Incompatible namespaceIDs问题解决,hdfs文件上传失败
解决namenode启动异常情况
事情起因
笔者在离线安装的hadoop上尝试往hdfs文件系统里面传输数据的时候,发现一直传不上去,报错内容如下:
DataStreamer Exception: org.apache.hadoop .ipc.RemoteException: java.io.IOEx <此处省略大部分内容> could only be replicated to 0 node instead of minReplication(-1)
报错的大概内容如下,因为笔者的已经弄好了,忘记留个截图了,就用了这篇文章里面的图(ps:这个没解决我的问题)

然后在翻查了很多东西之后,我开始怀疑我hadoop的配置一开始就出了问题,所以执行了下面这个命令看了下我的namenode和datanode的启动情况。
hadoop dfsadmin -report
好家伙,空的,甚至连大小都没有,这个时候我就意识到了配置是真的出问题了。
Configured Capacity: 0 (0 B)
Present Capacity: 0 (0 B)
DFS Remaining: 0 (0 B)
DFS Used: 0 (0 B)
DFS Used%: NaN%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 0 (0 total, 0 dead)
注意:hadoop namenode -format 别乱用,我后面会对这个事情解释一下。
############################################################
问题解决
如果你确保你能找得到你的datanode、namenode放文件的地方,也就是你进我下面讲的这两个配置文件里面你能找得到这几个参数,并且能正确找到对应文件夹的话,你就可以不用做我下面这几步,我这几步的原因是我找不到我放hdfs文件的tmp文件夹的地方,所以做了这几步。
首先配置core-site内的hadoop.tmp.dir参数,如果你文件里面找不到这个参数,那么你就之间把我下面这段内容中的地址改成你想要放namenode的相关数据的文件夹路径,之后再把内容附在configuration标签内。
<!--part_added-->
<property>
<name>hadoop.tmp.dir</name>
<value>/software/JDK/cygwin/tmp/hadoop-Neroism/dfs/name</value>
</property>
<!--part_added-->
再就是配置hdfs-site.xml中的dfs.name.dir和dfs.data.dir的路径问题,这里我建议,你还是改一下好点,以防万一你找不到文件夹,路径是从盘符后面部分过来,比如我这里是w/software/JDK/cygwin/tmp/hadoop-Neroism/dfs/name,从w盘过来的,我就取w后面的部分。
#要改的路径就是value部分,以防你有点迷惑改哪里
<property>
<name>dfs.name.dir</name>
<value>/software/JDK/cygwin/tmp/hadoop-Neroism/dfs/name</value>
<description>Determines where on the local filesystem the DFS name node
should store the name table(fsimage). If this is a comma-delimited list
of directories then the name table is replicated in all of the
directories, for redundancy. </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/software/JDK/cygwin/tmp/hadoop-Neroism/dfs/data</value>
<description>Determines where on the local filesystem an DFS data node
should store its blocks. If this is a comma-delimited
list of directories, then data will be stored in all named
directories, typically on different devices.
Directories that do not exist are ignored.
</description>
</property>
之后,在配置完文件后,重新打开终端,重新初始化namenode,也就是执行
hadoop namenode -format
之后会弹出让你覆盖之前配置的name信息的选项,直接选择Y,覆盖即可。
然后再执行./start-all(前提是你进到你hadoop/bin文件夹里面了才能这样干)起开hadoop所有服务。
在成功启动后,执行
hadoop dfsadmin -report
再次查看namenode和datanode情况,如果显示出了大小,比如下图
Configured Capacity: 124960894976 (116.38 GB)
Present Capacity: 31902061568 (29.71 GB)
DFS Remaining: 31902048256 (29.71 GB)
DFS Used: 13312 (13 KB)
DFS Used%: 0%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
则代表成功了,接下来在传文件就没问题了。
但是如果你发现仍然是0,没有任何数据,不用慌,接下来我会讲到
############################################################
Incompatible namespaceIDs问题解决
如果执行上述步骤,发现datanode、namenode显示的存储大小仍然是0,那么,你可以进入hadoop的平台,也就是进到http://localhost:50030/内,找到locallog,看一下日志

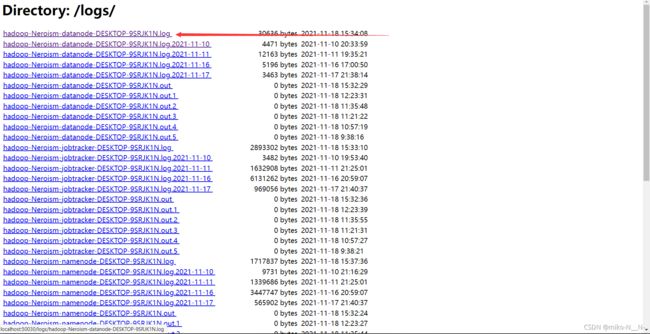
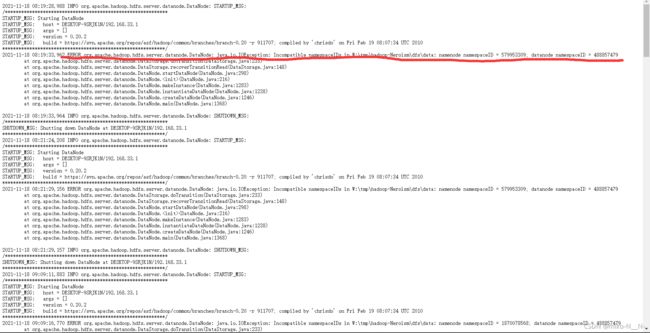
如果你看日志上,发现报了这个错误“Incompatible namespaceIDs”
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Incompatible namespaceIDs in W:\tmp\hadoop-Neroism\dfs\data: namenode namespaceID = 579953309; datanode namespaceID = 488857479
那么恭喜你,你执行namenode的格式化次数太多了,hadoop认不出你的datanode和namenode的路径在哪里了。
那么怎么解决呢?只需要找到你之前的datanode和namenode的存储路径,清空整个tmp文件夹,关闭你之前打开的hadoop,即在hadoop/bin目录下执行./stop-all.sh,再重新执行hadoop namenode -format对namenode格式化,./start-all.sh重新启动hadoop即可。
如果你找不到,那么我建议你去你装cygwin的目录下,或者是hadoop的文件夹内,找一下tmp文件夹,如果有,点进去看是否存在hsperfdata_{你的用户名}或者是hadoop_{你的用户名}类型的文件夹,或者是存在pid后缀的文件,如果有就代表找对了。
参考文章如下:
https://blog.csdn.net/weiyongle1996/article/details/74094989/
https://blog.csdn.net/qq_38712932/article/details/84197154
https://www.cnblogs.com/AK47Sonic/p/7198033.html
(还有一些记得不太清楚了~~)