论文阅读:Vision GNN: An Image is Worth Graph of Nodes
计算机视觉与图卷积神经网络的结合
作者单位: 华为诺亚方舟实验室、北京大学、澳门大学
作者:韩凯、王云贺等
论文地址:点击这里下载
代码地址: 点击这里访问
摘要
基于深度学习的计算机视觉系统的网络架构是重中之重。卷积神经网络和transformer在处理图像的过程中是把图像类数据集作为格子和序列的结构(欧式数据)来进行处理。这样对于不规则的目标进行学习的时候显得不够灵活。
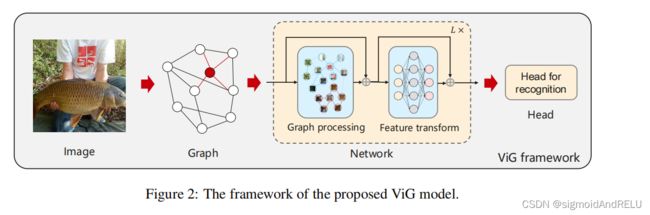
本文将图像变成节点的形式,而非序列数据和格子数据,使用对应的图神经网络学习Graph水平的特征信息。 步骤如下:
首先,将图像切割成补丁的形式,作为对应的图节点,相邻的节点相连组建成一张完整的图。
然后,基于image图,我们使用ViG模型来进行节点的信息交互和转化。
ViG模型由两部分组成:
Grapher 模型使用图卷积进行节点的聚合和更新。
FFN 由两个全连接层进行 节点特征转换。
本文同时建立了不同模型尺寸的各向同性和金字塔结构,对于图像识别和目标检测任务的大量实验证明了我们的ViG架构的优越性。
希望GNN对于一般视觉任务的开创性研究能够提供有用的灵感和经验。
引言
在现代计算机视觉系统中,卷积神经网络曾经是事实上的标准架构!这两年,transformer和注意力机制在视觉任务中崭露头角并掀起了一股热潮,所取得的效果也很显著。基于多层感知机的视觉模型在不使用自注意力的时候也能够取得不错的效果。这些方法将视觉模型推向了不可预知的高度。
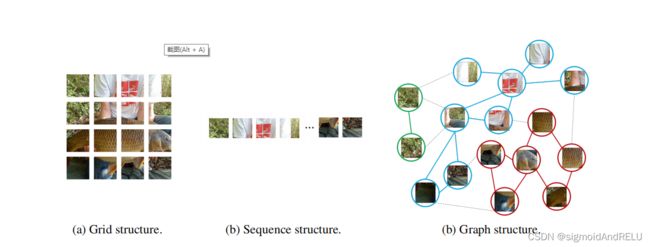
不同的网络对待图像的方式不同,图像通常被认为是欧式空间的规则网格的像素分布表示。卷积的思想在于使用带冗余的滑动窗口,引入平移不变形和局部性来学习这些窗口中的信息。
而transformer是将图像分成一系列的patch,例如,ViT将224224的图像分割成196张1616大小的patch。
本文则不用上述两种方式,而是用一种更为灵活的方式。计算机视觉的一个基础任务是识别一张图像中的对象,因为对象不总是长方形的,我们现有的网格化和序列架构是有冗余且不灵活的。
一个对象可以看成几个部分的组成,例如人可以看成是头、上肢、胳膊和腿组成。这些部分会自然而然的形成一个图架构。通过分析这张图,我们就能将它识别成一个人。并且,图可以看做序列和网格化数据的一个泛型,将图像变成图数据会更为的灵活,并且在视觉感知上更为有效。
基于这个理念,本文搭建了一个GNN(ViG for short)用于视觉任务。对于任意一张图片,大于10Kd像素点是非常常见的,如果像素点作为图节点,那么太密集了,计算量可想而知。所以,在图节点划分这一步,依然参考transformer的方法,将图进行patch分化,并且,以这些patch作为图节点,ViG的作用就是勾连这些节点并且进行信息交流转换。
ViG分为两个部分:图卷积网络和 前馈网络。前者用于图信息处理,后者进行节点特征转换。基于这两个基础模块,本文以各向同性和金字塔的方式搭建模型(这里可以看代码,应该不至于太复杂)。
在实验中,我们证明了模型的有效性,无论是分类还是目标检测。 对比CNN、MLP、transformer的 三个具有代表性的模型(ResNet、CycleMLP、Swin-T)。
在大规模的数据集上,图神经网络的应用,这是第一次,这说法没错。
相关工作
2.1 CNN、transformer、MLP
LeNet、ResNet、MobileNet、NAS
ViT、Pyramid vision transformer、swin-T、TIT、位置编码器transformer
MLP-mixer、Resmlp、Phase-avare vision mlp、As-mlp、Cyclemlp、Hire-mlp
2.2 GNN
1、A new model for learning in graph domains
2、The graph neural network model.
3、 Neural network for graphs: A contextual constructive approach
spatial-GNN:
1、Learning convolutional neural networks for graphs
2、Neural message passing for quantum chemistry
3、Diffusion-convolutional neural networks
spectal-GNN:
1、 Spectral networks and locally connected networks on graphs
2、Semi-supervised classification with graph convolutional networks
3、 Deep convolutional networks on graph-structured data.
4、 Convolutional neural networks on graphs with fast localized spectral filtering.
5、Inductive representation learning on large graphs
6、Collective classification in network data
7、 Comparison of descriptor spaces for chemical compound retrieval and classification
3D点云分割:
1、 Large-scale point cloud semantic segmentation with superpoint graphs
2、Dynamic graph cnn for learning on point clouds
3、 Scene graph generation by iterative message passing
4、Graph r-cnn for scene graph generation
为了计算机视觉更广泛的应用,我们需要一个基于GCN的backbone 用于处理图形数据。
方法:
3.1 ViG block
用图节点表示图像,并且使用聚合的更新策略,结合多头注意力的功能,将图节点周围的信息进行权重筛选。
由于深层的图卷积会导致图像过平滑,我们使用非线性激活函数来缓解这一情况的发生,
具体操作就是前后加上线性层,最后嵌套非线性激活。
为了提高特征转换能力,使用多层感知机来达到目的。
所以,由图卷积加上全连接层就构成了基本的ViG块,简单的堆叠之后就形成了我们要用的VIG网络。
3.2 各向同性和金字塔架构
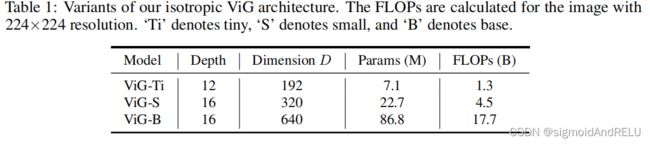
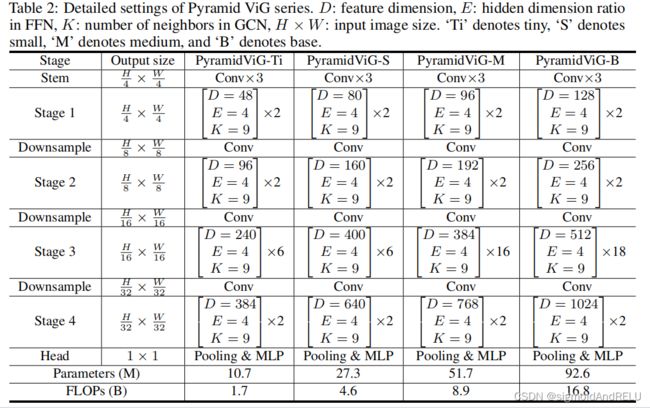
多尺度的还是比较好看。
结果
数据集:ILSVRC 2012、 COCO2017
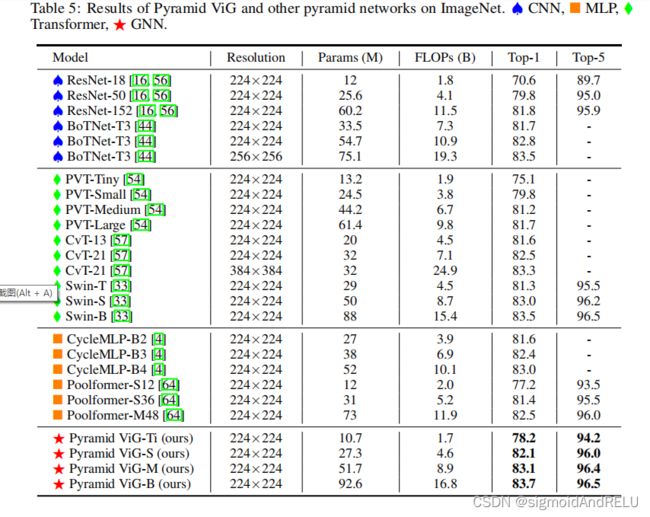
总结:本文的思想还是不错的,并且实验做的很充分,在整个GNN计算机视觉应用中算是将GNN摆上了台面,还是希望有更多的优秀的GNN的方法能够应用到视觉任务中,并且在理论方面有着更充分解释!
感谢大家观看。