学习腾讯的NLP文本分类
背景:照例先说背景,笔者是O厂数据挖掘工程师一枚,负责广告标签挖掘工作,实质就是给广告主大大找最适合投放广告的一批手机用户,考核指标主要有点击率CTR、下载率、注册率、首日ROI(就是当天用户注册充值的金额比上广告主大大的成本)等。我们的数据源主要有app、咨询、url、ad和query。拿app来说,我们有用户使用app的数据。这样user-app表有了,然后我们构建标签体系生成app-tag表,其实就是给app打上标签。比如:“传奇盛世”打上传奇标签。用户使用了传奇盛世标签,我们就会给这个用户打上传奇的标签。根据用户使用传奇盛世app的情况会有不同的得分,比如经常付费、下载、注册等行为得分就高,就更容易给这类用户曝光传奇类的广告。通过user-app表和app-tag表,我们可以得到user-tag表。这样我们就完成了给用户打标签的工作。
我目前主要负责app和query数据源,其中理解query比较麻烦,主要是因为用户的输入不规范等原因理解query搜索词本身比较难。通过理解用户搜索完之后点击了某个网页来挖掘用户的兴趣可行性更高,所以主要理解用户点击的url,这个url会有title。title类似于文章标题或者url的标题,很规范,也更容易理解。目前负责理解title(短文本识别工作),其实就是将title打上相对应的兴趣标签。
过程:现在主要学习腾讯开源的文本分类github工程NeuralClassifier。
https://github.com/Tencent/NeuralNLP-NeuralClassifier
现在就开始学习吧
使用的开发环境是 intelli ide,原因是该编译器既可以写java、scala程序,还能写python程序。
必须的包:
torch_nightly>=1.0.0.dev20190325 numpy>=1.16.2 torch>=1.0.1.post2。
安装torch:1.先确保安装python 3.X 64位;
2.然后输入一下命令。因为先是用本地电脑跑的,没有GPU,所以安装的NONE CUDA版本。
pip3 install https://download.pytorch.org/whl/cpu/torch-1.1.0-cp37-cp37m-win_amd64.whl
pip3 install https://download.pytorch.org/whl/cpu/torchvision-0.3.0-cp37-cp37m-win_amd64.whl支持的任务:
二分类文本任务、多分类文本任务、多标签文本分类和多层级多标签文本分类任务。
这里我们的一个title对应多个标签,所以应该是多标签文本分类任务。
支持的文本编码器:
- TextCNN (Kim, 2014)
- RCNN (Lai et al., 2015)
- TextRNN (Liu et al., 2016)
- FastText (Joulin et al., 2016)
- VDCNN (Conneau et al., 2016)
- DPCNN (Johnson and Zhang, 2017)
- AttentiveConvNet (Yin and Schutze, 2017)
- DRNN (Wang, 2018)
- Region embedding (Qiao et al., 2018)
- Transformer encoder (Vaswani et al., 2017)
- Star-Transformer encoder (Guo et al., 2019)
系统架构:
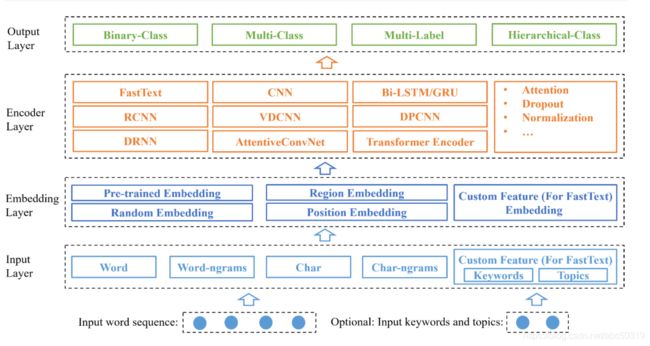
输入:语句(必须),关键词和主题(可选项)
输出:类别
工程使用:
整个文件目录大概是这样的:
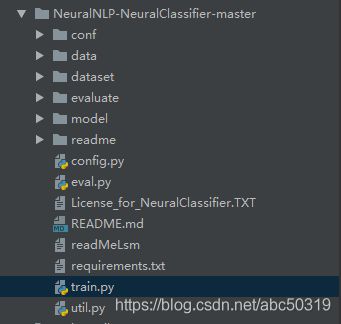
conf:里面包含train.json文件,主要是相关的配置文件(输入输入目录、模型超参数等)。
data:数据目录,训练、测试、验证数据集。
1.模型训练:
python train.py conf/train.json详细的配置和描述在这里:Configuration
训练相关的信息会输出到 log.logger_file日志文件中。
2.模型评估:
python eval.py conf/train.json- if eval.is_flat = false, hierarchical evaluation will be outputted.
- eval.model_dir is the model to evaluate.
- data.test_json_files is the input text file to evaluate.
模型评估的信息会输出到eval.dir。
输入的数据格式
JSON example:
{
"doc_label": ["Computer--MachineLearning--DeepLearning", "Neuro--ComputationalNeuro"],
"doc_token": ["I", "love", "deep", "learning"],
"doc_keyword": ["deep learning"],
"doc_topic": ["AI", "Machine learning"]
}
"doc_keyword" and "doc_topic" are optional.