中国人民大学文继荣:搜索,从相关性到有用性
整理 | Mr Bear
在今年智源大会上,中国人民大学高领人工智能学院执行院长、北京智源人工智能研究院首席科学家文继荣教授以「从相关性到有用性」为线索,对搜索技术的发展历程以及未来的研究方向进行了梳理和展望。

图 2:搜索发展的三个阶段
上世纪 90 年代,互联网刚刚兴起。彼时,我们将搜索任务定义为语法匹配。起初搜索技术面向的用户和任务较少,Google 研制的第一个搜索引擎索引了 2000 多万网页。搜索技术最早的受众人群是图书管理员、读者,以及早期的网民,当时语法匹配方法就可以满足搜索的要求。

图 3:语义匹配阶段
随着互联网的发展,搜索技术逐渐向语义匹配发展。此时出现了更多样化、多噪声的数据,受众也逐渐发展为了大量的互联网网民。我们希望搜索系统能够理解用户表达的并不清晰、完整的查询,因此进行准确的语义的理解是非常关键的。

图 4:语用匹配
目前,搜索技术正在向语用匹配过渡。在未来的移动互联网等场景中,我们需要能够随时随地进行搜索,得到理想的答案,从而帮我们完成任务。汽车未来也可能成为一个重要的搜索场景,移动的环境中存在多种可以随时随地获取信息的传感器,帮助人类完成各种任务。

图 5:语用匹配的关键因素
为了实现搜索技术从相关性到可用性的革新,我们需要考虑以下 3 个关键的因素:
(1)循因果、可解释。挖掘出事物内在的运行规律,做到知其然且知其所以然。
(2)多轮交互。未来的搜索系统应该扮演人类助手的角色,人类可以与之进行交互,而不仅仅只是单独完成一次次的查询。
(3)多模态。结合多个模态的数据帮助人类作出决策。
1基于因果的搜索技术初探
第一,基于因果的搜索。因果性不光是信息检索领域,各个领域都非常关注,这就是为什么要知其所以然。现在有很多模型,包括悟道2.0预训练模型,还主要是基于相关性而非因果性的。

图 6:基于相关性的智能
基于因果的智能是当下多个研究领域的热点问题。目前我们建立的大多数智能系统仍然是以相关性为基础的,它们存在诸多不足之处。
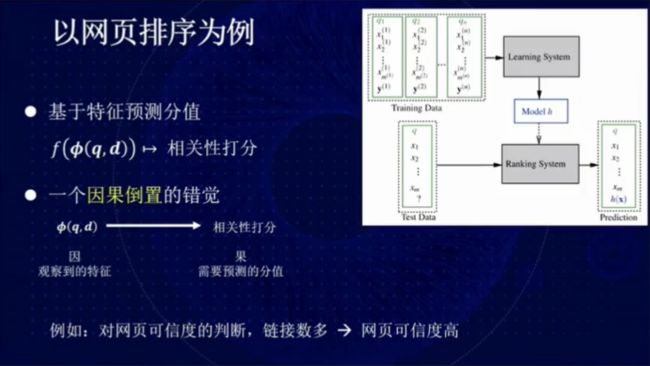
图 7:网页排序
以网页排序为例,在使用 PageRank 算法时,我们假设网页的链接数越则多网页的可信度和重要性越高。然而,实际上这种假设将因果倒置了。真正的因果可能是,网页质量高导致网页的链接数较多。
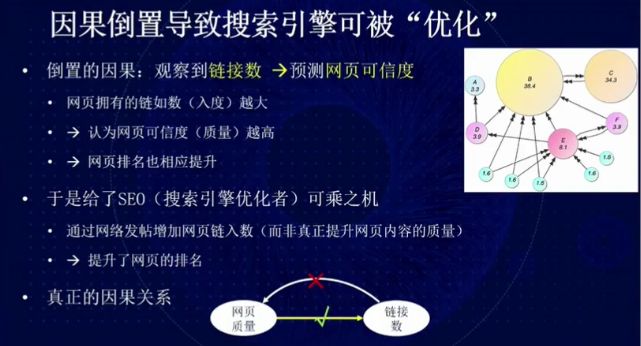
图 8:因果关系倒置的影响
而如果我们将上述因果关系倒置,该漏洞可能会被「搜索引擎优化者」(SEO)利用。SEO 可以通过「灌水」增加网页的链接数,从而提升网页的排名,即 Link Spam。
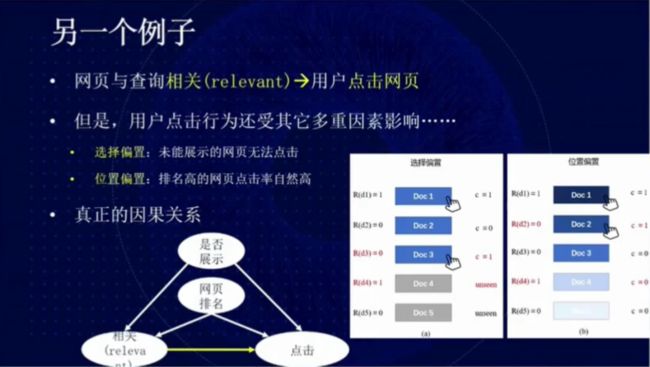
图 9:真正的因果关系
此外,用户点击行为还会受到选择偏置和位置偏置等因素的影响。排名靠前的网页被点击的可能性往往较大,排在后面的点击率则较小。如果某网页没有被排在第一页,它甚至没有机会被点击。以往的搜索系统大多没没有考虑选择偏置和位置偏置。实际上,「是否展示」、「网页排名」、「点击」和「相关性」会构成复杂的因果关系,我们不应该简单地构建点击率与网页排名的相关性。
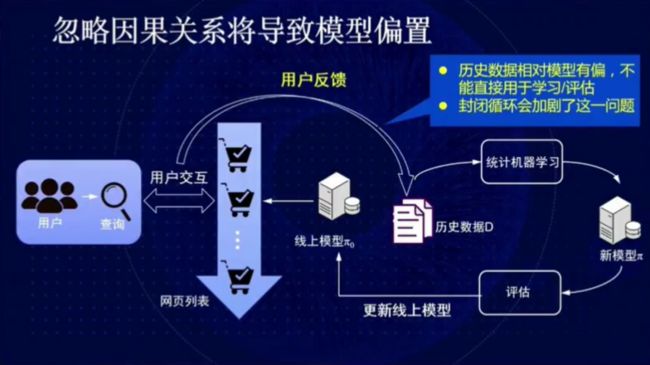
图 10:忽略因果关系将导致模型偏置
在搜索系统中,我们可以利用用户的反馈结果改进排序算法,而这一过程会使上述偏置不断在系统中积累。可见,忽略因果关系将导致模型偏置对系统性能的影响越来越大。

图 11:基于因果技术的搜索
未来,我们需要将因果推断集成到搜索引擎中,从而实现更可信、公平、可解释的搜索,使搜索引擎不易被攻击、不受到偏置因素的影响、解释得到搜索结果的理由。
2面向信息检索的反事实学习
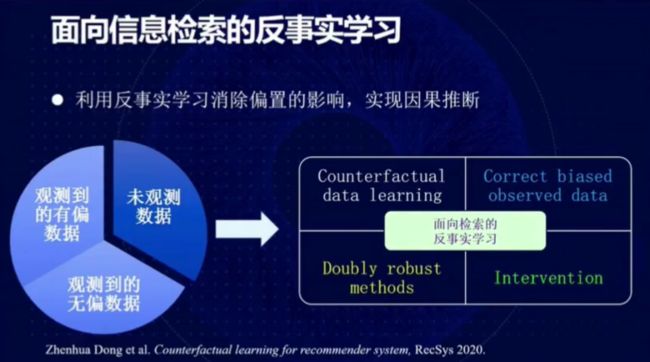
图 12:面向信息检索的反事实学习
信息检索可以利用反事实学习消除偏置的影响,从而实现因果推断。反事实技术指的是通过改变某些条件,并观察改变条件之前的结果是否还会发生,从而判断该条件对结果的影响。
在该场景下,我们一般会处理三种数据:(1)观测到的有偏数据;(2)观测到的无偏数据;(3)未观测数据。
面向检索的反事实学习包含四个部分:(1)反事实数据学习(2)对观测到的有偏数据进行校正(3)双鲁棒方法,同时处理未观测到的数据和观测到的有偏数据(4)通过干预方法结合观测到的有偏和无偏数据
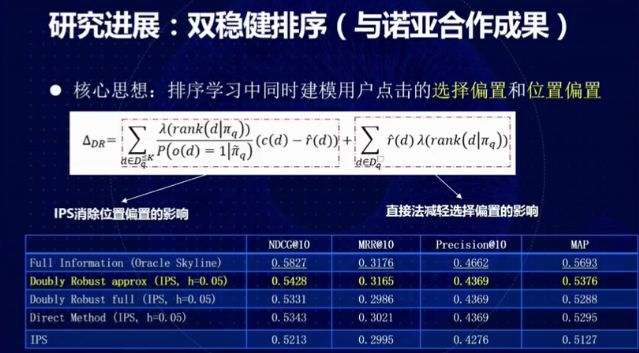
图 13:双稳健排序
我们与华为诺亚方舟实验室合作设计了一种双稳健排序算法,可以在排序学习过程中同时对选择偏置和位置偏置建模,同时处理观测到的有偏数据和未观测的数据,通过 IPS 消除位置偏置的影响,用直接法消除选择偏置的影响。
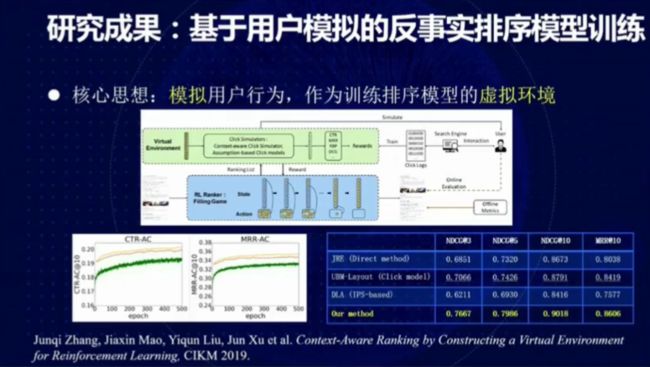
图 14:基于用户模拟的反事实排序模型训练
我们可以直接将用户的点击日志和深度学习模型组合起来模拟用户的行为,构建一个训练排序模型的虚拟环境,并基于该环境对未观测的数据做反事实学习。
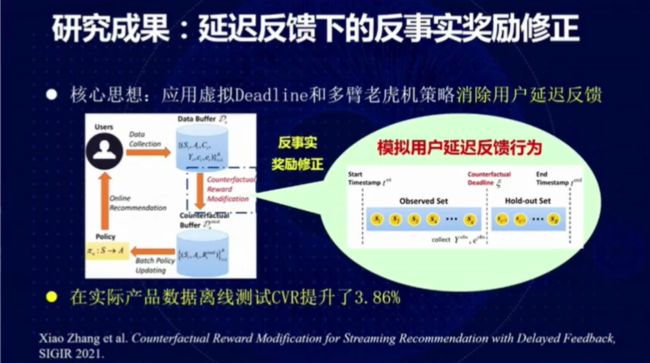
图 15:延迟反馈下的反事实奖励修正
在我们最近被 SIGIR 2021 接收的论文「Counterfactual Reward Modification for Streaming Recommendation with Delayed Feedback」中,我们用反事实约束的方法消除用户的延迟反馈。具体而言,我们利用模拟的延迟反馈构建反事实的 Deadline,并采取了多臂老虎机强化学习策略,从而将实际产品数据离线测试的 CVR 提升了 3.86%。
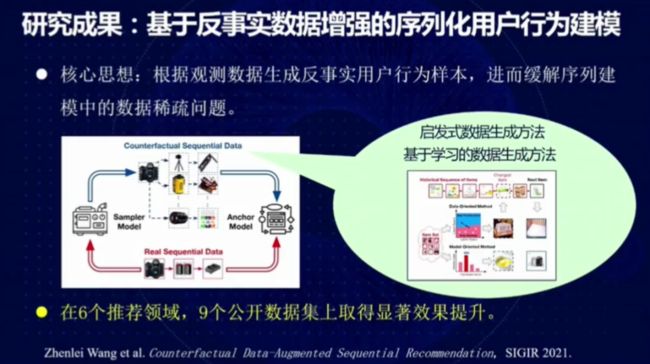
图 16:基于反事实数据增强的序列化用户行为建模
推荐任务中往往存在数据稀疏的问题。比如,用户购买了商品 A,后面又浏览或者购买了其它的商品。我们可以利用反事实技术,假设该用户没有购买商品 A,预测他接下来的行为。在 SIGIR 2021 论文「Counterfactual Data-Augmented Sequential Recommendation」中,我们用反事实数据进行数据增强,根据观测数据生成反事实用户行为样本,进而缓解了序列建模中的数据稀疏问题。
3多轮交互
多轮交互很多领域都在研究,自然语言处理、信息检索领域对其关注尤其多。我们认为未来的信息检索不是一趟式的。现在的搜索引擎强迫用户采用单轮的搜索来找答案,而更好的方式是与系统交互,有问有答,层层递进寻找答案。

图 17:交互式信息检索
多轮交互式自然语言处理、信息检索领域的另一个热门研究课题。我们希望未来的信息检索不仅仅局限于单趟交互,能够在多轮交互中从用户并不完整、清晰的表达中充分获取信息需求,这种层层递进的方式更加符合人类的使用习惯。例如,我们在订餐馆的过程中,需要通过多轮交互逐渐确定对于餐馆、菜品、交通等因素的需求。

图 18:交互式检索面临的挑战
多轮交互和信息检索的结合面临诸多挑战,例如:意图跟踪、语言问答的生成、结果的评价等。
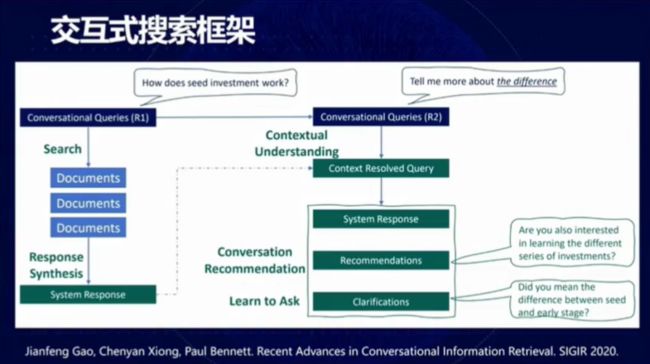
图 19:交互式搜索框架
在 SIGIR 2020 论文「Recent Advances in Conversational Information Retrieval」中,作者提出了一种交互式搜索框架。在该框架下,用户首先给出一个查询,系统会搜索到一些与查询匹配的文档,并通过将多个文档综合起来最终形成回答结果。在下一轮问答中,系统会将用户在对话中的查询和上一轮的回答结合起来生成考虑上下文信息的查询。系统在回答查询问题的同时也可以给向用户做推荐、与用户进行交互,或者反过来想用户询问一些需要进一步说明的问题。
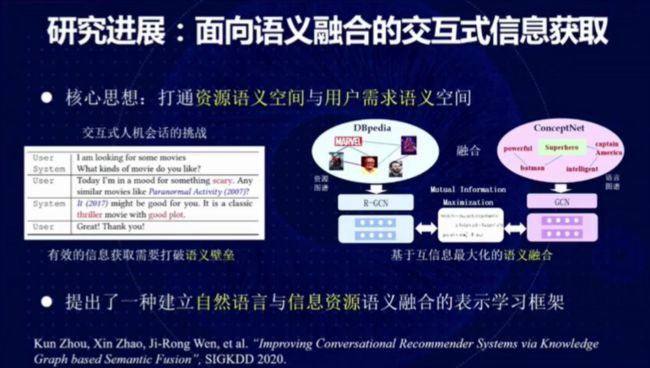
图 20:面向语义融合的交互式信息获取
问答系统除了要理解用户的问题,还需要利用信息资源语义空间中的对象的语义。为此,我们同时在资源空间和用户空间内构建了知识图谱,并分别对它们进行表示学习,然后基于互信息最大化技术对上述两个图谱进行了语义融合,从而使系统可以根据问题推测出用户关注的是哪些对象及其属性。
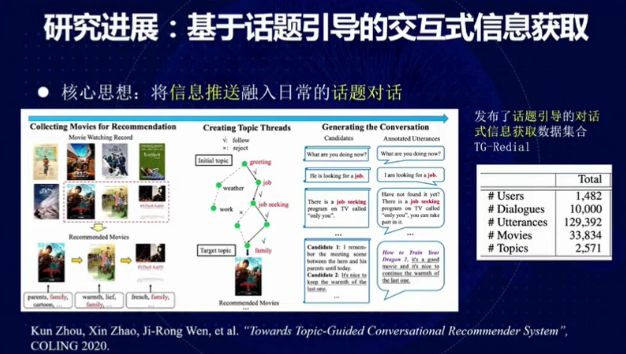
图 21:基于话题引导的交互式信息获取
我们常常希望以自然的方式在对话中进行推荐。然而,缺乏测试和训练数据集是我们面临的主要挑战,为此我们收集大量用户在推荐网站上的行为数据(例如,电影浏览的序列),从而生成对话数据,并发布了话题引导的对话式信息获取数据集 TG-Redial。
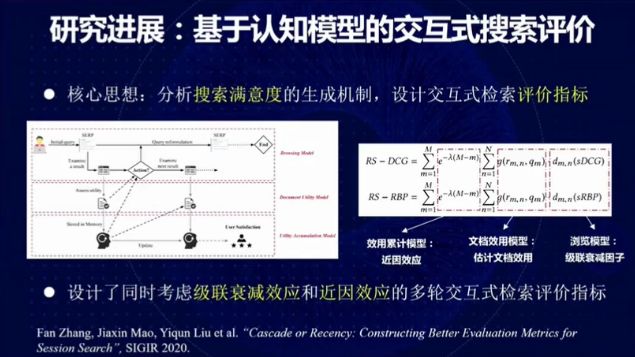
图 22:基于认知模型的交互式搜索评价
我们分析了搜索满意度的生成机制,设计了同时考虑级联衰减效应和近因效应的多轮交互式检索评价指标。具体而言,我们考虑通过以下三个模型为交互式搜索任务提供一种高质量的评价体系:
(1)浏览模型:记录用户在浏览阶段的行为(例如,点击、提问等)。
(2)文档效用模型:估计文档的效用
(3)效用累计模型:在交互式搜索中如何逐渐寻找到要理想的答案。
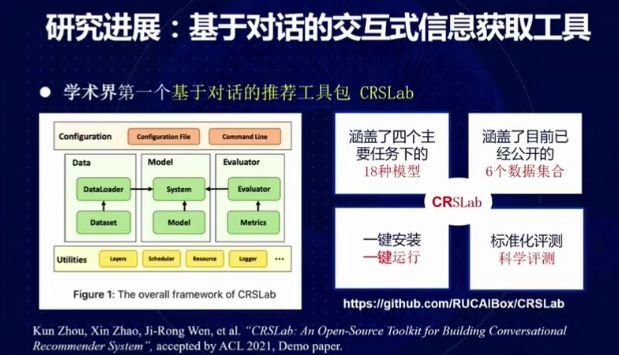
图 23:基于对话的交互式信息获取工具
我们发布了学术界第一个基于对话的推荐工具包 CRSLab,覆盖了四个主要任务下的 18 种模型和大量已公开的数据集。
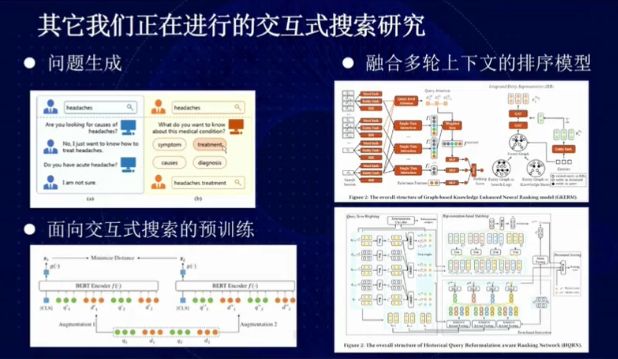
图 24:交互式搜索研究
此外,在交互式搜索领域中,我们还针对「问题生成」,「融合多轮上下文的排序模型」和「面向交互式搜索的预训练」等问题展开了研究。

图 25:推荐系统开源工具库“伯乐”
赵鑫教授团队发布了推荐系统开源工具库“伯乐”,目前已在 Github 上收获了近 1000个 Star。
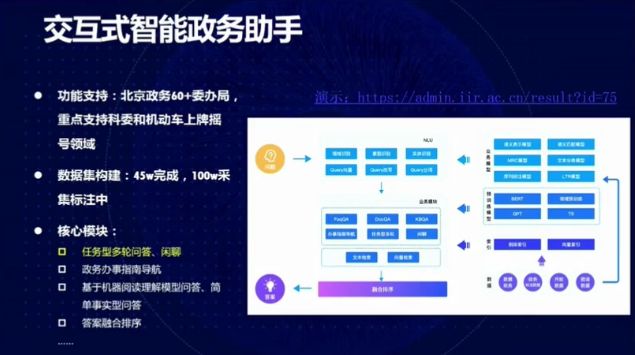
图 26:交互式智能政务助手
智源信息检索团队基于交互式搜索开发了智能政务助手。该系统的第一个版本的开发工作已经完成,具备任务型多论问答、政务办事指南导航、基于机器阅读理解的模型问答、答案融合排序等功能。
4从文本到多模态

图 27:人脑处理多模态信息的机制
多模态预训练技术对于搜索任务也具有十分重要的意义。人类在做信息搜索时往往会使用多模态的数据。在 2005 年《自然》杂志刊登的的一篇论文中,作者指出人脑会自动将对应于同一个概念的多模态信息映射到相同的语义空间的表征上,我们期望计算机也能实现同样的功能。

图 28:文澜——大规模多模态预训练模型
人脑的强大之处在于,我们可以利用弱相关的信息。例如,看到图 28 中的蛋糕,人类会想到吃蛋糕不利于减肥。目前主流的模型旨在理解图文数据间的强相关信息,中国人民大学、中科院计算所、清华大学、智源人工智能研究院联合组成的文澜团队开发了能够有效利用图文数据间弱相关信息的大规模预训练模型,更加符合实际需求。此外,文澜团队还收集了海量的数据用于模型预训练。
我们主要使用了图片和文字两个模态的数据,根据图文匹配程度对样本进行了排序,从而提升匹配精度,并使用了跨模态对比学习技术构建了双塔的 BriVL 架构。
与 OpenAI 的 CLIP 和谷歌的 ALIGN 大规模预训练模型相比,文澜模型的性能均取得了较大程度的提升。

图 29:多语言多模态预训练
此外,我们还研发了多语言多模态预训练模型,旨在结合多模态与多语言与训练的优势,利用视觉作为多种语言知识迁移的桥梁,为多模态模型提供更广阔的应用场景。

图 30:文澜多模态神经元示例——诗句
当我们向文澜模型输入诗句时,模型会自动生成符合诗句内容和意境的图像,这证明了多模态数据之间的相关性。
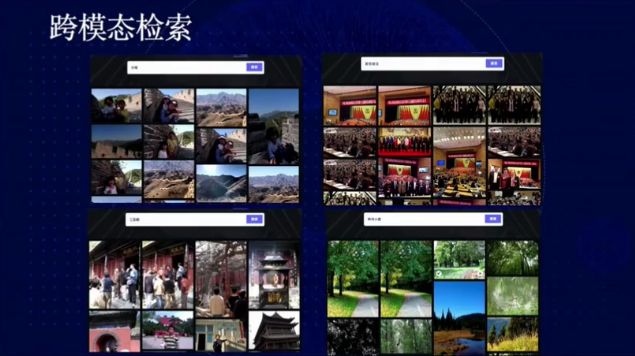
图 31:跨模态检索
基于文澜模型,我们可以实现跨模态检索,只需向系统输入关键词,就可以检索出来之前并没有标注过的图像。
5未来的研究方向
图 32:智能信息助手贾维斯
两年前,智源信息检索与挖掘团队成立时,我们的愿景就是未来能够创造出类似于电影《钢铁侠》中的智能信息助手贾维斯这样的搜索系统。

图 33:交互式个人智能信息助手
无论人类想知道什么信息,都可以通过与该系统进行对话得到最智慧的答案。由于人的存储计算和能力是有限的,所以我们需要使用这样的「外挂」,从而使人类的能力得到提升,最终将信息和知识转化为有用的行动。
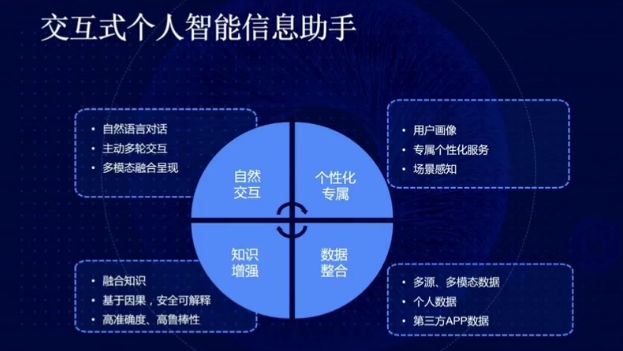
图 34:交互式个人智能信息助手的能力
交互式个人智能信息助手需要具备自然交互的能力,在主动的多轮交互中做到自然语言对话;需要为用户指定专属的用户画像、考虑专属的个性化服务,做到场景感知;同时,我们需要整合多源数据、多模态数据、个人数据、来自第三方 APP 的数据解决多模态整合的问题;此外,我们还需要向该系统中融入知识,基于因果推理技术实现安全、可解释的搜索,实现搜索的高准确性、高鲁棒性。