mysql索引优化、mysql索引失效、索引命中规则、索引设计原则
目录
初体验
索引使用
使用规范
今天说的是索引优化,通常使用索引是为了提高查询效率,也是就响应时间,但响应时间跟是不是使用了索引也没有必然关系,准确点说,今天说的是怎么写sql能使用到索引,即命中索引,具体到表象中,是 explain 一个语句的时候,数据结果里面 key 的值不是 NULL。用到索引就行了吗,还要用的合适,也就是需要遵守一定的使用规范,所以在这之前,建议先看下前一篇关于执行计划的详细介绍:MySQL 执行计划explain各参数说明。各位看到此博客的小伙伴,如有不对的地方请及时通过私信我或者评论此博客的方式指出,以免误人子弟。多谢!
初体验
看下一个简单的查询,索引是不是提高了我们的查询效率:
select * from t_student where qq_account = '1873561761';
再看下添加索引之后:
alter table t_student add index idx_qq(qq_account) ;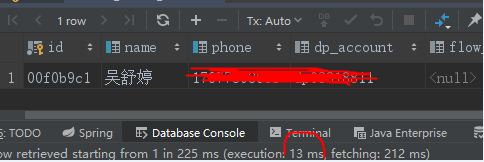
如上:没建立索引之前查询生成结果的时间为409毫秒,把结果从database返回客户端的时间为201毫秒,总时间为610毫秒;加上索引后生成结果的时间为13毫秒,把结果从database返回客户端的时间为212毫秒,总时间为225毫秒。可以看出,总时间提高了三倍,而通过sql获取符合条件的数据差别更大,一个409毫秒,一个13毫秒,加不加索引的查询效率一目了然。另外上面也提到,响应时间跟是不是使用了索引也没有必然关系,从上面两个查看也可以看出,将结果返回给客户端的时间还是占一大部分的,这与网络也是有很大关系的;假如一个表就千八百条数据,用不用索引也是没什么区别的;
索引使用
怎么写sql会命中索引,什么情况下索引会失效呢,下面通过例子验证试验下,t_user表id为主键,mobile字段有索引:
1.模糊查询 以%开头,索引无效;当like前缀没有%,后缀有%时,索引有效
explain select * from t_user where mobile like '18888%'; ![]()
explain select * from t_user where mobile like '%18888';![]()
2.为查询中与其他表关联的字段创建索引
explain select * from t_student t left join t_student_archive t1 on t.id = t1.student_id;t_student_archive表的student_id无索引时

添加索引后
alter table t_student_archive add index idx_studentid(student_id);![]()
3.or语句前后没有同时使用索引。
当or左右查询字段只有一个是索引,该索引失效,只有当or左右查询字段均为索引时,才会生效。
explain select * from t_user where id = 'jvemv4yggm' or mobile = '18888888888';![]()
explain select * from t_user where id = 'jvemv4yggm' or employee_no = 'E15944';![]()
4.在索引字段上使用not、<>、!=。不等于操作符用不到索引,特别的当条件是主键的话是可以的
explain select * from t_user where mobile != '18888888888'![]()
当条件为主键时:
explain select * from t_user where id != 'jvemv4yggm'![]()
5.数据类型出现隐式转换
如果列是字符串类型,传入条件必须用引号引起来。如下:虽然可以查出来,但是不会使用索引。
select * from t_user where mobile = 18888888888![]()
![]()
6.要符合最左匹配原则
如果列不构成索引最左面的前缀,MySQL不能使用局部索引。如在col1,col2,col3建立一个联合索引idx_col1_col2_col3(col1,col2,col3),则(col1)、(col1,col2)和(col1,col2,col3)上的查询可以使用到索引,但(col2)、(col3)、(col2,col3)都使用不了索引,最左前缀针对的是联合索引。
能用到索引的情况如下:
create index idx_name_phone_qq on t_student(name,phone,qq_account);
explain select * from t_student where name = '大大卷' and phone = '15288883452' and qq_account = '88888524';![]()
explain select * from t_student where name = '大大卷' and phone = '15288883452'![]()
explain select * from t_student where name = '大大卷'![]()
不能用到索引的情况如下:
explain select * from t_student where phone = '15288883452' and qq_account = '88888524';![]()
explain select * from t_student where phone = '15288883452' ![]()
explain select * from t_student where qq_account = '88888524';![]()
那 (col1,col3)这种能不能用上呢?
explain select * from t_student where name = '大大卷' and qq_account = '88888524';![]()
7.尽量使用覆盖索引
如果查询列可通过索引节点中的关键字直接返回,则该索引称之为覆盖索引。即查询的列全部在索引中。
explain select * from t_student![]()
explain select name,phone,qq_account,wx_account from t_student; 
explain select name,phone,qq_account from t_student![]()
explain select phone,qq_account from t_student;
如果查询列可通过索引节点中的关键字直接返回,则该索引称之为覆盖索引。从上面执行计划可以得出结论:1.使用覆盖索引可以避免回表,如第二条在查询wx_account时,从索引上找不到需要去基表中获取;2.从联合索引上取数据不必遵循最左匹配原则,如上面最后一条查询phone,qq_account,并没有以name开头,也可以使用到索引。另外使用覆盖索引还可以避免出现Using filesort。
8.为需要排序、分组的字段创建索引
先看一下我的测试结果:
explain select name,phone,qq_account from t_student order by name,phone,qq_account;
explain select name,phone,qq_account from t_student order by name,phone;
explain select name,phone,qq_account from t_student order by name;以上语句都可以使用到索引,并且没有出现Using filesort。

再看下面一组的测试结果:
explain select name,phone,qq_account from t_student order by phone,qq_account;
explain select name,phone,qq_account from t_student order by qq_account;
explain select name,phone,qq_account from t_student order by phone;
explain select name,phone,qq_account from t_student order by name,qq_account;以上语句虽然都可以使用到索引,但是都出现了Using filesort。

由以上两组测试,可以看出order by后的条件也要符合最左前缀法则,否则会出现Using filesort。
那在排序前使用where过滤后,会是什么样呢?看下我的测试结果:
explain select name,phone,qq_account from t_student where name = '大大卷' order by name,phone,qq_account;
explain select name,phone,qq_account from t_student where name = '大大卷' order by phone,qq_account;
explain select name,phone,qq_account from t_student where phone = '1888888888' order by name, qq_account;
explain select name,phone,qq_account from t_student where name = '大大卷' and phone = '1888888888' order by qq_account;以上语句都可以使用到索引,并且没有出现Using filesort。

再看下面一组的测试结果:
explain select name,phone,qq_account from t_student where name = '大大卷' order by qq_account;
explain select name,phone,qq_account from t_student where name = '大大卷' order by name,qq_account;
explain select name,phone,qq_account from t_student where phone = '1888888888' order by qq_account;
explain select name,phone,qq_account from t_student where name > '大大卷' order by phone,qq_account;以上语句虽然都可以使用到索引,但是都出现了Using filesort。

由以上两组测试,可以看出order by和where组合使用时,只有在避免索引失效的前提下,并且where条件和order by使用的字段联合起来要组成最左匹配的形式,或者查询字段为常数时,才能避免出现Using filesort。 如:where name = '大大卷' order by qq_account;符合最左前缀法则的形式; where phone = '18682302191' order by name, qq_account;联合索引的中间字段为常数; where name > '大大卷' order by phone,qq_account;虽然符合最左前缀的形式,但是>号使后面索引失效。简单点说order by在满足以下两种情况下会使用index方式不会出现filesort排序:1.order by语句符合最左匹配;2.使用where子句与order by子句条件组合起来满足最左匹配。
上面这些仅仅是基于联合索引的情况下适用,如果将联合索引分解为三个单独的索引,所有的查询将都会出现Using filesort。至于group by和where、order by的结合,那组合出的sql写法太多了,只要记住分组字段要加索引即可。
使用规范
除了上面这些示例中提到的可能会导致索引失效的情况需要避免外,建立索引的时候也需要遵循一定的规范,如索引不能建立太多,为什么呢?通过前面几篇的介绍,也很好解释,索引是存放在文件中的,首先建立过多索引会占用一定的空间,当然这还不算什么,但是每次进行表数据更新的时候,还要同时去维护索引,重建索引树,这对表的insert、update、delete的性能会有一定影响。总结一下一般需要遵循的规范如下:
1. 为经常用作查询条件的字段创建索引。
2. 为需要排序、分组的字段创建索引。
3. 避免使用select *。
4. 使用短索引。
5. 组合索引代替单列索引。
6. 不要过度索引。
7. 基数较小的类,索引效果较差,没有必要在此列建立索引。
8. 表的记录少不需要创建索引。
9. 经常增删改的表不需要创建索引。
10、不要对索引字段进行计算操作和字段上使用函数。 11、利用最左索引。