C++ 001:C++ 基础语法
1. 开始之前
1.1 学习路线
这次我是下定决心要学 C++ 了,而且是系统地,不半途而废地学习 C++ 了~ 有这个新专栏为证~
由于某次偶然的机会,我看见了一张 C++ 竞赛的学习路线表(这里由于表格内容太多就不贴出来),里面的东西是真的多:不仅仅有 C++ 本身,还有各种算法,数据结构,数论等等等等。但是学习路线旁边,还贴了一个学完之后参加比赛能够拿到的名次,我一秒也没犹豫,直接开了这个坑~
但是由于这些内容实在太多了,所以学习路线肯定是要有的。下面浅浅的贴出来画个大饼~
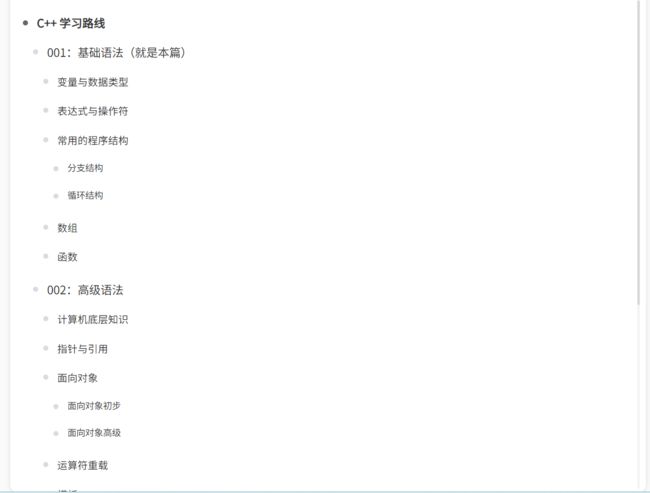

(后面的后面再说了,要不然万一弃坑了就悲剧了……)
1.2 准备工作
这一小节我们要做一些准备工作。首先要进行 C++ 开发,你得有一个 C++ IDE。用了一圈虽然说 Visual Studio 实在太重了,但是确实比较好用~
(用一个例子说明 VS(Visual Studio 的简称)有多重:为了演示一遍安装过程,我卸载 VS 愣是花了 1 小时……)
首先去 https://visualstudio.microsoft.com/zh-hans/downloads/ 下载社区版 VS 的安装程序(安装之前你需要保证你的电脑是 Windows 10 及以上,要不然 Visual Studio 能不能跑得动都是个问题。如果实在要装只能度娘了……)~
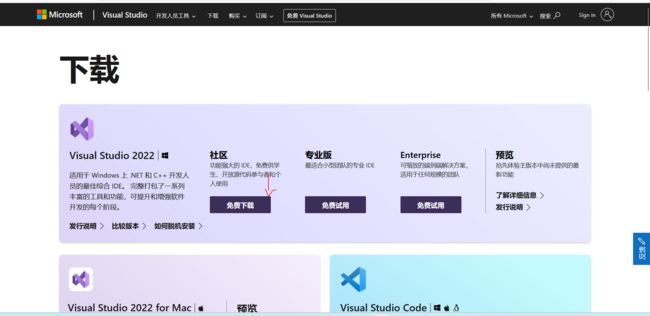
然后运行它,它会帮你先安装好完整的 VS 安装程序~

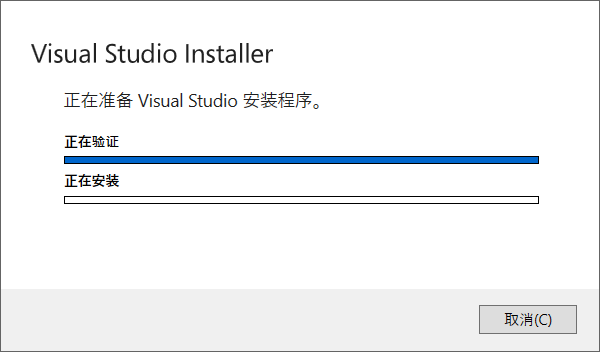
然后真正的 Visual Studio Installer 就出现了,这里我们只勾选 C++ 桌面开发,点击安装;
然后就是漫长的下载和安装过程……
安装完之后就可以完成了~
1.3 Hello World
既然我们要学习一门语言,那肯定要有一些“仪式感”:众人皆知的 Hello World。所以这一小节我们就来创建一个 VS 项目,打印一下 Hello World~
干掉这个 VS Installer,然后启动 VS:

等它登录一下,很快。登陆完之后应该就会显示如下界面:

点击创建新项目,选择控制台应用,下一步;
这个自己写就行,随便,然后点创建;

你应该会看见一个源码编辑窗口,这就是我们要敲代码的地方了。把里面的内容全部删除,然后加入以下内容:
#include
using namespace std;
int main() {
cout << "Hello World!" << endl;
return 0;
}
这些代码的功能就是打印 Hello World。Ctrl + S 保存,然后 Ctrl + Fn + F5(如果不行按下 Ctrl + F5),你可能会看见一个窗口一闪而过。再运行一次,你会发现 Hello World 就被打印出来了~

这里说明一下 Hello World 代码实现的原理:
首先第一行 #include ,这行代码使用 #include 引入了一个库叫做 iostream,它的功能就是实现控制台的读与写。库中有一个 std 对象,里面有很多可以实现控制台读写的函数(函数就是一些可以实现特定功能的代码),比如 std::cout 可以输入内容,std::endl 可以换行。
第二行 using namespace std; 则涉及到了命名空间。简而言之,你写了 using namespace std,std::cout 就可以简写为 cout,std::endl 就可以简写为 endl。而句末的分号代表语句结束了,除了预处理语句(就是前面带 # 的),其它的所有语句的结尾都需要加上 ; 号。
然后我们到了 int main() 里面。int main 是一个程序的入口函数,所有代码都需要写在里面才能被执行。int main(){ 是一个函数的声明,不是一条语句,所以不需要加上 ; 号。同时这个函数需要指明哪里结束,最后一行的 } 就代表它结束了。同样的它也不需要加括号。函数里面的所有代码都需要缩进,即代码前面要留出 4 格空格的位置。
接下来就到了最核心的打印语句,首先我们肯定要先写代表输出内容的 cout,后面的 << “Hello World” 代表把一个 Hello World 字符串传入 cout 进行打印。字符串要使用双引号包裹。这样的传递可以不止一次,比如我们还可以传递一个 << endl 来让 cout 打印一个换行字符。同样的句末一定要加 ; 号。
最后就是 return 0; 了。这行代码给函数返回了一个值 0 代表程序正常退出。同样分号一定要加。
一个 Hello World 就扯出来这么多内容,C++ 复不复杂(T_T)
2. 变量与数据类型
2.1 变量
这一小节我们就要来学习 C++ 的第一个芝士点:变量了。变量,简单来说它是一个盒子,一个可以存放数据的盒子。这个盒子有类型,比如一个 int 类型的盒子就可以装入整数。盒子里面还有数据。当然盒子肯定得有一个名字,即变量名。

这个盒子的名称可以当作实际的值来调用,比如你输入 cout << number 就等于输入了 cout << 123。
那怎么定义一个变量呢?使用赋值语句,语法如下:
// 变量类型 变量名 = 变量值;
int number = 123;
这就定义了一个名叫 number,值为 123 的变量。上面的第一行代表注释,它可以帮助我们理解代码的意思。注释使用 // 开头,里面的内容不会被执行。
我们可以把它打印出来看一看:
#include
using namespace std;
int main() {
int number = 123;
cout << number << endl;
return 0;
}
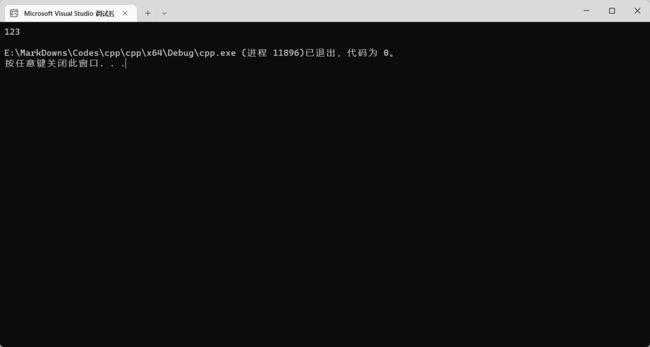
可以看见它打印出了 123:
当然变量只是一个盒子,盒子里面装的东西是可以改变的,比如你突然想把它改成 456 ,他就变成了 456:

我们可以试一试:
#include
using namespace std;
int main() {
int number = 123;
cout << "更改之前,number 的值为:" << number << endl;
// 这里由于我们已经定义了变量的类型为 int,所以这里就不用重复写了
number = 456;
cout << "更改之后,number 的值为:" << number << endl;
return 0;
}
效果很好~

上面的代码中,我们只使用了一行代码就新建了一个变量,但实际上我们要走两步流程:声明和定义。声明的意义就是向 C++ 说明,我这儿要建一个变量。而定义的意义就是告诉 C++,我要往这个变量里面放东西了。这两步流程如果不合并,是需要写成这样的:
int number;
number = 123;
我们上面的定义方式实际上是把两步合为一步。但是,声明只能出现一次,也就是说你跟 C++ 说了要建一个变量,你不能再跟它说再建一个和它同名的变量,否则它会报错。而定义可以出现很多次。
声明可以一次性初始化很多同类型的变量,比如 int a, b, c; 就是声明了三个类型为 int 的变量。后面我们只需要给它加入值就可以。
关于变量的命名其实也有规范,它能让我们的代码不报错,或是让其可读性更高,即让自己和别人能更好地读懂我们的代码。
首先变量名必须以字母或下划线开头。这个如果不按照规范走程序会报错(即程序出现了错误),比如 1number 就不行。
然后变量名尽量不要出现中文。这个就国际惯例了,虽然不会报错,但是尽量不要,对编码很不友好。
变量名中如果出现了多个单词,推荐使用驼峰命名法。比如你想给变量取 thisisanvalue 你可以写成 thisIsAnValue,看起来舒服多了。
最后一个就是不能使用 C++ 关键字。比如 int int = 3 就不行,要不然 C++ 会看不懂变量名这个 int 是变量名还是声明变量的关键字。关于关键字我们后面慢慢学~
2.2 数据类型:整型
这一小节和下面 2.3 2.4 两个小节,我们要来研究一下 C++ 中的数据类型。变量的数据类型绝对不止 int 一种,下面列出了所有的 C++ 内置基础类型(基础类型就是最基础的一些类型,除了基础类型之外的类型都是程序员自己定义的类型)。不同的基础类型,变量所占用的大小也不一样(你可以把它想象为盒子的容积)
short 短整型
int 整型
long int 长整型
float 单精度浮点型
double 双精度浮点型
long double 扩展精度浮点型
char 字符型
wchar_t 宽字符型
bool 布尔型
string 字符串(但是它不是基础类型,这里说明一下)
这一小节我们要讨论其中的整数类型,简称整型,即 short int 和 long int。这三种其实都可以表示整数,只是范围有些不同。short 可以表达 -32768 - 32767 之间的整数,int 和 long int 都可以表示 -2147483678 - 2147483647 之间的数。我们一般使用 int 表示整型。(个人想法:既然 int 和 long int 能表达的数值都一样了,那还要 long int 干嘛……)
这些数默认是有符号数,即有正有负的数。如果加上 unsigned 修饰符,就代表无符号数。它可以让一个数的正数范围扩大一倍,当然负数的部分就没了。比如 unsigned short 可以表示 0 - 65535 之间的数。unsigned 我们等到 002 讲计算机底层原理的时候再来细说。
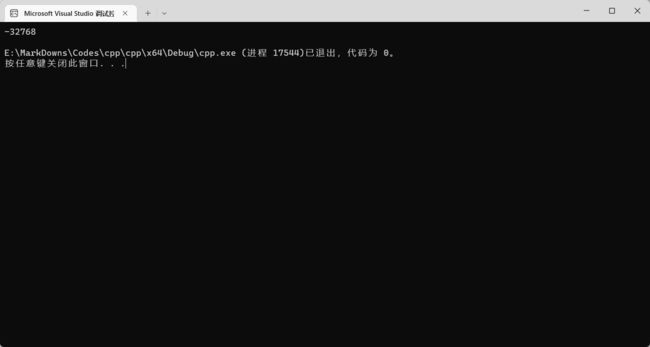
如果一个变量的值超出了其所规定的值,那么就会出现溢出。比如你给一个 short 赋值为 32768,这样就会溢出。C++ 处理溢出的方式也很简单:大于最大值的回到最小值,小于最小值的回到最大值。我们在开发中要尽量避免溢出。
下面演示一个溢出的例子:
#include
using namespace std;
int main() {
short number = 32768;
cout << number << endl;
return 0;
}
你可以看到打印出了 short 的最小值 -32768~
2.3 数据类型:浮点型
浮点型,说的通俗一点,它其实就是小数。但是对于小数数值的限制,可能有点儿复杂。一个浮点型的数值,C++ 需要存储它的整数部分和小数部分。这两个部分所使用的数字统称为有效数字。比如 3.14 的有效数字为 3 位。对于 float 来说,最多可以存储 6 位的有效数字。对于 double 和 long double 来说,最多可以存储 10 位的有效数字。其中我们一般使用 double。对于一个浮点类型来说,可以存储的小数部分的位数称为它的精度。通常一个浮点类型的变量可以存储的精度 = 有效数字位数 - 整数部分位数。
浮点型和整型的使用方法是一样的:
#include
using namespace std;
int main() {
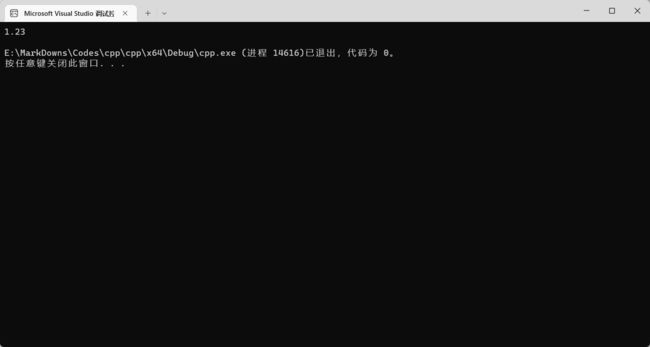
double doubleNum = 1.23;
cout << doubleNum << endl;
return 0;
}
执行效果:
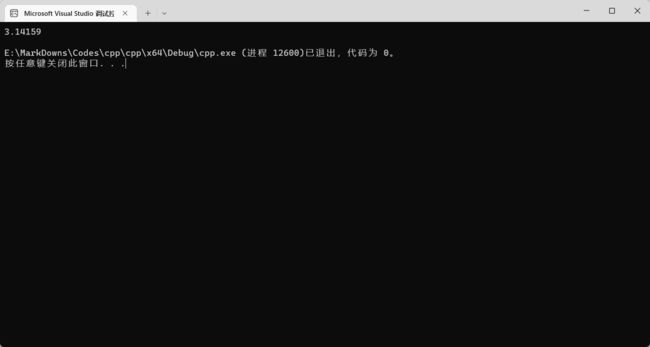
浮点型如果超出了存储大小,不会造成溢出,而会造成精度损失。比如你给一个 float 类型的变量放入一个小数点位数十几位的小数,它就会帮你把这个小数“四舍五入”成变量支持的最大精度。
#include
using namespace std;
int main() {
float pi = 3.14159265358979;
cout << pi << endl;
return 0;
}
2.4 数据类型:字符,字符串和布尔型
这一小节我们要学习三种其它的类型:字符型,字符串和布尔型。字符,其实就是字符串当中的一个字母或者空格或是控制符号比如回车,比如 a 就是一个字符。字符使用单引号 ‘’ 来包裹。这里有一个可能很难理解的点:字符是可以和整型互化的。比如 char ch = 97,C++ 会把 97 转化成字符 a。C++ 使用 ASCII 字符表来转化,具体看 https://zhuanlan.zhihu.com/p/388458283 这篇文章。
下面我们做一个实验:
#include
using namespace std;
int main() {
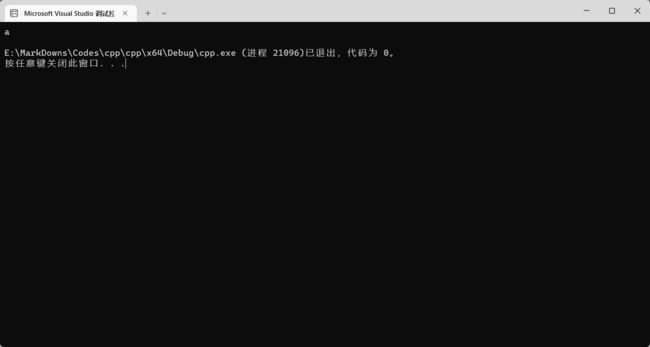
char ch = 97;
cout << ch << endl;
return 0;
}
可以看见打印出了 a~
那还有一个 wchar_t 是什么呢?它可以表示的字符就不仅仅局限于英文了,还可以表示中文等其它字符。因为它的大小增加了一倍。下面给个示例:
#include
using namespace std;
int main() {
wchar_t wch = '好';
cout << wch << endl;
return 0;
}
可以看到它打印出了“好”字转化为整型之后的代码,为 47811。

接下来我们要介绍一个不是基本类型,但是很常用的数据类型:字符串。它其实就是几个字符组成的,比如我们上面的 Hello World 就使用了字符串。要使用字符串类型,你首先要先引入一个库叫做 string:
#include
然后直接使用 string 定义变量即可。变量的值就是双引号包裹的几个字符。我们可以试着打印它:
#include
#include
using namespace std;
int main() {
string str = "Hello, C++!";
cout << str << endl;
return 0;
}
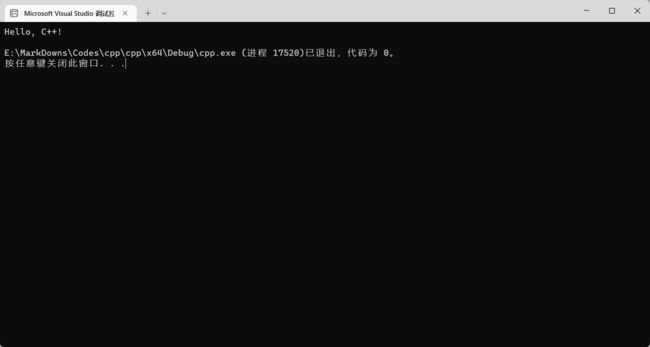
最后一个就是布尔型 bool 了。它可以存储一个布尔值,即真(true)或假(false)。C++ 在处理布尔值时会把 true 转换为 1,false 转换为 0。我们可以自己输入 true 或 false,也可以传递一个整型,如果这个整型为 0 则转换为 false,否则转换为 true。下面给一个例子:
#include
using namespace std;
int main() {
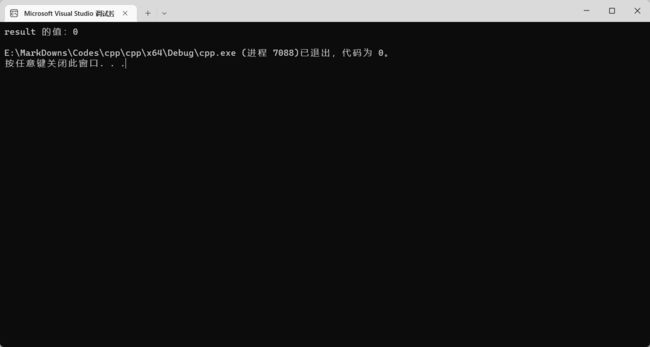
bool result = true;
result = 0;
cout << "result 的值:" << result << endl;
return 0;
}
2.5 字面值常量
这小节我们要学习一个新用过的芝士点:字面值常量。我们刚刚在给变量赋值的时候,比如 int number = 123,里面的 123 就是字面值常量(简称字面量)。字面值常量,顾名思义,就是被用作字面值(在程序中直接出现的值)的常量(不可以更改的量)。这里我们主要来说说字面值常量的数据类型。
如果一个整数什么后缀也不加,则默认为 int 类型。
如果你想使用无符号的整型,可以在后面加上后缀 u。比如 30u。(当然如果你要声明一个无符号数是不需要的)
如果你想使用长整型即 long int,可以在后面加上后缀 l。比如 1234567890l。如果你想把上面两种 Buff 叠加起来,可以加上后缀 ul。
如果一个浮点数(即小数)什么后缀也不加,默认为 double 类型。
如果你想使用 float,可以在后面加上 f 后缀。比如 3.14f。
如果你想使用 long double,和 long int 一样加上后缀 l 就可以。
(上述所有的后缀字母都可以变成大写)
如果一个字符什么也不加,则默认为 char 类型。
如果一个字符套上了一个 L’',比如 L’好’,那么该字符为 wchar_t 类型。
布尔型就不需要多说了吧,就直接使用 true 和 false 就行。
至于字符串,大家自己体会,Hello World 里面就有出现……
下面举一个 float 字面量精度损失的例子:
#include
using namespace std;
int main() {
cout << 3.14159265358979f << endl;
return 0;
}

这里还有一个与字面量没什么关系但是又有点儿关系的知识点需要注意,在定义字符串时,我们可以使用 \ 反斜杠来转义一些字符,比如 \n 代表换行,\t 代表缩进(一般为 4 格)。除此之外,反斜杠 \ 还可以被用来在字符串中把一些特殊字符显示在屏幕上,比如 \ 后面加双引号 "。如果你不加 \ 的话双引号会被识别为字符串结束的标志,加了 \ 的话 C++ 就知道这是转义了。和双引号相似的还有问号 ?(不过貌似问号不加反斜杠也可以)和反斜杠本身。下面举一个栗子:
#include
using namespace std;
int main() {
cout << "Does \"1+1\" equal 2\?" << endl;
return 0;
}
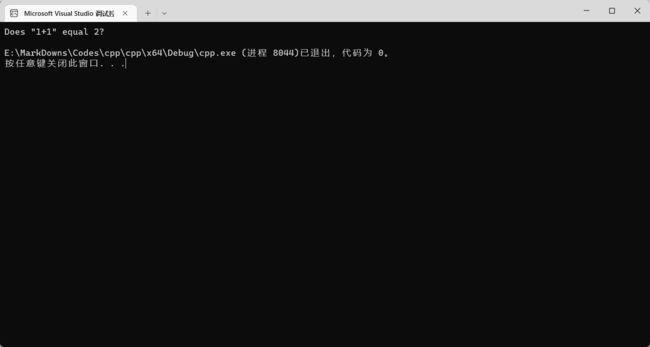
这里拓展一个小知识:如果你想使用纯纯的常量(不是字面量),即把它定义为变量那种形式,并且里面的值不能更改,你可以使用 const 修饰符。比如定义一个 int 常量就可以写成 const int NUMBER = 123。且定义常量的时候通常使用大写字母,而且不使用驼峰命名法使用下划线 _,比如 PI_DOUBLE。
2.6 typedef 类型名简写
不知道同学们有没有一个需求,就是一些类型名非常长的类型,比如 unsigned long int,敲起来非常烦,可不可以简写一下?typedef 可以帮你。它可以帮你把一个很长的类型名替换成短的类型名。比如 typedef unsigned long int ul,我们后面写代码的时候就可以使用 ul 来替换 unsigned long int 了。C++ 会自动将 unsigned long int 识别为一个整体,所以不用担心空格的问题~
下面举个粒子:
#include
using namespace std;
int main() {
typedef unsigned long int ul;
ul number = 1234567890;
cout << number << endl;
return 0;
}

3. 表达式与操作符
3.1 表达式
这小节我们就要学习 C++ 里面的表达式了。表达式它其实也不难,它就是一个可以返回一个值的式子,返回的值称为该表达式的值。比如 1+1,1+2+3+4+5+6 这些都是表达式。一个变量名也是表达式,比如 number,它返回这个变量的值。一个变量名和一个字面量进行操作,比如 number+1,它也是一个表达式,返回这个变量与 1 相加的结果。如果你在一个程序里写了一个表达式,那么 C++ 实际得到的就是这个表达式的值。举个例子:
#include
using namespace std;
int main() {
cout << 1 + 1 << endl;
return 0;
}
可以看到打印出了 2:

3.2 算术操作符
表达式最核心的功能在于操作符,比如 1+1 中的 +,它让两边的数进行加法运算然后返回它们的和。所以下面几个小节我们就来学习一下操作符。这里先来算术操作符。
算术操作符非常简单,就是我们熟知的加减乘除。加法用 +,减法用 -,乘法用 *,除法用 /。这里的 / 是整数除法,比如 5/2 不会求得 2.5 而会求得 2。而且它不会四舍五入,0.5 直接去掉不会变成 1。
除此之外还有两个特殊的,取余数用 %,比如 5 % 2 求得的就是 5 ÷ 2 = 2 …… 1 里面的余数 1。取余数不能对浮点数进行,也不能对负数进行,否则要么报错,要么结果很奇怪。还有取相反数在数值前面加上 - 就可以,比如 -(-5) 求得 5。
#include
using namespace std;
int main() {
int a = 5;
int b = 2;
cout << a / b << endl;
cout << a % b << endl;
return 0;
}
结果:
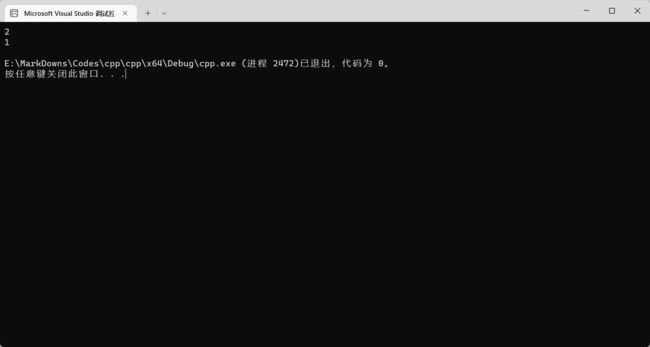
3.3 关系操作符与逻辑操作符
这小节我们要学习一些返回布尔值的操作符:关系操作符与逻辑操作符。
关系操作符,它是用来比较两个数的。判断是否相等使用 ==(两个等于号),是否不等使用 !=,是否大于使用 >,是否小于使用 <,是否大于等于使用 >=,是否小于等于使用 <=。它会返回一个布尔值。比如 3 == 5,很明显它是不成立的,所以会返回 false,或者 3 < 5 ,很明显它是成立的,所以返回 true。这些由关系操作符组合起来的表达式最好使用括号括起来,以避免一些不必要的麻烦和报错。
#include
using namespace std;
int main() {
int a = 5;
int b = 2;
cout << (a > b) << endl;
cout << (a == b) << endl;
return 0;
}
结果:

逻辑操作符是一些可以对布尔值进行操作的操作符。比如 && 代表逻辑与,意思就是 && 左右的表达式都需要是 true,一整个 && 表达式才能是 true。比如 true && false 返回 false。
|| 代表逻辑或,意思就是 || 左右的表达式只要有任意一个为 true 那么一整个表达式就为 true。
! 代表逻辑非,它只有一个操作数,比如 !false。它对右边的操作数进行取反,比如 !true 的值为 false,!false 的值为 true。
和上面的关系操作符一样,所有的逻辑操作符外边儿都需要套一个括号。
#include
using namespace std;
int main() {
int a = 5;
int b = 2;
cout << ((a > b) && (a == b)) << endl;
cout << ((a > b) || (a == b)) << endl;
return 0;
}

关系操作符与逻辑操作符可以无限套娃,想套几层套几层,C++ 都会为你生成最后的结果。
这里扩展一个小知识点:短路求值。它的意义非常简单,比如一个 || 操作符,左边已经判断出来是 true 了,那么右边的那个 C++ 就不判断了直接返回结果。比如你想在右边给一个变量赋值,C++ 也会自动跳过。&& 同理,左边已经判断出是 false 了,那么右边也不执行了直接返回结果。
3.4 赋值操作符
这个我们已经非常熟悉了,因为变量那节我们就用到了赋值操作符:int number = 123。里面的 = 代表把这个赋值表达式的右边的值(简称右值)赋给左边的变量或常量(简称左值)。这里这个赋值表达式返回的结果是右值,所以我们可以连续赋值:a = b = 1+1,这样 a 和 b 都等于 2。
当然赋值操作符绝对不止 = 一种,还有以下几种:
+=,把左值和右值相加后的返回值赋给左值,比如 a += 1 相当于 a = a + 1。
-=,把左值和右值相减后的返回值赋给左值,比如 a -= 1 相当于 a = a - 1,下面的全部同理。
*=,把左值和右值相乘后的返回值赋给左值。
/=,把左值和右值进行整数除法所得的返回值赋给左值。
%=,把左值和右值取余数所得的返回值赋给左值。
其中我们比较常用的是简单的 += 和 -=。下面给个李子:
#include
using namespace std;
int main() {
int a = 5;
int b = 2;
a += b;
cout << a << endl;
a *= b;
cout << a << endl;
return 0;
}

还有两个特殊的赋值操作符:++ 和 --。它们的作用分别为 +1 和 -1。这两种操作符可以放在操作数的前面或后面,但意思有点儿不同。如果放在后面代表先返回值后 +1。比如 a = 1++,a 的值是 1。如果放在前面代表先 +1 后返回值,比如 a = ++1,a 的值是 2。
#include
using namespace std;
int main() {
int c = 5;
cout << "++c:" << ++c << endl;
cout << "c++:" << c++ << endl;
return 0;
}
可以看到打印出来的都是 6。但实际上现在 c 的值为 7。

3.5 条件操作符
这个操作符的功能就有些强大了。它有三个操作数,当第一个操作数为真时,返回第二个操作数,否则返回第三个操作数。条件操作符只有一个,写成类似 (a == b) ? a : b 的形式,其中的 (a == b) 为第一个操作数,后面的就是第二、第三个操作数。返回的操作数还可以是赋值表达式,是不是非常强大~
#include
#include
using namespace std;
int main() {
string result = "等待比较……";
cout << result << endl;
int a = 3;
int b = 5;
result = (a > b) ? "a > b" : "a < b";
cout << result << endl;
return 0;
}
结果:

3.6 操作符的优先级
现在我们学了这么多操作符,但是如果把这些操作堆在一起,那 C++ 会先执行哪个呢?这就涉及到了操作符的优先级。
一般来说,优先级更高的操作会更先执行,优先级更低的操作就后面执行,我们现在学过的操作符的优先级如下:
1 级:a++,a–
2 级:++a,–a,-a,!a
3 级:a*b,a/b,a%b
4 级:a+b,a-b
5 级:a < b,a > b,a <= b,a >= b
6 级:a == b,a != b
7 级:a && b
8 级:a || b
9 级:a ? b : c
10 级:a = b,a += b,a -= b,a *= b,a /= b,a %= b
优先级从 1 到 10 级递减。如果几个操作优先级一样,那就是按照默认顺序执行。当然这些优先级不用背,记得一些常用的就行,如果不确定优先级可以使用括号,无视所有优先级。
3.7 类型转换
一般来说,操作符的操作数如果有一个,称其为一元操作符,如果有两个,那就是二元操作符。如果有三个,那就是三元操作符。
当然我们这小节的主题不是这个,我们要来说说类型的转换。一般的二元操作符,两个操作数的类型要一样,比如 1+2,两边都是 int 类型。但是也有一些操作数的类型不一样,比如 1.2 + 2,一边是 int 类型,一边是 double 类型。我们可以显而易见的得出结果:3.2,但是 C++ 面对两个类型不一样的值,是怎么处理的?
其实 C++ 本身是不支持两个类型不一样的值操作的。这里 C++ 帮我们做了隐式类型转换(简称隐式转换),它会把整型转化为浮点型,然后两个浮点型再相加得到。隐式类型转换在操作时一般是把容量小的往容量大的转换,整型往浮点型转换,有符号数往无符号数转换,这样才能保持最大的精度。不信我们实验一下:
#include
using namespace std;
int main() {
cout << 1.2 + 2 << endl;
return 0;
}
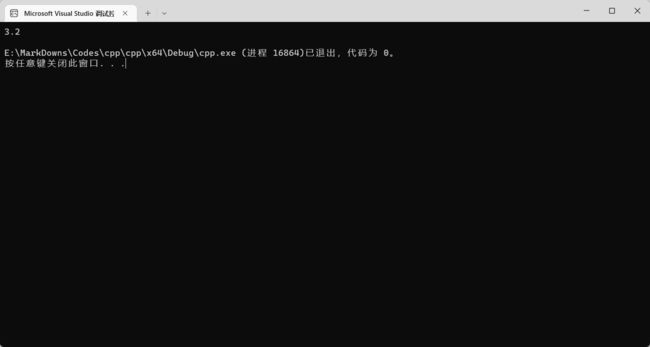
但是有一种特殊的隐式转换。这种隐式转换出现在转换后的类型已经固定的情况下。比如 1.2 + 2 的结果必须要是一个 int,那只能把 0.2 “砍掉”,最后得出 3。
#include
using namespace std;
int main() {
int number = 1.2 + 2;
cout << number << endl;
return 0;
}
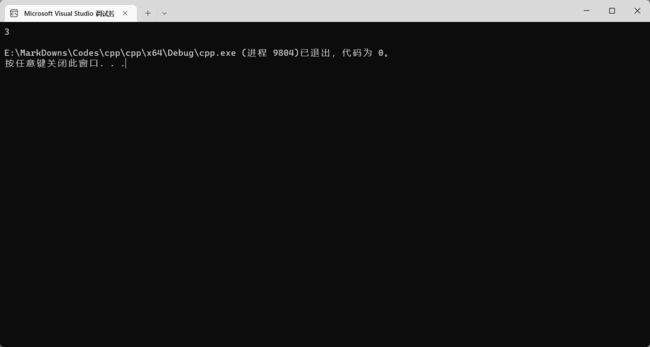
那既然有隐式转换,那肯定就有显式转换了。在 C++ 中实现显式转换有两种途径:C 风格和 C++ 风格。
C 风格转换非常易懂,比如你想把 1.2 转换为 int,我们可以在 1.2 的前面加上一个 (int),即 (int)1.2,然后这个数就会被转换成 int 类型,即 1。
#include
using namespace std;
int main() {
cout << (int)1.2 + 2 << endl;
return 0;
}

C++ 风格的转换写起来会稍微复杂一点。C++ 的转换要写成如下这样:
static_cast(1.2)
其中前面的 static_cast 不变,<> 里面写需要转换的类型,() 里面需要转换的数字。在实际使用中,我们更建议使用 C++ 风格转换,不为别的,C++ 的语言特性,我们总得去捧捧场吧……而且 static_cast 你不觉得非常好认吗……
#include
using namespace std;
int main() {
cout << static_cast(1.2) + 2 << endl;
return 0;
}
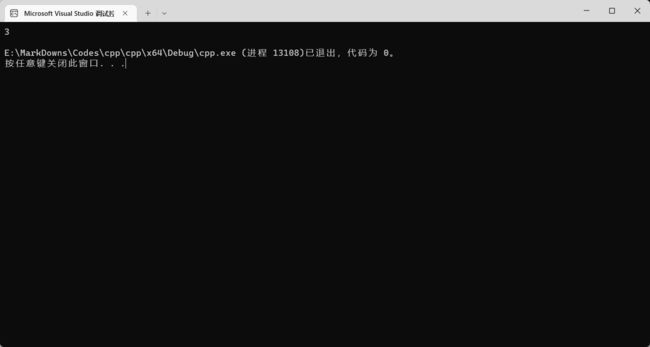
4. 常用的程序结构
4.1 作用域
如果说前 3 章都是在打基础的话,到了第 4 章,我们就要开始来一点基础有难度的内容了。这一章里面我们会介绍分支结构与循环结构。当然在讲这些结构之前,我们要先来认识一下作用域。
如果你的程序中出现了花括号 {},那么你的程序里就出现了作用域。一般来说,花括号里面定义的变量,只对这个花括号里面的内容有效。这些变量有效的区域就叫做它的作用域。出了作用域,这些变量就会被销毁。不管是什么花括号都算数,就算什么也没有,单独一个花括号也算数。
如果你在作用域之外使用作用域之内的内容,C++ 会给你报一个错,显示变量没有声明过。比如下面的例子:
#include
using namespace std;
int main() {
{
int num = 1;
}
cout << num << endl;
}

而你在花括号之内是可以使用花括号之外的内容的。因为花括号之外变量的作用域还包括了花括号之内的内容。
那如果花括号之内定义了一个变量 num,花括号之外也定义了一个变量 num,那如果在花括号内打印 num,会打印哪个 num?这涉及到了 C++ 变量查找的规则。C++ 查找变量是从内向外查。也就是如果在花括号内查找到 num,就不再往外查找了。比如一个例子:
#include
using namespace std;
int main() {
int num = 1;
{
int num = 2;
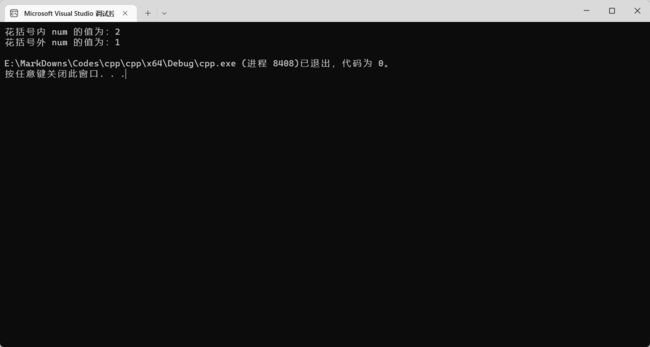
cout << "花括号内 num 的值为:" << num << endl;
}
cout << "花括号外 num 的值为:" << num << endl;
return 0;
}
结果显而易见:
4.2 if 语句
接下来我们正式学习分支语句。if 语句是最简单的分支语句。它在某一个条件满足的时候,执行一些代码。if 语句需要执行的代码需要使用花括号包裹。比如下面:
#include
using namespace std;
int main() {
bool isLikeBasketball = true;
// if 语句后面要接一个括号,里面是一个布尔值或返回布尔值的表达式
// 当该表达式的值是 true 时执行 if 中的代码,否则不执行
if (isLikeBasketball) {
cout << "该用户喜欢篮球" << endl;
}
return 0;
}
你应该会看见输入“该用户喜欢篮球”:

如果你把 isLikeBasketball 的值改为 false,它什么也不会输出。
if 语句后面还可以选择性地加上 else 语句。如果 if 语句的条件不满足就会执行 else 的代码:
#include
using namespace std;
int main() {
bool isLikeBasketball = false;
if (isLikeBasketball) {
cout << "该用户喜欢篮球" << endl;
}
else {
cout << "该用户不喜欢篮球" << endl;
}
return 0;
}
按照上面的程序来走,因为 isLikeBasketball = false,所以 if 里面的程序就不会被执行,接着来到 else,执行 else 中的代码。所以输出应该是:
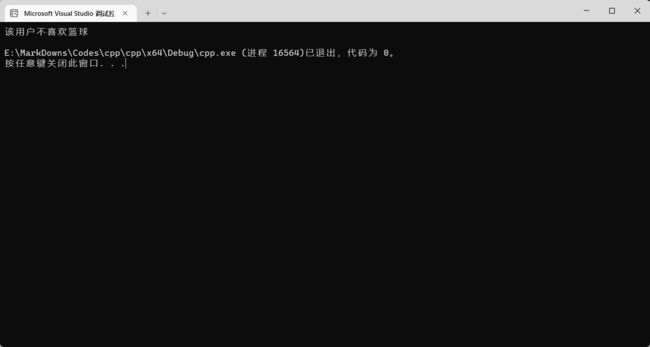
if else 也可以套娃,比如这个例子:
#include
using namespace std;
int main() {
int num = 3;
if (num < 10) {
if (num % 2 == 0) {
cout << num << " 是 10 以内的偶数" << endl;
}
else {
cout << num << " 是 10 以内的奇数" << endl;
}
}
else {
cout << num << " 是 10 以外的数" << endl;
}
return 0;
}
结果:
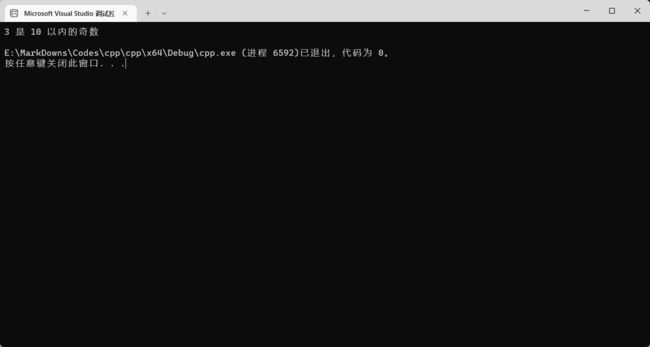
if 语句的后面还可以加 else if 语句。else if 语句在 if 不成立时执行,如果 else if 匹配的条件成立,那么执行 else if 中的代码。比如下面:
#include
using namespace std;
int main() {
int score = 74;
if (score >= 85) {
cout << "优" << endl;
}
else if (score >= 70) {
cout << "良" << endl;
}
else if (score >= 60) {
cout << "及格" << endl;
}
else {
cout << "不及格" << endl;
}
return 0;
}
应该可以打出结果为良:

其实 else if 还可以写成 if else 套娃的形式,只是把 else 的花括号省略了而已。实际上,else if 是 if else 套娃的语法糖(意思就是 else if 只是简化了语法,原理是没有变的)
4.3 switch 语句
或许很多人在敲代码的时候都会遇见这样的:
#include
using namespace std;
int main() {
int num = 7;
if (num == 0) {
cout << "零" << endl;
}
else if (num == 1) {
cout << "一" << endl;
}
else if (num == 2) {
cout << "二" << endl;
}
else if (num == 3) {
cout << "三" << endl;
}
else if (num == 4) {
cout << "四" << endl;
}
else if (num == 5) {
cout << "五" << endl;
}
else if (num == 6) {
cout << "六" << endl;
}
else if (num == 7) {
cout << "七" << endl;
}
else if (num == 8) {
cout << "八" << endl;
}
else if (num == 9) {
cout << "九" << endl;
}
else {
cout << "不在 0~9 范围内!" << endl;
}
return 0;
}
这样的 if 语句有很多地方重复了,比如 else if (num == ) 出现了很多次。那这种写法有没有更简便的?switch 语句帮你解决。它的基本语法是这样的:
switch (a) {
case xxx:
dosomething...;
break;
case yyy:
dosomething...;
break;
default:
dosomething...;
}
它的工作流程是:如果 a == xxx,那么执行 xxx 这个 case 里面的代码。最后的 break 跳出 switch 一定不能少,要不然就会执行下一个 case 中的代码,称为贯穿。如果 a == yyy,那么执行 yyy 中的代码,如果都不匹配那么执行 default 中的代码。其中 default 像 if 语句中的 else 一样为可选。
接下来我们用 switch 写一个大~~~应用。用户在键盘上输入一个 0~9 的阿拉伯数字,然后我们把这个阿拉伯数字对应的中文汉字打印出来。话不多说,开写~
#include
using namespace std;
int main() {
int num;
cout << "请输入一个 0~9 之内的数字,我们可以帮你转化成中文数字。" << endl << "请输入:";
// 对下面注释的一个注释:下面这叫成对注释,/* */ 中间的内容都会被算作注释
/*
* 下面的 std::cin 和 std::cout 一样都是 iostream 库里的一个函数
* 只是省略了 std
* cin 的功能是把用户输入的一个字符串赋值给一个变量
* 使用 >> 操作符
* 比如这里我们把它赋值给了 num
* 如果用户输入了一个含空格的字符串
* 那 cin 会把它以空格作为分界线拆成几个字符串
* 然后把几个字符串分别赋给几个变量
* 比如 cin >> n1 >> n2 >> n3;
*/
cin >> num; // 这里 C++ 帮我们做了隐式转换,换成显式的就是 static_cast(输入值)
switch (num) {
case 0:
cout << "零" << endl;
break; // break 千万不能忘
case 1:
cout << "一" << endl;
break;
case 2:
cout << "二" << endl;
break;
case 3:
cout << "三" << endl;
break;
case 4:
cout << "四" << endl;
break;
case 5:
cout << "五" << endl;
break;
case 6:
cout << "六" << endl;
break;
case 7:
cout << "七" << endl;
break;
case 8:
cout << "八" << endl;
break;
case 9:
cout << "九" << endl;
break;
default:
cout << "数字不在 0~9 范围内!" << endl;
// 这里由于最后一个了
}
return 0;
}
效果 very good:
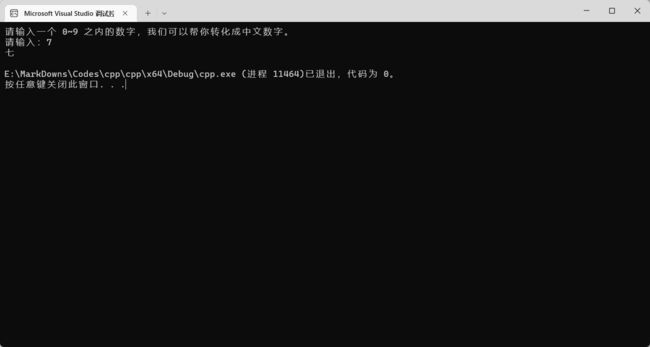
关于贯穿我们这里也要好好提一下。贯穿可以视作 C++ 中的一个 bug。但是对开发不利的叫 bug,对开发有利的就叫特性。这里我们就介绍怎么把贯穿变成特性。比如我们可以使用贯穿来实现奇偶判断:
#include
using namespace std;
int main() {
int num;
cout << "请输入一个 0~9 之内的数字,我们可以帮你判断奇偶。" << endl << "请输入:";
cin >> num;
switch (num) {
case 0:
case 2:
case 4:
case 6:
case 8:
cout << "偶数" << endl;
break;
case 1:
case 3:
case 5:
case 7:
case 9:
cout << "奇数" << endl;
break;
default:
cout << "数字不在 0~9 范围内!" << endl;
}
return 0;
}
效果:
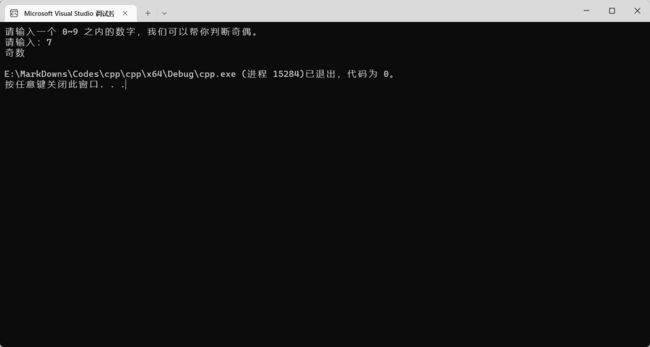
4.4 for 循环
接下来我们要学习循环结构。循环结构解决了我们的一大痛点:重复输入。比如下面的程序:
#include
using namespace std;
int main() {
int num = 1;
cout << "num 的值为:" << num++ << endl;
cout << "num 的值为:" << num++ << endl;
cout << "num 的值为:" << num++ << endl;
cout << "num 的值为:" << num++ << endl;
cout << "num 的值为:" << num++ << endl;
cout << "num 的值为:" << num++ << endl;
cout << "num 的值为:" << num++ << endl;
cout << "num 的值为:" << num++ << endl;
cout << "num 的值为:" << num++ << endl;
cout << "num 的值为:" << num++ << endl;
return 0;
}
这个程序实现了如下效果:
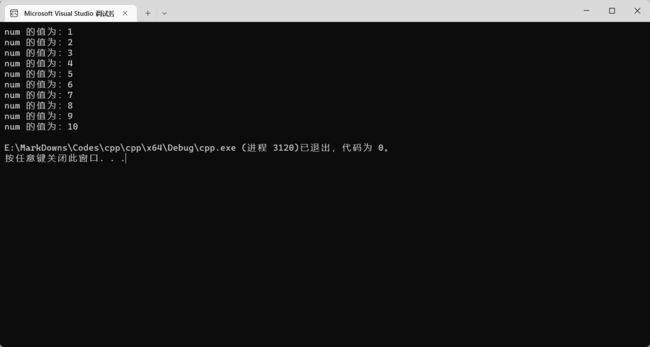
那我们能不能少敲一些代码,而实现一样的效果呢?for 循环可以帮助你。for 循环后面接一个 (),里面有三个语句。第一个语句为计数器初始化语句。它可以帮我们初始化一个拥有计数器功能的变量,比如 int num = 0;。这个变量出了作用域就会被销毁,与上面讲到的是一样的。第二个语句就是让这个变量发挥作用的语句。它是一个返回布尔值的表达式(后文称为条件表达式),比如 num < 10。最后一个语句是操作计数器的语句,在循环的所有内容执行完之后触发。一般为计数器的自增减操作,比如 num++。下面我们简化一下上面的代码:
#include
using namespace std;
int main() {
for (int num = 0; num < 10; num++) {
// 这里因为 num 在循环中是从 0 开始的,而不是从 1 开始。所以我们要给它加上 1
cout << "num 的值为:" << num + 1 << endl;
}
return 0;
}
完美复刻~
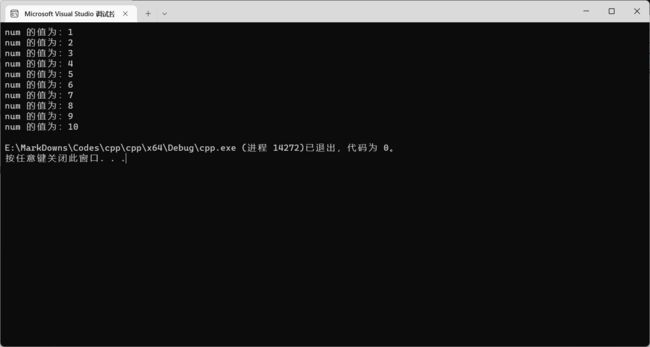
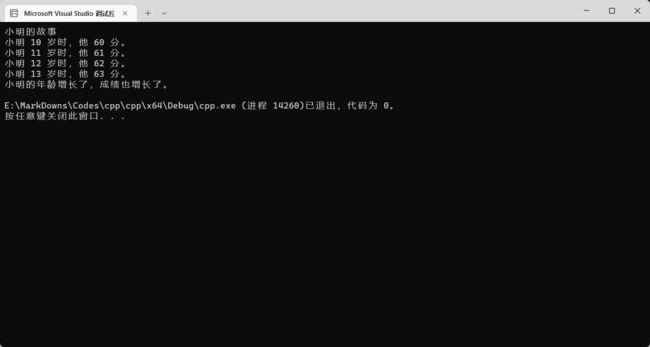
计数器可以不止有一个。我们可以初始化两个计数器,之间用逗号 , 隔开。后面的操作计数器也可以操作两个,也是用 , 号隔开~
#include
using namespace std;
int main() {
cout << "小明的故事" << endl;
for (int score = 60, age = 10; age < 14; score++, age++) {
cout << "小明 " << age << " 岁时,他 " << score << " 分。" << endl;
}
cout << "小明的年龄增长了,成绩也增长了。" << endl; // 所以多个计数器的 for 循环你学会了没~
return 0;
}
结果:
VS 小 tip:如果你迫不得已需要使用我演示的第一种形式,你可以使用 Visual Studio 提供的快捷键 Ctrl + D 快速把一行代码复制为多行代码。
4.5 while 循环
while 也是一种循环方式。它比 for 循环更简便。它省略了 for 循环中的计数器初始化和操作计数器语句,只保留一个判断表达式。至于删除的两个操作,我们可以通过自己的代码补上。下面把 num 的值那个练习用 while 写一遍:
#include
using namespace std;
int main() {
// 计数器初始化放在了这里
// 它不受作用域的限制
int num = 0;
while (num < 10) {
cout << "num 的值为:" << num + 1 << endl;
// 对计数器的操作放在了这里
num++;
}
return 0;
}
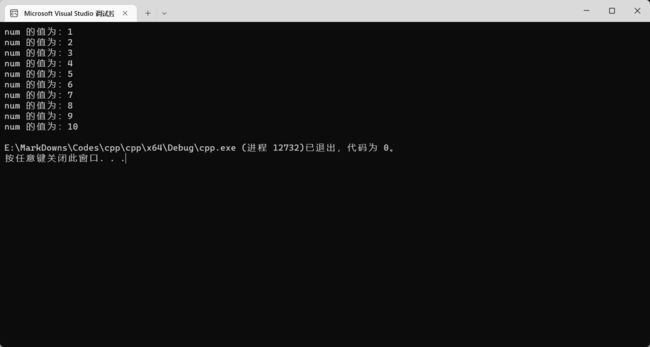
while 循环还有一种变体:do while。它把 while 的判断写在后面,把前面的 while 换成 do。后面的 while 判断要加分号,就像下面这样:
do {
dosomething;
} while ();
do while 和 while 最大的不同在于不管 while 后面的条件表达式是否为真,do 中的程序都先执行了一遍。因为 do while 是先执行后判断。比如下面的示例:
#include
using namespace std;
int main() {
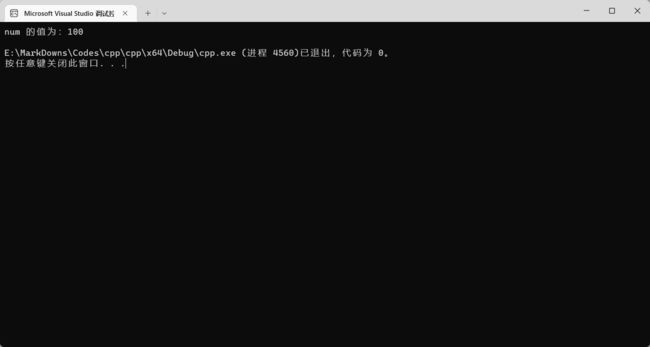
int num = 100;
do {
cout << "num 的值为:" << num << endl;
num++;
} while (num < 10);
return 0;
}
4.6 break 与 continue
这小节我们要学两个小语句:break 和 continue。break 在之前 switch 语句中就已经见过,它用于跳出一个程序块。它同样也可以跳出循环结构。比如下面:
#include
using namespace std;
int main() {
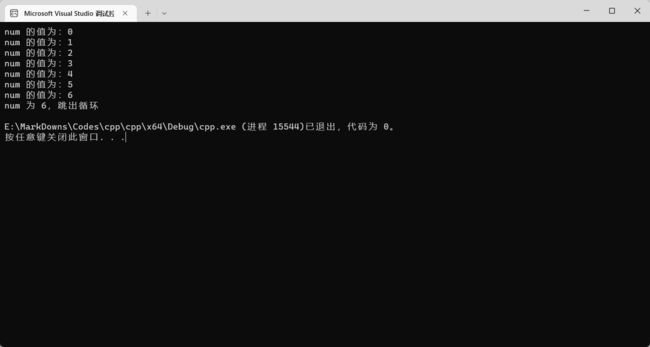
for (int num = 0; num < 10; num++) {
cout << "num 的值为:" << num << endl;
if (num == 6) {
cout << "num 为 6,跳出循环" << endl;
break;
}
}
return 0;
}
执行结果:
那如果只是想跳过本次循环的剩余内容呢?使用 continue。它可以帮你直接进入下一次循环。
#include
using namespace std;
int main() {
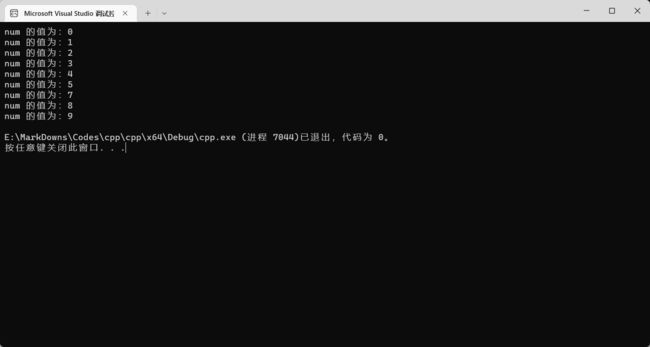
for (int num = 0; num < 10; num++) {
if (num == 6) {
continue;
}
cout << "num 的值为:" << num << endl;
}
return 0;
}
可以看到缺了 6~
C++ 还有一个功能很强大的工具:goto。但是因为太强大,会让很多结构错乱,看起来也不方便,所以不推荐使用。但这里还是讲一讲用法。
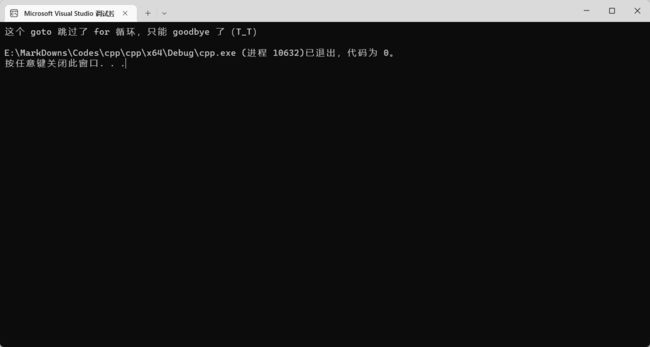
goto 可以跳到任何一个被标签标记过的地方,比如下面这个例子:
#includeusing namespace std; int main() { goto goodbye; for (int num = 0; num < 10; num++) { cout << "num 的值为:" << num << endl; } goodbye: cout << "这个 goto 跳过了 for 循环,只能 goodbye 了(T_T)" << endl; return 0; }
5. 数组
5.1 数组的基本使用
接下来我们要学一个新东西:数组。当然这里先声明一下,vector 比数组更好用
数组是一个固定的数据容器。数组容量固定,类型固定,看看人家 vector 都能随便新增元素
数组的使用非常简单。语法如下:
// 类型名 数组名[数组大小] = { 元素 1, 元素 2, 元素 3... };
其中的数组大小限制非常多,只能使用整型字面量或是 const 常量,不能使用变量。虽然我觉得使用变量没什么问题,但人家 C++ 觉得有问题我们有什么办法……
初始化数组(就是右边那个)可以不把数组大小填满,未填满的值 C++ 会帮我们填充该类型的默认值,比如 int 是 0。初始化数组还可以不填,直接分号结束。这样数组的初始化数组就全是默认值了~
如果你确定你的初始化数组填满了,数组大小可以不填,C++ 会帮我们计算~
那如何指定数组的某一个元素呢?使用下标。比如我们想取到数组中的第一个元素,我们就可以使用下标 10。下标从 0 开始计算,所以我们要把实际的位置 - 1 得到下标。
// 数组名[下标]
有了下标,我们就可以使用循环遍历数组:
#include
#include
using namespace std;
int main() {
string food[5] = { "ice cream", "pizza", "chicken", "rice", "cherrys" };
for (int i = 0; i < 5; i++) {
cout << "food 数组第 " << i + 1 << " 项的食物是 " << food[i] << endl;
}
return 0;
}

我们还可以更改下标中某一元素的值,更改方式很简单,形如以下形式,和更改变量一样方便:
数组名[下标] = 值;
比如下面:
#include
#include
using namespace std;
int main() {
string food[5] = { "ice cream", "pizza", "chicken", "rice", "cherrys" };
cout << food[2] << endl; // 下标是 2,获取到的元素就是第 2+1=3 个,即 chicken
food[2] = "lichee";
cout << food[2] << endl;
return 0;
}

数组使用时有一个坑。要更改数组,只能每次更改其中的一个值,不能一整个改。要不然会报错:
#include
#include
using namespace std;
int main() {
string food[5] = { "ice cream", "pizza", "chicken", "rice", "cherrys" };
food = { "Coke", "Sprite", "Fanta", "Lemonade", "Milk Tea" };
return 0;
}
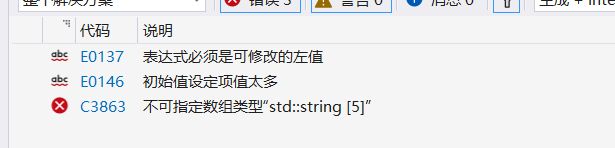
(重点是“表达式必须是可修改的左值”,这说明数组不可一整个修改)
5.2 多维数组
上面我们说了,if 可以套娃,for 可以套娃,同样数组也可以套娃。但数组套娃和上面 if for 的简单套娃有些不一样。数组的套娃需要指定每一个子数组的大小(子数组的大小必须一样)。如下:
// 类型名 数组名[数组大小][子数组大小][子子数组大小(如果有)] = 数组值;
这样的数组不管套了几层娃我们都管它叫做多维数组。其中套两层娃我们称为二维数组,套三层称为三维数组,以此类推。
多维数组获取元素要使用多个下标,比如 numbers[1][2] 代表获取第 2 个子数组的第 3 个值。
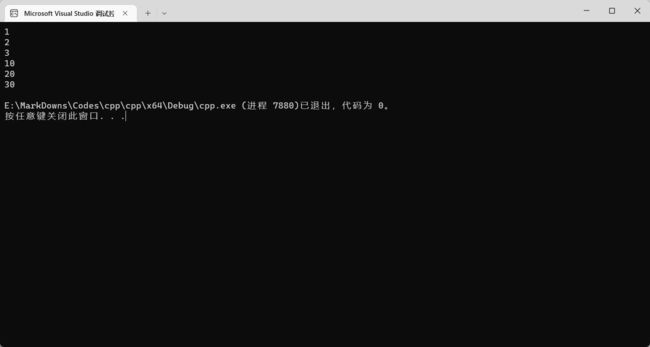
多维数组需要使用多层循环遍历,如下:
#include
using namespace std;
int main() {
int numbers[2][3] = { { 1, 2, 3 }, { 10, 20, 30 } };
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 3; j++) {
cout << numbers[i][j] << endl;
}
}
return 0;
}
6. 函数
6.1 封装思想与函数
这小节我们就要学习 C++ 中的重中之重:函数了。函数,其实就是把一些实现一定功能的代码封装成一个代码块,需要的时候调用它就相当于调用了函数中的所有代码。说起函数就不得不提一下函数所遵循的思想原则:封装思想。
比如你把一个函数比作一个计算器,能加减乘除的那种。它的功能是什么?不就是加减乘除吗。
那说这个,跟封装有什么关系?这我们就要聊聊计算器是怎么实现的了。计算器首先要把你输入的数字读进去,然后一番八仙过海各显神通得出结论,再把结论显示在屏幕上。
但是计算器到底是怎么个八仙过海各显神通呢?先别思考这个问题,重点是,我们这些计算器用户需不需要知道计算器的内部原理是什么?很明显是不需要的。我们只需要知道计算器能够帮我们加减乘除就可以了。所以,把内部原理隐藏起来,只让使用者知道函数功能的操作就叫做封装。函数很明显就是遵循封装思想的。
其实前面的作用域也是遵循封装思想,才不让作用域内的变量再作用域外也能使用。如果这样的话,就等于把计算器的外壳拆掉,直接把里面复杂的电路暴露出来。这会让用户感觉非常疑惑。
接下来我们把话题回到函数。函数等同于一个可以实现自定义功能的计算器。函数可以接收参数。比如计算器,我们输入的值就是计算器的参数。计算器根据接收的参数进行运算然后得到结果。参数需要指定一个数据类型。
函数声明时定义的参数叫做形式参数,简称形参。用户实际传入的参数叫做实际参数,简称实参。函数中使用形参就等于使用了传入的实参。
函数本身定义时是不会被执行的,要执行函数,我们需要调用它。上面其实已经出现过这个术语了。
函数可以返回一个值,简称返回值。函数调用本身也可以作为表达式,表达式的值就是函数的返回值。函数返回值也需要指定数据类型。返回值是可选的。如果没有返回值的话返回值类型为 void。

6.2 函数的基本使用
上面我们了解过了函数是什么,那函数该怎么用呢?其实我们之前一直在用的 int main 就是一个函数。那我们如果想定义一个函数打印 hello 不是也可以使用这种形式,如下:
#include
using namespace std;
// void 为返回值类型,代表无返回值
void hello() {
cout << "Hello there!" << endl;
}
int main() {
// 函数调用直接写函数名加一个圆括号
// 如果要传参数在圆括号里传
hello();
return 0;
}
事实证明是可以的:

函数还可以返回一个值,使用 return 操作符(return 之后如果还有代码就不会被执行了,return 会强制终止函数):
#include
#include
using namespace std;
// 这里的 string 代表返回一个字符串
string hello() {
return "Hello there!";
}
int main() {
cout << hello() << endl;
return 0;
}
效果一样~
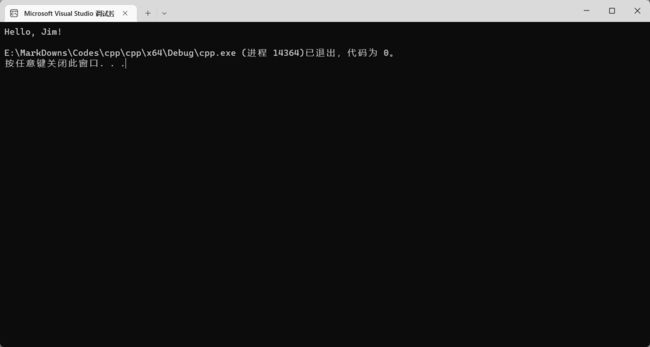
函数可以接收参数。参数直接在函数定义时在圆括号内声明。参数需要指明类型。调用时如果想传递参数直接在圆括号里边写。
#include
#include
using namespace std;
void hello(string name) {
// 这里的 + 号可以连接字符串
cout << "Hello, " + name + "!" << endl;
}
int main() {
hello("Jim");
return 0;
}
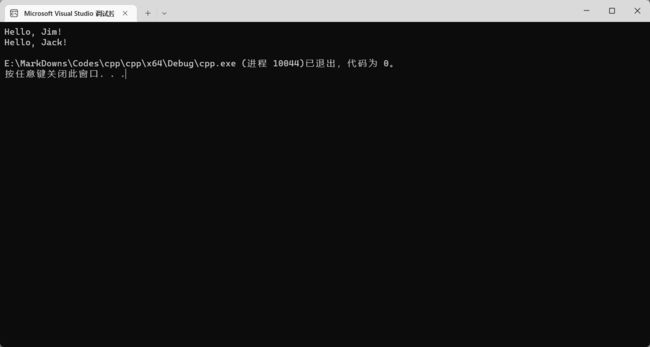
函数还可以接收很多参数,使用 , 号分隔:
#include
#include
using namespace std;
void hello(string name1, string name2) {
// 上面的 + 号连接还可以写成如下形式
cout << "Hello, " << name1 << "!" << endl;
cout << "Hello, " << name2 << "!" << endl;
}
int main() {
hello("Jim", "Jack");
return 0;
}
函数定义形参时可以定义一个默认值(如果有未定义默认值的形参,定义了默认值的形参必须写在未定义默认值形参的后面)。这样当用户不传某个参数时,函数便会使用形参的默认值作为实参。
#include
#include
using namespace std;
// 其中 Jack 为默认值
void hello(string name = "Jack") {
cout << "Hello, " << name << "!" << endl;
}
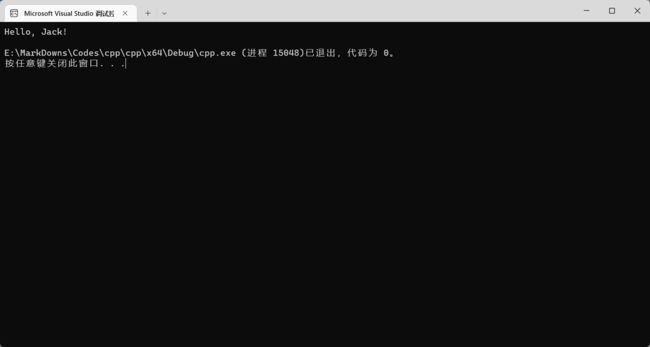
int main() {
hello();
return 0;
}
有了上面的了解,我们就可以写一些比较复杂的函数了。比如求数组中的最小值:
#include
using namespace std;
// 这里的 int arr[] 指 arr 接收一个类型为 int 的数组
// 数组参数的接收方式和普通类型有点不同
// length 指数组长度
int minOfArray(int arr[], int length) {
int smallest = arr[0];
for (int i = 0; i < length; i++) {
if (arr[i] < smallest) {
smallest = arr[i];
}
}
return smallest;
}
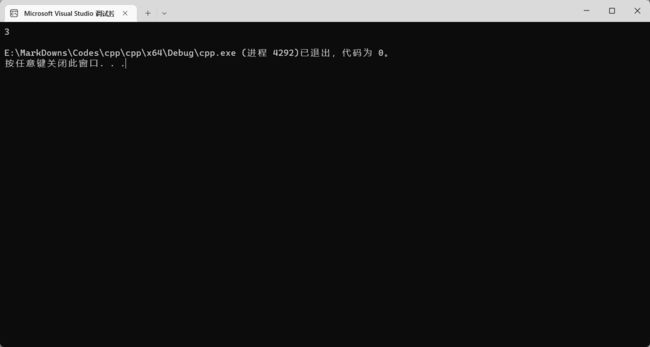
int main() {
int array[] = {8, 5, 3, 9};
cout << minOfArray(array, 4) << endl;
return 0;
}
6.3 函数传参
这小节我们要深入的了解一下函数传参的过程。这里我想引用一段我之前写的博客的内容:
传参,就是传递参数。讲指针传参之前,我们先要了解一下普通的传参方法的原理。函数传参,你可以把它理解为发信。调用函数,我们要把调用函数的要求和参数装进一个信封里,然后送进程序员给你预先准备好的邮局。邮局小哥会把你的参数 copy 一份,这是最关键的步骤,它防止了函数直接修改原变量。然后邮局小哥把复制品传入函数参数,函数开始运行。

(里面的指针传参先别管,第 8 章会细讲)
我们来验证一下这种说法对不对:
#include
using namespace std;
void swap(int a, int b) {
int temp = a;
a = b;
b = temp;
cout << a << " " << b << endl;
}
int main() {
int a = 3;
int b = 5;
swap(a, b);
cout << a << " " << b << endl;
return 0;
}
果然:

那如果我们真的要改变实参的值呢?这里先讲方法,就是使用引用传参。就是在形参前加上 & 号:
#include
using namespace std;
void swap(int &a, int &b) {
int temp = a;
a = b;
b = temp;
cout << a << " " << b << endl;
}
int main() {
int a = 3;
int b = 5;
swap(a, b);
cout << a << " " << b << endl;
return 0;
}
可以发现解决了问题:

关于引用传参这里简单说一下原理。引用,相当于一个别名。比如隔壁邻居的名字叫做王XX,我们为了方便,叫它老王。那老王就是王XX 的别名。引用传参,其实就是把实参的别名传进来,然后我们修改了实参的别名(形参),也就等于修改了实参。比如老王今天吃了 10 碗饭就等于王XX 今天吃了 10 碗饭。由于引用涉及到指针,所以这里不细讲,后面再说。
6.4 Lambda 函数
如果有学过 JavaScript 的同学一定对箭头函数十分熟悉。它可以让我们使用简便的语法创建一个函数,而且可以让这个函数赋值给一个变量,或者当作参数传递,非常灵活。C++ 中也有和箭头函数差不多意义的存在:Lambda 函数。Lambda 最大的特点就是灵活。没有返回值可以省略返回值,没有参数可以省略参数圆括号,甚至可以当作表达式来使用。那 Lambda 函数怎么定义呢?使用如下语法:
[闭包方式](参数列表) -> 返回值类型 {
函数代码……
}
其中如果不接收参数那参数列表那个圆括号可以省。如果没有返回值也不用指定 -> void 直接省去。闭包方式我们后面会讲,这里先留空。
那我们的函数不是可以写成如下形式(如果不接参数也不返回任何值)
[] { cout << "Hello" << endl; }
有点 JavaScript 那味儿了……
() => console.log("Hello!")
那这个函数如果要存进去一个变量,那用什么数据类型来接住呢?这就有一点复杂。我们需要引入一个库 functional,然后使用 function<返回值类型(参数 1 类型,参数 2 类型), …> 来接。如果返回值类型没有则为 void,如果没有参数就留空。当然还有一种更简便的方法:auto。它可以让 C++ 帮你推导变量类型。那么所有的 lambda 函数乃至其它变量都可以用 auto 来接住了(但是声明参数的时候就不能使用 auto 了,你以为 C++ 那么强大……)
#include
using namespace std;
int main() {
function hello = [] {
cout << "Hello!" << endl;
}; // 这个分号不能漏,这是和普通函数定义时的一个区别
// 还可以写成 auto hello = [] { cout << "Hello!" << endl; };
hello();
return 0;
}
和普通函数一样的:

然后我们来聊聊 Lambda 函数的闭包机制。通过闭包机制,你可以把该作用域内可以使用的变量让 Lambda 函数也可以使用。举个例子,比如一个作用域内定义了 int a = 3; ,然后你如果使用闭包,就可以让 Lambda 函数也可以用到这个 a 变量。当然闭包不止只有一种方式,下面列出了闭包的多种方式:
// 不使用闭包:[]
// 把作用域内所有变量(以下简称“所有变量”)都以按值传递方式闭包(即所有值都拷贝一份再闭包):[=]
// 把所有变量都以引用方式闭包:[&]
// 把 a, b 变量以按值传递方式闭包:[a, b]
// 把 a, b 变量以引用方式闭包:[&a, &b]
// 把所有变量都以按值传递方式闭包,但是 a 例外,使用引用方式闭包:[=, &a]
// 把所有变量都以引用方式闭包,但是 a 例外,使用按值传递方式闭包:[&, a]
// 闭包时新建变量:[a = b + 3],但是不多见
Lambda 函数如果使用了按值传递方式的闭包,那么里面的变量均不可更改(虽然里面的变量即使更改了也不会影响到实际的变量)如果需要更改,请加上 mutable 属性。mutable 放置的位置是参数列表(若 mutable 存在,参数列表不能没有,如果不接参数也要写一个圆括号)之后,返回值声明 ->(可以为空)之前。
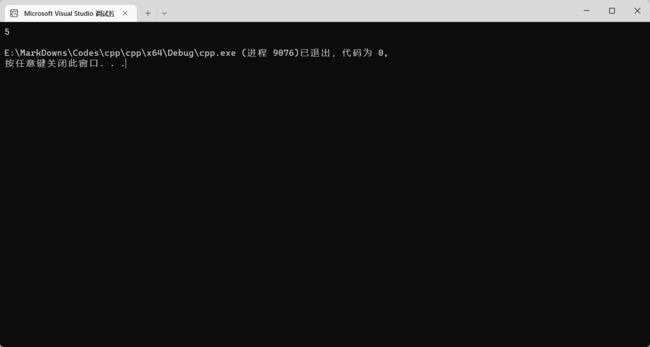
#include
using namespace std;
int main() {
int x = 3;
auto add2 = [x]() mutable -> int {
x += 2;
return x;
};
x = add2();
cout << x << endl;
return 0;
}
效果:
本篇小结
这篇的内容还是挺多的。它涉及到了大部分我们需要学习的基础语法。首先我们花了两个单元学习了 C++ 最基础的语法:变量,数据类型和操作符。然后我们学习了一些常用的程序结构:分支结构与循环结构。然后我们认识了数组和函数,然后 OK~
这是年前最后一更了,后面的两篇年后会更新。学完这些内容,表格上说可以 CSP-J 一等奖了,也不知道是不是真的~