gitchat训练营15天共度深度学习入门课程笔记(十三)
第7章 卷积神经网络
- 7.5 CNN 的实现
- 7.6 CNN 的可视化
-
- 7.6.1 第 1 层权重的可视化
- 7.6.2 基于分层结构的信息提取
- 7.7 具有代表性的 CNN
-
- 7.7.1 LeNet
- 7.7.2 AlexNet
7.5 CNN 的实现
- CNN各层示意图:
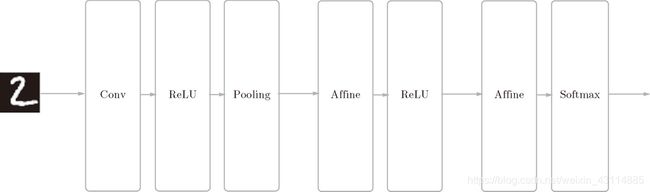
隐藏层:Convolution - ReLU - Pooling
输出层的前一层:Affine - ReLU
输出层:Affine - Softmax - SimpleConvNet 初始化:
参数和函数:
-
input_dim——输入数据的维度:(通道,高,长)
-
conv_param——卷积层的超参数(字典)。字典的关键字如下:
filter_num——滤波器的数量
filter_size——滤波器的大小
stride——步幅
pad——填充
-
hidden_size——隐藏层(全连接)的神经元数量
-
output_size——输出层(全连接)的神经元数量
-
weitght_int_std——初始化时权重的标准差
步骤:
- 将超参数从字典中取了出来,方便之后用
- 计算出来卷积层和池化层的输出大小
class SimpleConvNet:
def __init__(self, input_dim=(1, 28, 28),conv_param={'filter_num':30, 'filter_size':5,'pad':0, 'stride':1},hidden_size=100, output_size=10,weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) /filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) *(conv_output_size/2))
3.权重参数的初始化
参数和函数:
- params——滤波器和偏置的字典变量:4维、2维和1维
- filter_num——滤波器的数量
- filter_size——滤波器的大小
- input_dim[0]——通道个数
- np.zeros(filter_num)——偏置为0
- hidden_size——隐藏层(全连接)的神经元数量
- output_size——输出层(全连接)的神经元数量
- pool_output_size——池化层输出的神经元数量
- weitght_int_std——初始化权重用高斯分布np.random.randn随机生成的标准差
步骤:
- 将卷积层(第一个卷积层)的滤波器放入params
- 将卷积层的偏置放入params
- 将Affine-ReLu层(第二个全连接层)的权重放入params,大小为池化层的输出的大小和隐藏层的大小
- 将Affine-ReLu层的偏置放入params
- 将输出层(第三个全连接层)的权重放入params,大小为隐藏层的输出的大小和输出层的大小
- 将输出层的偏置放入params
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(filter_num, input_dim[0],filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * np.random.randn(pool_output_size,hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
- 各层的生成
参数和函数:
- layers——保存各层的有序字典变量
- OrderedDict()——有序字典保存各层顺序
- params——滤波器和偏置的字典变量
- pool_h,pool_w——池化窗口大小
- lastLayer——保存SoftmaxWithLoss 层的变量
步骤:
- 分别初始化Convolution 层,ReLu 层,Pooling 层,Affine 层,SoftmaxWithLoss 层
- 将这些初始化的函数放入字典变量layers
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'],
self.params['b1'],
conv_param['stride'],
conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'],
self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'],
self.params['b3'])
self.last_layer = SoftmaxWithLoss()
- 推理函数和损失函数
参数和函数:
- x ——输入数据
- t ——监督标签
- y——经过推理得出的输出数据
步骤:
- 从头开始依次调用已添加的层,并将结果传递给下一层
- loss 方法调用最后的 SoftmaxWithLoss 层
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
- 误差反向传播法求梯度
参数和函数:
- dout ——最后一层偏导值
- lastLayer.backward(dout) ——调用最后一层的反向传播函数
- reverse() ——翻转层的顺序
- grads ——保存各个权重参数的梯度的字典变量
步骤:
- 正向传播
- 单独调用最后一层的反向传播函数
- 反转各层,调用各层的反向传播函数
- 记录梯度
def gradient(self, x, t):
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'] = self.layers['Conv1'].dW
grads['b1'] = self.layers['Conv1'].db
grads['W2'] = self.layers['Affine1'].dW
grads['b2'] = self.layers['Affine1'].db
grads['W3'] = self.layers['Affine2'].dW
grads['b3'] = self.layers['Affine2'].db
return grads
- 用于学习Minist数据集的代码与 4.5 节中介绍的代码基本相同,因此这里不再罗列(源代码在
ch07/train_convnet.py中)。
7.6 CNN 的可视化
7.6.1 第 1 层权重的可视化
- 卷积层前后数据的对比
将卷积层(第 1 层)的滤波器(权重)大小显示出来,统一将最小值显示为黑色(0),最大值显示为白色(255):

通过学习,显示非常散乱的滤波器被更新成了有一定规律的滤波器
- 滤波器在观察和显示出了什么
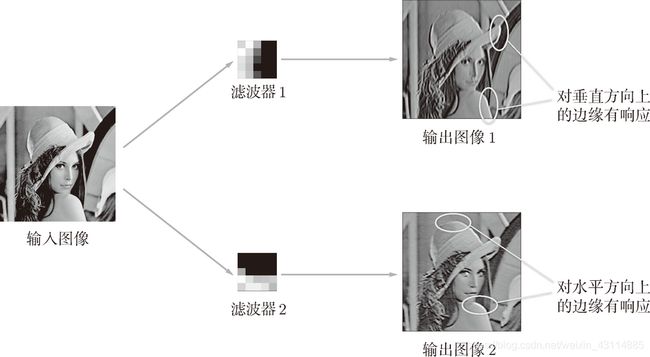
滤波器在观察边缘(颜色变化的分界线)和斑块(局部的块状区域)等。
如图所示,输出图像 1 对垂直方向上的边缘有响应,输出图像 2 对水平方向上的边缘有响应:
- 输出图像 1 中,垂直方向的边缘上出现白色像素,输出图像 2 中,水平方向的边缘上出现很多白色像素
7.6.2 基于分层结构的信息提取
- 随着层次加深,提取的信息(正确地讲,是反映强烈的神经元)也越来越抽象。
图中展示了进行一般物体识别(车或狗等)的 8 层 CNN。这个网络结构的名称是马上要介绍的 AlexNet。

最开始的层对简单的边缘有响应,接下来的层对纹理有响应,再后面的层对更加复杂的物体部件有响应。也就是说,随着层次加深,神经元从简单的形状向“高级”信息变化。换句话说,就像我们理解东西的“含义”一样,响应的对象在逐渐变化。
7.7 具有代表性的 CNN
7.7.1 LeNet
LeNet的特征:
- 在 1998 年被提出,是进行手写数字识别的网络
- 有连续的卷积层和池化层,最后经全连接层输出结果
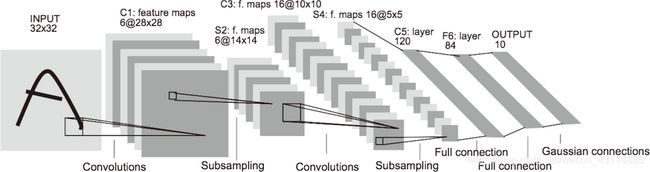
- 激活函数使用sigmoid 函数
- 原始的 LeNet 中使用子采样(subsampling)缩小中间数据的大小,而现在的 CNN 中 Max 池化是主流
7.7.2 AlexNet
AlexNet的特征:
- 在2012 年被提出
- 多个卷积层和 max 池化层,最后经由全连接层输出结果

- 激活函数使用 ReLU函数
- 使用进行局部正规化的 LRN(Local Response Normalization)层
- 使用 Dropout随机删除神经元来抑制过拟合
end
- 原书为《深度学习入门 基于Python的理论与实现》作者:斋藤康毅
人民邮电出版社 - 本文章是gitchat的《陆宇杰的训练营:15天共读深度学习》1的课程读书笔记
- 本文章大量引用原书中的内容和训练营课程中的内容作为笔记
《陆宇杰的训练营:15天共读深度学习》 ↩︎