重学深度学习系列-- CNN猫狗分类(TensorFlow2)
重学深度学习系列-- CNN猫狗分类(TensorFlow2)
文章目录
- 重学深度学习系列-- CNN猫狗分类(TensorFlow2)
-
- 一、我的环境
- 二、工程结构
- 三、训练
-
- 3.1 导入库
- 3.2 导入数据集
- 3.3 进行数据增强
- 3.4 构建CNN模型
- 3.5 输出网络的参数
- 3.6 配置训练的参数
- 3.7 开始训练
- 3.8 将训练的结果可视化
- 3.9 保存训练好的模型
- 四、预测
- 参考文献
一、我的环境
windows10 + pycharm , TensorFlow2.3.0
二、工程结构
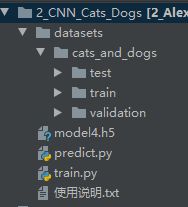
train.py – 训练
predict.py – 预测
model4.h5 是我训练过的猫狗分类的模型,可以调用predict.py直接对图片进行预测
datasets
– train 2000 训练集
— cats 1000
— dogs 1000
– validation 400 验证集
— cats 200
— dogs 200
– test 40 测试集,不参与训练,自己预测使用
— cats 20
— dogs 20
工程已分享在百度网盘链接:
链接:https://pan.baidu.com/s/1P9x5DscRt0LpW6GXX9uJ7g
提取码:2022
–来自百度网盘超级会员V4的分享
三、训练
3.1 导入库
import os
import warnings
warnings.filterwarnings("ignore")
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
3.2 导入数据集
由于已经自己按类别单独存放在不同文件夹了,并且此次分类只有2类,所以可以这样编写分别加载训练集和验证集:
# 加载数据集
base_dir = './datasets/cats_and_dogs/'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
3.3 进行数据增强
# 进行数据增强
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
test_datagen = ImageDataGenerator(rescale=1. / 255)
img_size = (64, 64) # 与网络输入大小一致
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=img_size, # 与网络的固定输入一致
batch_size=8,
class_mode='binary' # one-hot编码格式,在预测时输出也要注意
)
validation_generator = train_datagen.flow_from_directory(
validation_dir,
target_size=img_size,
batch_size=8,
class_mode='binary'
)
需要注意的是,batchsize基本上是越大越好,你的设备能支持多大就多大,并且batchsize在一定程度上还能影响你模型的准确率,一般来说batchsize越大模型收敛得越快。
3.4 构建CNN模型
这个CNN模型基本上可以说是最简单的模型了,可以利用该模型来分析一个分类任务的复杂性,如果准确率没有达到预期就可以进行进一步的调参和优化。这里我采用64×64的大小,因为太大了笔记本跑不动。另外加入了0.5的dropout可以有效地防止过拟合。(可以自己把dropout那行注释掉比较加不加的区别)。
# 构建模型
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1, activation='sigmoid')
])
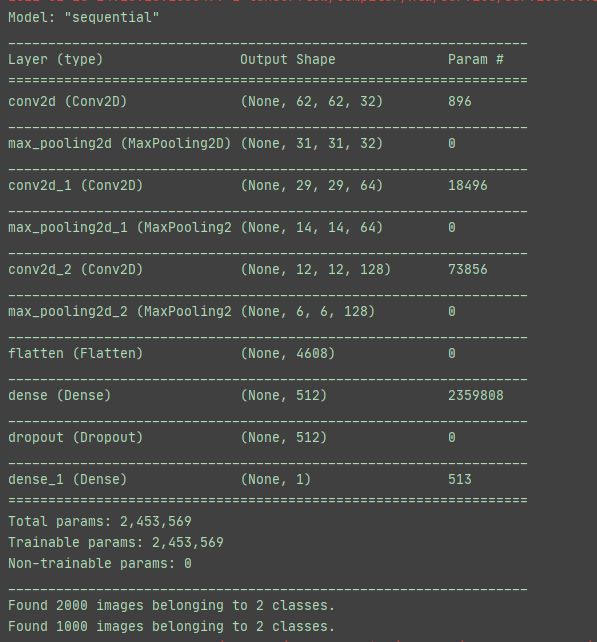
3.5 输出网络的参数
# 总结输出网络参数
model.summary()
3.6 配置训练的参数
# 配置模型训练的参数
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=1e-4), metrics=['acc'])
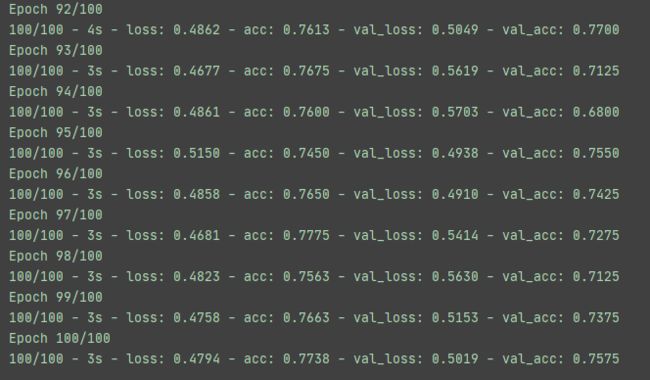
3.7 开始训练
# 加载训练数据
history = model.fit_generator(
train_generator,
steps_per_epoch=100, # 2000 images = batchsize * steps
epochs=100,
validation_data=validation_generator, # 1000 images = batchsize * steps
validation_steps=50,
verbose=2
)
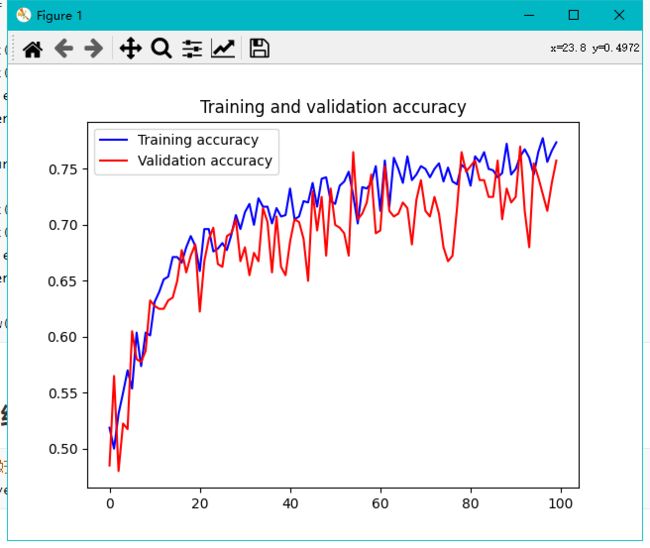
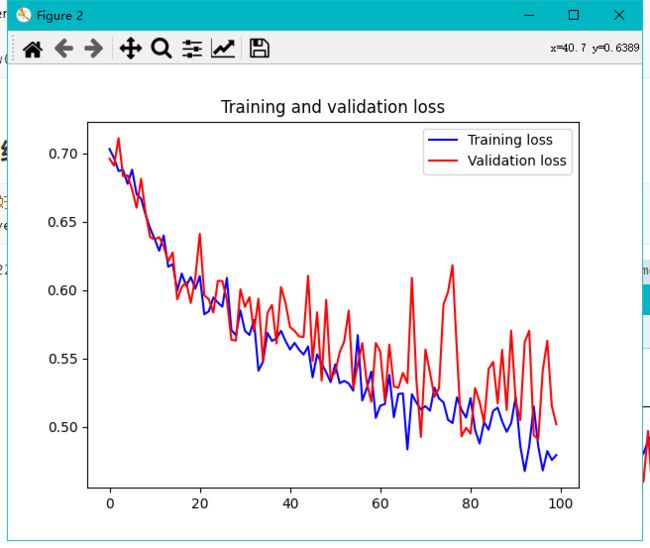
3.8 将训练的结果可视化
# 将训练结果可视化
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'b', label='Training accuracy')
plt.plot(epochs, val_acc, 'r', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
3.9 保存训练好的模型
# 保存训练好的模型
model.save('./model.h5')
四、预测
import numpy as np
from tensorflow.keras.models import load_model
import cv2
# 种类字典
class_dict = {0: '猫', 1: '狗'}
def predict(img_path):
# 载入模型
model = load_model('./model4.h5')
# 载入图片,并处理
img = cv2.imread(img_path)
img = cv2.resize(img, (64, 64))
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_nor = img_RGB / 255
img_nor = np.expand_dims(img_nor, axis=0)
# 预测
# print((np.argmax(model.predict(img_nor))))
# print(model.predict(img_nor))
y = model.predict_classes(img_nor)
print(class_dict.get(y[0][0])) # 直接输出种类 0是猫 1是狗
if __name__ == "__main__":
predict('./datasets/cats_and_dogs/test/cat.1500.jpg') #
predict('./datasets/cats_and_dogs/test/dog.1500.jpg') #
predict('./datasets/cats_and_dogs/test/dog.1504.jpg') #
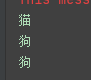
在预测时0之所以是猫是因为在文件夹中cat排在dog的前面,所以1就代表狗。预测时有model.predict_classes和model.predict两种不同的函数,前者直接输出种类,后者是对应one-hot格式的。实在不明白的可以查看官网的API文档。也可以参考这篇文章:https://blog.csdn.net/zds13257177985/article/details/80638384
参考文献
1.唐宇迪的b站课程
2.https://blog.csdn.net/zds13257177985/article/details/80638384
3.TensorFlowAPI文档:https://tensorflow.google.cn/versions/r2.3/api_docs