机器学习的实验
目录
BP神经网络预测波士顿房价
1. 神经网络基本概念
1.1概念
1.2发展
CNN
RNN
GAN
2.神经网络基本框架
2.1单元/神经元
2.2 连接/权重/参数
2.3偏置项
2.4超参数
2.5激活函数
2.6层
3.神经网络算法
4.算法方案
5. 实验
6.参考文献
BP神经网络预测波士顿房价
1. 神经网络基本概念
1.1概念
神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
1.2发展
神经网络起源于 WarrenMcCulloch 和 Walter Pitts 于 1943 年首次建立的神经网络模型。他们的模型完全基于数学和算法,由于缺乏计算资源,模型无法测试。后来,在 1958 年,Frank Rosenblatt 创建了第一个可以进行模式识别的模型,改变了现状。即感知器。但是他只提出了 notation 和模型。实际的神经网络模型仍然无法测试,此前的相关研究也较少。第一批可以测试并具有多个层的神经网络于 1965 年由 Alexey Ivakhnenko 和 Lapa 创建。之后,由于机器学习模型具有很强可行性,神经网络的研究停滞不前。很多人认为这是因为 Marvin Minsky 和 Seymour Papert 在 1969 年完成的书《感知机》(Perceptrons)导致的。然而,这个停滞期相对较短。6 年后,即 1975 年,Paul Werbos 提出反向传播,解决了 XOR 问题,并且使神经网络的学习效率更高。1992 年,最大池化(max-pooling)被提出,这有助于 3D 目标识别,因为它具备平移不变性,对变形具备一定鲁棒性。2009 年至 2012 年间,JürgenSchmidhuber 研究小组创建的循环神经网络和深度前馈神经网络获得了模式识别和机器学习领域 8 项国际竞赛的冠军。2011 年,深度学习神经网络开始将卷积层与最大池化层合并,然后将其输出传递给几个全连接层,再传递给输出层。这些被称为卷积神经网络。
1.3神经网络三大分类
- 常用于影像数据进行分析处理的卷积神经网络(简称CNN)
- 常用于数据生成或非监督式学习应用的生成对抗网络(简称GAN)3.
- 文本分析或自然语言处理的递归神经网络(简称RNN)
CNN
因为应用种类多样,本篇会以算法类别细分,CNN主要应用可分为图像分类(image classification)、目标检测(object detection)及语义分割(semantic segmentation)。
RNN
有别于CNN,RNN的特色在于可处理图像或数值数据,并且由于网络本身具有记忆能力,可学习具有前后相关的数据类型。例如进行语言翻译或文本翻译,一个句子中的前后词汇通常会有一定的关系,但CNN网络无法学习到这层关系,而RNN因具有内存,所以性能会比较好。因为可以通过RNN进行文字理解,其他应用如输入一张图像,但是输出为一段关于图像叙述的句子。
GAN
除了深度学习外,有一种新兴的网络称为强化学习(Reinforcement Learning),其中一种很具有特色的网络为生成式对抗网络(GAN)。
2.神经网络基本框架
单元/神经元
连接/权重/参数
偏置项
2.1单元/神经元
作为神经网络架构三个部分中最不重要的部分,神经元是包含权重和偏置项的函数,等待数据传递给它们。接收数据后,它们执行一些计算,然后使用激活函数将数据限制在一个范围内(多数情况下)。我们将这些单元想象成一个包含权重和偏置项的盒子。盒子从两端打开。一端接收数据,另一端输出修改后的数据。数据首先进入盒子中,将权重与数据相乘,再向相乘的数据添加偏置项。这是一个单元,也可以被认为是一个函数。该函数与下面这个直线方程类似:
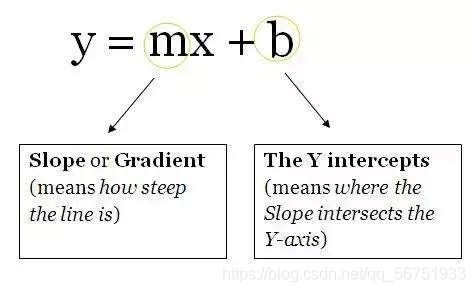
想象一下有多个直线方程,超过 2 个可以促进神经网络中的非线性。从现在开始,你将为同一个数据点(输入)计算多个输出值。这些输出值将被发送到另一个单元,然后神经网络会计算出最终输出值。
2.2 连接/权重/参数
作为神经网络最重要的部分,这些(和偏置项)是用神经网络解决问题时必须学习的数值。
2.3偏置项
这些数字代表神经网络认为其在将权重与数据相乘之后应该添加的内容。当然,它们经常出错,但神经网络随后也学习到最佳偏置项。
2.4超参数
- 定义关于模型的更高层次的概念,如复杂性或学习能力。
- 不能直接从标准模型培训过程中的数据中学习,需要预先定义。
- 可以通过设置不同的值,训练不同的模型和选择更好的测试值来决定
2.5激活函数
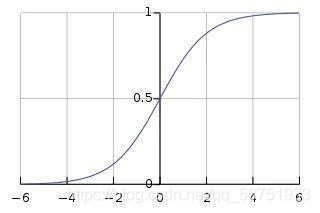
也称为映射函数(mapping function)。它们在 x 轴上输入数据,并在有限的范围内(大部分情况下)输出一个值。大多数情况下,它们被用于将单元的较大输出转换成较小的值。你选择的激活函数可以大幅提高或降低神经网络的性能。如果你喜欢,你可以为不同的单元选择不同的激活函数。
例如:Sigmoid
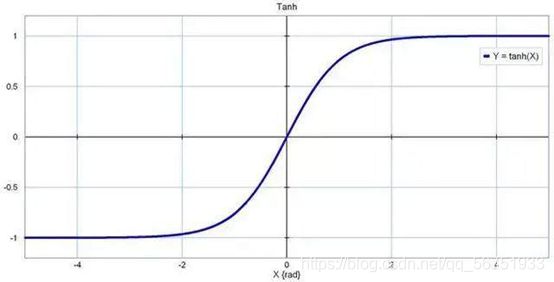
Tanh:
2.6层
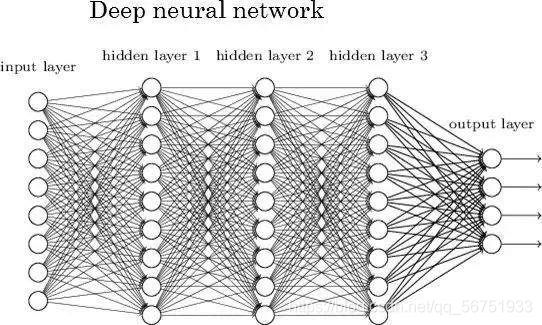
这是神经网络在任何问题中都可获得复杂度的原因。增加层(具备单元)可增加神经网络输出的非线性。每个层都包含一定数量的单元。大多数情况下单元的数量完全取决于创建者。但是,对于一个简单的任务而言,层数过多会增加不必要的复杂性,且在大多数情况下会降低其准确率。反之亦然。每个神经网络有两层:输入层和输出层。二者之间的层称为隐藏层。下图所示的神经网络包含一个输入层(8 个单元)、一个输出层(4 个单元)和 3 个隐藏层(每层包含 9 个单元)。
3.神经网络算法
逻辑性的思维是指根据逻辑规则进行推理的过程;它先将信息化成概念,并用符号表示,然后,根据符号运算按串行模式进行逻辑推理;这一过程可以写成串行的指令,让计算机执行。然而,直观性的思维是将分布式存储的信息综合起来,结果是忽然间产生的想法或解决问题的办法。这种思维方式的根本之点在于以下两点:1.信息是通过神经元上的兴奋模式分布存储在网络上;2.信息处理是通过神经元之间同时相互作用的动态过程来完成的。
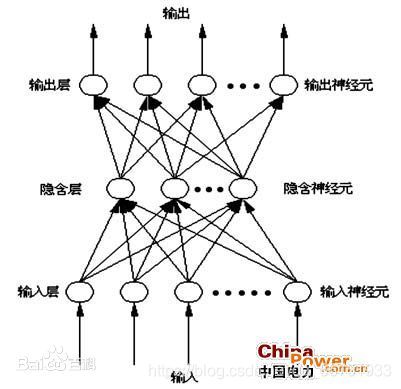
4.算法方案
用神经网络训练四组输入输出,直到误差达到指定误差,停止。用隐含层带有三个节点的神经网络解决该分类问题(该逻辑运算相当于是将其分为(0,0)、(1,1)和(0,1)、(1,0)两类的问题)
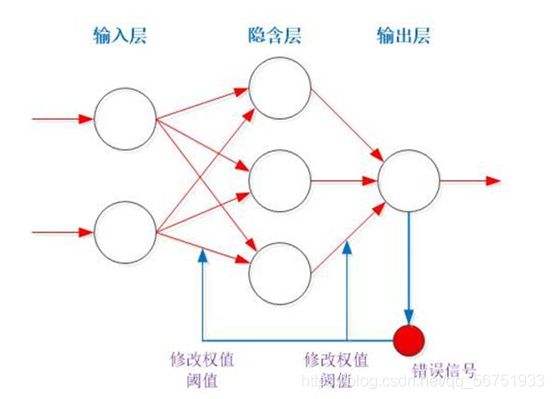
BP神经网络就是根据实际输出与期望输出调节连接权值及阈值,使其误差达到给定值,能够进行分类的目标。
这里用的激励函数
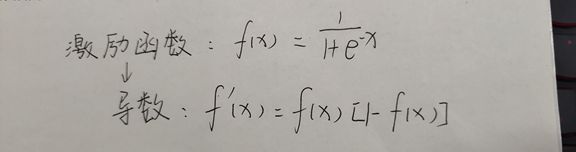
假设输入层–>隐含层权值用W,阈值用theta表示表示,隐含层到输出层权值用V表示,阈值用gamma表示。
- 为连接权值初始化,赋值区间为【-0.1,0.1】;
- 随机选取一个学习模式对提供给网络;
- 利用权值和阈值计算输入层输出;
- 计算隐含层神经元输入输出
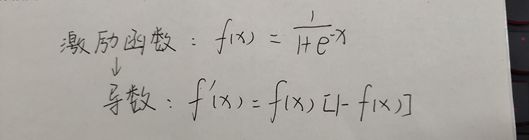
这里有两个输入神经元,三个隐含层神经元,所以i = 1,2;j =1,2,3,K表示训练次数。
(5)、计算输出层各个神经元输入和输出(这里就一个输出神经元)

(11)、判断全局误差E是否满足要求,若满足,转至(13);
(12)、学习次数加一,若小于规定最大次数(这里是2e+4即2万次),返回(2)继续。
(13)、结束。
5. 实验
数据集展示:
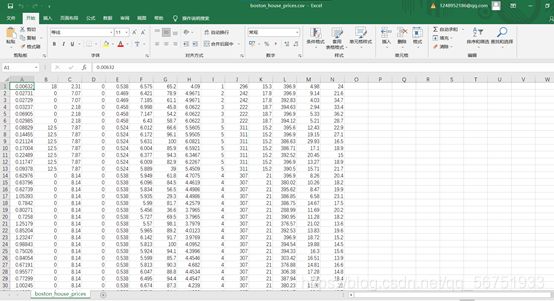
步骤:
导入数据库

数据集预处理

转换为nparray(浮点型)
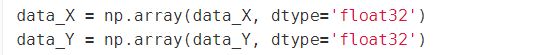
检查形状
![]()
归一化
分割训练集、测试集


查看训练集、测试集形状

定义每个批次大小
![]()
计算总批次的次数,以便迭代
![]()
训练次数
![]()
文件路径

参数概要

定义一个命名空间

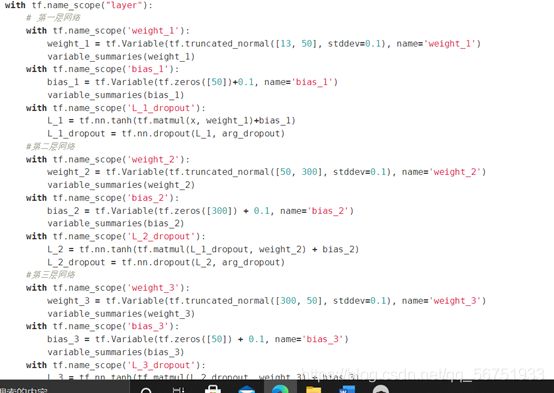
定义神经网络
adam梯度下降方式最小化代价函数
![]()
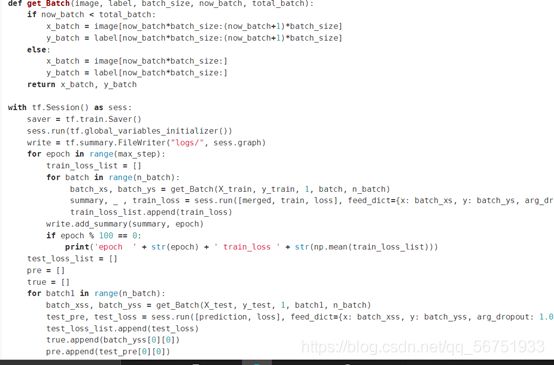
训练、测试
结果:
训练测试:
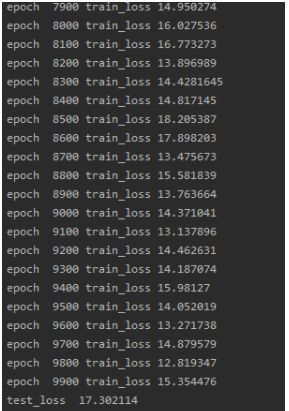
线性回归
真实值与预测值对比:
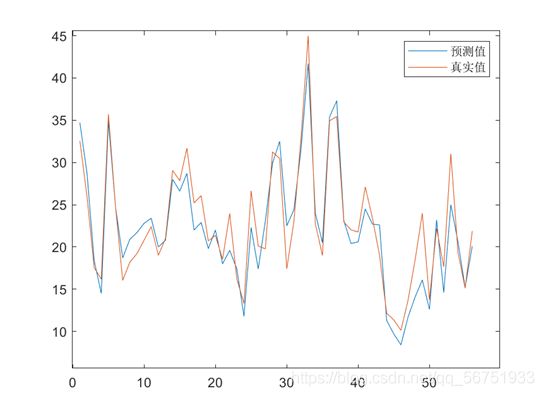
神经网络预测:
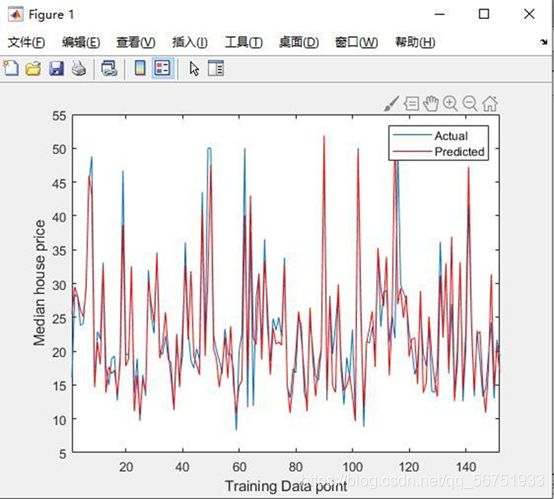
6.参考文献
[1] BP神经网络_百度百科 (baidu.com)
[2] 《BP算法的哲学思考》,成素梅、郝中华著[3]https://blog.csdn.net/wade1203/article/details/98477034
[4]https://blog.csdn.net/memoryheroli/article/details/80920260
[5]《机器学习》 周志华 著
[6]《机器学习实战》 Peter Harrington 著
[7] 《机器学习技法》 林轩田 著