TensorFlow2 学习——CNN图像分类
文章目录
- TensorFlow2 学习——CNN图像分类
-
- 1. 导包
- 2. 图像分类 fashion_mnist
- 3. 图像分类 Dogs vs. Cats
-
- 3.1 原始数据
- 3.2 利用Dataset加载图片
- 3.3 构建CNN模型,并训练
TensorFlow2 学习——CNN图像分类
1. 导包
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import os
2. 图像分类 fashion_mnist
- 数据处理
# 原始数据 (X_train_all, y_train_all),(X_test, y_test) = tf.keras.datasets.fashion_mnist.load_data() # 训练集、验证集拆分 X_train, X_valid, y_train, y_valid = train_test_split(X_train_all, y_train_all, test_size=0.25) # 数据标准化,你也可以用除以255的方式实现归一化 # 注意最后reshape中的1,代表图像只有一个channel,即当前图像是灰度图 scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train.reshape(-1, 28 * 28)).reshape(-1, 28, 28, 1) X_valid_scaled = scaler.transform(X_valid.reshape(-1, 28 * 28)).reshape(-1, 28, 28, 1) X_test_scaled = scaler.transform(X_test.reshape(-1, 28 * 28)).reshape(-1, 28, 28, 1) - 构建CNN模型
model = tf.keras.models.Sequential() # 多个卷积层 model.add(tf.keras.layers.Conv2D(filters=32, kernel_size=[5, 5], padding="same", activation="relu", input_shape=(28, 28, 1))) model.add(tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)) model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=[5, 5], padding="same", activation="relu")) model.add(tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)) # 将前面卷积层得出的多维数据转为一维 # 7和前面的kernel_size、padding、MaxPool2D有关 # Conv2D: 28*28 -> 28*28 (因为padding="same") # MaxPool2D: 28*28 -> 14*14 # Conv2D: 14*14 -> 14*14 (因为padding="same") # MaxPool2D: 14*14 -> 7*7 model.add(tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))) # 传入全连接层 model.add(tf.keras.layers.Dense(1024, activation="relu")) model.add(tf.keras.layers.Dense(10, activation="softmax")) # compile model.compile(loss = "sparse_categorical_crossentropy", optimizer = "sgd", metrics = ["accuracy"]) - 模型训练
callbacks = [ tf.keras.callbacks.EarlyStopping(min_delta=1e-3, patience=5) ] history = model.fit(X_train_scaled, y_train, epochs=15, validation_data=(X_valid_scaled, y_valid), callbacks = callbacks)Train on 50000 samples, validate on 10000 samples Epoch 1/15 50000/50000 [==============================] - 17s 343us/sample - loss: 0.5707 - accuracy: 0.7965 - val_loss: 0.4631 - val_accuracy: 0.8323 Epoch 2/15 50000/50000 [==============================] - 13s 259us/sample - loss: 0.3728 - accuracy: 0.8669 - val_loss: 0.3573 - val_accuracy: 0.8738 ... Epoch 13/15 50000/50000 [==============================] - 12s 244us/sample - loss: 0.1625 - accuracy: 0.9407 - val_loss: 0.2489 - val_accuracy: 0.9112 Epoch 14/15 50000/50000 [==============================] - 12s 240us/sample - loss: 0.1522 - accuracy: 0.9451 - val_loss: 0.2584 - val_accuracy: 0.9104 Epoch 15/15 50000/50000 [==============================] - 12s 237us/sample - loss: 0.1424 - accuracy: 0.9500 - val_loss: 0.2521 - val_accuracy: 0.9114 - 作图
def plot_learning_curves(history): pd.DataFrame(history.history).plot(figsize=(8, 5)) plt.grid(True) #plt.gca().set_ylim(0, 1) plt.show() plot_learning_curves(history)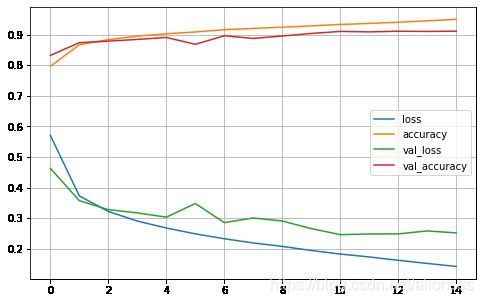
- 测试集评估准确率
model.evaluate(X_test_scaled, y_test)[0.269884311157465, 0.9071] - 可以看到使用CNN后,图像分类的准确率明显提升了。之前的模型是0.8747,现在是0.9071。
3. 图像分类 Dogs vs. Cats
3.1 原始数据
-
原始数据下载
- Kaggle: https://www.kaggle.com/c/dogs-vs-cats/
- 百度网盘:
https://pan.baidu.com/s/13hw4LK8ihR6-6-8mpjLKDA提取码 dmp4
-
读取一张图片,并展示
image_string = tf.io.read_file("C:/Users/Skey/Downloads/datasets/cat_vs_dog/train/cat.28.jpg") image_decoded = tf.image.decode_jpeg(image_string) plt.imshow(image_decoded)

3.2 利用Dataset加载图片
- 由于原始图片过多,我们不能将所有图片一次加载入内存。Tensorflow为我们提供了便利的Dataset API,可以从硬盘中一批一批的加载数据,以用于训练。
- 处理本地图片路径与标签
# 训练数据的路径 train_dir = "C:/Users/Skey/Downloads/datasets/cat_vs_dog/train/" train_filenames = [] # 所有图片的文件名 train_labels = [] # 所有图片的标签 for filename in os.listdir(train_dir): train_filenames.append(train_dir + filename) if (filename.startswith("cat")): train_labels.append(0) # 将cat标记为0 else: train_labels.append(1) # 将dog标记为1 # 数据随机拆分 X_train, X_valid, y_train, y_valid = train_test_split(train_filenames, train_labels, test_size=0.2) # 转换为tensorflow的constant train_filenames = tf.constant(X_train) valid_filenames = tf.constant(X_valid) train_labels = tf.constant(y_train) valid_labels = tf.constant(y_valid) - 定义一个解码图片的方法
def _decode_and_resize(filename, label): image_string = tf.io.read_file(filename) # 读取图片 image_decoded = tf.image.decode_jpeg(image_string) # 解码 image_resized = tf.image.resize(image_decoded, [256, 256]) / 255.0 # 重置size,并归一化 return image_resized, label - 定义 Dataset,用于加载图片数据
# 训练集 train_dataset = tf.data.Dataset.from_tensor_slices((train_filenames, train_labels)) train_dataset = train_dataset.map( map_func=_decode_and_resize, # 调用前面定义的方法,解析filename,转为特征和标签 num_parallel_calls=tf.data.experimental.AUTOTUNE) train_dataset = train_dataset.shuffle(buffer_size=128) # 设置缓冲区大小 train_dataset = train_dataset.batch(32) # 每批数据的量 train_dataset = train_dataset.prefetch(tf.data.experimental.AUTOTUNE) # 启动预加载图片,也就是说CPU会提前从磁盘加载数据,不用等上一次训练完后再加载 # 验证集 valid_dataset = tf.data.Dataset.from_tensor_slices((valid_filenames, valid_labels)) valid_dataset = valid_dataset.map( map_func=_decode_and_resize, num_parallel_calls=tf.data.experimental.AUTOTUNE) valid_dataset = valid_dataset.batch(32)
3.3 构建CNN模型,并训练
-
构建模型与编译
model = tf.keras.Sequential([ # 卷积,32个filter(卷积核),每个大小为3*3,步长为1 tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(256, 256, 3)), # 池化,默认大小2*2,步长为2 tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 5, activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(64, activation='relu'), tf.keras.layers.Dense(2, activation='softmax') ]) model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss=tf.keras.losses.sparse_categorical_crossentropy, metrics=[tf.keras.metrics.sparse_categorical_accuracy] ) -
模型总览
model.summary()Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_2 (Conv2D) (None, 254, 254, 32) 896 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 127, 127, 32) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 123, 123, 32) 25632 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 61, 61, 32) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 119072) 0 _________________________________________________________________ dense_2 (Dense) (None, 64) 7620672 _________________________________________________________________ dense_3 (Dense) (None, 2) 130 ================================================================= Total params: 7,647,330 Trainable params: 7,647,330 Non-trainable params: 0 -
开始训练
model.fit(train_dataset, epochs=10, validation_data=valid_dataset)- 由于数据量大,此处训练时间较久
- 需要注意的是此处打印的step,每个step指的是一个batch(例如32个样本一个batch)
-
模型评估
test_dataset = tf.data.Dataset.from_tensor_slices((valid_filenames, valid_labels)) test_dataset = test_dataset.map(_decode_and_resize) test_dataset = test_dataset.batch(32) print(model.metrics_names) print(model.evaluate(test_dataset))