基于支持向量机的量化选股模型
要求开发一个基于支持向量机技术的多因子量化投资模型,以近五年沪深300成分股的交易与财务数据为样本,结合大数据相关技术进行数据清洗,整理,存储,并构建投资策略与回测框架,输出量化投资模型的结果,为投资者选股与择时提供参考信号,具体要求如下:
- 从金融数据库(CSMAR、jqdata、tushare)获得2014-2020年股票行情数据以及公司的财务数据利用数据构造相关选股因子,并进行数据清洗、数据预处理等操作
- 以上述选股因子作为特征,并以下一期收益率数据作为标签,选取前 70%的数据作为训练集,后30%的数据样本作为测试集,构建支持向量机模型(包括提取特征因子、标签、分割数据集、模型参数寻优、利用样本训练模型、测试模型以及模型评价等步骤)来预测股价未来的上涨概率。
- 参数优化:本文选用网格搜索法来对SVM模型的重要参数进行优化。
- 构建投资策略:根据SVM 模型预测的未来上涨概率的预测值进行等权重选股投资。
- 参考tradebacker框架进行回测设计,根据上述选股结果和投资策略,构建模拟交易的回测框架,并对评价策略回测结果在收益以及风险方面的表现。
1 数据获取与预处理
本文基于聚宽(JQDATA)平台提供的数据支持,利用其python版API编写代码,在线获取相关数据,数据量的选取需要有代表性,且样本余越充足,得到的结果实用性就越强,模型也就越有效,因此在充分考虑上述因素与数据可得性的前提下,数据选取如下:
股票池:本文在沪深300指数(HS300)成分股里进行选股,剔除ST股票、剔除上市月份不足三个月的股票以及停牌退市的股票,同时考虑到银行这一金融机构的特殊性,许多数据无法获得以及财务指标具有行业特性等原因,因此剔除银行行业股票,剩下股票为股票池,每个股票为一个样本。
样本区间:2014年12月31日至2020年12月31日之间的月末截面数据。
1.1 风险因子的选取

3.1.2 数据预处理
- 百分位法去极值:对每一个风险指标进行升序排列,最小的百分之10和最大的10%定义为极值,即超过[10%,90%]以外的数据为极值,10%对应的值为下临界值,90%对应的值为上临界值,对极值进行缩尾处理,即将所有大于上临界值的值用上临界值来替代,所有小于下临界值的值用下临界值来替代。
- 缺失值处理:调用sklearn.impute中的SimpleImputer 库进行缺失值填充,首先获取各个行业每个风险因子的平均值,然后用行业均值对缺失值进行填充。
- 行业市值中性化处理:中性化实质是对因子进行提纯,去除掉由共同特质带来的多余的风险暴露,其中最常见的是行业与市值中性化。由于各个行业的特质性,不同行业的财务指标有很大差异,直接进行对比没有可比性,例如不同行业之间的市净率无法比较大小,因为需要考虑行业的特性,有可能某一个行业由于重资产的特性,导致普遍市净率偏高,因此需要剔除行业影响才能使得不同个股间的因子具备可比性。同理,市值这一因素也与各个指标之间具有很强的相关性,因此需要剔除不同行业与市值大小导致的误差影响,,具体做法是将因子数据对市值变量和行业哑变量做线性回归,得到的残差即为去除行业与市值影响的因子序列。
- 均值方差标准化:标准化的目的是去除不同指标之间量纲的影响,调用sklearn.preprocessing中的StandardScaler对数据进行均值方差规范化,(观察值-均值)/标准差得到近似于标准正态分布的序列。
代码实现:
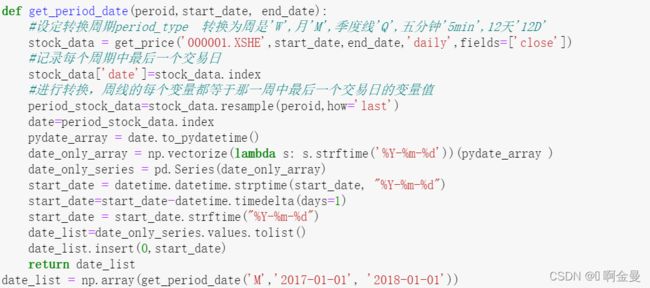


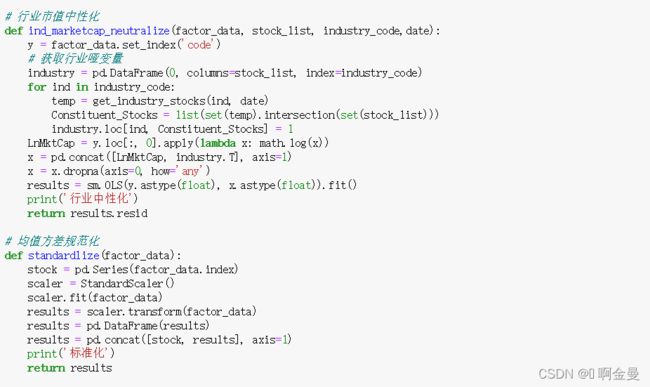

2 特征值、分割数据集与标签标记
2.1特征和标签的提取
计算个股下个月的收益率,收益率(pchg)=(当月最后一个交易日收盘价—下月最后一个交易日收盘价)-1,将pchg设为Y,也就是样本标签,每个月最后一个交易日提取15个风险因子的数据,进行预处理后作为样本特征,即Xi。
2.2分割数据集
构建机器学习方法,首先要训练模型,再用模型进行测试,因此先要对数据集进行分割,将其分为训练集和数据集,本文按照70%的比例进行分割,即2014年12月31日至2018年10月30日的数据集作为训练数据集,至2020年12月31日的数据集为测试数据集。
2.2标签标记
由于SVM模型本质是分类器,因此需要将收益率(pchg)指标数据转换成分类标签,在每一个月末,将收益率从高到低进行排序,收益率排在前30%的股票设为正类,此时Y=1,后30%的股票设为反类,此时Y=-1。
代码实现:


3 模型的训练与测试
3.1训练支持向量机模型的步骤
(1)根据前人经验表明,采用K折交叉验证法可以更好地实现模型参数设计,做法是将数据分成K组,随机选择训练集中10%的样本作为交叉验证集,剩下90%作为训练集。
(2)利用训练集建立SVM模型,利用训练好的模型预测交叉验证集的标签
(3)将预测的标签结果与实际的标签结果进行对比,从而得到模型的正确率与AUC等评价指标。
(4)重复上述步骤N次,用评价指标的均值判断模型的有效性。
3.2利用网格搜索法参数寻优
在构建机器学习模型的过程中,找到使模型表现最好的参数直接决定了模型的优劣,因此参数寻优是关键步骤,而网格搜索法是常用的参数寻优方法,且被多篇文献证明是对支持向量机模型的参数寻优十分有效。
网格搜索法的原理是:
(1)根据经验,确定出可能得到较优结果的待搜索的范围。
(2)将需要搜索的参数值网格离散化,再设定搜索长度,按照搜索参数的不同增长方向生成网格,网格中的节点就是对应的参数对。
(3)在待搜索的范围里对每个参数都取一系列的待检验的离散值,分别将所有可能的参数值组合用来训练模型并对模型的有效性以及推广能力进行评价。
(4)选择能使训练模型得到最好结果的参数作为最优的参数。
综上所述,网格搜索法就是采用暴力式地穷举待优化的参数组合值,然后评估不同参数组合下的模型性能,选出获得最优参数组合。
综上,需要优化的参数有:
(1)惩罚系数C,它表示SVM模型对错误分类的容忍度,当C取值较大时,模型对误差的容忍度较低,此时模型将尽可能以训练集的正确率出发,保证分类的正确,这样可能会导致过拟合现象,尽管训练集准确率高,但是模型预测的测试集的正确率并不高;当C取值较小时,则模型能够容忍一定的误差,模型将倾向于以最大间隔的原则进行分类,但会牺牲一定的训练集和测试机的正确率。
(2)核函数gamma值,由于高斯核函数和sigmoid核函数处理大样本时效果更好,高斯核函数和多项式核在处理向量维数较高的问题上效果更好,因此核函数的选择也是需要进行优化的,判断哪种核函数更适合当下的数据集特征。其中,高斯核、sigmoid核和多项式核都含有一个重要参数——γ值,gamma值越大,说明样本在空间中散布越稀疏,数据点的间隔越远,越容易被分类平面分开,训练集正确率也就越高,但也容易出现过拟合现象。
网格搜索法对SVM模型参数寻优流程如图二所示:
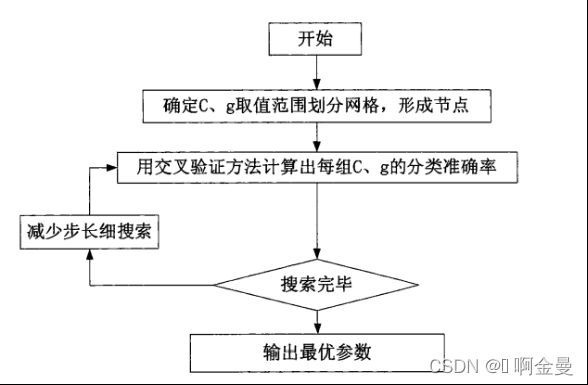
图3.2 网格搜索法的寻优流程
具体代码如下:

图3.3 利用网格搜索法进行参数寻优
 图3.4 训练构建支持向量机模型
图3.4 训练构建支持向量机模型
3.3 构建SVM模型预测月度表现最好和最差的股票
得到最优参数后,利用训练集训练模型,然后将训练好的SVM模型来预测测试集,预测出测试集中收益率最高的前30%的股票,标签设为1,收益率最低的后30%的股票,标签设为-1。

图3.5 模型预测与评价代码
3.4 模型评价
将预测的标签结果与真实的标签进行对比,模型的accuracy和AUC等评价指标如下所示,可知,模型预测的正确率总体来说大于50%,AUC最大值为0.6。
#--------SVM类,训练SVM模型并进行预测----------
from jqdatasdk import *
import data
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split #拆分数据集
from sklearn import svm #支持向量机
from sklearn.model_selection import GridSearchCV #网格搜索法
from sklearn import metrics #用于模型评估
import math
import os
import warnings
warnings.filterwarnings("ignore")
global date_list
global stock_list
date_list = data.get_period_date(data.para.peroid, data.para.start_date, data.para.end_date)
stock_list = data.get_stock(data.para.stock_pool, '2021-01-01')
factor_solve_data = pd.read_csv('C:/Users/DEL/after.csv')
factor_solve_data = factor_solve_data.set_index('code')
test_data = pd.read_csv('C:/Users/DEL/data2.csv')
test_data = test_data.set_index('code')
train_data = pd.read_csv('C:/Users/DEL/data1.csv')
train_data = train_data.set_index('code')
# 设置训练集与交叉验证集
def factor_select(df):
if data.para.type == 'all':
x_in_sample = df.loc[:, 'market_cap':'debtequityratio']
if data.para.type == 'value':
x_in_sample = df.loc[:, 'market_cap':'pcf_ratio']
if data.para.type == 'growth':
x_in_sample = df.loc[:, ['market_cap','roe','roa','profitmargin_q','gross_profit_margin','inc_revenue_year_on_year','inc_net_profit_year_on_year']]
if data.para.type == 'quality':
x_in_sample = df.loc[:, ['market_cap','asset_liability_ratio','total_assets_turnover','current_ratio','financial_leverage','debtequityratio']]
return x_in_sample
x_in_sample = factor_select(train_data)
y_in_sample = train_data.loc[:, 'label']
# 网格搜索法
# 将超参数范围包成字典
# Hyperparameter = dict(C=data.para.C, kernel=data.para.kernel, gamma=data.para.gamma)
# # 支持向量机中的SVC模型
# grid = GridSearchCV(estimator=svm.SVC(), param_grid=Hyperparameter, scoring='roc_auc', cv=10, refit='roc_auc')
# # 模型在训练数据集上的拟合
# grid_result = grid.fit(np.array(x_in_sample), np.array(y_in_sample))
# # 返回最佳参数组合
# print('最优参数:%f using %s' % (grid_result.best_score_, grid_result.best_params_))
def svm_train():
m = 10
train_score = []
cv_score = []
train_auc = []
cv_auc = []
# 获取模型
# SVC = svm.SVC(C=10,gamma=1,kernel='rbf')
SVC = svm.SVC(C=0.01, gamma=0.1, kernel='rbf')
for i in range(m):
# 随机获取10%的数据作为交叉验证集
x_train, x_cv, y_train, y_cv = train_test_split(x_in_sample, y_in_sample, test_size=0.1)
# 模型训练
SVC.fit(x_train, y_train)
# 模型预测
train_predict = SVC.predict(x_train)
cv_predict = SVC.predict(x_cv)
# 样本内训练集正确率
train_score.append(SVC.score(x_train, y_train))
# 交叉验证集正确率
cv_score.append(SVC.score(x_cv, y_cv))
# 样本内训练集auc值
train_auc.append(metrics.roc_auc_score(y_train, train_predict))
# 交叉验证集auc值
cv_auc.append(metrics.roc_auc_score(y_cv, cv_predict))
print('样本内训练集正确率:', np.mean(train_score))
print('交叉验证集正确率:', np.mean(cv_score))
print('样本内训练集AUC:', np.mean(train_auc))
print('交叉验证集AUC:', np.mean(cv_auc))
return SVC
SVC = svm_train()
def svm_predict():
# SVM模型预测
test_score = []
test_auc = []
length = len(date_list)
global train_length
global y_score_test
train_length = int(length * data.para.train_percent)
y_true_test = pd.DataFrame(index=stock_list, columns=date_list[train_length:-1])
y_predict_test = pd.DataFrame(index=stock_list, columns=date_list[train_length:-1])
y_score_test = pd.DataFrame(index=stock_list, columns=date_list[train_length:-1])
svm_test = pd.DataFrame()
for date in date_list[train_length:-1]:
print(date)
svm_test = test_data[test_data['date'].isin([date])]
x_cur_month = factor_select(svm_test)
y_cur_month = svm_test.loc[:, 'label']
if data.para.method == 'SVM':
y_pred_cur_month = SVC.predict(x_cur_month)
y_score_cur_month = SVC.decision_function(x_cur_month)
# 保存预测的结果
y_true_test.loc[svm_test.index, date] = svm_test['pchg']
y_predict_test.loc[svm_test.index, date] = y_pred_cur_month
y_score_test.loc[svm_test.index, date] = y_score_cur_month
# 模型评价
print('test set,' + date + ',accuracy = %.2f' % (metrics.accuracy_score(y_cur_month, y_pred_cur_month)))
print('test set,' + date + ',AUC = %.2f' % (metrics.roc_auc_score(y_cur_month, y_score_cur_month)))
return y_score_test
def select_stock(y_score_test,date_list):
# 策略构建
# 选股
n_stock_select = 10
date_list = list(date_list)
security_select = {}
i = 1
for date in date_list[train_length:-1]:
y_score_curr_month = y_score_test.loc[:,date]
y_score_curr_month = y_score_curr_month.sort_values(ascending=False)
security_select[date] = list(y_score_curr_month[0:n_stock_select].index)
i += 1
return security_select4 回测框架设计
本文设计的量化选股交易策略如下:
设置每个月的最后一个交易日为调仓日,在调仓日根据SVM模型的预测结果,选取SVM模型预测的下个月上涨概率最高的前十只股票构建投资组合,买进选出的股票,卖出未选中的股票,采取等权重选股,即对持仓的十只股票的仓位分配为等权重的,因此还需要根据调仓日时个股的市值对持仓进行仓位调整。选好股建好仓后,将持有该投资组合一个月,这一个月中的每一个交易日都计算该组合的收益率以及风险等指标,直至下一个调仓日,再进行选股结果进行调仓。
因此,可以将回测框架分为数据准备模块、调仓策略模块、模拟交易模块与策略评价模块,每个模块具体功能如下所示:
 图4.1 回测框架及其功能模块设计
图4.1 回测框架及其功能模块设计
4.1 数据准备模块
数据准备模块通过定义account类来实现,定义setup()函数实现参数初始化设置,定义set_dic()函数来获取历史行情数据,定义set_days()实现交易日与调仓日日期的获取。
4.1.1参数设置
进行模拟量化交易,首先需要对各种交易参数进行预设置,需要预设置的参数如下:回测开始时间(start_date),回测结束时间(end_date)、选股股票池(security)、参照基准(benchmark)、初始资金(capital_base)、印花税(stamp_duty)、交易手续费(commission)、委托下单价格滑点(slippage)。
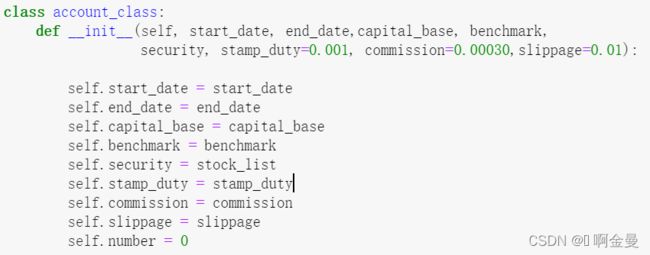
图4.2 初始参数设置
除了上述需要提前设置的参数外,还有许多需要在交易的过程中实时更新的参数,需要对其预定义,例如当天交易日的日期、持仓股票的价值、以及用于计算收益率以及最大回撤等指标时的定义。
4.1.2获取历史行情数据
为了进行模拟交易以及进行策略评价,需要获取股票池中每只股票在每个交易日的开盘价、收盘价等历史行情数据,具体步骤如下:
(1)获取回测区间每个交易日以及调仓日的日期。
(2)利用jqdata提供的API接口,获取股票池中每只股票和参照基准(沪深300股指)在每个交易日的收盘价等历史行情数据。
核心代码如下:
 图4.3 交易日与调仓日的设置
图4.3 交易日与调仓日的设置

图4.4 获取股票池与参照基准的历史交易行情数据
4.2 调仓策略模块
根据前文对交易策略的描述可知,策略的重点就是每个月最后一个交易日根据SVM模型的预测结果进行选股,并进行调仓,定义rebalance_portofolio函数实现在每个调仓日执行调仓策略的功能,核心代码如下:

图4.5 建仓与调仓代码
4.3 模拟交易模块
本文定义order_function函数进行模拟交易,本文的模拟交易功能模块根据策略需求进行了调整,不再采用根据操作指令分别设计买入与卖出操作功能的实现方式,而是首先通过对持仓进行判断,然后根据判断结果进行买入卖出操作,此外,还要根据等权重选股的仓位进行仓位管理,流程如下:
 图4.6 模拟交易模块设计流程图
图4.6 模拟交易模块设计流程图
在设计模拟交易的过程中,按照现实生活中股票交易的规则展开。注意点如下:
(1)根据规定,我国交易股票以一手(100股)为单位,也就是说股票买入和卖出交易必须为100的整数倍(除了在分红送股或增股的情形下导致持仓股数不是100的整数倍时除外)
(2)我国没有做空机制,即投资者如果预期股价未来会下跌,他不能通过高价融券卖出,待价格下跌后买入股票赚取差价。因此在设计模拟交易时必须判断是否持仓,不能够卖出并不持有的股票。
(3)滑点的应用,滑点=(下单时的价格点位-最后成交的点位),导致滑点的原因有交易系统等硬件的技术条件限制以及市场价格的跳空等等,因此为了确保买单和卖单的执行,防止跳单的情况,对买单进行(当前价格+滑点)的价格进行下单,对卖单进行(当前价格-滑点)的价格下单。
(4)模拟买单时,需要进行判断持有的现金是否足够购买买单的股票数量,若金额不够则需对下单的手数进行调整。
核心代码如下图所示:

图4.7 模拟卖出交易代码
 图4.8 模拟买入交易代码
图4.8 模拟买入交易代码
4.4 量化选股模型的绩效评价
通过资产组合收益率以及风险的相关指标,可以评价组合的优劣,根据金融学理论,风险与收益是对等的,我们不能说收益率越高,投资组合的表现越好,因为忽视了投资者在该收益下承担的风险,因此,我们需要综合收益与风险指标进行评价。本文计算投以下指标作为绩效评价的依据。

核心代码如下:

图4.9 计算每日的收益率与最大回撤指标代码
将得到的结果进行可视化,部分代码如下:
 图4.10 结果可视化代码
图4.10 结果可视化代码
#-------backtrade类,回测框架----------
# -*- coding: utf-8 -*-
# @Time : 2021/5/18 16:54
# @Author : LMQ
# @File : backtrade.py
# @Software : PyCharm
import data
import svm
import numpy as np
import pandas as pd
from jqdatasdk import *
import matplotlib.pyplot as plt
import math
date_list = data.get_period_date(data.para.peroid, data.para.start_date, data.para.end_date)
stock_list = data.get_stock(data.para.stock_pool, '2021-01-01')
y_score_test = svm.svm_predict()
security_select = svm.select_stock(svm.y_score_test,date_list)
date_list = date_list[svm.train_length:-1]
print(date_list)
print(stock_list)
print(security_select)
# --------------------------参数预定义与数据准备------------------------------
class account_class:
def __init__(self, start_date, end_date, capital_base, benchmark,
security, stamp_duty=0.001, commission=0.00030, slippage=0.01):
self.start_date = start_date
self.end_date = end_date
self.capital_base = capital_base
self.benchmark = benchmark
self.security = stock_list
self.stamp_duty = stamp_duty
self.commission = commission
self.slippage = slippage
self.number = 0
self.ini_dic = None
self.benchmark_data = None
self.trade_days = None
self.order_days = None
self.today_capital = None
self.ret = None # 计算 return 收益率
self.history_max = None
self.drawdown_start = None
self.drawdown_end = None
self.capital = None
self.cash = None
self.today = None
def setup(self):
self.ini_dic = {}
self.benchmark_data = pd.DataFrame()
self.ret = pd.DataFrame() # 收益率为 df
self.history_max = 0
self.capital = []
self.cash = capital_base
# 调用函数
self.set_dic() # 调用不用写 self
self.set_days() # 调用不用写 self
def set_dic(self):
for stock in self.security:
try:
security_data = get_price(stock,
start_date=self.start_date,
end_date=self.end_date,
frequency='daily',
fields=['open', 'close'],
).sort_index()
self.ini_dic[stock] = security_data
except Exception:
self.security.remove(stock)
print("Stock ", stock, " data unavailable.")
try:
data1 = get_price(self.benchmark,
start_date=self.start_date,
end_date=self.end_date,
frequency='daily',
fields=['open', 'close'],
).set_index('time')
self.benchmark_data = data1
except Exception:
print("Benchmark ", self.benchmark, " data unavailable.")
def set_days(self):
self.trade_days = self.benchmark_data.index
temp = account.benchmark_data.copy()
temp['date'] = self.benchmark_data.index
temp = temp.resample('M').first().set_index('date')
self.order_days = temp.index
# --------------------------执行策略——调仓------------------------------
def rebalance_portfolio(security_select, date):
global holding
security = security_select[date_list[account.number]]
print(security)
account.number += 1
ini_dic = account.ini_dic
today_capital = account.today_capital
positions = pd.Series()
price_data = pd.Series()
target = pd.Series() # 保存 股票数量的序列
# 初次建仓
if account.number == 1:
holding = pd.DataFrame({'amount': [0],
'price': [0],
'value': [0],
'percent': [0]},
index=security)
# 仓位设置
for stock in security:
positions[stock] = 1 / len(security)
price_data = ini_dic[stock].loc[date.strftime('%Y-%m-%d')]
price = price_data['open']
print(stock, price)
target[stock] = int((positions[stock] * today_capital) / price / 100) * 100
print(target)
order_function(target, date)
# --------------------------模拟交易操作------------------------------
def order_function(target, date):
global holding
ini_dic = account.ini_dic
stamp_duty = account.stamp_duty
commission = account.commission
slippage = account.slippage
# 卖出持有的股票
print(holding.index)
for stock in list(holding.index):
if stock not in target.index:
print('以月底的收盘价卖出')
price_data = ini_dic[stock].loc[date.strftime('%Y-%m-%d')]
price = price_data['close']
# 计算资金=数量*开盘价
account.cash += holding.loc[stock, 'amount'] * (price - slippage) * (1 - stamp_duty - commission)
print('sell_order: ', stock, 'amount ', - holding.loc[stock, 'amount'])
holding = holding.drop(stock) # bug
# 买入选股池股票
for stock in list(target.index):
stock_data = ini_dic[stock].loc[date.strftime('%Y-%m-%d')]
price = stock_data['open'] # 获取股票的开盘价
if stock not in list(holding.index):
holding = holding.append(pd.DataFrame({'amount': [0],
'price': [0],
'value': [0],
'percent': [0]},
index=[stock]))
if holding.loc[stock, 'amount'] > target[stock]:
account.cash += (holding.loc[stock, 'amount'] - target[stock]) * (price - slippage) * (
1 - stamp_duty - commission)
if holding.loc[stock, 'amount'] < target[stock]:
# Attention: buy hand by hand in case cash becomes negative
for number in range(int(target[stock] / 100), 0, -1):
if (account.cash - (number * 100 - holding.loc[stock, 'amount']) * (price + slippage) * (
1 + commission)) < 0:
continue
else:
account.cash -= (number * 100 - holding.loc[stock, 'amount']) * (price + slippage) * (
1 + commission)
break
if holding.loc[stock, 'amount'] - target[stock] != 0:
print('order: ', stock, 'amount ', int(target[stock] - holding.loc[stock, 'amount']))
holding.loc[stock, 'amount'] = target[stock]
holding.loc[stock, 'price'] = price
holding.loc[stock, 'value'] = holding.loc[stock, 'price'] * holding.loc[stock, 'amount']
holding['percent'] = holding['value'] / sum(holding['value'])
# --------------------------计算最大回撤------------------------------
def drawdown(): # 必须在【每个交易日】计算最大回撤,【声明/访问/全局变量】或者【通过参数,传入date】
global account
date = account.today
print('drawdown_date', date)
today_capital = account.today_capital # 获取当日的资金
trade_days = account.trade_days # 必须在每个交易日 计算最大回撤
account.capital.append(today_capital) # 将【今天的资金量】 累加到account.capital中
# 计算公式 前n-1天资金的最大值 减 第n天的资金 除以 第n天的资金
try:
drawdown = (max(account.capital[:-1]) - account.capital[-1]) / \
max(account.capital[:-1])
except Exception:
drawdown = 0
if drawdown > account.history_max: # 大于历史最高,保存为最大,和日期
account.drawdown_start = trade_days[account.capital.index(max(account.capital[:-1]))]
account.drawdown_end = trade_days[account.capital.index(account.capital[-1])]
account.history_max = drawdown # 最大值保存
# ----------------------------------计算收益率结果-------------------------------------
def ret(): # 必须在【每个交易日】【计算收益率结果】,【声明/访问/全局变量】或者【通过参数,传入date】
global account
benchmark = account.benchmark # 列索引
# print(code1)
# 每个交易日计算 收益率的df,并累加到df
# print(account.benchmark_data)
date = account.today # 当天的日期
trade_days = account.trade_days
print('当天的日期为:', date)
# print('当天的日期为:',date.strftime('%Y-%m-%d'))
account.ret = account.ret.append(
pd.DataFrame(
{
'rev': (account.capital[-1] - account.capital[0]) / account.capital[0],
'max_drawdown': account.history_max,
'benchmark':
(account.benchmark_data.loc[date, 'close'] -
account.benchmark_data.loc[trade_days[0], 'close']) /
account.benchmark_data.loc[trade_days[0], 'close']},
index=[date]
)
)
print('account.capital每天的资金量列表:', account.capital)5、结果分析
基于支持向量机的选股模型的表现如下,收益率为254.34%,年化收益率为86.60%,对比参照基准沪深300股指的收益率可知,基于SVM模型选出的股票组合收益率将近是参照基准的4-5倍,最大回撤率为16.30%,可知执行该策略最坏的可能性是跌16.30%,夏普率为26.26,说明在承担一单位风险可以获得24.60的超额收益率,总得来说,该选股模型选出来的投资组合表现出很好的收益率,风险指标也控制在可以接受的程度内。

图5.1 策略的收益率表现
为了进一步比较分析,在当下中国的股市中,究竟哪一类的因子更为有效,表现更好,本文对价值因子、成长因子以及品质因子均进行了回测,回测结果如下:

图5.2 不同因子策略的收益率对比
表5-1 不同因子策略的评价指标表
| indicator |
All strategy |
Value strategy |
Growth strategy |
Quality strategy |
| benchmark return |
59.81% |
59.81% |
59.81% |
59.81% |
| Strategy return |
254.34% |
189.45% |
288.47% |
180.46% |
| Strategy annual return |
86.60% |
68.89% |
95.26% |
66.28% |
| annual_sharpe_ratio |
24.60 |
36.54 |
21.47 |
26.75 |
| Max drawdown |
16.30% |
20.38% |
13.15% |
9.58% |
| Max drawdown interval |
2020-01-03 to 2020-02-04 |
2019-04-22 to 2019-05-08 |
2020-01-23 to 2020-02-04 |
2020-02-24 to 2020-03-23 |
从上述分析可以得知,在我国当前股市下,估值因子表现最不好,其收益指标较低而回撤率较高,这可能与我国股市的机制不健全,投机炒作的风气盛行有关,导致市场估值机制失灵,而这种炒作都是暂时性的盈利,一旦热度过去,反而会跌的更惨,长期来看很难持续,表现最好的是成长性因子,单独的成长因子选股甚至好过了同时考虑三种因子的选股,因此可以说,目前状况下,成长性因子选股更具有参考和指导意义。