第一次作业:深度学习基础
第一部分:深度学习概论
1956年,达特茅斯会议首次提出“人工智能”的概念,随后人工智能经历了三次起伏。
人工智能的三个层面:计算智能(主要是计算和存储)、感知智能(有感知,能听说,会看,例如无人驾驶)、认知智能(有意识,能理解,能思考)。
人工智能、机器学习与深度学习
人工智能>机器学习>深度学习
人工智能中包含机器学习,机器学习通过是否使用神经网络划分为神经网络和传统机器学习,而运用深度神经网络的才是深度学习。
机器学习
定义:从数据中自动提取知识
机器学习的学习从模型(确定假设空间)、策略(确定目标函数)和算法(求解模型参数)三个方面学习。

(一)绪论
深度学习
从感知器开始
深度学习发展的三个助推器:大数据、算法、计算力
过去应用研究:特征提取、物体检测、语义标注、实体标注
未来应用走向:视觉+语言:描述生成、多媒体问答、多媒体叙事
理论研究:从“能”到“不能”
(1)算法输出不稳定,易被攻击。
(2)模型复杂度高,难以纠错和调适。
以上两点需要找到对输出影响最大的点来解决。
(3)模型层级复合程度高,参数不透明。
(4)人类知识无法有效监督,机器偏见难以避免。
双向:算法能被人的知识体系理解+利用和结合人类知识
(5)专注直观感知类问题,对开放型推理问题无能为力。(乌鸦和鹦鹉)
(6)端到端训练方式对数据依赖性强,模型增量性差。(语义标注关系检测需要新的模型)
知识能够得到有效存储、积累和复用
机器学习评估:解释性和泛化性(准确性)
连接主义vs符号主义:对立-->合作
连接主义:自下向上,以统计为核心,深度学习为代表
符号主义:自上向下,以逻辑为核心,知识图谱为代表
相比符号主义,连接主义解释性降低。
(二)神经网络基础
1、浅层神经网络
M-P神经元
按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型。
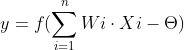
其中Wi是权值,正/负表示兴奋/抑制,大小表示强度
Xi表示输入
 表示阈值
表示阈值
f表示激活函数
激活函数:
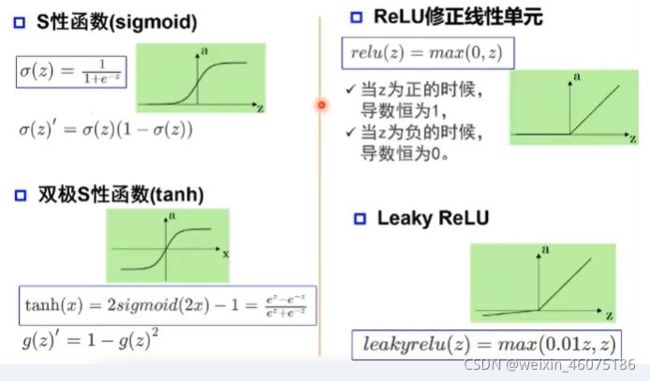
2、单层感知器
首个可以学习的人工神经网络,只能解决单个线性问题(如与、或、非问题),不能解决异或、同或问题。
3、多层感知器
依据万有逼近定理,将线性问题组合后可以解决非线性问题(将单层感知器嵌入带另一个单层感知器,成为多层感知器)
万有逼近定理
1、如果一个隐层包含足够多的神经元,三层前馈神经网络(单隐层)能以任意精度逼近任意预定的连续函数。
2、双隐层感知器逼近非连续函数,当隐层足够宽时,双隐层感知器可已逼近任何非连续函数,可以解决任何复杂问题。
神经网络每一层的作用:完成从输入到输出的空间变换
y=a(w·x+b)
神经网络学习如何利用矩阵的线性变换(节点数)加激活函数的非线性变换(层数),将原始输入空间投影到线性可分空间去分类/回归。
深度对函数复杂度的贡献呈指数增长,层数对函数复杂度的贡献呈线性增长。
梯度消失问题
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大。
梯度消失的表现:模型无法从训练数据中获得更新,损失几乎保持不变
深层神经网络的问题:梯度消失
无约束优化:梯度下降:主要目的是通过迭代找到目标函数(损失函数)的最小值,或者收敛到最小值。梯度的方向是函数在给定点上升最快的方向,那么梯度的反方向就是函数在给定点下降最快的方向,参数沿反梯度方向更新可使函数值下降。
损失函数就是一个自变量为算法的参数,函数值为误差值的函数。所以梯度下降就是找让误差值最小时候算法取的参数。
神经网络的参数学习:误差反向传播
多层神经网络可以看成是复合的非线性多元函数
逐层预训练
原因:存在局部极小值和梯度消失
实现:
1、受限玻尔兹曼机RBM(生成模型)
模型结构:RBM是两层神经网络,包含可见层v(输入层)和隐藏层h;不同层之间全连接,层内无连接;与感知器不同,RBM不区分前向和反向:输入v,通过p(h|v)得到隐藏层h,输入h,通过p(v|h)得到v;目的是为了让隐藏层得到的可见层v`与原来的可见层v分布一致,从而使隐藏层作为可见层的特征;两个方向权重w共享,偏置不同。
2、自编码器(判别式模型)
自编码器假设输出与输入相同,是一种尽可能复现输入信号的神经网络。将input输入一个encoder编码器,就会得到一个code;加一个decoder解码器,输出信息。通过调整encoder和decoder的参数,使得重构误差最小。自编码器没有额外监督信息,误差来源是直接重构后信号与原输入相比得到。
自编码器一般是一个多层神经网络,训练目标是是输出层与输入成误差最小。
堆叠自编码器(SAE)将多个自编码器得到的隐层串联;所有层预训练完成后,进行基于监督学习的全网络微调。
第二部分 李沐课程学习
深度学习应用
图片分类、物体检测与分割、样式迁移、人脸合成、文字生成图片、文字生成、无人驾驶
数据操作
机器学习与神经网络主要数据结构:N维数组
张量:一个由数值组成的数组,这可能有多个维度,可通过张量的shape属性访问其形状和张量中的元素总数。

reshape函数:改变张量形状而不改变其元素数量及元素值。
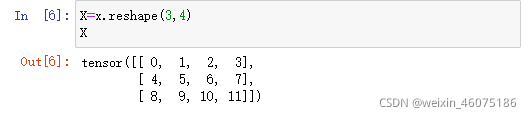
numel函数:返回数组中元素的个数

zeros函数:返回全为0的数组
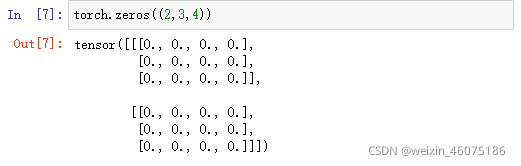
ones函数:返回全为1的数组
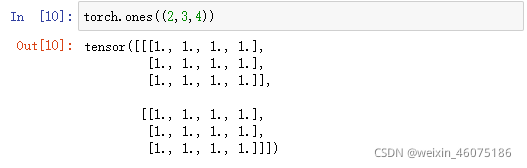
也可以通过提供包含数值的python列表(或嵌套列表)来为所需张量每个元素赋确定值。

对于张量所有标准算术运算符(+、-、*、/和**)都可以被升级为按元素运算。

也可以把多个张量连结在

对张量中的所有元素进行求和(sum函数)会产生一个只有一个元素的张量。
即使形状不同(维度相同),仍可通过调用广播机制来执行按元素操作。
除读取外,还可以通过指定索引将元素写入矩阵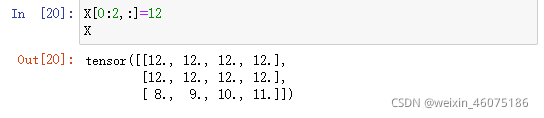
为多个元素赋相同的值,只需要索引所有元素,然后为他们赋值
执行一些操作可能会导致为新结果分配内存

执行原地操作

X[i]=X+Y或X+=Y来减少操作的内存开销,张量id不变。

转换为numpy张量

将大小为1的张量装换为python标量

数据预处理
处理缺失数据:删除或插值(此处只说插值方式)
fillna函数:对空缺数据进行填充
mean函数:求均值
get_dummies函数:特征值提取;dummy_na属性:bool, default False,增加一列表示空缺值,如果False就忽略空缺值
创建一个人工数据集,存储在csv(逗号分隔符)文件
import os
os.makedirs(os.path.join('..','data'),exist_ok=True)
data_file=os.path.join('..','data','house_tiny.csv')
with open(data_file,'w')as f:
f.write('NumberRooms,Alley,Price\n')
f.write('NA,Pave,127500\n')
f.write('2,NA,10500')
f.write('4,NA,12345')
f.write('NA,NA,12345')从创建的csv文件中加载原始数据集
import pandas as pd
data=pd.read_csv(data_file)
print(data)插值处理缺失数据
inputs,outputs=data.iloc[:,0:2],data.iloc[:,2]
inputs=inputs.fillna(inputs.mean())#均值填充
print(input)对于inputs中类别值或离散值,将NaN视为一个类别。
inputs=pd.get_dummies(inputs,dummy_na=True)
print(inputs)所有条目均为数值型后可转换为张量模式。
import torch
X,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
X,y线性代数
L2范数:向量元素平方和的平方根
L1范数:向量元素绝对值之和
矩阵的弗罗贝尼乌斯范数:矩阵元素的平方和的平方根
按特定轴求和
矩阵计算(以下截图均来自李沐老师课件!!!)
x为向量,y为标量时
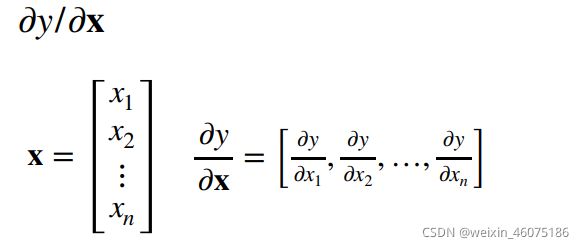
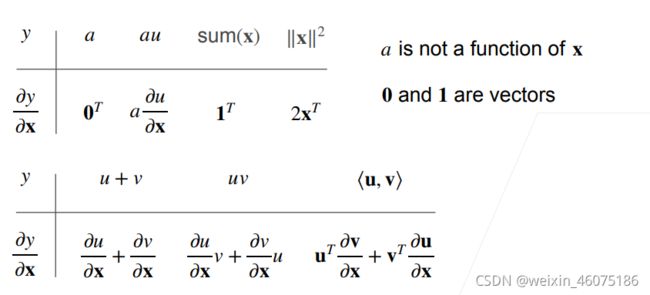
当y为向量,x为标量时
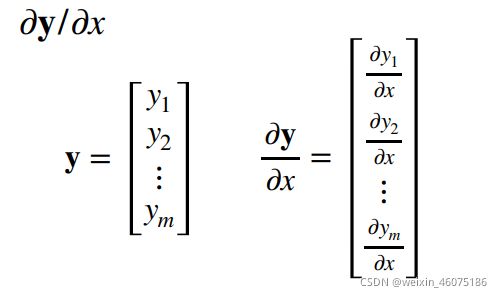
当x和y都是向量时


自动求导

自动求导计算一个函数在指定值上的导数


实现
假设对函数![]() 关于列向量X求导
关于列向量X求导
import torch
x=torch.arange(4.0)
print(x)
x.requires_grad_(True)#存储梯度
y=2*torch.dot(x,x)#计算y
print(y)
y.backward()#通过调用反向传播函数自动计算y关于x每个分量的梯度
print(x.grad)
x.grad==4*x
#计算另一个函数
import torch
x.grad.zero_()
y=x.sum()
y.backward()
x.grad![]()
我的问题
本来在听课的时候和自己查资料的时候有很多问题,但是现在就想不起来了,下次要及时将问题记录下来。
自动求导部分的公式还是记不住。