因果系列文章(2):因果推断初探
以下内容仅仅是作者因个人兴趣而对因果推理领域的非常粗浅的学习笔记,难免充满低级的谬误和肤浅的认识。作者已经在表达上尽量直白。如有错漏请及时指教。
深度学习不是万能的
人工智能发展至今,经历了无数次的浪潮,终于在深度学习爆发的时代迎来了新的革命。人们惊讶地发现,人工智能已经强大到可以打败最高水平的人类围棋选手,可以通过面部识别技术精准地抓捕潜逃的罪犯,可以从成千上万首诗歌中学习语法,并毫无破绽地创造出新的诗句,其水平与古代诗人相差无几。在新冠肺炎肆虐的2020年,人工智能更是大显身手,在疫情预测、人流管控、社区配送、病源追溯、新药研发等方面都起到了至关重要的作用,极大地解决了极端恶劣的条件下超大规模人口的城市治理问题。
在这种种的应用背后,先进的深度学习技术和充足的数据和计算资源功不可没。但同时,人们也越来越多的发现,许多人类能够轻易理解和掌握的技能,对于人工智能来说仍然举步维艰。这一点在机器人领域尤为突出:借助人工智能的进步,机器人已经可以实现精准的环境感知,构建复杂的地图,甚至像朋友一样与人无障碍地沟通。然而,许多人类认为非常简单的日常操作,对于机器人来说还有很大的距离。这其中的原因有很多,但最重要的一点是,虽然机器人的感知能力已经取得了很大的突破,但机器人的大脑,也即“决策”能力还尤为不足,这导致机器人在面对相似而不相同的任务时难以适应。比如,通过电机、减速器等硬件设备的提高,机器人已经能够精准地执行轨迹完成动作、并精确地施加力和力矩,但由于缺乏适应性或泛化能力,机器人仍然难以执行复杂而精巧的操作。比如握杯子这个任务,由于杯子的形状大小各异,最佳的抓取点不尽相同,所适用的力可能也不同,机器人即便学会了如何抓取一个杯子,也很难学会抓取所有的杯子,这极大地制约了机器人走进我们的千家万户为我们服务:试想一下,学个抓杯子就如此费劲了,你还指望机器人替你干什么?
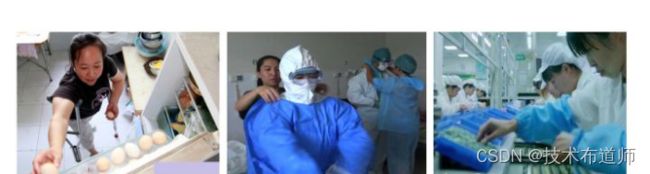 图1:人类认为简单的操作任务,对于机器人来说却不容易(左:拾取鸡蛋,中:穿脱衣服,右:卡扣零件)
图1:人类认为简单的操作任务,对于机器人来说却不容易(左:拾取鸡蛋,中:穿脱衣服,右:卡扣零件)
另一方面,面对复杂多变的任务序列,人类能够轻易地知道该做什么,不该做什么,先做什么后做什么,这是基于人类长期的知识、经验和习惯形成的。比如泡一杯咖啡,我们一般先加咖啡粉、然后注入开水,然后再加一点奶,最后加一块方糖。这个顺序并不是绝对的,我们也可以先加糖再加奶,或者先加开水再加咖啡粉,这似乎都没关系。但是我们很少先加奶,再加开水,再加咖啡(这样冲出来的咖啡肯定不好喝)。可是这一大套逻辑,要让机器人理解,那就不那么容易了。机器人不知道,先加开水的原因是因为开水才能把咖啡粉冲泡开,而牛奶冲不开。诸如此类的例子,还包括生产线上复杂工艺的规划、家庭聚会中摆餐桌餐具的顺序等等。
 图2:机器人难以掌握的复杂工序,序列的背后均有逻辑(左:冲咖啡,右:摆餐具)
图2:机器人难以掌握的复杂工序,序列的背后均有逻辑(左:冲咖啡,右:摆餐具)
不讲因果是万万不能的
在讲下文之前我建议读者能够去浏览一下中国人民大学明德讲坛第十一期关于人工智能与因果推理讲座内容,这篇记录稿非常全面的探讨了因果在我们生活中应用,四位大佬的分享极其有益,墙裂推荐:
讲座文稿 | 人工智能与因果推理
https://www.zhihu.com/question/410413388/answer/2651871415
说到这里终于快入正活了!机器人没法学到的背后那一大套逻辑,其实很大程度上都是因果关系。而复杂的世界是充满因果的,人类是世界的主宰者,善于通过变化万千的事物总结规律形成自己的知识。聪明的人“一叶知秋”,愚蠢的人“见到棺材才落泪”。
而现在,越来越多的科学家意识到,机器人和人工智能也需要这样的推理能力,才能从弱人工智能走向强人工智能。很多研究和应用深度学习的研究者也开始融入因果的思想和理论。这其中也有部分原因是深度学习本身并不是万能的,甚至说是有缺陷的,比如它需要大量的数据(而很多领域采集大量样本并不是容易的事情),同时它也需要精巧设计的网络结构和调整到位的超参数。而抛开这些因素不谈,深度学习本身也没有考虑因果的关系,仅仅在进行“曲线拟合”。这一点也是后面将详细说明的重点。
在这里举一个简单的例子,说明一下为什么不讲因果是会出问题的。我们知道,深度学习,特别是模仿学习为主的思想,在无人驾驶领域的研究已经经历了数年。最早的一个算法叫DAgger,就是将人类经验驾驶员的驾驶过程记录下来,然后训练模型用于控制车辆。但是在训练中人们发现,并不是特征越多越好,有时候如果引入了多余的特征,反而会误导算法给出的策略。比如下面这幅图中的两个情况。左边的情形A,用于训练网络的输入样本包含了挡风玻璃外的场景图像,也包含了驾驶台的图像(方向盘和仪表盘),输出就是人类的动作(油门刹车);在右边的情形B中,输入样本只包含挡风玻璃外的场景图像,仪表盘和方向盘被抠掉了,输出依然是人类的动作。经过训练,这两个模型的结果却大相径庭:左边的信息完整的数据训练出的策略,并不比右边的信息不完整的数据训练出的策略做出的正确动作更多。
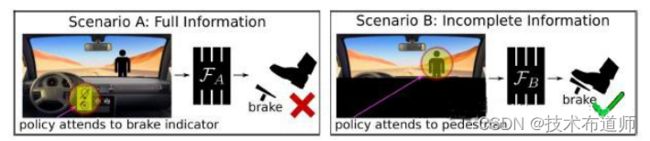 图3:包含刹车指示灯的训练数据误以为刹车灯亮起时应该踩刹车(左),而实际上是否踩刹车应该关注的是窗外的行人(右)
图3:包含刹车指示灯的训练数据误以为刹车灯亮起时应该踩刹车(左),而实际上是否踩刹车应该关注的是窗外的行人(右)
使用更多的数据特征难道不好吗?这个例子就证明了,还真不一定好。误导算法的原因是左边的数据中包含了刹车指示灯的信息,算法错误地建立了刹车指示灯与踩刹车动作之间的关联关系,误以为只要刹车指示灯亮了,就应该踩刹车。而右边的数据中没有刹车指示灯的信息,算法只能聚焦于窗外的行人,从而碰巧建立了正确的关系。事实证明,关注窗外的行人而不是刹车指示灯才是正确的决策。这其中的根源在于,刹车指示灯是刹车动作的“果”,而不是刹车动作的“因”,窗外的行人才是刹车动作的“因”。可是,如果只用深度学习来训练数据,又怎么可能学得到这背后的因果逻辑呢?这也让人们逐渐意识到,并不是数据越多越好、特征越多越接近真相,方向错了就很难得到正确的解答。
Pearl教授和因果关系之梯
在因果关系领域,不得不提到一位大牛,被称为“贝叶斯网络之父”的Judea Pearl,这位图灵奖的得主在2017年NIPS大会上做报告时无人问津,一度引发了争议和思考。当时比现在更充满深度学习流派的风潮(这几年其实慢慢理性下来),所以无人问津也可想而知。自那以后,Pearl写了一本通俗易懂的科普书《The Book of Why: The New Science of Cause and Effect[2],这本书的中文版《为什么:关于因果关系的新科学》已经由中信出版集团出版[3]。这本书也似乎正在引领一场因果关系的革命,让更多的研究者关注这一领域的发展。
 图4:Judea Pearl教授(左)和他的新书中英文版(中、右)
图4:Judea Pearl教授(左)和他的新书中英文版(中、右)
在这本书中,Pearl将因果关系分为三个层次(他称之为“因果关系之梯”)。自底到顶分别是:关联、干预、反事实推理。最底层的是关联(Association),也就是我们通常意义下所认识的深度学习在做的事情,通过观察到的数据找出变量之间的关联性。这无法得出事件互相影响的方向,只知道两者相关,比如我们知道事件A发生时,事件B也发生,但我们并不能挖掘出,是不是因为事件A的发生导致了事件B的发生。第二层级是干预(Intervention),也就是我们希望知道,当我们改变事件A时,事件B是否会跟着随之改变。最高层级是反事实(Conterfactuals),也可以理解为“执果索因”,也就是我们希望知道,如果我们想让事件B发生某种变化时,我们能否通过改变事件A来实现。
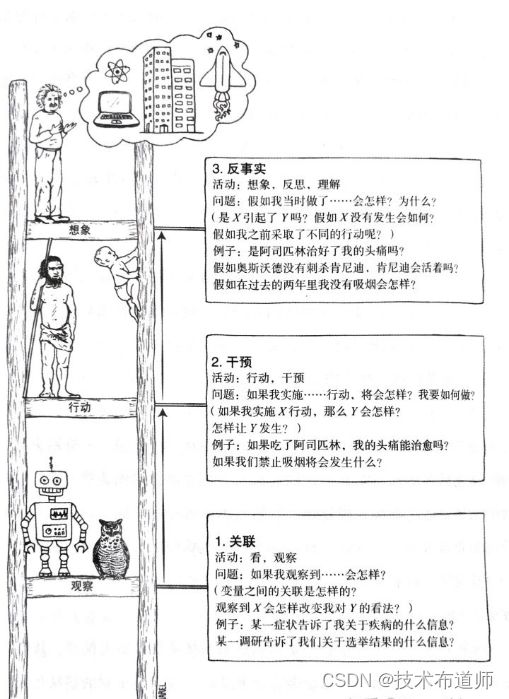
图5:因果关系之梯——关联、干预、反事实
所以简单来说,相关不等于因果,因果关系之梯的第一层级只涉及相关,第二、第三层级才涉及因果。用一个经典的例子,可以把这三个层次的关系解释清楚。《新英格兰医学》杂志发表了一篇论文指出,一个国家消耗的巧克力越多,该国人均产生的诺贝尔奖得主便越多[4]。这样的结论很荒谬,但问题在哪里呢?通过数据分析,人们确实发现巧克力销量高的国家,获得的诺贝尔奖数量往往更多,两者几乎呈现一种线性关系。但进行到这一步也仅仅符合因果关系之梯的最底层——关联,我们仅仅得知这两者之间相关。为了探寻两者之间是否有因果关系,我们可以进行干预和反事实推理。我们可以提问:如果给诺贝尔获得数量较少的国家的国民吃更多的巧克力,那么这个国家能有更多的诺贝尔奖获得者吗?这便是第二层级“干预”。很显然,答案是否定的(吃更多的巧克力不能导致获得更多的诺贝尔奖)。同样,我们还可以提问,如果那些诺贝尔奖获得数量较多的国家的人没有吃那么多巧克力,他们还能获得那么多诺贝尔奖吗?这便是第三层级“反事实推理”,很显然,答案是肯定的(即便不吃那么多巧克力,他们该得诺贝尔奖还是会得),因为获得诺贝尔奖并不是吃巧克力的“果”,吃巧克力较多可能反映的是该国的经济发达、国民素质高、受教育程度高等等,而这些才是获得诺贝尔奖的“因”。
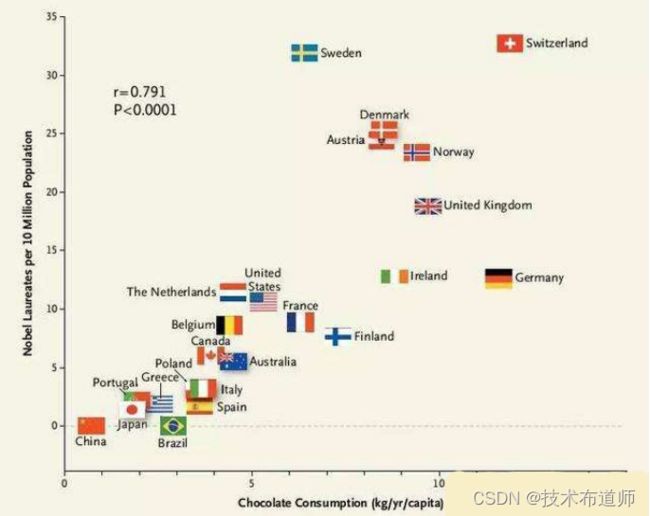 图6:巧克力销量与诺贝尔奖获得数
图6:巧克力销量与诺贝尔奖获得数
因此,研究因果关系最大的一个目标,就是找出事物之间真正的因果关系,去掉那些混杂的伪因果关系。因果关系对于巧克力诺贝尔奖这个例子可能无关紧要,但对于经济、医学、环境、政治等领域来说都非常重要,这直接决定了决策者做出什么样的行为。比如,如果不能准确地得到“吃药”和“某种病被治愈”之间的因果关系,那么医生就无法正确判断是否应该采取这种吃药的措施来治疗这种病。
幸运的是,已经有足够多的方法让我们能够拨开迷雾,找出事件之间的因果关系。
参考:
- ^Pim de Haan, Dinesh Jayaraman, Sergey Levine, "Causal Confusion in Imitation Learning", arXiv:1905.11979 https://arxiv.org/abs/1905.11979?context=stat.ML
- ^Judea Pearl, Dana Mackenzie, “The Book of Why: The New Science of Cause and Effect”, Allen Lane.
- ^朱迪亚·珀尔,达纳·麦肯齐 著,江生,于华 译,“为什么:关于因果关系的新科学”,中信出版集团,2019.
- ^Franz H Messerli, "Chocolate Consumption, Cognitive Function, and Nobel Laureates", The New England Journal of Medicine, vol. 367, no.16, pp.1562-1564, 2012. Chocolate Consumption, Cognitive Function, and Nobel Laureates | NEJM