使用 Pytorch 实现 GAN
使用 Pytorch 实现 GAN
文章目录
- 使用 Pytorch 实现 GAN
- 前言
- 一、什么是GAN?
- 二、代码讲解
-
- 1.生成器(Generator)
- 2.判别器(Discriminator)
- 3.全部代码
- 总结
前言
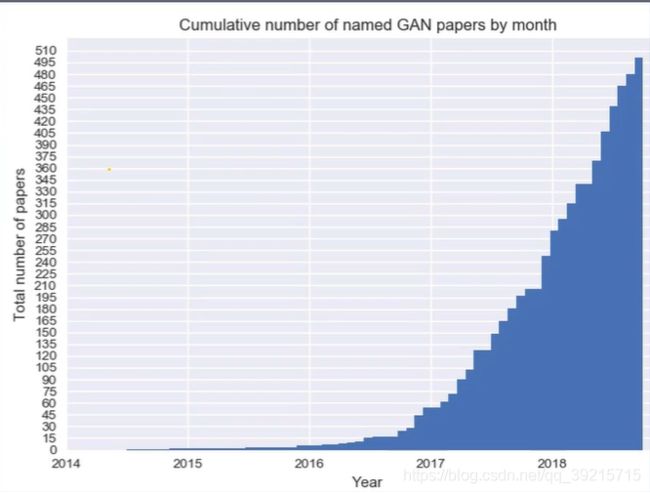
自 2014 年 Ian Goodfellow 提出了 GAN(Generative Adversarial Network)以来,对 GAN 的研究可谓如火如荼,各种 GAN 的变体不断涌现。
下图是 GAN 相关论文的发表情况:
Yann LeCun 评价 GAN 为 “adversarial training is the coolest thing since sliced bread”。那么到底什么是 GAN 呢?它又好在哪里?
一、什么是GAN?
GAN 结构如图1所示,包含了一个生成器(Generator)和一个判别器 (Discriminator)。生成器的目的是生成以假乱真的图片,而判别器的目的是尽可能区分输入图片的真假。
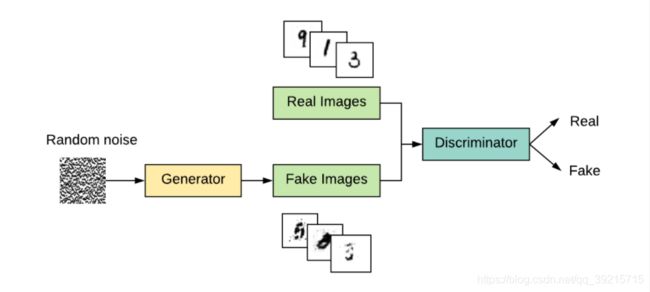
举一个简单的例子,比如说假钞的流通。犯罪分子希望制作出逼真的假钞,可是警察的鉴定技术也在不断改良,双方互相博弈,互相提高,最终达到一种动态的平衡。讲到这里,是不是感觉很简单?实际上就是生成器和判别器两者动态博弈,最终达到平衡的过程。
二、代码讲解
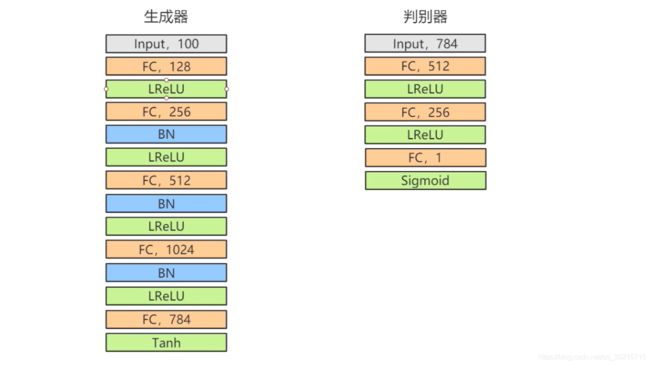
在本实验中,生成器和判别器的相应结构如下图所示。
1.生成器(Generator)
代码如下:
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 类似于残差网络,将网络层封装起来,默认每次进行一次BN,然后再使用先线性激活函数LeakyReLU()
def block(in_feat, out_feat, normalize=True):
# 利用 layers 存储网络,形成网络块
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
# np.prod(img_shape) 是计算图片的维度,比如图片的尺寸时28*28,np.prod(img_shape) = 784
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
2.判别器(Discriminator)
代码如下:
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
nn.LeakyReLU() 中默认 inplace=False, 这个inplace意思:是否将计算得到的值直接覆盖之前的值。
如果,inplace=True,那么就是会对原变量覆盖,没有通过中间变量,直接覆盖原变量的值。
如果,inplace=False,通过中间变量,没用覆盖之前变量的值。
这样就可以节省内(显)存,同时还可以省去反复申请和释放内存的时间。
所以 inplace=True 和 inplace=False 对计算结果没用影响,只是计算时,是否覆盖原变量的值的区别。
3.全部代码
代码如下:
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
#如果有显卡,就在显卡(GPU)上进行训练,否则就在CPU上进行训练
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# Loss function
#使用 BCE Loss function 该损失函数主要用来创建衡量目标和输出之间的二进制交叉熵的标准。
#而在平常我们会更多的使用 CE(CrossEntropyLoss)
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Configure data loader
#加载数据集,平常见的很多
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers,使用了Adam 优化器
#参数 betas (Tuple[float, float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Adversarial ground truths
# 因为 batch 是64,所以在这里 imgs.size(0) = 64
# 这两句话本质就是为64张真图片和64张假图片打上标签,真图片标签为1,假图片标签为0
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
总结
这是最后面生成的数字,跑完之后总体来说还是不错的,大部分都可以较为直接的看出数字,少部分也有模糊的情况。

以上就是今天要讲的内容,本文仅仅简单实现了GAN网络,对于如何证明最后会达到平衡,即最后辨别器的识别率达到 0.5,GAN又是如何引入JS散度等一些理论知识,还请移步知乎、CSDN论坛、B站等平台,他们都有详细讲解。
代码来源于Github,还有一些其它很经典的网络,有时间大家一起学习。
代码来源:https://github.com/eriklindernoren/PyTorch-GAN.