BERT 词向量理解及训练更新
1、BERT 词向量理解
在预训练阶段中,词向量是在不断更新的,而在fine-tuning阶段中,词向量是固定不变的。在fine-tuning阶段中,我们使用预训练好的模型参数来对新的数据进行训练。
BERT模型在预训练阶段中,会学习词表中所有词的词向量。在学习过程中,词表中每个词的词向量是通过输入的语料来学习的。
在训练过程中,词表中每个词的词向量都是随机初始化的,然后通过训练数据和反向传播算法来不断更新。反向传播算法会根据当前的词向量和训练数据的误差来调整词向量的值,使得模型在语料中学到的语言知识能够更好地概括文本。
在预训练阶段结束之后,这些词向量就成为了预训练权重。在 fine-tuning 阶段中,使用这些预训练好的词向量来对新的数据进行训练。
2、词向量训练更新
词向量权重矩阵为什么能训练更新?
理解就是输入字x,1个神经元对应了多个神经元,权重(即是这个x的词向量)就是1对多的连接层上的权重,相当于是个线性函数的连接层参数
#比如这里输入层有1个神经元,输出层有3个神经元,因此W是一个1*3的矩阵,b是一个3维的向量
y = Wx + b
假设输入层有1个神经元x=2,W是1*3的矩阵 [[1, 2, 3]],W就是x的词向量,b是3维的向量 [1, 1, 1]。
那么 y = Wx + b
y = [[1, 2, 3]] * 2 + [1, 1, 1] = [2, 4, 6] + [1, 1, 1] = [3, 5, 7]
这就是输入值为2时,输出层的结果。
1)torch全连接层表示词向量,3维度词向量代码更新训练说明
import torch
import torch.nn as nn
# 定义模型
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = nn.Linear(in_features=1, out_features=3)
def forward(self, x):
return self.linear(x)
# 实例化模型
model = LinearModel()
# 获取权重
print(model.linear.weight)
print(model.linear.bias)
# 设置输入
x = torch.tensor([[1.0]])
# 模型预测
print(model(x))
# 设置损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.06)
# 训练循环
for epoch in range(1000):
# 清空梯度
optimizer.zero_grad()
# 预测
y_pred = model(x)
# 计算损失
loss = criterion(y_pred, torch.tensor([[2.0, 4.0, 6.0]]))
# 反向传播
loss.backward()
# 更新权重
optimizer.step()
if (epoch+1) % 100 == 0:
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
# 训练后查看权重
print(model.linear.weight)
print(model.linear.bias)
线性连接层上参数训练前后变化

2)pytorch 词向量Embedding封装层表示,词向量更新训练代码
Embedding层理解,参考https://blog.csdn.net/weixin_42357472/article/details/120886559
import torch
import torch.nn as nn
import torch.optim as optim
# 定义词汇表大小和词向量维度
vocab_size = 10000
embedding_dim = 300
# 创建Embedding层
embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim)
初始化的词向量矩阵向量,每行表示一个字(或词)的向量
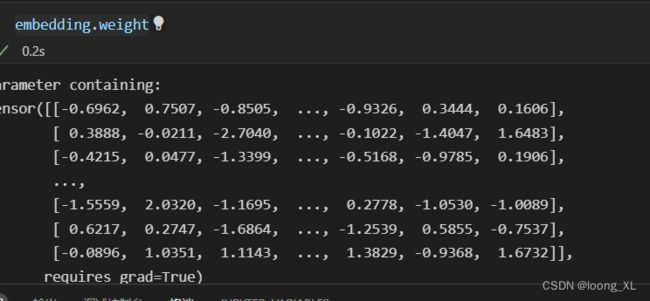
# 定义输入数据
inputs = torch.LongTensor([1, 2, 3, 4])
# 定义标签数据
labels = torch.LongTensor([1, 2, 3, 4])
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.SGD(embedding.parameters(), lr=0.3)
# 迭代训练
for epoch in range(100):
# 计算模型输出
outputs = embedding(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 清空梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新权重
optimizer.step()
embedding.weight
训练后的词向量矩阵向量变化,因为只有1,2,3,4行测试数据,所以只更新的是这几行的向量
