PyTorch深度学习实践-P10卷积神经网络
代码部分 参考了csdn上别的博主,经测试可以跑成功
复习:上一节的全连接神经网络
任意两个节点之间都有权重

全连接层处理图片时丢失了部分空间信息,因为为它把输入直接连成了一长串,但没有考虑他们在图片中的位置
处理图像时常用的二维卷积神经网络:考虑输入输出维度,做空间变换
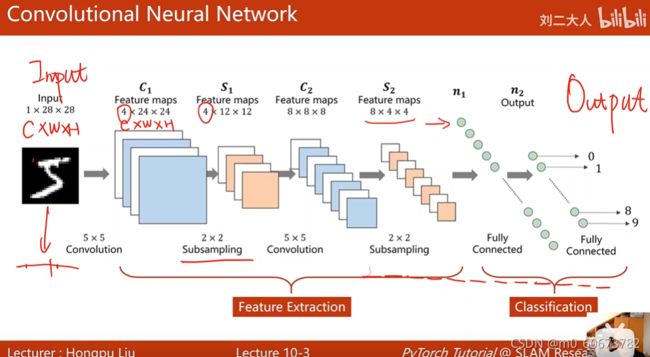
工作方式:
输入图像1*28*28的张量 c*w*h
卷积层:保留图像的空间特征
feature maps:卷积之后,依然是三维张量,得到了4*24*24的图像 通道变了 高度宽度变了
feature maps:2*2下采样之后得到了4*12*12的图像,使用下采样时,通道数不变,图像高度宽度改变,下采样可以减少数据量,降低运算需求
5*5卷积,2*2下采样,维度由3阶到1阶(10个元素,一个向量),将张量展开成1维,上一讲用view来实现,
全连接层映射到10维输出,然后交叉熵损失,softmax计算分布
最终目的是将3维的图像转换到10维的线性空间中
把卷积下采样称为特征提取,全连接网络称为分类
卷积:
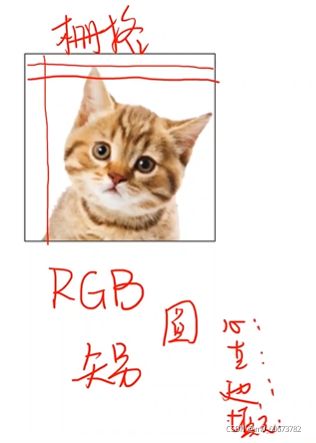
猫的图片,计算机读取RGB图像,是一个一个的格子--栅格图像,从自然界直接捕获
矢量图象:无法直接捕获,大部分人工生成,圆心在哪,边是啥颜色,用啥颜色填充,现画的
图像获取:ccd 数码采集器,光敏电阻,光锥可以识别一部分发射过来的光
输入图像c=3,3*w*h,,取3*w'*h'图像块(patch)来做卷积,输出是C*W*H

卷积运算过程
单通道卷积:输入1*5*5图像,卷积核3*3,输入与卷积核做数乘(对应的值相乘)
三通道卷积:RGB每个通道配一个卷积核,输入通道数量和卷积核数量一样,算出来三个矩阵之后做加法得到结果1*3*3,上下左右减去一行一列

多通道输入:卷积核是n**的张量,输出是1*3*3

假设要m个输出通道:m个卷积核卷积,然后拼接,m*w*h

卷积核的通道数量和输入通道数量一样,卷积核个数与输出通道数一样 即共享权重机制

把m个卷积核拼成一个4维张量,m*n*w*h、
卷积层代码:


代码:
import torch
in_channels,out_channels=5,10
width,height=100,100
kernel_size=3
batch_size=1
#生成一个服从正在分布的随机数 4维张量
input=torch.randn(batch_size,
in_channels,
width,
height)
conv_layer=torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size)
output=conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)结果:
torch.Size([1, 5, 100, 100])
torch.Size([1, 10, 98, 98])
torch.Size([10, 5, 3, 3])然后用卷积层对象把input输入,得到output
in_channels ,kernel_size ,batch 1 xiaopiliang 数据
torch.randn卷积生成去随机数
卷积层 module vonvd
padding填充 :根据输入宽度和输出宽度的需求
卷积核3*3
输入3*3, 要是想输出3*3,图像外层padding一圈0 3/2=1
要是想输出5*5,图像外层padding两圈 5/2=2


padding代码:

import torch
input=[3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
# (1,1,5,5) (batch,channel,width,height)
input=torch.Tensor(input).view(1,1,5,5)
conv_layer=torch.nn.Conv2d(1,1,kernel_size=3,padding=1,bias=False)
#(1,1,3,3) (output,input,kernel_width,kernel_height)
kernel=torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3)
#卷积层权重初始化
conv_layer.weight.data=kernel.data
output=conv_layer(input)
print(output)运行结果:
tensor([[[[ 91., 168., 224., 215., 127.],
[114., 211., 295., 262., 149.],
[192., 259., 282., 214., 122.],
[194., 251., 253., 169., 86.],
[ 96., 112., 110., 68., 31.]]]], grad_fn=) view(batch,c,w,h) 卷积层,kernel size 3*3
付给卷积层的权重.data kernel.data
stride:步长
索引下一个坐标的长度
5*5做完卷积变成2*2 可以有效降低 图像的宽度和高度
 代码:添加stride=2,其余不变
代码:添加stride=2,其余不变
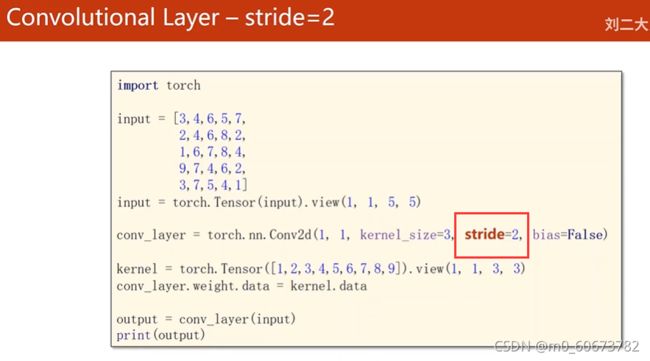
代码:
import torch
input=[3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input=torch.Tensor(input).view(1,1,5,5)
conv_layer=torch.nn.Conv2d(1,1,kernel_size=3,stride=2,bias=False)
kernel=torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3)
conv_layer.weight.data=kernel.data
output=conv_layer(input)
print(output)结果:
tensor([[[[211., 262.],
[251., 169.]]]], grad_fn=) 下采样:max pooling用的多,最大池化层,没有权重,默认stride=2,通道数不变,图像缩小成原来的一半
有关池化的定义:
在通过卷积层获得特征(feature map) 之后 ,下一步要做的就是利用这些特征进行整合、分类。理论上来讲,所有经过卷积提取得到的特征都可以作为分类器的输入(比如 softmax 分类器) ,但这样做会面临着巨大的计算量. 比如对于一个 300X300 的输入图像(假设只有一个通道) ,经过 100个 3X3 大小的卷积核进行卷积操作后,得到的特征矩阵大小是 (300 -3+1) X(300 -3+1) = 88804 ,将这些数据一下输入到分类器中显然不好.
此时我们就会采用 池化层将得到的特征(feature map) 进行降维常见的池化有 最大池化(Max Pooling) , 平均池化(Average Pooling) ,使用池化函数来进一步对卷积操作得到的特征映射结果进行处理
链接:https://blog.csdn.net/qq_41661809/article/details/96500250?ops_request_misc=&request_id=&biz_id=102&utm_term=%E6%B1%A0%E5%8C%96&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-96500250.pc_search_result_hbase_insert&spm=1018.2226.3001.4187
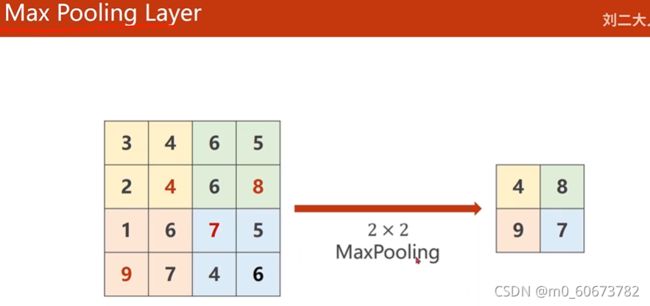
4*4分成2*2一组,每一组找最大值,把最大值拼起来成2*2输出
代码:

代码:
import torch
input=[3,4,6,5,
2,4,6,8,
1,6,7,8,
9,7,4,6,]
input=torch.Tensor(input).view(1,1,4,4)
#步长stride默认为2
maxpooling_layer=torch.nn.MaxPool2d(kernel_size=2)
output=maxpooling_layer(input)
print(output)结果:
tensor([[[[4., 8.],
[9., 8.]]]])举例处理mnist:
偷懒不算维度:定义模型时先不定义到全连接层,定义到其前一层,把输出结果的维度输出一下。
可以手算也可以pytorch帮我们算

输入batch 1*28*28 第一个卷积层卷积核5*5,输入通道为1,输出通道是10,输出通道10,28*28 和5*5卷积之后变成了batch * 10 *24*24
用输出最大池化,batch 10 不变 24*24减少一半 输出batch *10 *12*12
接下来卷积核5*5 ,选择输入通道10,输出通道20,经过这层之后batch*20*8*8
池化层 2*2 ,输出batch*20*4*4 一共320个元素,变成一个向量,然后全连接层映射成10,最后输出预测值


view变成全连接网络想要的输入,然后用全连接层变换,后面用交叉熵算损失,最后一层不激活
PyTorch如何使用GPU:
1把模型迁移到GPU


2计算张量迁移到GPU


results:
正确率97-98,提升1%,另一角度看错误率3%-2%,降低了三分之一

完整代码:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_dataset = datasets.MNIST(root='../dataset/mnist',
train=True,
download=True,
# 指定数据用transform来处理
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
# x的第0维就是batch_size
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1)
x = self.fc(x)
return x
model = Net()
# 将模型迁移到GPU上运行,cuda:0表示第0块显卡
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(torch.cuda.is_available())
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 将训练和测试过程分别封装在两个函数当中
def train(epoch):
running_loss = 0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
# 将要计算的张量也迁移到GPU上——输入和输出
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# 前馈 反馈 更新
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0
accuracy = []
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
# 测试中的张量也迁移到GPU上
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
# ??怎么比较的相等
# print(predicted)
# print(labels)
# print('predicted == labels', predicted == labels)
# 两个张量比较,得出的是其中相等的元素的个数(即一个批次中预测正确的个数)
correct += (predicted == labels).sum().item()
# print('correct______', correct)
print('Accuracy on test set: %d %%' % (100 * correct / total))
accuracy.append(100 * correct / total)
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
print(accuracy)
plt.plot(range(10), accuracy)
plt.xlabel("epoch")
plt.ylabel("Accuracy")
plt.show()
作业:写复杂点的CNN

完整代码:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
train_dataset = datasets.MNIST(root='../dataset/mnist',
train=True,
download=True,
# 指定数据用transform来处理
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 模型修改如下(随便改的)
self.conv1 = torch.nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=5)
self.conv3 = torch.nn.Conv2d(32, 64, kernel_size=3)
self.pooling = torch.nn.MaxPool2d(2)
self.fc1 = torch.nn.Linear(64, 32)
self.fc2 = torch.nn.Linear(32, 10)
def forward(self, x):
# x的第0维就是batch_size
batch_size = x.size(0)
x = self.pooling(F.relu((self.conv1(x))))
x = self.pooling(F.relu((self.conv2(x))))
x = self.pooling(F.relu((self.conv3(x))))
x = x.view(batch_size, -1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
model = Net()
# 将模型迁移到GPU上运行,cuda:0表示第0块显卡
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(torch.cuda.is_available())
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 将训练和测试过程分别封装在两个函数当中
def train(epoch):
running_loss = 0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
# 将要计算的张量也迁移到GPU上——输入和输出
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# 前馈 反馈 更新
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0
accuracy = []
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
# 测试中的张量也迁移到GPU上
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
# ??怎么比较的相等
# print(predicted)
# print(labels)
# print('predicted == labels', predicted == labels)
# 两个张量比较,得出的是其中相等的元素的个数(即一个批次中预测正确的个数)
correct += (predicted == labels).sum().item()
# print('correct______', correct)
print('Accuracy on test set: %d %%' % (100 * correct / total))
accuracy.append(100 * correct / total)
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
print(accuracy)
plt.plot(range(10), accuracy)
plt.xlabel("epoch")
plt.ylabel("Accuracy")
plt.show()
正确率最后得到了98.71%