干货:科大讯飞最新语音识别系统和框架深度剖析
雷锋网按;本文作者魏思,博士,科大讯飞研究院副院长,主要研究领域为语音信号处理、模式识别、人工智能等,并拥有多项业界领先的科研成果。张仕良,潘嘉,张致江科大讯飞研究院研究员。刘聪,王智国科大讯飞研究院副院长。责编:周建丁。
语音作为最自然便捷的交流方式,一直是人机通信和交互最重要的研究领域之一。自动语音识别(Automatic Speech Recognition,ASR)是实现人机交互尤为关键的技术,其所要解决的问题是让计算机能够“听懂”人类的语音,将语音中传化为文本。自动语音识别技术经过几十年的发展已经取得了显著的成效。近年来,越来越多的语音识别智能软件和应用走人了大家的日常生活,苹果的Siri、微软的小娜、科大讯飞的语音输入法和灵犀等都是其中的典型代表。本文将以科大讯飞的视角介绍语音识别的发展历程和最新技术进展。
我们首先简要回顾语音识别的发展历史,然后介绍目前主流的基于深度神经网路的语音识别系统,最后重点介绍科大讯飞语音识别系统的最新进展。
语音识别关键突破回顾
语音识别的研究起源于上世纪50年代,当时的主要研究者是贝尔实验室。早期的语音识别系统是简单的孤立词识别系统,例如1952年贝尔实验室实现了十个英文数字识别系统。从上世纪60年代开始,CMU的Reddy开始进行连续语音识别的开创性工作。但是这期间语音识别的技术进展非常缓慢,以至于1969年贝尔实验室的约翰·皮尔斯(John Pierce)在一封公开信中将语音识别比作“将水转化为汽油、从海里提取金子、治疗癌症”等几乎不可能实现的事情。上世纪70年代,计算机性能的大幅度提升,以及模式识别基础研究的发展,例如码本生成算法(LBG)和线性预测编码(LPC)的出现,促进了语音识别的发展。
这个时期美国国防部高级研究计划署(DARPA)介入语音领域,设立了语音理解研究计划,研究计划包括BBN、CMU、SRI、IBM等众多顶尖的研究机构。IBM、贝尔实验室相继推出了实时的PC端孤立词识别系统。上世纪80年代是语音识别快速发展的时期,其中两个关键技术是隐马尔科夫模型(HMM)的理论和应用趋于完善以及NGram语言模型的应用。
此时语音识别开始从孤立词识别系统向大词汇量连续语音识别系统发展。例如,李开复研发的SPHINX系统,是基于统计学原理开发的第一个“非特定人连续语音识别系统”。其核心框架就是用隐马尔科模型对语音的时序进行建模,而用高斯混合模型(GMM)对语音的观察概率进行建模。基于GMM-HMM的语音识别框架在此后很长一段时间内一直是语音识别系统的主导框架。上世纪90年代是语音识别基本成熟的时期,主要进展是语音识别声学模型的区分性训练准则和模型自适应方法的提出。这个时期剑桥语音识别组推出的HTK工具包对于促进语音识别的发展起到了很大的推动作用。此后语音识别发展很缓慢,主流的框架GMM-HMM趋于稳定,但是识别效果离实用化还相差甚远,语音识别的研究陷入了瓶颈。
关键突破起始于2006年。这一年辛顿(Hinton)提出深度置信网络(DBN),促使了深度神经网络(Deep Neural Network,DNN)研究的复苏,掀起了深度学习的热潮。2009年,辛顿以及他的学生默罕默德(D. Mohamed)将深度神经网络应用于语音的声学建模,在小词汇量连续语音识别数据库TIMIT上获得成功。2011年,微软研究院俞栋、邓力等发表深度神经网络在语音识别上的应用文章,在大词汇量连续语音识别任务上获得突破。从此基于GMM-HMM的语音识别框架被打破,大量研究人员开始转向基于DNN-HMM的语音识别系统的研究。
基于深度神经网络的语音识别系统
基于深度神经网络的语音识别系统主要采用如图1所示的框架。相比传统的基于GMM-HMM的语音识别系统,其最大的改变是采用深度神经网络替换GMM模型对语音的观察概率进行建模。最初主流的深度神经网络是最简单的前馈型深度神经网络(Feedforward Deep Neural Network,FDNN)。DNN相比GMM的优势在于:1. 使用DNN估计HMM的状态的后验概率分布不需要对语音数据分布进行假设;2. DNN的输入特征可以是多种特征的融合,包括离散或者连续的;3. DNN可以利用相邻的语音帧所包含的结构信息。
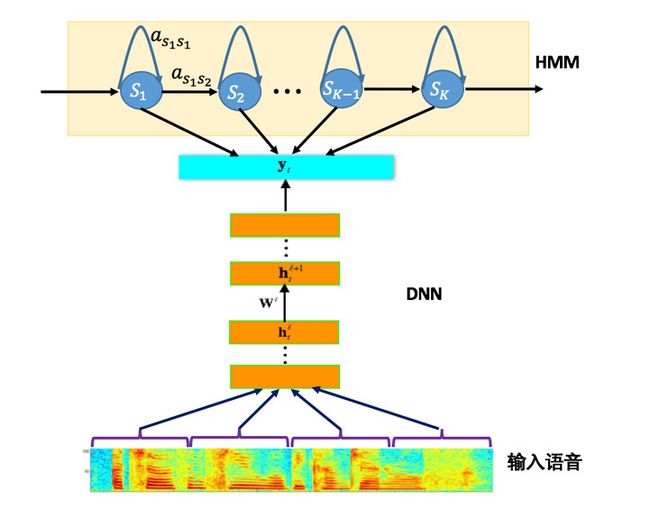
图1 基于深度神经网络的语音识别系统框架
语音识别需要对波形进行加窗、分帧、提取特征等预处理。训练GMM时候,输入特征一般只能是单帧的信号,而对于DNN可以采用拼接帧作为输入,这些是DNN相比GMM可以获得很大性能提升的关键因素。然而,语音是一种各帧之间具有很强相关性的复杂时变信号,这种相关性主要体现在说话时的协同发音现象上,往往前后好几个字对我们正要说的字都有影响,也就是语音的各帧之间具有长时相关性。采用拼接帧的方式可以学到一定程度的上下文信息。但是由于DNN输入的窗长是固定的,学习到的是固定输入到输入的映射关系,从而导致DNN对于时序信息的长时相关性的建模是较弱的。
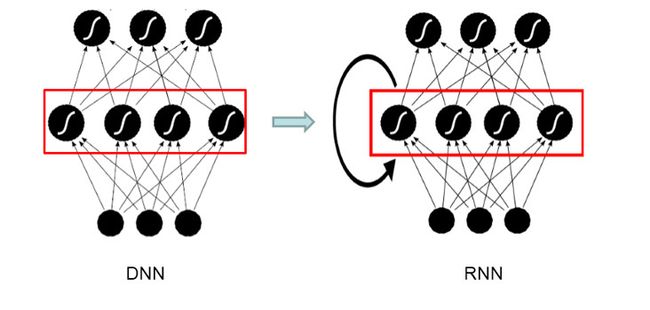
图2 DNN和RNN示意图
考虑到语音信号的长时相关性,一个自然而然的想法是选用具有更强长时建模能力的神经网络模型。于是,循环神经网络(Recurrent Neural Network,RNN)近年来逐渐替代传统的DNN成为主流的语音识别建模方案。如图2,相比前馈型神经网络DNN,循环神经网络在隐层上增加了一个反馈连接,也就是说,RNN隐层当前时刻的输入有一部分是前一时刻的隐层输出,这使得RNN可以通过循环反馈连接看到前面所有时刻的信息,这赋予了RNN记忆功能。这些特点使得RNN非常适合用于对时序信号的建模。而长短时记忆模块 (Long-Short Term Memory,LSTM) 的引入解决了传统简单RNN梯度消失等问题,使得RNN框架可以在语音识别领域实用化并获得了超越DNN的效果,目前已经使用在业界一些比较先进的语音系统中。除此之外,研究人员还在RNN的基础上做了进一步改进工作,如图3是当前语音识别中的主流RNN声学模型框架,主要包含两部分:深层双向RNN和序列短时分类(Connectionist Temporal Classification,CTC)输出层。其中双向RNN对当前语音帧进行判断时,不仅可以利用历史的语音信息,还可以利用未来的语音信息,从而进行更加准确的决策;CTC使得训练过程无需帧级别的标注,实现有效的“端对端”训练。
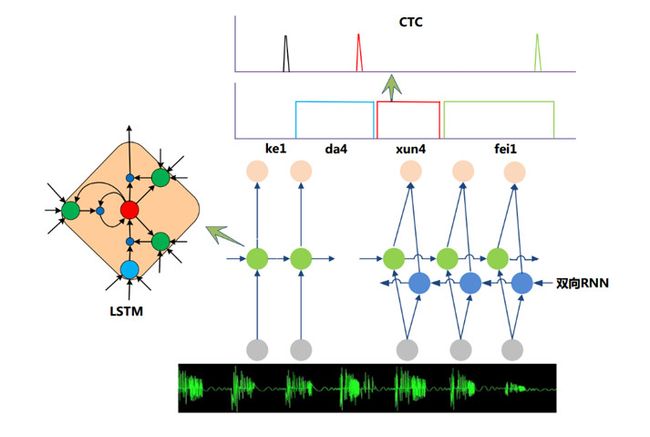
图3 基于RNN——CTC的主流语音识别系统框架
科大讯飞最新语音识别系统
国际国内已经有不少学术或工业机构掌握了RNN模型,并在上述某个或多个技术点进行研究。然而,上述各个技术点单独研究时一般可以获得较好的结果,但是如果想将这些技术点融合在一起则会碰到一些问题。例如,多个技术结合在一起的提升幅度会比各个技术点提升幅度的叠加要小。又例如对于目前主流的双向RNN的语音识别系统,其实用化过程面临一个最大的问题是:理论上只有获得了完整的全部语音段,才能成功地利用未来的信息。这就使得其具有很大时延,只能用于处理一些离线任务。而对于实时的语音交互,例如语音输入法,双向RNN显然是不适用的。再者,RNN对上下文相关性的拟合较强,相对于DNN更容易陷入过拟合的问题,容易因为训练数据的局部不鲁棒现象而带来额外的异常识别错误。最后,由于RNN具有比DNN更加复杂的结构,给海量数据下的RNN模型训练带来了更大的挑战。
讯飞FSMN语音识别框架
鉴于上述问题,科大讯飞研发了一种名为前馈型序列记忆网络FSMN (Feed-forward Sequential Memory Network) 的新框架。这个框架可以把上述几点很好地融合,同时各个技术点对效果的提升可以获得叠加。值得一提的是,FSMN采用非循环的前馈结构,只需要180ms延迟,就达到了和双向RNN相当的效果。
图4(a)即为FSMN的结构示意图,相比传统的DNN,我们在隐层旁增加了一个称为“记忆块”的模块,用于存储对判断当前语音帧有用的历史信息和未来信息。图4(b)画出了双向FSMN中记忆块左右各记忆1帧语音信息(在实际任务中,可根据任务需要,调整所需记忆的历史和未来信息长度)的时序展开结构。从图中我们可以看出,不同于传统的基于循环反馈的RNN,FSMN记忆块的记忆功能是使用前馈结构实现的。这种前馈结构有两大好处:
首先,双向FSMN对未来信息进行记忆时,没有传统双向RNN必须等待语音输入结束才能对当前语音帧进行判断的限制,它只需要等待有限长度的未来语音帧即可,正如前文所说的,我们的双向FSMN在将延迟控制在180ms的情况下就可获得媲美双向RNN的效果;
其次,如前所述,传统的简单RNN因为训练过程中的梯度是按时间逐次往前传播的,因此会出现指数衰减的梯度消失现象,这导致理论上具有无限长记忆的RNN实际上能记住的信息很有限,然而FSMN这种基于前馈时序展开结构的记忆网络,在训练过程中梯度沿着图4中记忆块与隐层的连接权重往回传给各个时刻即可,这些连接权重决定了不同时刻输入对判断当前语音帧的影响,而且这种梯度传播在任何时刻的衰减都是常数的,也是可训练的,因此FSMN用一种更为简单的方式解决了RNN中的梯度消失问题,使其具有类似LSTM的长时记忆能力。
另外,在模型训练效率和稳定性方面,由于FSMN完全基于前馈神经网络,所以不存在RNN训练中因mini-batch中句子长短不一需要补0而导致浪费运算的情况,前馈结构也使得它的并行度更高,可最大化利用GPU计算能力。从最终训练收敛的双向FSMN模型记忆块中各时刻的加权系数分布我们观察到,权重值基本上在当前时刻最大,往左右两边逐渐衰减,这也符合预期。更进一步,FSMN可和CTC准则结合,实现语音识别中的“端到端”建模。
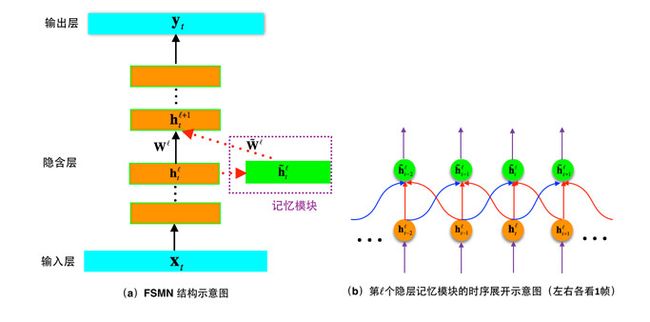
图4 FSMN结构框图
科大讯飞DFCNN语音识别框架
FSMN的成功给了我们一个很好的启发:对语音的长时相关性建模并不需要观察整个句子,也不一定需要使用递归结构,只要将足够长的语音上下文信息进行良好的表达就可以对当前帧的决策提供足够的帮助,而卷积神经网络(CNN)同样可以做到这一点。
CNN早在2012年就被用于语音识别系统,并且一直以来都有很多研究人员积极投身于基于CNN的语音识别系统的研究,但始终没有大的突破。最主要的原因是他们没有突破传统前馈神经网络采用固定长度的帧拼接作为输入的思维定式,从而无法看到足够长的语音上下文信息。另外一个缺陷是他们只是将CNN视作一种特征提取器,因此所用的卷积层数很少,一般只有一到二层,这样的卷积网络表达能力十分有限。针对这些问题,结合研发FSMN时的经验,我们研发了一种名为深度全序列卷积神经网络(Deep Fully Convolutional Neural Network,DFCNN)的语音识别框架,使用大量的卷积层直接对整句语音信号进行建模,更好地表达了语音的长时相关性。
DFCNN的结构如图5所示,它直接将一句语音转化成一张图像作为输入,即先对每帧语音进行傅里叶变换,再将时间和频率作为图像的两个维度,然后通过非常多的卷积层和池化(pooling)层的组合,对整句语音进行建模,输出单元直接与最终的识别结果比如音节或者汉字相对应。 DFCNN的工作机理俨然像是一位德高望重的语音学专家,通过“观看”语谱图即可知道语音中表达的内容。对于很多读者来说,乍一听可能以为是在写科幻小说,但看完我们下面的分析之后,相信大家都会觉得这种架构是那么的自然。
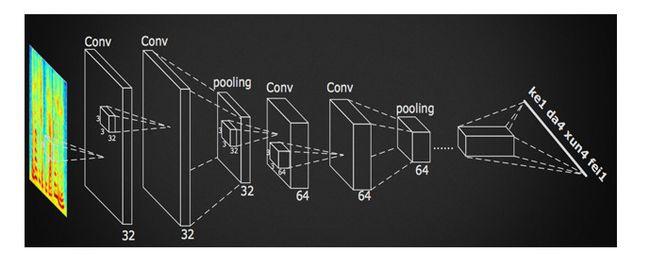
图5 DFCNN示意图
首先,从输入端来看,传统语音特征在傅里叶变换之后使用各种人工设计的滤波器组来提取特征,造成了频域上的信息损失,在高频区域的信息损失尤为明显,而且传统语音特征为了计算量的考虑必须采用非常大的帧移,无疑造成了时域上的信息损失,在说话人语速较快的时候表现得更为突出。因此DFCNN直接将语谱图作为输入,相比其他以传统语音特征作为输入的语音识别框架相比具有天然的优势。其次,从模型结构来看,DFCNN与传统语音识别中的CNN做法不同,它借鉴了图像识别中效果最好的网络配置,每个卷积层使用3x3的小卷积核,并在多个卷积层之后再加上池化层,这样大大增强了CNN的表达能力,与此同时,通过累积非常多的这种卷积池化层对,DFCNN可以看到非常长的历史和未来信息,这就保证了DFCNN可以出色地表达语音的长时相关性,相比RNN网络结构在鲁棒性上更加出色。最后,从输出端来看,DFCNN还可以和近期很热的CTC方案完美结合以实现整个模型的端到端训练,且其包含的池化层等特殊结构可以使得以上端到端训练变得更加稳定。
在和其他多个技术点结合后,科大讯飞DFCNN的语音识别框架在内部数千小时的中文语音短信听写任务上,相比目前业界最好的语音识别框架双向RNN-CTC系统获得了15%的性能提升,同时结合科大讯飞的HPC平台和多GPU并行加速技术,训练速度也优于传统的双向RNN-CTC系统。DFCNN的提出开辟了语音识别的一片新天地,后续基于DFCNN框架,我们还将展开更多相关的研究工作,例如:双向RNN和DFCNN都可以提供对长时历史以及未来信息的表达,但是这两种表达之间是否存在互补性,是值得思考的问题。
深度学习平台
以上科大讯飞的研究都很好的语音识别的效果,同时科大讯飞也意识到这些深度神经网络需要大量的数据和计算量进行训练。例如,两万小时的语音数据约有12000PFlop的计算量,如果在一颗E5-2697 v4的CPU上进行训练,大约需要116天时间,这对语音识别技术研究来说是无法接受的。为此,科大讯飞分析算法的计算特点,搭建了一套快速的深度学习计算平台——深度学习平台。
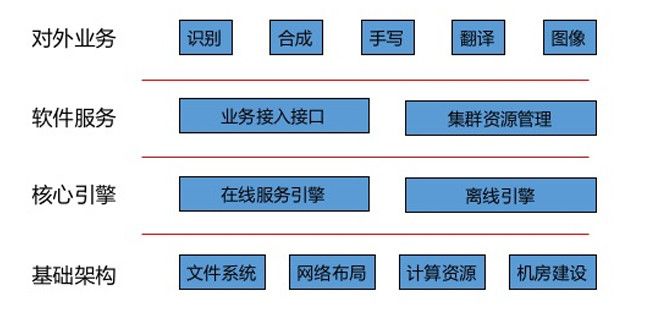
图6 深度学习平台架构
如图6所示,整个平台分为四个组成部分。首先,底层基础架构,依据语音数据量、访问的带宽、访问频度、计算量、计算特点,选择适合的文件系统、网络连接、计算资源。其中,文件系统使用并行分布式文件系统,网络使用万兆连接,计算资源使用GPU集群,并且单独建设了专门的机房。在此基础之上,开发核心计算引擎,用于进行各种模型训练和计算,如适合CNN计算的引擎、适合DNN的计算引擎以及适合FSMN/DFCNN的计算引擎等。整个计算引擎和基础架构对使用者来说还是比较抽象,为简化使用门槛,科大讯飞专门开发了平台的资源调度服务和引擎的调用服务;这些工作大大减少研究院人员使用集群资源的难度,提升研究的进度。在此三个基础工作之上,科大讯飞的深度学习平台可以支撑整个研究相关的工作,如语音识别、语音合成、手写识别……
科大讯飞使用GPU作为主要的运算部件,并结合算法的特点,进行了大量的GPU并行化的工作。如科大讯飞在分块模型更新(BMUF)基础之上设计了融合弹性平均随机梯度下降(EASGD)算法的并行计算框架,在64 GPU上实现了近线性的加速比,大大提升训练效率,加快深度学习相关应用的研究进程。
写在最后
回顾语音识别的发展历史和科大讯飞语音识别系统的最新进展后,我们可以发现,技术的突破总是艰难而缓慢的,重要的是坚持和不断思考。虽然近几年深度神经网络的兴起使得语音识别性能获得了极大的提升,但是我们并不能迷信于现有的技术,总有一天新技术的提出会替代现有的技术,科大讯飞希望可以通过不断的技术创新实现语音识别技术的进一步突破。
雷锋网(公众号:雷锋网)注:本文由CSDN授权雷锋网转载,如需转载请联系原作者。
雷锋网原创文章,未经授权禁止转载。详情见转载须知。
