sentence transformer微调(simcse模型为例)
简要介绍
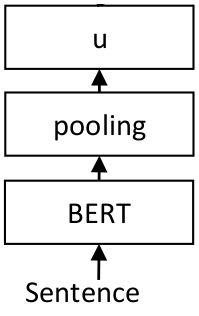
sentence transformer是一个使用pytorch对常见语言模型进行封装,得到一个句子级别的embedder的python包。主要由基于transformer的预训练模型(生成句子中各个字的embedding)+pooing层(对句子中各个字的embedding选择一种方式生成句子的embedding)组成,如下图:
如何在自己的数据上finetune?
闲话:相比于单纯针对预训练模型的transformer包,sentence transformer的封装程度更高一些,但二者都是可以在huggingface上寻找别人训练好的预训练参数进行初始化。
主要就几步:
- 读自己数据
def read_data(filepath):
texts_1=[]
with open(filepath,'r') as f:
lines=f.readlines()
for line in lines:
items=line.replace('\n','').split('\t')
texts_1.append(items[0])
return texts_1
train_texts_1=read_data('./data/train.txt')
print("训练集:",len(train_texts_1))
- 使用dataset、dataloader封装数据
train_data = []
for idx in range(len(train_texts_1)):
train_data.append(InputExample(texts=[train_texts_1[idx], train_texts_1[idx]]))
# 定义微调的dataset、dataloader、loss
from sentence_transformers import SentenceTransformer, SentencesDataset, InputExample, evaluation, losses, models
from torch.utils.data import DataLoader
train_dataset = SentencesDataset(train_data, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=32)
- 生成模型并初始化
# 加载预训练模型
# 方式1
model = SentenceTransformer("cyclone/simcse-chinese-roberta-wwm-ext")
# 方式2
model_name = 'cyclone/simcse-chinese-roberta-wwm-ext'
word_embedding_model = models.Transformer(model_name, max_seq_length=64)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
# 查看一下模型架构是否一样,而这并没有什么区别,都是按照上面的模型图:bert+pooling组成
print(model)
- 选择损失函数,simcse这样的句子模型往往可以有监督或者无监督训练,使用sentence_transformer作为模型容器的话,这里选择的loss类型就决定了模型的监督方式
# 有监督fintune时应该选择的loss类型,需要标签
train_loss = losses.CosineSimilarityLoss(model)
# 定义测试器,有监督时
evaluator = evaluation.EmbeddingSimilarityEvaluator(test_texts_1,test_texts_2,test_labels)
# 无监督fintune的loss类型,不需要标签
train_loss = losses.MultipleNegativesRankingLoss(model)
- 训练、保存
# 微调训练
model.fit(train_objectives=[(train_dataloader, train_loss)],show_progress_bar=True, epochs=3, warmup_steps=500, output_path='./SaveModel')
如何使用finetune之后的模型
记住上面保存模型的路径,output_path=’./SaveModel’,使用时直接按照该路径加载模型参数即可
from sentence_transformers import SentenceTransformer, util
#微调后的模型
model = SentenceTransformer('./SaveModel')
# model = SentenceTransformer('cyclone/simcse-chinese-roberta-wwm-ext')
emb1 = model.encode("预备党员")
emb2 = model.encode("正式党员")
emb3 = model.encode("交纳党费")
cos_sim = util.pytorch_cos_sim(emb1, emb2)
cos_sim1 = util.pytorch_cos_sim(emb3, emb2)
print("Cosine-Similarity:", cos_sim,cos_sim1)
注意事项
model = SentenceTransformer(’./SaveModel’)加载后的模型对象有很多借口函数,建议需要的话去官网查看接口,这里仅仅用到了最基础的一些训练接口。
送你去官网
预训练模型及参数:
https://huggingface.co/
sentence transformer官网
https://www.sbert.net/index.html