
'''
用于截取xml目标框下的图片
结果保存在train中
'''
def main():
# JPG文件的地址
img_path = 'images/'
# XML文件的地址
anno_path = 'annotations/'
# 存结果的文件夹
cut_path = 'train/'
if not os.path.exists(cut_path):
os.makedirs(cut_path)
# 获取文件夹中的文件
imagelist = os.listdir(img_path)
for image in imagelist:
image_pre, ext = os.path.splitext(image)
img_file = img_path + image
img = cv2.imread(img_file)
xml_file = anno_path + image_pre + '.xml'
# DOMTree = xml.dom.minidom.parse(xml_file)
# collection = DOMTree.documentElement
# objects = collection.getElementsByTagName("object")
tree = ET.parse(xml_file)
root = tree.getroot()
# if root.find('object') == None:
# return
# obj_i = 0
dict_obj_i = {'1':1,'2':2,'3':3,'4':4,'5':5,
'a':6,'b':7,'c':8,'d':9,'e':10}
for obj in root.iter('object'):
# obj_i += 1
cls = obj.find('name').text
obj_i = dict_obj_i[cls]
xmlbox = obj.find('bndbox')
b = [int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)),
int(float(xmlbox.find('xmax').text)),
int(float(xmlbox.find('ymax').text))]
img_cut = img[b[1]:b[3], b[0]:b[2], :]
path = os.path.join(cut_path, cls)
# # 目录是否存在,不存在则创建
mkdirlambda = lambda x: os.makedirs(x) if not os.path.exists(x) else True
mkdirlambda(path)
try:
cv2.imwrite(os.path.join(cut_path, cls, '{}_{:0>2d}.jpg'.format(image_pre, obj_i)), img_cut)
except:
continue
print("done")
if __name__ == '__main__':
main()
注意:在dict_obj_i 中实现对自己的ID编号
split.py
import os
import random
import shutil
'''
用于划分训练集train和测试集test
'''
src_path = 'train'
dst_path = 'test'
train_scale = 0.9
test_scale = 0.1
list = os.listdir(src_path) # 文件名1,2,3......
for classes in list: # 遍历文件1,2,3.....
dst_dir = os.path.join(dst_path,classes) #目标文件夹test/1......
deal_class = os.path.join(src_path, classes) # 选择要处理的文件夹1 2 3 .....
in_class = os.listdir(deal_class) # 进入文件夹1 2 3..... tpye(in_class)=list
total_num = len(in_class)
train_num = int(total_num * train_scale)
test_num = int(total_num * test_scale)
for i in range(test_num):
test_jpg = random.choice(in_class) # 随机选取列表test_num个图片
in_class.remove(test_jpg)
test_path = os.path.join(deal_class, test_jpg)
shutil.move(test_path,dst_dir)
print('{} done'.format(classes))
print('训练集:测试集 = {}:{}'.format(train_scale,test_scale))
至此,多目标跟踪完毕。在deep_sort/deep/checkpoint文件夹下找到ckpt.t7,这是我们需要的跟踪权重文件。