《机器学习方法(第三版)—— 李航》学习笔记(一)附代码
目录
前言
一、第一章 机器学习及监督学习概论
1、机器学习
实现机器方法的步骤
机器学习的研究
2、机器学习的分类
基本分类
二、第二章 感知机
1、感知机模型
2、感知机学习策略
感知机学习策略
感知机学习算法
前言
提示:本blog不用于商用,如有侵权请速与作者联系。`
毕竟是又开启了人生的又一阶段,花点时间重新系统的学一遍机器学习也未尝不是一件好事。有幸了解到李航博士新书《机器学习方法》(第三版),并第一时间买了下来,此书的前两版名叫《统计学习方法》,第一版主要讲解了监督学习,第二版加入了无监督学习,第三版在基础上加入了深度学习的内容,主要围绕着在各大领域大放异彩的前馈神经网络、卷积神经网络、循环神经网络、生成对抗网络及对应的经典模型。
接下来的几天甚至几周将过一遍此书中的内容,并以笔记的形式写成Blog。由于书中并没有案例代码,所以想要在此Blog中找寻机器学习代码可以直接绕行,不要过多浪费时间。
本人水平有限,能够吃透李航博士书中内容的零星半点便知足了,而笔记更是只能照猫画虎似地摘抄,提出些天马行空的理解,如有错误之处还望各位读者批评指正。
提示:笔记中的多级标题与书中的章节或小结并不一一对应,且笔记中的内容是个人认为的没见过的且比较重点的内容,而不是全部内容,还望各位读者不要将其奉为圭臬。
一、第一章 机器学习及监督学习概论
1、机器学习
实现机器方法的步骤
(1)得到一个有限的训练数据集合;
(2)确定包含所有可能的模型的假设空间,即学习模型的集合;
(3)确定模型选择的准则,即学习的策略;
(4)实现求解最优模型的算法,即学习的算法;
(5)通过学习方法选择最优模型;
(6)利用学习的最优模型对新数据进行预测或分析。
机器学习的研究
(1)机器学习方法的研究:旨在开发新的学习方法;
(2)机器学习理论的研究在于探求及学习方法的有效性与效率,以及机器学习基本理论问题;
(3)机器学习应用的研究主要考虑将机器学习方法应用到实际问题中去,解决实际问题。
个人理解:就我所了解到的人智领域的现状(一位步入大厂的朋友反复和我强调的):(1)与(3)方面上只有工业界才能做出突破,而学界只不过是拿着工业界所取得的成果,在(2)进行一系列证明,或拿着(1)的残羹剩饭进行二创。因为想要以一个实验室或者学校的力量提出一个新的学习范式并转化为生产力在现阶段来说是完全不可能的。
2、机器学习的分类
基本分类
监督学习:
监督学习是指从标注数据中学习预测模型的机器学习问题。标注数据表述输入输出的对应关系,预测模型对给定的输入产生相应的输出。监督学习的本质是学习输入到输出的映射的同级规律。
(1)输入空间、特征空间和输入空间
在监督学习中,将输入与输出的所有可能取值的集合分别称为输入空间与输出空间。输入空间和输出空间可以是有限元素集合,也可以是整个欧式空间。输入空间与输出空间可以是同一空间,也可以是不同的空间,但通常输出空间是远远小于输入空间的。每个具体的输入是一个实例,通常由特征向量表示。这时,所有特征向量存在的空间称为特征空间。模型实际上都是定义在特征空间上的。
在监督学习中,将输入与输出看作是定义在输入(特征)空间与输出空间上的随机变量的取值。输入输出变量用大写字母表示,习惯上输入变量写作X,输出变量写作Y。监督学习从训练数据集合中学习模型,对测试数据及逆行预测。训练数据由输入(或特征向量)与输出对组成,测试数据也由输入与输出对组成。输入与输出对又称为样本或样本点。
(2)联合概率分布
监督学习假设输入与输出的随机变量X与Y遵循联合概率分布P(X,Y)。P(X,Y)表示分布函数或分布密度函数。在学习过程中,假定这一联合概率分布存在,但对学习系统来说,联合概率分布的具体定义是未知的。训练数据与测试数据被看作是依联合概率分布P(X,Y)独立同分布产生的。机器学习假设数据存在一定的统计规律,X和Y具有联合概率分布就是监督学习关于数据的基本假设。
联合概率是指在多元的概率分布中多个随机变量分别满足各自条件的概率。假设X和Y都服从正态分布,那么P{X<4,Y<0}就是一个联合概率,表示X<4,Y<0两个条件同时成立的概率。表示两个事件共同发生的概率。A与B的联合概率表示为 P(AB) 或者P(A,B),或者P(A∩B)。
无监督学习:
无监督学习是指从无标注数据中学习预测模型的机器学习问题。无标注数据是自然得到的数据,预测模型表示数据的类别、转换或概率。无监督学习的本质是学习数据中的同级规律或潜在结构。每个输入是一个实例,由特征向量表示。每个输出是对输入的分析结果,由输入的类别、转换或概率表示。模型可以实现对数据的聚类、降维或概率估计。
假设X是输入空间,Z是隐式结构空间。要学习的模型可以表示为函数z=g(x)、条件概率分布P(z|x)或者条件概率分布P(x|z)的形式。包含所有可能的模型的集合称为假设空间。无监督学习旨在从假设空间中选出在给定评价标准下的最优模型。
无监督学习通常使用大量的无标注数据学习或训练,每一个样本是一个实例。无监督学习可以用于对已有数据的分析,也可用于对未来数据的预测。
强化学习:
强化学习是指智能系统在与环境的连续互动中学习最优行为策略的机器学习的问题。假设智能系统与环境的互动基于马尔科夫决策过程,智能系统能观测到的是与环境互动得到的数据序列。强化学习的本质是学习最优的序贯策略。
强化学习不是三言两语就能讲明白的,有些基本概念反复学习四五遍还是不理解。所以,这部分内容不会在本笔记中详细讲述,后续可以会单独写一个强化学习和深度强化学习的系列笔记。
半监督学习与主动学习:
半监督学习是指利用标注数据和未标注数据学习预测模型的机器学习问题。通常拥有少量标注数据、大量未标注数据,因为标注数据的构建往往需要人工、成本较高,未标注数据的收集不需要太多成本。半监督学习旨在利用未标注数据中的信息,辅助标注数据,进行监督学习,以较低的成本达到较好的学习效果。
主动学习指是机器不断主动给出实例让教师进行标注,然后利用标注数据学习预测模型的机器学习问题。通常的监督学习使用给定的标注数据,往往是随机得到的,可以看作是“被动学习”,主动学习的目标是找出对学习最有帮助的实例让教师标注,以较小的标注代价达到较好的学习效果。
半监督学习和主动学习更接近监督学习。
个人理解:
根据样本是否带有标签将机器学习分为监督学习和无监督学习。对于强化学习的分类,也会有监督强化学习和无监督强化学习,这里之所以会将强化学习的概念与监督、无监督学习并且,我个人认为是作者按照样本的差异性分类的。
2022.07.04 添加内容,对于上述自己的理解,继续做出解释:仔细学习了强化学习后发现,监督学习和强化学习确实是两个不一样的概念。(1)强化学习处理的大多数是序列数据,其很难像监督学习的样本一样满足独立同分布。(2)学习器并没有告诉我们每一步正确的动作是什么,学习器需要自己去发现那些动作可以带来最多的奖励,只能通过不断尝试来发现最有利的动作。(3)智能体获得自己能力的过程,其实是不断第尝试探索的过程。(4)在强化学习中,没有非常强的监督者,只有奖励信号,并且奖励是有延迟的。但是,强化学习和监督学习真的是那么独立的么?个人认为,并不是!其概念是可以相互转化的。奖励函数像是损失函数对于强化学习中完全可观测状态设计出的具体的奖励函数,可以看作是监督学习,对于强化学习中部分可观测状态人为设计的奖励函数,可以看作是无监督学习。再就是类似于图像分割领域,其目的是精确分割图像,既可以用强化学习也可以用监督学习,两者可进行同种任务的学习,并不是一定没有互相转化的可能的。
也就是说,对于监督学习,样本是(x,y)这样的一个特征与结果(预测值)的二元模型对;对于无监督学习,样本是x这样的一个特征,并没有结果,学习的是一个隐式空间;对于强化学习,输入是每个t下的状态,或者状态的可观测值,并且学习的不是一个结果,不是一个隐式结构空间,学习是一个价值函数、动作价值函数或者一个马尔可夫决策过程,用于产生最优的序贯决策。
接着,半监督学习,我认为只不过是学界为了各种原因从监督学习中择出来的概念,本质和监督学习没啥区别;主动学习则是更常出现在强化学习中,用于产生新的环境或状态。
二、第二章 感知机
感知机是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1二值。感知机对于输入空间(特征空间)中将实例划分为正负两类的分离超平面,属于判别模型。感知机学习旨在求出将训练数据进行线性划分的分离超平面,为此导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。感知机学习算法具有简单而易于实现的优点,分为原始形式和对偶形式。
1、感知机模型
假设输入空间(特征空间)![]() ,输出空间是Y = {+1,-1}输入
,输出空间是Y = {+1,-1}输入

 表示实例的特征向量,对应于输入空间(特征空间)的点;输入y Y 表示实例的类别。由输入空间到输出空间的函数
表示实例的特征向量,对应于输入空间(特征空间)的点;输入y Y 表示实例的类别。由输入空间到输出空间的函数 ![]() ,称为感知机。其中
,称为感知机。其中 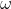 和 b为感知机模型参数,
和 b为感知机模型参数, ![]() 叫做权值或者权值量,b
叫做权值或者权值量,b ![]() 叫做偏置,
叫做偏置,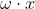 表示 和 的内积。
表示 和 的内积。
2、感知机学习策略
数据集线性可分:
对于一个数据集,如果存在一个超平面能够将数据集的正实例点和负实例点完全正确地划分到超平面的两侧,则称数据集为线性可分,否则为线性不可分。
感知机学习策略
假设训练集是线性可分的,感知机得目的是求得一个能够将训练集正实例点和负实例点完全正确分开的分离超平面。为了找出这样一个超平面,即确定感知机模型参数w,b,需要确定一个学习策略,即定义(经验)损失函数并将损失函数极小化。
损失函数的一个自然选择是误分类点的总数,但这样的损失函数不是w,b的连续可导函数,不易优化。损失函数的另一个选择是误分类点到超平面S的总距离,这是感知机所采用的。根据点到超平面S的距离公式:![]() (2.1)。这里,
(2.1)。这里,![]() 是 w 的L2范数。
是 w 的L2范数。
对于误分类数据有 ![]() 成立,所以误分类点到超平面S的距离为上述表达式(2.1)的反。
成立,所以误分类点到超平面S的距离为上述表达式(2.1)的反。
假设超平面的S的误分类点集合为M,那么所有误分类点到超平面的S的总距离为![]() ,不考虑
,不考虑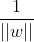 ,就得到了感知机的损失函数。如果没有误分类点,损失函数值为0。而且,误分类点越少,误分类点离超平面越近,损失函数值就越小。一个特定的样本点的损失函数在误分类时是参数w,b的线性函数,在分类正确时是0。因此,给定训练集T,损失函数L(w,b)是w,b的连续可导函数。
,就得到了感知机的损失函数。如果没有误分类点,损失函数值为0。而且,误分类点越少,误分类点离超平面越近,损失函数值就越小。一个特定的样本点的损失函数在误分类时是参数w,b的线性函数,在分类正确时是0。因此,给定训练集T,损失函数L(w,b)是w,b的连续可导函数。
感知机学习算法
原始形式:
算法2.1 感知机学习算法的原始形式
输入:训练数据集T = {(x1,y1),(x2,y2),……,(xN,yN)},其中xi∈= ,yi∈Y={+1,-1},i=1,2,…,N;学习率 η (0<η≤1)
,yi∈Y={+1,-1},i=1,2,…,N;学习率 η (0<η≤1)
输出:w,b;感知机模型![]()
(1)选取初始值w0,b0;
(2)在训练集中选择数据(xi,yi);
(3)如果yi (w·xi + b) ≤ 0,则 w ← w + η yi xi ,b ← b + η yi ;
(4)转至步骤(2),直至训练集中没有误分类点。
# perceptron.py
import numpy as np
def update_net(x,y,w,b):
dot = np.dot(x,w)
if y * (dot + b) <= 0:
w = w + (y * x).T
b = b + y
return w,b,False
else:
return w,b,True
def perceptron(x_list,y_list):
w = np.zeros((2, 1))
b = 0
all_flag = False
while all_flag != True:
all_flag = True
for i in range(len(x_list)):
w,b,flag = update_net(x_list[i],y_list[i],w,b)
if flag == False:
all_flag = False
return w,b
if __name__ == "__main__":
x_list = [[[3,3]],
[[4,3]],
[[1,1]]]
y_list = [[1],
[1],
[-1]]
x_list = np.array(x_list)
y_list = np.array(y_list)
w,b = perceptron(x_list,y_list)
print("Best w is :" + str(w))
print("Best b is :" + str(b))
对偶形式:
算法2.2 感知机学习算法的对偶形式
输入:训练数据集T = {(x1,y1),(x2,y2),……,(xN,yN)},其中xi∈=,yi∈Y={+1,-1},i=1,2,…,N;学习率 η (0<η≤1)
输出:a,b;感知机模型 ,其中
,其中 ![]()
(1) ![]()
(2) 在训练过程中选择数据(xi,yi)
(3) 如果 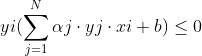 ,则
,则 ![]()
(4) 转至步骤(2)直到没有误分类数据
对偶形式中训练实例仅以内积的形式出现。为了方便,可以预先将训练中集中实例间的内积计算出来并以矩阵的形式存储,这个矩阵就是Gram矩阵。
# perceptron_Antithesis.py
import numpy as np
def Gram(x_list):
gram_matrix = np.zeros((len(x_list),len(x_list)))
for i in range(len(x_list)):
for j in range(len(x_list)):
gram_matrix[i][j] = np.dot(x_list[i],x_list[j].T)[0][0]
print(gram_matrix)
return gram_matrix
def perceptron(x_list,y_list,alpha,eta):
b = 0
gram_matrix = Gram(x_list)
all_flag = False
while all_flag != True:
all_flag = True
for i in range(len(x_list)):
tmp = 0
for j in range(len(gram_matrix)):
tmp = tmp + alpha[j] * y_list[j] * gram_matrix[i][j]
if (tmp+b) * y_list[i] <= 0:
alpha[i] = alpha[i] + eta
b = b + y_list[i]
all_flag = False
return alpha,b
if __name__ == "__main__":
x_list = [[[3,3]],
[[4,3]],
[[1,1]]]
y_list = [[1],
[1],
[-1]]
x_list = np.array(x_list)
y_list = np.array(y_list)
alpha = [0,0,0]
eta = 1
w,b = perceptron(x_list,y_list,alpha,eta)
print("Best alpha is :" + str(w))
print("Best b is :" + str(b))