Numpy模块
目录
- 广播broadcast
- 创建ndarray数组
- 一些记录
- 常用属性
- 常用方法
- 踩坑
python核心没有数组的概念,在Numpy以前用列表来模拟数组,但由于列表的通用性,这种模拟与C相比时间花销更大,数值计算缓慢。标准的解决方案就是使用Numpy模块,Numpy的内部实现为C的数组,其对象称为ndarray。
广播broadcast
法则:
-
法则一:
若多个数组的维度(或叫轴)的数量ndim不同,对ndim少的数组,从后向前使用“1”来扩展,直到所有数组的ndim相同。
-
法则二:
此时(所有数组的ndim已经相同)判断能否广播,若存在两数组的shape中某一对应位置都不包含1且不相等,则不能广播抛出ValueError;否则可以广播,将“1”改为对应维度大小的最大值,最终所有数组的shape都相同。
举例:
-
例一
a = np.array([[1, 2, 3], [4, 5, 6]])a.shape=(2,3)
b = np.array([4, 5, 6])b.shape=(3, )
c = np.array(2)c.shape=()
a * b + c,
由法则一:b.shape改为(1, 3),c.shape改为(1, 1)
由法则二:首先判断得出可以广播,然后将b.shape索引为0元素的改为最大值2(max{a.shape[0], b.shape[0], c.shape[0]}),此时b的元素在逻辑上进行复制,即b.shape为(2, 3)。同样,将c.shape改为(2, 3)。 -
例二
a = np.array([[1, 2, 3], [4, 5, 6]])a.shape=(2,3)
b = np.array([4, 5])b.shape=(2, )
由法则一:b.shape改为(1, 2)
由法则二:a.shape[0]和b.shape[0]满足,但a.shape[1]和b.shape[1]不满足,不能广播。
创建ndarray数组
生成一维数组
- np.array([[1, 2], [3, 4]])
- np.linsapce(start, stop, num=50, endpoint=True, retstep=False, dtype=None),num为长度,endpoint=True包含stop,retstep=True返回数组和步长step的元组。
- np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None),start和stop分别为起始指数和终止指数,base为底数,num为元素个数。
- np.mgrid[start, stop, numj],包含stop,注意中括号
- np.arange(start=0, stop, step=1, dtype=None),类似内置函数range,左闭右开。
- np.ones(num, dtype=float),num为长度,默认float
- np.zeros(num, dtype=float)
- np.ones_like(x),size和x相同
- np.zeros_like(x)
- np.diag()
- np.eye()
生成二维数组
- np.mgrid[start1, stop1, num1j, start2, stop2, num2j],二维网格数据,注意中括号
- np.meshgrid(x, y),x、y可由linspace或arange生成
- np.ones(size, dtype=float)
- np.zeros(num, dtype=float) `
x = np.linspace(0, 3, 4) # 等价于x = np.mgrid[0:3:4j]
y = np.linspace(-1, 4, 5) # 等价于y = np.mgrid[-1:4:5j]
(xm, ym) = np.linspace(x, y)
(xm, ym) = np.mgrid[0:3:4j, -1:4:5j] # 不能np.mgrid[x, y]
一些记录
正无穷np.inf
负无穷np.NINF
可以0/np.inf,但不能np.inf/np.inf,这种需求时可以定义INF=1.0e99
x=np.where(a>0)返回元组(i, j, k,…),其len与a的轴数或维度相同,其中i, j, k是同维度的array数组。a[i[idx], j
注意:a[x]=a[x]/2,得到的是整数,当索引是where时数据类型得一致?仅a[x]/2还不是
理解axis
np.sum(a, axis=0)
第0轴上的元素相加,第0轴将消失,可通过a.shape查看。类比三维坐标系的画法,x、y、z分别对应0、1、2
学会数shape
去掉最外面的[],此时最大[]的个数为shape[0]
以此类推
或者,最里面的[]里的元素个数为shape[end-1]
以此类推
所以,当是三维的时候,shape[0]为高的维度,shape[1]为行,shape[2]为列(用reshape和tile的时候得注意),就shape是个例外,其他与axis保持一致
[[1,2]
[1,2]
[1,2]]
(3,2)
vstack, hstack, dstack,第一二三位上堆叠
区别
np.zeros(shape=(m, 0)),为空,vstack、hstack不影响
np.zeros(shape=(m,))
numpy中power运算时,底数为负数时幂指数不能是小数。
np.power(-2, 2.3)
(-2)**2.3
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2020/12/21 21:11
# @Author : Jin Echo
import numpy as np
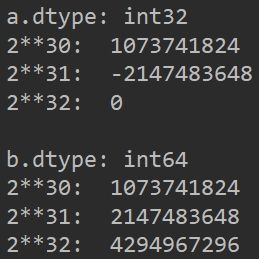
a = np.array(2) # 默认32
print('a.dtype:', a.dtype)
print('2**30: ', a**30)
print('2**31: ', a**31)
print('2**32: ', a**32)
b = np.array(2, dtype=np.int64) # 默认32
print('\nb.dtype:', b.dtype)
print('2**30: ', b**30)
print('2**31: ', b**31)
print('2**32: ', b**32)
a.shape=(2,)
np.tile(a,5).reshape(2, 5)
gen_x = np.clip(gen_x, self.lb, self.ub)
res = np.zeros(shape=(0, 3)
np.r_: 两矩阵按行合并,增加行,等价于np.row_stack((a, b))
np.c_: 两矩阵按列合并,增加列,价于np.column_stack(a,b)
np.range(1, 10, 2): 只能int
np.arange(1, 5, 0.5):包含5,可以设置不包含
np.linspace(0,5,6):包含5
np.log(x)、np.log10(x)、np.log2(x)
np.exp(1)
a = np.log1p(x)—x=np.expm1(a)
np.random.seed(0),
np.random.shuffle(a),可变对象列表,无返回值
np.matrix.tolist(a):ndarray数组转换为列表
常用属性
dtype
shape
ndim
size
T
常用方法
- np.reshape(a, newshape, order=‘C’
newshape=(m, )或(m, n)。m*n必须为数组元素个数,m、n中的一个可以为-1,将自动推算新形状。等价于ndarray.reshape(shape, order=‘C’) - a.reshape()和a.resize(),都返回变形对象,前者原数组不变,后者原数组改变。
- a.flatten()/ravel()返回展平数组,原数组不变
- a.sum/prod/argmax/compress
- np.hastck()/vstack()/concatenate()/c_[]/r_[]组合数组,区别stack和concatenate
- np.hsplit/()vsplit()/split()分割数组
- np.random.rand/randn
有没有查找到第一个元素就结束的?(即返回第一个满足条件的索引,不再继续找)
argwhere看看有没有其他参数
numpy查找某一元素的索引
np.argmin返回第一个最小值的索引
np.argwhere(条件)
(a==1).nonzero(0)
以下两个好用
对2D np.ndarray
i, j = np.where(a == value)
对1D np.ndarray
i, = np.where(a == value)或i = np.where(a == value)[0]:返回满足条件的数组,i[0]取第一个
其实对numpy数组,可以直接:
idx_bool = a>0.5
a[idx_bool] = 1
但列表不能这么玩
pytorch nonzero、where函数与numpy应该是一样的
踩坑
-
ndarray数组是可变对象
a = np.zeros(2) b = a a[0] = 0 0==b[0] # True使用浅拷贝
b=copy.copy(a),b = a[:]b = copy.deepcopy(a)。b = a[:]不行
id(a)==id(b) or a is ba = np.zeros(4) b = a[0:2] b[0] = 1 1==b[0] # True修改b[0],a[0]将变换;修改a[0],b[0]将变化
但b = a[0],将不影响