Paddle进阶实战系列(二):智慧交通预测系统
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,通俗易懂,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。
项目总结
随着深度学习在近几年的快速发展,智慧交通出现许多不同方面应用,如车牌识别、交通标志检测与识别及综合应用的行人分析系统等。 本项目分为三部分,分别是交通流量预测、车牌识别、车辆检测等,采用热门百度开源框架--PaddlePaddle,其模型方便易上手且生态完善,目前在人工智能各领域取得不错效果,通过PaddleOCR和Yolo框架可分别实现车牌识别与车辆检测任务。
项目链接:见文末!
PaddleOCR介绍
该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身(如绿框所示),最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。主流识别OCR项目主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。
项目内容:
项目共分为三部分:交通流量预测、车牌识别、车辆检测。后续会更新Paddle智慧交通更多模型实战,如PaddleDetection行人分析工具PP-Human、PP-Vehicle的多种使用方式等。
(1) 基于LSTM的交通流量预测
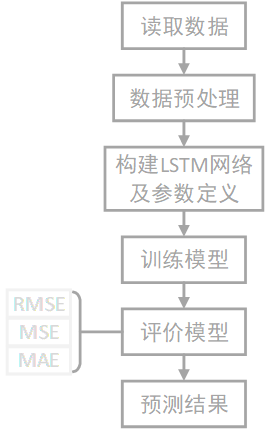
目前在交通领域,深度学习相关模型被广泛应用于道路、航空、铁路等各方面研究,如短期交通流预测、公交车到站时间预测、铁路客运量预测等。因此,本题以交通领域车流量问题为例,构建基于LSTM时间序列预测模型,流程大致分为数据预处理、构建网络及参数、模型训练、评估与预测,以RMSE、MAE等回归预测评价 。
(2) 基于PaddleOCR的车牌识别
项目介绍
车牌识别技术是智能交通的重要环节,目前已广泛应用于例如停车场、收费站等等交通设施中,提供高效便捷的车辆认证的服务,其中较为典型的应用场景为卡口系统。车牌识别即识别车牌上的文字信息,属于光学字符识别(OCR)的一项子任务。

项目流程
- 本项目基于Paddleocr完成深度学习车牌识别,项目可分为车牌检测与车牌识别两部分,主要流程为数据预处理、模型训练、导出推理模型、测试,算法主要由检测算法DBnet、检测框矫正和CRNN文本识别三部分组成,最终识别精度可达到90%,右图为车牌检测+识别流程后识别效果。。
- 检测车牌所在图片位置
- 识别车牌图片具体内容

(3) 基于Yolov5的车辆检测
项目介绍
- 车辆检测技术大量应用于高速公路的监控设备中,可以进行车辆监控、车流量统计。本次主要参考Paddle框架,使用YOLOV5检测网络对车辆进行检测,并且在残差单元中嵌入卷积注意力模块,强化学习细节特征,抑制冗余信息干扰。然后,将卷积注意力融入金字塔网络中用以区分不同重要信息,加强关键特征融合。在车辆VOC车辆数据集上进行实验,mAP达到0.79,左图为车辆检测效果。

一、 基于LSTM的交通流量预测
- 针对交通流量预测模块 ,传统回归模型虽然可以实现,但存在预测精度不高问题 ,而采用机器学习算法可以实现交通流量预测,其推理速度及准确率有很大提升,如决策树、随机森林回归等。目前在交通领域,深度学习相关模型被广泛应用于道路、航空、铁路等各方面研究,如短期交通流预测、公交车到站时间预测、铁路客运量预测等。因此,本题以交通领域车流量问题为例,构建基于LSTM时间序列预测模型,其具体算法流程如下图所示。
- 长短时记忆网络( LSTM )是深度学习中循环神经网络RNN的特殊变体,具有“门”结构,通过门单元逻辑控制 决定数据是否更新或是丢弃,克服RNN易产生梯度消失和爆炸缺点,使其能够有效利用长距离的时序信息,提高预测精度。其内部模型构建流程如图所示。

交通数据集介绍
针对交通流量预测模块,数据集主要使用某街道2018年的交通数据,数据集字段有时间信息、交通流量、车速、道路编号等信息,本次选取同日期不同时间和同时间不同日期的车流量数据进行简要数据分析,项目文件夹目录为traffic_predict,下图为数据可视化结果。
!cat traffic_predict/traffic.csv | head -n 10Local Date,Local Time,Day Type ID,Total_Carriageway_Flow,Total Flow vehicles less than 5.2m,Total Flow vehicles 5.21m - 6.6m,Total Flow vehicles 6.61m - 11.6m,Total Flow vehicles above 11.6m,Speed Value,Quality Index,NTIS Model Version 2018/8/1,0:14:00,9,246,179,20,17,30,101.87,15,8 2018/8/1,0:29:00,9,246,181,20,13,32,81.37,15,8 2018/8/1,0:44:00,9,247,179,23,14,31,73.24,15,8 2018/8/1,0:59:00,9,193,132,17,15,29,77.25,15,8 2018/8/1,1:14:00,9,189,117,12,21,39,72.71,15,8 2018/8/1,1:29:00,9,152,96,21,10,25,75.28,15,8 2018/8/1,1:44:00,9,157,100,4,14,39,80.23,15,8 2018/8/1,1:59:00,9,166,112,18,17,19,106.44,15,8 2018/8/1,2:14:00,9,141,82,10,17,32,102.28,15,8 cat: write error: Broken pipe
同一日期不同时间段车流量变化情况图:

不同日期同一时间段车流量变化情况图:

不同情况车流量对比图:

LSTM交通流量预测实战:
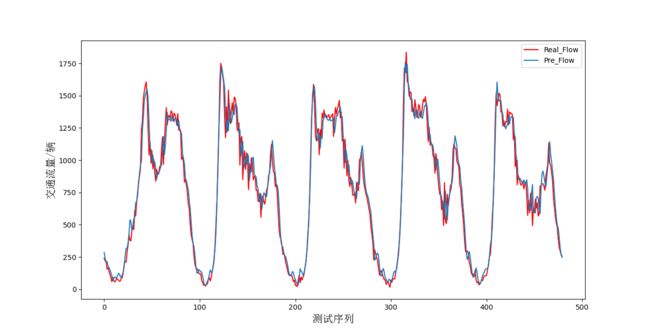
针对交通流量预测, 采用深度学习LSTM模型对交通流量进行预测 ,将一个月前三周时间作为训练集,最后一周做测试集,参数设置方面,采用两层LSTM,单元数128,优化器Adam,损失函数为MSE等相关参数,经过多次实验优化,最终预测拟合及模型损失随轮数变化情况如下图所示。
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as Data
from torchsummary import summary
import math
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import time
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
from matplotlib.font_manager import FontProperties # 画图时可以使用中文
# 加载数据
f = pd.read_csv('./traffic.csv')
# 从新设置列标
# def set_columns():
# columns = []
# for i in f.loc[2]:
# # columns.append(i.strip())
# columns.append(i)
# print(columns)
# return columns
#
#
# f.columns = set_columns()
# f.drop([0, 1, 2], inplace=True)
# 读取数据
data = f['Total_Carriageway_Flow'].astype(np.float64).values[:, np.newaxis]
class LoadData(Dataset):
def __init__(self, data, time_step, divide_days, train_mode):
self.train_mode = train_mode
self.time_step = time_step
self.train_days = divide_days[0]
self.test_days = divide_days[1]
self.one_day_length = int(24 * 4)
# flow_norm (max_data. min_data)
self.flow_norm, self.flow_data = LoadData.pre_process_data(data)
# 不进行标准化
# self.flow_data = data
def __len__(self, ):
if self.train_mode == "train":
return self.train_days * self.one_day_length - self.time_step
elif self.train_mode == "test":
return self.test_days * self.one_day_length
else:
raise ValueError(" train mode error")
def __getitem__(self, index):
if self.train_mode == "train":
index = index
elif self.train_mode == "test":
index += self.train_days * self.one_day_length
else:
raise ValueError(' train mode error')
data_x, data_y = LoadData.slice_data(self.flow_data, self.time_step, index,
self.train_mode)
data_x = LoadData.to_tensor(data_x)
data_y = LoadData.to_tensor(data_y)
return {"flow_x": data_x, "flow_y": data_y}
# 这一步就是划分数据
@staticmethod
def slice_data(data, time_step, index, train_mode):
if train_mode == "train":
start_index = index
end_index = index + time_step
elif train_mode == "test":
start_index = index - time_step
end_index = index
else:
raise ValueError("train mode error")
data_x = data[start_index: end_index, :]
data_y = data[end_index]
return data_x, data_y
# 数据与处理
@staticmethod
def pre_process_data(data, ):
norm_base = LoadData.normalized_base(data)
normalized_data = LoadData.normalized_data(data, norm_base[0], norm_base[1])
return norm_base, normalized_data
# 生成原始数据中最大值与最小值
@staticmethod
def normalized_base(data):
max_data = np.max(data, keepdims=True) # keepdims保持维度不变
min_data = np.min(data, keepdims=True)
# max_data.shape --->(1, 1)
return max_data, min_data
# 对数据进行标准化
@staticmethod
def normalized_data(data, max_data, min_data):
data_base = max_data - min_data
normalized_data = (data - min_data) / data_base
return normalized_data
@staticmethod
# 反标准化 在评价指标误差以及画图的使用使用
def recoverd_data(data, max_data, min_data):
data_base = max_data - min_data
recoverd_data = data * data_base - min_data
return recoverd_data
@staticmethod
def to_tensor(data):
return torch.tensor(data, dtype=torch.float)
# 划分数据
divide_days = [25, 5]
time_step = 5
batch_size = 48
train_data = LoadData(data, time_step, divide_days, "train")
test_data = LoadData(data, time_step, divide_days, "test")
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, )
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, )
# LSTM构建网络
class LSTM(nn.Module):
def __init__(self, input_num, hid_num, layers_num, out_num, batch_first=True):
super().__init__()
self.l1 = nn.LSTM(
input_size=input_num,
hidden_size=hid_num,
num_layers=layers_num,
batch_first=batch_first
)
self.out = nn.Linear(hid_num, out_num)
def forward(self, data):
flow_x = data['flow_x'] # B * T * D
l_out, (h_n, c_n) = self.l1(flow_x, None) # None表示第一次 hidden_state是0
# print(l_out[:, -1, :].shape)
out = self.out(l_out[:, -1, :])
return out
# 定义模型参数
input_num = 1 # 输入的特征维度
hid_num = 128 # 隐藏层个数
layers_num = 2 # LSTM层个数
out_num = 1
lstm = LSTM(input_num, hid_num, layers_num, out_num)
loss_func = nn.MSELoss()
# loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(lstm.parameters())
# 训练模型
lstm.train()
epoch_loss_change = []
for epoch in range(50):
epoch_loss = 0.0
start_time = time.time()
for data_ in train_loader:
lstm.zero_grad()
predict = lstm(data_)
loss = loss_func(predict, data_['flow_y'])
epoch_loss += loss.item()
loss.backward()
optimizer.step()
epoch_loss_change.append(1000 * epoch_loss / len(train_data))
end_time = time.time()
print("Epoch: {:04d}, Loss: {:02.4f}, Time: {:02.2f} mins".format(epoch, 1000 * epoch_loss / len(train_data),
(end_time - start_time) / 60))
# font_set = FontProperties(fname=r"C:\Windows\Fonts\simsun.ttc", size=15) # 中文字体使用宋体,15号
# plt.xlabel('epoch', fontproperties=font_set)
# plt.ylabel('loss', fontproperties=font_set)
plt.plot(epoch_loss_change)
# 评价模型
lstm.eval()
with torch.no_grad(): # 关闭梯度
total_loss = 0.0
pre_flow = np.zeros([batch_size, 1]) # [B, D],T=1 # 目标数据的维度,用0填充
real_flow = np.zeros_like(pre_flow)
for data_ in test_loader:
pre_value = lstm(data_)
loss = loss_func(pre_value, data_['flow_y'])
total_loss += loss.item()
# 反归一化
pre_value = LoadData.recoverd_data(pre_value.detach().numpy(),
test_data.flow_norm[0].squeeze(1), # max_data
test_data.flow_norm[1].squeeze(1), # min_data
)
target_value = LoadData.recoverd_data(data_['flow_y'].detach().numpy(),
test_data.flow_norm[0].squeeze(1),
test_data.flow_norm[1].squeeze(1),
)
pre_flow = np.concatenate([pre_flow, pre_value])
real_flow = np.concatenate([real_flow, target_value])
pre_flow = pre_flow[batch_size:]
real_flow = real_flow[batch_size:]
# # 计算误差
mse = mean_squared_error(pre_flow, real_flow)
rmse = math.sqrt(mean_squared_error(pre_flow, real_flow))
mae = mean_absolute_error(pre_flow, real_flow)
print('均方误差---', mse)
print('均方根误差---', rmse)
print('平均绝对误差--', mae)
# 画出预测结果图
font_set = FontProperties(fname=r"C:\Windows\Fonts\simsun.ttc", size=15) # 中文字体使用宋体,15号
plt.figure(figsize=(15, 10))
plt.plot(real_flow, label='真实交通流量', color='r', )
plt.plot(pre_flow, label='预测交通流量')
plt.xlabel('测试序列', fontproperties=font_set)
plt.ylabel('交通流量/辆', fontproperties=font_set)
plt.legend()
plt.show()
# 预测储存图片
plt.savefig('./result.jpg')
交通流程预测结果
损失变化情况

交通流量预测项目小结:
本模块构建交通流通流量预测。使用车流量相关数据,运用机器学习算法与深度学习算法按照不同时间对道路车流量进行流量预测。从侧解决交通拥堵问题,提示人们订制合理的出行计划,同时有利于交通部门规划交通政策。
后续优化方向:
1.数据方面:由于初赛数据有限,后续申请更多关于上海交通流量数据,引入其他特征和数据,提升模型准确度及更多方向应用。
2.模型方面:本模块后续可扩展到机器学习或其他深度学习模型,如Xgboost、Transformer等,也可以适当进行模型融合。
二、 基于PaddleOCR的车牌识别
数据集介绍
本项目数据集采用CCPD2019和CCPD02020车牌数据集,以CCPD02020演示车牌识别流程,其训练、验证、测试数据集已划分完毕,测试集包含5006张图片,大小共865.66M。本项目演示的CCPD20数据集的采集方式与CCPD19类似,其中均为新能源车辆的车牌,其命名为ccpd_green路径。
-
CCPD2020/ccpd_green/
-train
-val
-test

文件名即图片标注,具体含义可查看源网址,以下为数据集解读参考。
“025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg”.
数据集字段解释参考:
- CCPD数据集没有专门的标注文件,每张图像的文件名就是对应的数据标注(label)
- 例如:025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg 由分隔符'-'分为几个部分:
- 025为区域
- 95_113 对应两个角度, 水平95°, 竖直113°
- 154&383_386&473对应边界框坐标:左上(154, 383), 右下(386, 473)
- 386&473_177&454_154&383_363&402对应四个角点坐标
- 0_0_22_27_27_33_16为车牌号码 映射关系如下: 第一个为省份0 对应省份字典皖, 后面的为字母和文字, 查看ads字典.如0为A, 22为Y....
安装PaddleOCR环境
#下载PaddleOCR
%cd ~/
!git clone -b release/2.1 https://github.com/PaddlePaddle/PaddleOCR.git#安装环境
%cd PaddleOCR
!pip install -r requirments.txt
!pip install --upgrade scipy
# !pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple[Errno 2] No such file or directory: 'PaddleOCR'
/home/aistudio/PaddleOCR
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: shapely in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirments.txt (line 1)) (1.8.5.post1)
Collecting imgaug
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/66/b1/af3142c4a85cba6da9f4ebb5ff4e21e2616309552caca5e8acefe9840622/imgaug-0.4.0-py2.py3-none-any.whl (948 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 948.0/948.0 kB 123.2 kB/s eta 0:00:0000:0100:01
Collecting pyclipper
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/21/b9/f8bd7bb8b04906ac2f93518ae22040c99db9dfc9faf2a29d444c6469b6a3/pyclipper-1.3.0.post4-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.whl (604 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 604.2/604.2 kB 646.7 kB/s eta 0:00:0000:0100:01
Collecting lmdb
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/4d/cf/3230b1c9b0bec406abb85a9332ba5805bdd03a1d24025c6bbcfb8ed71539/lmdb-1.3.0-cp37-cp37m-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (298 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 298.8/298.8 kB 592.3 kB/s eta 0:00:0000:0100:01
Requirement already satisfied: matplotlib in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from imgaug->-r requirments.txt (line 2)) (2.2.3)
Requirement already satisfied: Pillow in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from imgaug->-r requirments.txt (line 2)) (7.1.2)
Requirement already satisfied: numpy>=1.15 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from imgaug->-r requirments.txt (line 2)) (1.21.6)
Requirement already satisfied: imageio in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from imgaug->-r requirments.txt (line 2)) (2.6.1)
Collecting scikit-image>=0.14.2
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/2d/ba/63ce953b7d593bd493e80be158f2d9f82936582380aee0998315510633aa/scikit_image-0.19.3-cp37-cp37m-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (13.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 13.5/13.5 MB 256.3 kB/s eta 0:00:0000:0100:02
Requirement already satisfied: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from imgaug->-r requirments.txt (line 2)) (1.16.0)
Requirement already satisfied: scipy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from imgaug->-r requirments.txt (line 2)) (1.3.0)
Requirement already satisfied: opencv-python in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from imgaug->-r requirments.txt (line 2)) (4.6.0.66)
Collecting tifffile>=2019.7.26
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/d8/38/85ae5ed77598ca90558c17a2f79ddaba33173b31cf8d8f545d34d9134f0d/tifffile-2021.11.2-py3-none-any.whl (178 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 178.9/178.9 kB 186.9 kB/s eta 0:00:0000:0100:01
Requirement already satisfied: packaging>=20.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-image>=0.14.2->imgaug->-r requirments.txt (line 2)) (21.3)
Collecting scipy
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/58/4f/11f34cfc57ead25752a7992b069c36f5d18421958ebd6466ecd849aeaf86/scipy-1.7.3-cp37-cp37m-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (38.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 38.1/38.1 MB 299.9 kB/s eta 0:00:0000:0100:04
Requirement already satisfied: networkx>=2.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-image>=0.14.2->imgaug->-r requirments.txt (line 2)) (2.4)
Collecting PyWavelets>=1.1.1
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ae/56/4441877073d8a5266dbf7b04c7f3dc66f1149c8efb9323e0ef987a9bb1ce/PyWavelets-1.3.0-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl (6.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.4/6.4 MB 1.1 MB/s eta 0:00:0000:0100:010m
Requirement already satisfied: cycler>=0.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->imgaug->-r requirments.txt (line 2)) (0.10.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->imgaug->-r requirments.txt (line 2)) (1.1.0)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->imgaug->-r requirments.txt (line 2)) (3.0.9)
Requirement already satisfied: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->imgaug->-r requirments.txt (line 2)) (2019.3)
Requirement already satisfied: python-dateutil>=2.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->imgaug->-r requirments.txt (line 2)) (2.8.2)
Requirement already satisfied: setuptools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from kiwisolver>=1.0.1->matplotlib->imgaug->-r requirments.txt (line 2)) (41.4.0)
Requirement already satisfied: decorator>=4.3.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from networkx>=2.2->scikit-image>=0.14.2->imgaug->-r requirments.txt (line 2)) (4.4.0)
Installing collected packages: pyclipper, lmdb, tifffile, scipy, PyWavelets, scikit-image, imgaug
Attempting uninstall: scipy
Found existing installation: scipy 1.3.0
Uninstalling scipy-1.3.0:
Successfully uninstalled scipy-1.3.0
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
parl 1.4.1 requires pyzmq==18.1.1, but you have pyzmq 23.2.1 which is incompatible.
paddlepaddle-gpu 1.8.0.post97 requires scipy<=1.3.1; python_version >= "3.5", but you have scipy 1.7.3 which is incompatible.
Successfully installed PyWavelets-1.3.0 imgaug-0.4.0 lmdb-1.3.0 pyclipper-1.3.0.post4 scikit-image-0.19.3 scipy-1.7.3 tifffile-2021.11.2
[notice] A new release of pip available: 22.1.2 -> 22.3.1
[notice] To update, run: pip install --upgrade pip
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: scipy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (1.7.3)
Requirement already satisfied: numpy<1.23.0,>=1.16.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scipy) (1.21.6)
[notice] A new release of pip available: 22.1.2 -> 22.3.1
[notice] To update, run: pip install --upgrade pip
数据预处理
字典内容:
车牌省份: provinces = [“皖”, “沪”, “津”, “渝”, “冀”, “晋”, “蒙”, “辽”, “吉”, “黑”, “苏”, “浙”, “京”, “闽”, “赣”, “鲁”, “豫”, “鄂”, “湘”, “粤”, “桂”, “琼”, “川”, “贵”, “云”, “藏”, “陕”, “甘”, “青”, “宁”, “新”, “警”, “学”, “O”]
alphabets = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’, ‘Y’, ‘Z’, ‘O’]
ads = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’, ‘Y’, ‘Z’, ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘O’]
In [ ]
!unzip -q data/data168819/CCPD2020.zip -d work/CCPD2020检测数据:转换成官方提供的icdar格式
格式如下:
transcription为具体内容,points存放检测车牌坐标
03706896551724138-90_263-185&516_545&610-543&607_194&610_185&518_545&516-0_0_3_29_27_33_24_33-59-41.jpg [{"transcription": "皖AD53909", "points": [[185, 518], [545, 516], [543, 607], [194, 610]]}] /034782088122605366-92_244-167&522_517&612-517&612_195&590_167&522_497&539-0_0_3_24_30_30_33_25-102-110.jpg [{"transcription": "皖AD06691", "points": [[167, 522], [497, 539], [517, 612], [195, 590]]}]
In [ ]
#转换检测数据,打开注释执行三次生成训练所需txt文件,分别为train、val、test。
%cd ~
import os, cv2
words_list = [
"A", "B", "C", "D", "E",
"F", "G", "H", "J", "K",
"L", "M", "N", "P", "Q",
"R", "S", "T", "U", "V",
"W", "X", "Y", "Z", "0",
"1", "2", "3", "4", "5",
"6", "7", "8", "9" ]
con_list = [
"皖", "沪", "津", "渝", "冀",
"晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "京", "闽", "赣",
"鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云",
"西", "陕", "甘", "青", "宁",
"新"]
count = 0
# data = open('work/train_data_det.txt', 'w', encoding='UTF-8')
# data = open('work/val_data_det.txt', 'w', encoding='UTF-8')
data = open('work/test_data_det.txt', 'w', encoding='UTF-8')
# for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/train'):
# for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/val'):
for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/test'):
# path = 'work/CCPD2020/CCPD2020/ccpd_green/train/'+item
# path = 'work/CCPD2020/CCPD2020/ccpd_green/val/'+item
path = 'work/CCPD2020/CCPD2020/ccpd_green/test/'+item
_, _, bbox, points, label, _, _ = item.split('-')
points = points.split('_')
points = [_.split('&') for _ in points]
tmp = points[-2:]+points[:2]
points = []
for point in tmp:
points.append([int(_) for _ in point])
label = label.split('_')
con = con_list[int(label[0])]
words = [words_list[int(_)] for _ in label[1:]]
label = con+''.join(words)
line = path+'\t'+'[{"transcription": "%s", "points": %s}]' % (label, str(points))
line = line[:]+'\n'
data.write(line)
total = []
# with open('work/train_data_det.txt', 'r', encoding='UTF-8') as f:
# for line in f:
# total.append(line)
# with open('work/val_data_det.txt', 'r', encoding='UTF-8') as f:
# for line in f:
# total.append(line)
with open('work/test_data_det.txt', 'r', encoding='UTF-8') as f:
for line in f:
total.append(line)
# with open('work/train_det.txt', 'w', encoding='UTF-8') as f:
# for line in total[:-500]:
# f.write(line)
# with open('work/dev_det.txt', 'w', encoding='UTF-8') as f:
# for line in total[-500:]:
# f.write(line)/home/aistudio
In [ ]
#识别数据:转换成PaddleOCR使用的格式(图片名+内容),打开注释执行三次生成训练所需txt文件,分别为train、val、test。
%cd ~
import os, cv2
words_list = [
"A", "B", "C", "D", "E",
"F", "G", "H", "J", "K",
"L", "M", "N", "P", "Q",
"R", "S", "T", "U", "V",
"W", "X", "Y", "Z", "0",
"1", "2", "3", "4", "5",
"6", "7", "8", "9" ]
con_list = [
"皖", "沪", "津", "渝", "冀",
"晋", "蒙", "辽", "吉", "黑",
"苏", "浙", "京", "闽", "赣",
"鲁", "豫", "鄂", "湘", "粤",
"桂", "琼", "川", "贵", "云",
"西", "陕", "甘", "青", "宁",
"新"]
# if not os.path.exists('work/img'): #所有数据集都放入一个文件夹
# os.mkdir('work/img')
#训练、验证、测试集分开三个文件夹对应解开注释依次执行三次
# if not os.path.exists('work/train_rec_img'):
# os.mkdir('work/train_rec_img')
if not os.path.exists('work/val_rec_img'):
os.mkdir('work/val_rec_img')
# if not os.path.exists('work/test_rec_img'):
# os.mkdir('work/test_rec_img')
count = 0
# data = open('work/train_data_rec.txt', 'w', encoding='UTF-8')
data = open('work/val_data_rec.txt', 'w', encoding='UTF-8')
# data = open('work/test_data_rec.txt', 'w', encoding='UTF-8')
# for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/train'):
for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/val'):
# for item in os.listdir('work/CCPD2020/CCPD2020/ccpd_green/test'):
# path = 'work/CCPD2020/CCPD2020/ccpd_green/train/'+item
path = 'work/CCPD2020/CCPD2020/ccpd_green/val/'+item
# path = 'work/CCPD2020/CCPD2020/ccpd_green/test/'+item
#原来的 path = 'work/CCPD2020/ccpd_base/'+item
_, _, bbox, _, label, _, _ = item.split('-')
bbox = bbox.split('_')
x1, y1 = bbox[0].split('&')
x2, y2 = bbox[1].split('&')
label = label.split('_')
con = con_list[int(label[0])]
words = [words_list[int(_)] for _ in label[1:]]
label = con+''.join(words)
bbox = [int(_) for _ in [x1, y1, x2, y2]]
img = cv2.imread(path)
crop = img[bbox[1]:bbox[3], bbox[0]:bbox[2], :]
# cv2.imwrite('work/train_rec_img/%06d.jpg' % count, crop)
# data.write('work/train_rec_img/%06d.jpg\t%s\n' % (count, label))
cv2.imwrite('work/val_rec_img/%06d.jpg' % count, crop)
data.write('work/val_rec_img/%06d.jpg\t%s\n' % (count, label))
# cv2.imwrite('work/test_rec_img/%06d.jpg' % count, crop)
# data.write('work/test_rec_img/%06d.jpg\t%s\n' % (count, label))
count += 1
data.close()
with open('work/word_dict.txt', 'w', encoding='UTF-8') as f:
for line in words_list+con_list:
f.write(line+'\n')
# total = []
# with open('work/train_data_rec.txt', 'r', encoding='UTF-8') as f:
# for line in f:
# total.append(line)
with open('work/val_data_rec.txt', 'r', encoding='UTF-8') as f:
for line in f:
total.append(line)
# with open('work/test_data_rec.txt', 'r', encoding='UTF-8') as f:
# for line in f:
# total.append(line)
/home/aistudio
最终文件生成效果:
- 注:”由于work文件较大,无法生成版本,读者可执行上述代码生成下述对应文件,也可以自行修改代码,放到其他路径。
- 下图为work目录下,其中CCPD为本项目CCPD2020数据(解压到work目录下),另三个rec_img文件夹为用于识别流程的图片,img为三个汇总,其余为用于检测det与识别rec生成的txt文本。

模型介绍
PaddleOCR提供的检测与识别模型如下:

模型选择
Paddocr提供以下文件检测及识别模型,考虑车牌识别中字符数量较少,而且长度也固定,且为标准的印刷字体,所以无需使用过于复杂的模型。因此,参考其他开源资料,本项目选择经典的DBNet+RARE,两个模型均使用MobileNetV3作为其主干网络(Backbone)。
DBNet与RARE算法介绍可参考我的博客:OCR文字识别经典论文详解
DBNet

RARE

下载对应预训练模型
In [ ]
%cd ~/work/PaddleOCR
# 下载预训练模型
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/ch_models/ch_det_mv3_db.tar
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/rec_mv3_tps_bilstm_attn.tar
# 解压模型参数
%cd pretrain_models
!tar -xf ch_det_mv3_db.tar && rm -rf ch_det_mv3_db.tar
!tar -xf rec_mv3_tps_bilstm_attn.tar && rm -rf rec_mv3_tps_bilstm_attn.tar模型训练
1.检测模型训练
检测模版文件 configs/det/det_mv3_db.yml
Global:
algorithm: DB
use_gpu: true
epoch_num: 1200
log_smooth_window: 20
print_batch_step: 20
save_model_dir: ./myoutput/det_db/
save_epoch_step: 10
# evaluation is run every 5000 iterations after the 4000th iteration
eval_batch_step: [100, 500]
train_batch_size_per_card: 4
test_batch_size_per_card: 4
image_shape: [3, 640, 640]
reader_yml: ./configs/det/det_db_icdar15_reader.yml
pretrain_weights: ./pretrain_models/det_mv3_db/best_accuracy
checkpoints:
save_res_path: ./myoutput/det_db/predicts_db.txt
save_inference_dir:
Architecture:
function: ppocr.modeling.architectures.det_model,DetModel
Backbone:
function: ppocr.modeling.backbones.det_mobilenet_v3,MobileNetV3
scale: 0.5
model_name: large
Head:
function: ppocr.modeling.heads.det_db_head,DBHead
model_name: large
k: 50
inner_channels: 96
out_channels: 2
Loss:
function: ppocr.modeling.losses.det_db_loss,DBLoss
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Optimizer:
function: ppocr.optimizer,AdamDecay
base_lr: 0.001
beta1: 0.9
beta2: 0.999
PostProcess:
function: ppocr.postprocess.db_postprocess,DBPostProcess
thresh: 0.3
box_thresh: 0.7
max_candidates: 1000
unclip_ratio: 2.0
In [ ]
%cd ~/PaddleOCR
# 设置PYTHONPATH路径
%env PYTHONPATH=$PYTHONPATH:.
# GPU单卡训练
%env CUDA_VISIBLE_DEVICES=0
!python3 tools/train.py -c configs/det/det_mv3_db.yml2.识别
主干网络为轻量级网络MobilenetV3,识别算法包括TPS校正+双向LSTM+Attention
Global:
algorithm: RARE
use_gpu: true
epoch_num: 200
log_smooth_window: 20
print_batch_step: 20
#save_model_dir: output/rec_RARE
save_model_dir: ./myoutput/rec_RARE_atten_new
save_epoch_step: 100
eval_batch_step: 500
train_batch_size_per_card: 256
test_batch_size_per_card: 256
image_shape: [3, 32, 320]
max_text_length: 8
character_type: ch
character_dict_path: ../word_dict.txt
loss_type: attention
tps: true
reader_yml: ./configs/rec/rec_chinese_reader.yml
pretrain_weights: ./pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy
# pretrain_weights:
checkpoints:
save_inference_dir: ./inference/newimg_rec_rare
infer_img:
Architecture:
function: ppocr.modeling.architectures.rec_model,RecModel
TPS:
function: ppocr.modeling.stns.tps,TPS
num_fiducial: 20
loc_lr: 0.1
model_name: small
Backbone:
function: ppocr.modeling.backbones.rec_mobilenet_v3,MobileNetV3
scale: 0.5
model_name: large
Head:
function: ppocr.modeling.heads.rec_attention_head,AttentionPredict
encoder_type: rnn
SeqRNN:
hidden_size: 96
Attention:
decoder_size: 96
word_vector_dim: 96
Loss:
function: ppocr.modeling.losses.rec_attention_loss,AttentionLoss
Optimizer:
function: ppocr.optimizer,AdamDecay
base_lr: 0.001
beta1: 0.9
beta2: 0.999
In [77]
%cd ~/PaddleOCR
# GPU单卡训练
%env CUDA_VISIBLE_DEVICES=0
!python3 tools/train.py -c configs/rec/rec_mv3_tps_bilstm_attn.yml/home/aistudio/work/PaddleOCR
env: CUDA_VISIBLE_DEVICES=0
2022-09-15 16:06:31,610-INFO: {'Global': {'debug': False, 'algorithm': 'RARE', 'use_gpu': True, 'epoch_num': 200, 'log_smooth_window': 20, 'print_batch_step': 20, 'save_model_dir': './myoutput/rec_RARE_atten_new', 'save_epoch_step': 100, 'eval_batch_step': 500, 'train_batch_size_per_card': 256, 'test_batch_size_per_card': 256, 'image_shape': [3, 32, 320], 'max_text_length': 8, 'character_type': 'ch', 'character_dict_path': '../word_dict.txt', 'loss_type': 'attention', 'tps': True, 'reader_yml': './configs/rec/rec_chinese_reader.yml', 'pretrain_weights': './pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy', 'checkpoints': None, 'save_inference_dir': './inference/newimg_rec_rare', 'infer_img': None}, 'Architecture': {'function': 'ppocr.modeling.architectures.rec_model,RecModel'}, 'TPS': {'function': 'ppocr.modeling.stns.tps,TPS', 'num_fiducial': 20, 'loc_lr': 0.1, 'model_name': 'small'}, 'Backbone': {'function': 'ppocr.modeling.backbones.rec_mobilenet_v3,MobileNetV3', 'scale': 0.5, 'model_name': 'large'}, 'Head': {'function': 'ppocr.modeling.heads.rec_attention_head,AttentionPredict', 'encoder_type': 'rnn', 'SeqRNN': {'hidden_size': 96}, 'Attention': {'decoder_size': 96, 'word_vector_dim': 96}}, 'Loss': {'function': 'ppocr.modeling.losses.rec_attention_loss,AttentionLoss'}, 'Optimizer': {'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 0.001, 'beta1': 0.9, 'beta2': 0.999}, 'TrainReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../train_data_rec.txt'}, 'EvalReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../val_data_rec.txt'}, 'TestReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader'}}
2022-09-15 16:06:32,400-INFO: If regularizer of a Parameter has been set by 'fluid.ParamAttr' or 'fluid.WeightNormParamAttr' already. The Regularization[L2Decay, regularization_coeff=0.000000] in Optimizer will not take effect, and it will only be applied to other Parameters!
2022-09-15 16:06:34,241-INFO: places would be ommited when DataLoader is not iterable
W0915 16:06:34.303215 18580 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.2, Runtime API Version: 9.0
W0915 16:06:34.307891 18580 device_context.cc:260] device: 0, cuDNN Version: 7.6.
2022-09-15 16:06:36,359-INFO: Loading parameters from ./pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy...
2022-09-15 16:06:36,425-WARNING: variable embedding_0.w_0 not used
2022-09-15 16:06:36,425-WARNING: variable rnn_out_fc.w_0 not used
2022-09-15 16:06:36,425-WARNING: variable rnn_out_fc.b_0 not used
2022-09-15 16:06:36,470-INFO: Finish initing model from ./pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy
2022-09-15 16:06:47,710-INFO: epoch: 1, iter: 20, lr: 0.001000, 'loss': 4937.542, 'acc': 0.0, time: 0.387
2022-09-15 16:06:56,909-INFO: epoch: 2, iter: 40, lr: 0.001000, 'loss': 3201.4744, 'acc': 0.0, time: 0.373
2022-09-15 16:07:06,105-INFO: epoch: 3, iter: 60, lr: 0.001000, 'loss': 2400.3447, 'acc': 0.007812, time: 0.374
2022-09-15 16:07:16,551-INFO: epoch: 5, iter: 80, lr: 0.001000, 'loss': 1625.6213, 'acc': 0.146484, time: 1.787
2022-09-15 16:07:25,677-INFO: epoch: 6, iter: 100, lr: 0.001000, 'loss': 740.44006, 'acc': 0.769531, time: 0.376
2022-09-15 16:07:34,829-INFO: epoch: 7, iter: 120, lr: 0.001000, 'loss': 370.51062, 'acc': 0.902344, time: 0.374
2022-09-15 16:07:43,827-INFO: epoch: 8, iter: 140, lr: 0.001000, 'loss': 281.9944, 'acc': 0.929688, time: 0.374
2022-09-15 16:07:54,266-INFO: epoch: 10, iter: 160, lr: 0.001000, 'loss': 213.27815, 'acc': 0.933594, time: 1.769
2022-09-15 16:08:03,481-INFO: epoch: 11, iter: 180, lr: 0.001000, 'loss': 149.04875, 'acc': 0.949219, time: 0.403
2022-09-15 16:08:12,440-INFO: epoch: 12, iter: 200, lr: 0.001000, 'loss': 119.06343, 'acc': 0.951172, time: 0.374
2022-09-15 16:08:21,519-INFO: epoch: 13, iter: 220, lr: 0.001000, 'loss': 100.26872, 'acc': 0.949219, time: 0.373
2022-09-15 16:08:32,031-INFO: epoch: 15, iter: 240, lr: 0.001000, 'loss': 84.79035, 'acc': 0.970703, time: 1.806
2022-09-15 16:08:41,146-INFO: epoch: 16, iter: 260, lr: 0.001000, 'loss': 79.10332, 'acc': 0.966797, time: 0.409
2022-09-15 16:08:50,249-INFO: epoch: 17, iter: 280, lr: 0.001000, 'loss': 97.50918, 'acc': 0.955078, time: 0.373
2022-09-15 16:08:59,211-INFO: epoch: 18, iter: 300, lr: 0.001000, 'loss': 81.51908, 'acc': 0.960938, time: 0.373
2022-09-15 16:09:09,670-INFO: epoch: 20, iter: 320, lr: 0.001000, 'loss': 153.25719, 'acc': 0.935547, time: 1.713
2022-09-15 16:09:18,849-INFO: epoch: 21, iter: 340, lr: 0.001000, 'loss': 122.89736, 'acc': 0.949219, time: 0.399
2022-09-15 16:09:28,010-INFO: epoch: 22, iter: 360, lr: 0.001000, 'loss': 78.92976, 'acc': 0.958984, time: 0.373
2022-09-15 16:09:37,014-INFO: epoch: 23, iter: 380, lr: 0.001000, 'loss': 53.346596, 'acc': 0.972656, time: 0.373
2022-09-15 16:09:47,468-INFO: epoch: 25, iter: 400, lr: 0.001000, 'loss': 52.11016, 'acc': 0.972656, time: 1.756
2022-09-15 16:09:56,459-INFO: epoch: 26, iter: 420, lr: 0.001000, 'loss': 43.66102, 'acc': 0.972656, time: 0.374
2022-09-15 16:10:05,548-INFO: epoch: 27, iter: 440, lr: 0.001000, 'loss': 38.42436, 'acc': 0.980469, time: 0.373
2022-09-15 16:10:14,536-INFO: epoch: 28, iter: 460, lr: 0.001000, 'loss': 45.512665, 'acc': 0.978516, time: 0.373
2022-09-15 16:10:25,020-INFO: epoch: 30, iter: 480, lr: 0.001000, 'loss': 40.709595, 'acc': 0.976562, time: 1.789
2022-09-15 16:10:34,337-INFO: epoch: 31, iter: 500, lr: 0.001000, 'loss': 39.14653, 'acc': 0.974609, time: 0.412
2022-09-15 16:10:36,277-INFO: Already save model in ./myoutput/rec_RARE_atten_new/best_accuracy
2022-09-15 16:10:36,277-INFO: Test iter: 500, acc:0.777223, best_acc:0.777223, best_epoch:31, best_batch_id:500, eval_sample_num:1001
2022-09-15 16:10:45,402-INFO: epoch: 32, iter: 520, lr: 0.001000, 'loss': 33.690575, 'acc': 0.984375, time: 0.377
2022-09-15 16:10:54,503-INFO: epoch: 33, iter: 540, lr: 0.001000, 'loss': 29.822884, 'acc': 0.982422, time: 0.374
2022-09-15 16:11:05,027-INFO: epoch: 35, iter: 560, lr: 0.001000, 'loss': 33.394993, 'acc': 0.980469, time: 1.868
2022-09-15 16:11:14,148-INFO: epoch: 36, iter: 580, lr: 0.001000, 'loss': 29.375713, 'acc': 0.980469, time: 0.419
2022-09-15 16:11:23,142-INFO: epoch: 37, iter: 600, lr: 0.001000, 'loss': 44.640976, 'acc': 0.976562, time: 0.374
2022-09-15 16:11:32,155-INFO: epoch: 38, iter: 620, lr: 0.001000, 'loss': 32.55059, 'acc': 0.988281, time: 0.373
2022-09-15 16:11:42,665-INFO: epoch: 40, iter: 640, lr: 0.001000, 'loss': 24.32478, 'acc': 0.988281, time: 1.872
2022-09-15 16:11:51,777-INFO: epoch: 41, iter: 660, lr: 0.001000, 'loss': 23.933027, 'acc': 0.986328, time: 0.375
2022-09-15 16:12:00,873-INFO: epoch: 42, iter: 680, lr: 0.001000, 'loss': 24.20562, 'acc': 0.990234, time: 0.376
2022-09-15 16:12:09,940-INFO: epoch: 43, iter: 700, lr: 0.001000, 'loss': 20.969837, 'acc': 0.988281, time: 0.374
2022-09-15 16:12:20,566-INFO: epoch: 45, iter: 720, lr: 0.001000, 'loss': 21.603209, 'acc': 0.988281, time: 1.798
2022-09-15 16:12:29,785-INFO: epoch: 46, iter: 740, lr: 0.001000, 'loss': 14.918937, 'acc': 0.992188, time: 0.380
2022-09-15 16:12:38,854-INFO: epoch: 47, iter: 760, lr: 0.001000, 'loss': 16.47085, 'acc': 0.992188, time: 0.373
2022-09-15 16:12:47,954-INFO: epoch: 48, iter: 780, lr: 0.001000, 'loss': 13.787853, 'acc': 0.992188, time: 0.373
2022-09-15 16:12:58,526-INFO: epoch: 50, iter: 800, lr: 0.001000, 'loss': 20.16197, 'acc': 0.990234, time: 1.886
2022-09-15 16:13:07,622-INFO: epoch: 51, iter: 820, lr: 0.001000, 'loss': 15.042562, 'acc': 0.992188, time: 0.413
2022-09-15 16:13:16,744-INFO: epoch: 52, iter: 840, lr: 0.001000, 'loss': 30.320072, 'acc': 0.980469, time: 0.374
2022-09-15 16:13:25,803-INFO: epoch: 53, iter: 860, lr: 0.001000, 'loss': 27.366596, 'acc': 0.984375, time: 0.373
2022-09-15 16:13:36,263-INFO: epoch: 55, iter: 880, lr: 0.001000, 'loss': 107.29559, 'acc': 0.964844, time: 1.804
2022-09-15 16:13:45,315-INFO: epoch: 56, iter: 900, lr: 0.001000, 'loss': 112.5357, 'acc': 0.9375, time: 0.377
2022-09-15 16:13:54,380-INFO: epoch: 57, iter: 920, lr: 0.001000, 'loss': 80.11721, 'acc': 0.951172, time: 0.375
2022-09-15 16:14:03,521-INFO: epoch: 58, iter: 940, lr: 0.001000, 'loss': 173.3816, 'acc': 0.896484, time: 0.375
2022-09-15 16:14:14,176-INFO: epoch: 60, iter: 960, lr: 0.001000, 'loss': 111.91419, 'acc': 0.943359, time: 1.820
2022-09-15 16:14:23,354-INFO: epoch: 61, iter: 980, lr: 0.001000, 'loss': 67.807884, 'acc': 0.964844, time: 0.418
2022-09-15 16:14:32,359-INFO: epoch: 62, iter: 1000, lr: 0.001000, 'loss': 49.46469, 'acc': 0.972656, time: 0.382
2022-09-15 16:14:34,236-INFO: Already save model in ./myoutput/rec_RARE_atten_new/best_accuracy
2022-09-15 16:14:34,237-INFO: Test iter: 1000, acc:0.782218, best_acc:0.782218, best_epoch:62, best_batch_id:1000, eval_sample_num:1001
2022-09-15 16:14:43,256-INFO: epoch: 63, iter: 1020, lr: 0.001000, 'loss': 43.5632, 'acc': 0.972656, time: 0.373
2022-09-15 16:14:53,769-INFO: epoch: 65, iter: 1040, lr: 0.001000, 'loss': 31.788738, 'acc': 0.984375, time: 1.797
2022-09-15 16:15:02,909-INFO: epoch: 66, iter: 1060, lr: 0.001000, 'loss': 24.396, 'acc': 0.984375, time: 0.411
2022-09-15 16:15:12,029-INFO: epoch: 67, iter: 1080, lr: 0.001000, 'loss': 21.756264, 'acc': 0.992188, time: 0.374
2022-09-15 16:15:21,012-INFO: epoch: 68, iter: 1100, lr: 0.001000, 'loss': 18.515491, 'acc': 0.988281, time: 0.379
2022-09-15 16:15:31,652-INFO: epoch: 70, iter: 1120, lr: 0.001000, 'loss': 28.279198, 'acc': 0.980469, time: 1.828
2022-09-15 16:15:40,799-INFO: epoch: 71, iter: 1140, lr: 0.001000, 'loss': 23.729788, 'acc': 0.988281, time: 0.374
2022-09-15 16:15:49,867-INFO: epoch: 72, iter: 1160, lr: 0.001000, 'loss': 19.145424, 'acc': 0.988281, time: 0.374
2022-09-15 16:15:58,914-INFO: epoch: 73, iter: 1180, lr: 0.001000, 'loss': 16.507511, 'acc': 0.992188, time: 0.374
2022-09-15 16:16:09,365-INFO: epoch: 75, iter: 1200, lr: 0.001000, 'loss': 19.851065, 'acc': 0.988281, time: 1.786
2022-09-15 16:16:18,561-INFO: epoch: 76, iter: 1220, lr: 0.001000, 'loss': 33.03997, 'acc': 0.980469, time: 0.404
2022-09-15 16:16:27,601-INFO: epoch: 77, iter: 1240, lr: 0.001000, 'loss': 43.73796, 'acc': 0.974609, time: 0.373
2022-09-15 16:16:36,731-INFO: epoch: 78, iter: 1260, lr: 0.001000, 'loss': 25.171104, 'acc': 0.984375, time: 0.374
2022-09-15 16:16:47,318-INFO: epoch: 80, iter: 1280, lr: 0.001000, 'loss': 19.046516, 'acc': 0.988281, time: 1.838
2022-09-15 16:16:56,417-INFO: epoch: 81, iter: 1300, lr: 0.001000, 'loss': 17.294367, 'acc': 0.988281, time: 0.399
2022-09-15 16:17:05,547-INFO: epoch: 82, iter: 1320, lr: 0.001000, 'loss': 17.236929, 'acc': 0.992188, time: 0.373
2022-09-15 16:17:14,582-INFO: epoch: 83, iter: 1340, lr: 0.001000, 'loss': 15.577, 'acc': 0.988281, time: 0.373
2022-09-15 16:17:25,033-INFO: epoch: 85, iter: 1360, lr: 0.001000, 'loss': 15.052889, 'acc': 0.990234, time: 1.760
2022-09-15 16:17:34,349-INFO: epoch: 86, iter: 1380, lr: 0.001000, 'loss': 17.350527, 'acc': 0.988281, time: 0.413
2022-09-15 16:17:43,599-INFO: epoch: 87, iter: 1400, lr: 0.001000, 'loss': 14.587466, 'acc': 0.990234, time: 0.374
2022-09-15 16:17:52,589-INFO: epoch: 88, iter: 1420, lr: 0.001000, 'loss': 14.150236, 'acc': 0.992188, time: 0.373
2022-09-15 16:18:02,967-INFO: epoch: 90, iter: 1440, lr: 0.001000, 'loss': 12.714052, 'acc': 0.988281, time: 1.742
2022-09-15 16:18:12,164-INFO: epoch: 91, iter: 1460, lr: 0.001000, 'loss': 10.972769, 'acc': 0.992188, time: 0.402
2022-09-15 16:18:21,412-INFO: epoch: 92, iter: 1480, lr: 0.001000, 'loss': 14.171873, 'acc': 0.992188, time: 0.374
2022-09-15 16:18:30,446-INFO: epoch: 93, iter: 1500, lr: 0.001000, 'loss': 10.255694, 'acc': 0.992188, time: 0.374
2022-09-15 16:18:32,318-INFO: Already save model in ./myoutput/rec_RARE_atten_new/best_accuracy
2022-09-15 16:18:32,319-INFO: Test iter: 1500, acc:0.823177, best_acc:0.823177, best_epoch:93, best_batch_id:1500, eval_sample_num:1001
2022-09-15 16:18:43,055-INFO: epoch: 95, iter: 1520, lr: 0.001000, 'loss': 9.569214, 'acc': 0.996094, time: 1.995
2022-09-15 16:18:52,264-INFO: epoch: 96, iter: 1540, lr: 0.001000, 'loss': 9.96125, 'acc': 0.992188, time: 0.414
2022-09-15 16:19:01,514-INFO: epoch: 97, iter: 1560, lr: 0.001000, 'loss': 8.359654, 'acc': 0.996094, time: 0.374
2022-09-15 16:19:10,616-INFO: epoch: 98, iter: 1580, lr: 0.001000, 'loss': 6.192225, 'acc': 0.998047, time: 0.373
2022-09-15 16:19:21,189-INFO: epoch: 100, iter: 1600, lr: 0.001000, 'loss': 5.406765, 'acc': 0.996094, time: 1.799
2022-09-15 16:19:27,310-INFO: Already save model in ./myoutput/rec_RARE_atten_new/iter_epoch_100
2022-09-15 16:19:30,699-INFO: epoch: 101, iter: 1620, lr: 0.001000, 'loss': 5.483102, 'acc': 0.996094, time: 0.381
2022-09-15 16:19:39,779-INFO: epoch: 102, iter: 1640, lr: 0.001000, 'loss': 9.586991, 'acc': 0.996094, time: 0.374
2022-09-15 16:19:48,841-INFO: epoch: 103, iter: 1660, lr: 0.001000, 'loss': 5.63769, 'acc': 0.996094, time: 0.374
2022-09-15 16:19:59,323-INFO: epoch: 105, iter: 1680, lr: 0.001000, 'loss': 11.556911, 'acc': 0.996094, time: 1.855
2022-09-15 16:20:08,442-INFO: epoch: 106, iter: 1700, lr: 0.001000, 'loss': 8.392323, 'acc': 0.996094, time: 0.420
2022-09-15 16:20:17,532-INFO: epoch: 107, iter: 1720, lr: 0.001000, 'loss': 4.550391, 'acc': 0.996094, time: 0.374
2022-09-15 16:20:26,593-INFO: epoch: 108, iter: 1740, lr: 0.001000, 'loss': 5.61542, 'acc': 0.996094, time: 0.373
2022-09-15 16:20:37,160-INFO: epoch: 110, iter: 1760, lr: 0.001000, 'loss': 9.220263, 'acc': 0.996094, time: 1.810
2022-09-15 16:20:46,332-INFO: epoch: 111, iter: 1780, lr: 0.001000, 'loss': 4.136215, 'acc': 0.998047, time: 0.422
2022-09-15 16:20:55,467-INFO: epoch: 112, iter: 1800, lr: 0.001000, 'loss': 5.135178, 'acc': 0.996094, time: 0.373
2022-09-15 16:21:04,534-INFO: epoch: 113, iter: 1820, lr: 0.001000, 'loss': 5.234288, 'acc': 0.996094, time: 0.374
2022-09-15 16:21:15,182-INFO: epoch: 115, iter: 1840, lr: 0.001000, 'loss': 4.517134, 'acc': 0.996094, time: 1.924
2022-09-15 16:21:24,325-INFO: epoch: 116, iter: 1860, lr: 0.001000, 'loss': 3.831606, 'acc': 1.0, time: 0.387
2022-09-15 16:21:33,438-INFO: epoch: 117, iter: 1880, lr: 0.001000, 'loss': 3.111336, 'acc': 0.996094, time: 0.373
2022-09-15 16:21:42,490-INFO: epoch: 118, iter: 1900, lr: 0.001000, 'loss': 3.794124, 'acc': 0.996094, time: 0.374
2022-09-15 16:21:53,098-INFO: epoch: 120, iter: 1920, lr: 0.001000, 'loss': 3.929718, 'acc': 0.998047, time: 1.913
2022-09-15 16:22:02,185-INFO: epoch: 121, iter: 1940, lr: 0.001000, 'loss': 4.611428, 'acc': 0.996094, time: 0.375
2022-09-15 16:22:11,267-INFO: epoch: 122, iter: 1960, lr: 0.001000, 'loss': 2.685765, 'acc': 1.0, time: 0.374
2022-09-15 16:22:20,275-INFO: epoch: 123, iter: 1980, lr: 0.001000, 'loss': 2.870256, 'acc': 1.0, time: 0.373
2022-09-15 16:22:30,732-INFO: epoch: 125, iter: 2000, lr: 0.001000, 'loss': 4.04394, 'acc': 0.998047, time: 1.891
2022-09-15 16:22:33,935-INFO: Already save model in ./myoutput/rec_RARE_atten_new/best_accuracy
2022-09-15 16:22:33,935-INFO: Test iter: 2000, acc:0.829171, best_acc:0.829171, best_epoch:125, best_batch_id:2000, eval_sample_num:1001
2022-09-15 16:22:42,925-INFO: epoch: 126, iter: 2020, lr: 0.001000, 'loss': 3.729886, 'acc': 0.996094, time: 0.384
2022-09-15 16:22:51,976-INFO: epoch: 127, iter: 2040, lr: 0.001000, 'loss': 3.797183, 'acc': 0.996094, time: 0.377
2022-09-15 16:23:01,064-INFO: epoch: 128, iter: 2060, lr: 0.001000, 'loss': 3.841343, 'acc': 1.0, time: 0.374
2022-09-15 16:23:11,632-INFO: epoch: 130, iter: 2080, lr: 0.001000, 'loss': 2.5157, 'acc': 1.0, time: 1.818
2022-09-15 16:23:20,885-INFO: epoch: 131, iter: 2100, lr: 0.001000, 'loss': 2.793916, 'acc': 1.0, time: 0.382
2022-09-15 16:23:29,893-INFO: epoch: 132, iter: 2120, lr: 0.001000, 'loss': 2.068662, 'acc': 1.0, time: 0.373
2022-09-15 16:23:38,892-INFO: epoch: 133, iter: 2140, lr: 0.001000, 'loss': 1.963152, 'acc': 1.0, time: 0.374
2022-09-15 16:23:49,438-INFO: epoch: 135, iter: 2160, lr: 0.001000, 'loss': 1.785324, 'acc': 1.0, time: 1.811
2022-09-15 16:23:58,622-INFO: epoch: 136, iter: 2180, lr: 0.001000, 'loss': 1.794544, 'acc': 1.0, time: 0.388
2022-09-15 16:24:07,731-INFO: epoch: 137, iter: 2200, lr: 0.001000, 'loss': 1.725564, 'acc': 1.0, time: 0.381
2022-09-15 16:24:16,818-INFO: epoch: 138, iter: 2220, lr: 0.001000, 'loss': 1.576424, 'acc': 1.0, time: 0.373
2022-09-15 16:24:27,274-INFO: epoch: 140, iter: 2240, lr: 0.001000, 'loss': 1.49527, 'acc': 1.0, time: 1.773
2022-09-15 16:24:36,422-INFO: epoch: 141, iter: 2260, lr: 0.001000, 'loss': 1.492407, 'acc': 1.0, time: 0.374
2022-09-15 16:24:45,728-INFO: epoch: 142, iter: 2280, lr: 0.001000, 'loss': 1.456, 'acc': 1.0, time: 0.374
2022-09-15 16:24:54,789-INFO: epoch: 143, iter: 2300, lr: 0.001000, 'loss': 1.191148, 'acc': 1.0, time: 0.373
2022-09-15 16:25:05,522-INFO: epoch: 145, iter: 2320, lr: 0.001000, 'loss': 1.210015, 'acc': 1.0, time: 1.863
2022-09-15 16:25:14,468-INFO: epoch: 146, iter: 2340, lr: 0.001000, 'loss': 1.281136, 'acc': 1.0, time: 0.375
2022-09-15 16:25:23,566-INFO: epoch: 147, iter: 2360, lr: 0.001000, 'loss': 1.303462, 'acc': 1.0, time: 0.374
2022-09-15 16:25:32,584-INFO: epoch: 148, iter: 2380, lr: 0.001000, 'loss': 1.070822, 'acc': 1.0, time: 0.375
2022-09-15 16:25:42,999-INFO: epoch: 150, iter: 2400, lr: 0.001000, 'loss': 1.107232, 'acc': 1.0, time: 1.789
2022-09-15 16:25:52,155-INFO: epoch: 151, iter: 2420, lr: 0.001000, 'loss': 1.304622, 'acc': 1.0, time: 0.411
2022-09-15 16:26:01,268-INFO: epoch: 152, iter: 2440, lr: 0.001000, 'loss': 1.403758, 'acc': 1.0, time: 0.374
2022-09-15 16:26:10,305-INFO: epoch: 153, iter: 2460, lr: 0.001000, 'loss': 1.210189, 'acc': 1.0, time: 0.373
2022-09-15 16:26:20,865-INFO: epoch: 155, iter: 2480, lr: 0.001000, 'loss': 1.069858, 'acc': 1.0, time: 1.815
2022-09-15 16:26:30,007-INFO: epoch: 156, iter: 2500, lr: 0.001000, 'loss': 1.320687, 'acc': 1.0, time: 0.375
2022-09-15 16:26:32,067-INFO: Already save model in ./myoutput/rec_RARE_atten_new/best_accuracy
2022-09-15 16:26:32,067-INFO: Test iter: 2500, acc:0.831169, best_acc:0.831169, best_epoch:156, best_batch_id:2500, eval_sample_num:1001
2022-09-15 16:26:41,097-INFO: epoch: 157, iter: 2520, lr: 0.001000, 'loss': 1.170897, 'acc': 1.0, time: 0.374
2022-09-15 16:26:50,126-INFO: epoch: 158, iter: 2540, lr: 0.001000, 'loss': 1.209216, 'acc': 1.0, time: 0.373
2022-09-15 16:27:00,639-INFO: epoch: 160, iter: 2560, lr: 0.001000, 'loss': 1.066662, 'acc': 1.0, time: 1.871
2022-09-15 16:27:09,739-INFO: epoch: 161, iter: 2580, lr: 0.001000, 'loss': 0.858585, 'acc': 1.0, time: 0.378
2022-09-15 16:27:18,841-INFO: epoch: 162, iter: 2600, lr: 0.001000, 'loss': 0.789717, 'acc': 1.0, time: 0.373
2022-09-15 16:27:27,905-INFO: epoch: 163, iter: 2620, lr: 0.001000, 'loss': 0.861278, 'acc': 1.0, time: 0.373
2022-09-15 16:27:38,476-INFO: epoch: 165, iter: 2640, lr: 0.001000, 'loss': 0.891585, 'acc': 1.0, time: 1.823
2022-09-15 16:27:47,624-INFO: epoch: 166, iter: 2660, lr: 0.001000, 'loss': 0.919595, 'acc': 1.0, time: 0.383
2022-09-15 16:27:56,740-INFO: epoch: 167, iter: 2680, lr: 0.001000, 'loss': 0.757441, 'acc': 1.0, time: 0.374
2022-09-15 16:28:05,765-INFO: epoch: 168, iter: 2700, lr: 0.001000, 'loss': 0.720211, 'acc': 1.0, time: 0.374
2022-09-15 16:28:16,255-INFO: epoch: 170, iter: 2720, lr: 0.001000, 'loss': 0.76394, 'acc': 1.0, time: 1.810
2022-09-15 16:28:25,394-INFO: epoch: 171, iter: 2740, lr: 0.001000, 'loss': 0.70124, 'acc': 1.0, time: 0.375
2022-09-15 16:28:34,568-INFO: epoch: 172, iter: 2760, lr: 0.001000, 'loss': 0.681117, 'acc': 1.0, time: 0.373
2022-09-15 16:28:43,565-INFO: epoch: 173, iter: 2780, lr: 0.001000, 'loss': 0.71791, 'acc': 1.0, time: 0.375
2022-09-15 16:28:54,132-INFO: epoch: 175, iter: 2800, lr: 0.001000, 'loss': 0.726069, 'acc': 1.0, time: 1.846
2022-09-15 16:29:03,266-INFO: epoch: 176, iter: 2820, lr: 0.001000, 'loss': 0.662951, 'acc': 1.0, time: 0.435
2022-09-15 16:29:12,259-INFO: epoch: 177, iter: 2840, lr: 0.001000, 'loss': 0.770077, 'acc': 1.0, time: 0.374
2022-09-15 16:29:21,314-INFO: epoch: 178, iter: 2860, lr: 0.001000, 'loss': 0.70409, 'acc': 1.0, time: 0.374
2022-09-15 16:29:31,740-INFO: epoch: 180, iter: 2880, lr: 0.001000, 'loss': 0.75167, 'acc': 1.0, time: 1.781
2022-09-15 16:29:40,952-INFO: epoch: 181, iter: 2900, lr: 0.001000, 'loss': 0.595518, 'acc': 1.0, time: 0.384
2022-09-15 16:29:50,018-INFO: epoch: 182, iter: 2920, lr: 0.001000, 'loss': 0.678415, 'acc': 1.0, time: 0.374
2022-09-15 16:29:59,274-INFO: epoch: 183, iter: 2940, lr: 0.001000, 'loss': 0.602751, 'acc': 1.0, time: 0.373
2022-09-15 16:30:09,946-INFO: epoch: 185, iter: 2960, lr: 0.001000, 'loss': 0.568185, 'acc': 1.0, time: 2.010
2022-09-15 16:30:19,154-INFO: epoch: 186, iter: 2980, lr: 0.001000, 'loss': 0.56914, 'acc': 1.0, time: 0.397
2022-09-15 16:30:28,234-INFO: epoch: 187, iter: 3000, lr: 0.001000, 'loss': 0.570147, 'acc': 1.0, time: 0.373
2022-09-15 16:30:29,647-INFO: Test iter: 3000, acc:0.831169, best_acc:0.831169, best_epoch:156, best_batch_id:2500, eval_sample_num:1001
2022-09-15 16:30:38,718-INFO: epoch: 188, iter: 3020, lr: 0.001000, 'loss': 0.556909, 'acc': 1.0, time: 0.373
2022-09-15 16:30:49,241-INFO: epoch: 190, iter: 3040, lr: 0.001000, 'loss': 0.522148, 'acc': 1.0, time: 1.889
2022-09-15 16:30:58,437-INFO: epoch: 191, iter: 3060, lr: 0.001000, 'loss': 0.498712, 'acc': 1.0, time: 0.404
2022-09-15 16:31:07,491-INFO: epoch: 192, iter: 3080, lr: 0.001000, 'loss': 0.428753, 'acc': 1.0, time: 0.373
2022-09-15 16:31:16,654-INFO: epoch: 193, iter: 3100, lr: 0.001000, 'loss': 0.434947, 'acc': 1.0, time: 0.374
2022-09-15 16:31:27,201-INFO: epoch: 195, iter: 3120, lr: 0.001000, 'loss': 0.485586, 'acc': 1.0, time: 1.832
2022-09-15 16:31:36,403-INFO: epoch: 196, iter: 3140, lr: 0.001000, 'loss': 0.46684, 'acc': 1.0, time: 0.392
2022-09-15 16:31:45,477-INFO: epoch: 197, iter: 3160, lr: 0.001000, 'loss': 0.513497, 'acc': 1.0, time: 0.374
2022-09-15 16:31:54,520-INFO: epoch: 198, iter: 3180, lr: 0.001000, 'loss': 0.657723, 'acc': 1.0, time: 0.374
导出推理模型
In [78]
%cd ~/PaddleOCR
# 导出检测模型
!python3 tools/export_model.py \
-c configs/det/det_mv3_db.yml \
-o Global.checkpoints=./myoutput/det_db/best_accuracy \
Global.save_inference_dir=./inference/mydet_db
# 导出识别模型
!python3 tools/export_model.py \
-c configs/rec/rec_mv3_tps_bilstm_attn.yml \
-o Global.checkpoints=./myoutput/rec_RARE_atten_new/best_accuracy \
Global.save_inference_dir=./inference/myrec_rare/home/aistudio/work/PaddleOCR
2022-09-15 16:37:11,326-INFO: {'Global': {'debug': False, 'algorithm': 'DB', 'use_gpu': True, 'epoch_num': 1200, 'log_smooth_window': 20, 'print_batch_step': 20, 'save_model_dir': './myoutput/det_db/', 'save_epoch_step': 10, 'eval_batch_step': [100, 500], 'train_batch_size_per_card': 4, 'test_batch_size_per_card': 4, 'image_shape': [3, 640, 640], 'reader_yml': './configs/det/det_db_icdar15_reader.yml', 'pretrain_weights': './pretrain_models/det_mv3_db/best_accuracy', 'checkpoints': './myoutput/det_db/best_accuracy', 'save_res_path': './myoutput/det_db/predicts_db.txt', 'save_inference_dir': './inference/mydet_db'}, 'Architecture': {'function': 'ppocr.modeling.architectures.det_model,DetModel'}, 'Backbone': {'function': 'ppocr.modeling.backbones.det_mobilenet_v3,MobileNetV3', 'scale': 0.5, 'model_name': 'large'}, 'Head': {'function': 'ppocr.modeling.heads.det_db_head,DBHead', 'model_name': 'large', 'k': 50, 'inner_channels': 96, 'out_channels': 2}, 'Loss': {'function': 'ppocr.modeling.losses.det_db_loss,DBLoss', 'balance_loss': True, 'main_loss_type': 'DiceLoss', 'alpha': 5, 'beta': 10, 'ohem_ratio': 3}, 'Optimizer': {'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 0.001, 'beta1': 0.9, 'beta2': 0.999}, 'PostProcess': {'function': 'ppocr.postprocess.db_postprocess,DBPostProcess', 'thresh': 0.3, 'box_thresh': 0.7, 'max_candidates': 1000, 'unclip_ratio': 2.0}, 'TrainReader': {'reader_function': 'ppocr.data.det.dataset_traversal,TrainReader', 'process_function': 'ppocr.data.det.db_process,DBProcessTrain', 'num_workers': 1, 'img_set_dir': '../../', 'label_file_path': '../train_data_det.txt'}, 'EvalReader': {'reader_function': 'ppocr.data.det.dataset_traversal,EvalTestReader', 'process_function': 'ppocr.data.det.db_process,DBProcessTest', 'img_set_dir': '../../', 'label_file_path': '../val_data_det.txt', 'test_image_shape': [736, 1280]}, 'TestReader': {'reader_function': 'ppocr.data.det.dataset_traversal,EvalTestReader', 'process_function': 'ppocr.data.det.db_process,DBProcessTest', 'infer_img': None, 'img_set_dir': '../../', 'label_file_path': '../test_data_det.txt', 'test_image_shape': [736, 1280], 'do_eval': True}}
3 640 640
W0915 16:37:11.688948 25074 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.2, Runtime API Version: 9.0
W0915 16:37:11.693445 25074 device_context.cc:260] device: 0, cuDNN Version: 7.6.
2022-09-15 16:37:13,747-INFO: Finish initing model from ./myoutput/det_db/best_accuracy
inference model saved in ./inference/mydet_db/model and ./inference/mydet_db/params
save success, output_name_list: ['maps']
2022-09-15 16:37:16,325-INFO: {'Global': {'debug': False, 'algorithm': 'RARE', 'use_gpu': True, 'epoch_num': 200, 'log_smooth_window': 20, 'print_batch_step': 20, 'save_model_dir': './myoutput/rec_RARE_atten_new', 'save_epoch_step': 100, 'eval_batch_step': 500, 'train_batch_size_per_card': 256, 'test_batch_size_per_card': 256, 'image_shape': [3, 32, 320], 'max_text_length': 8, 'character_type': 'ch', 'character_dict_path': '../word_dict.txt', 'loss_type': 'attention', 'tps': True, 'reader_yml': './configs/rec/rec_chinese_reader.yml', 'pretrain_weights': './pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy', 'checkpoints': './myoutput/rec_RARE_atten_new/best_accuracy', 'save_inference_dir': './inference/myrec_rare', 'infer_img': None}, 'Architecture': {'function': 'ppocr.modeling.architectures.rec_model,RecModel'}, 'TPS': {'function': 'ppocr.modeling.stns.tps,TPS', 'num_fiducial': 20, 'loc_lr': 0.1, 'model_name': 'small'}, 'Backbone': {'function': 'ppocr.modeling.backbones.rec_mobilenet_v3,MobileNetV3', 'scale': 0.5, 'model_name': 'large'}, 'Head': {'function': 'ppocr.modeling.heads.rec_attention_head,AttentionPredict', 'encoder_type': 'rnn', 'SeqRNN': {'hidden_size': 96}, 'Attention': {'decoder_size': 96, 'word_vector_dim': 96}}, 'Loss': {'function': 'ppocr.modeling.losses.rec_attention_loss,AttentionLoss'}, 'Optimizer': {'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 0.001, 'beta1': 0.9, 'beta2': 0.999}, 'TrainReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../train_data_rec.txt'}, 'EvalReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../val_data_rec.txt'}, 'TestReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader'}}
W0915 16:37:16.958099 25152 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.2, Runtime API Version: 9.0
W0915 16:37:16.962687 25152 device_context.cc:260] device: 0, cuDNN Version: 7.6.
2022-09-15 16:37:19,039-INFO: Finish initing model from ./myoutput/rec_RARE_atten_new/best_accuracy
inference model saved in ./inference/myrec_rare/model and ./inference/myrec_rare/params
save success, output_name_list: ['decoded_out', 'predicts']
模型测试
In [3]
!pip install imgaugIn [4]
%cd ~/PaddleOCR
!python3 tools/infer/predict_system.py \
--image_dir="../imgtest" \
--det_model_dir="./inference/mydet_db" \
--rec_model_dir="./inference/myrec_rare" \
--rec_image_shape="3, 32, 320" \
--rec_char_type="ch" \
--rec_algorithm="RARE" \
--use_space_char False \
--max_text_length 8 \
--rec_char_dict_path="../word_dict.txt" \
--use_gpu False /home/aistudio/PaddleOCR dt_boxes num : 1, elapse : 2.805420160293579 rec_res num : 1, elapse : 0.28385162353515625 Predict time of ../imgtest/04-90_267-207&511_555&616-550&605_211&616_207&515_555&511-0_0_3_1_26_30_31_30-68-81.jpg: 3.123s 皖AD82676, 0.995 The visualized image saved in ./inference_results/04-90_267-207&511_555&616-550&605_211&616_207&515_555&511-0_0_3_1_26_30_31_30-68-81.jpg dt_boxes num : 1, elapse : 1.8948018550872803 rec_res num : 1, elapse : 0.30234551429748535 Predict time of ../imgtest/04-91_254-145&472_529&567-529&567_164&552_145&472_529&485-0_0_3_25_24_24_24_29-148-355.jpg: 2.275s 皖AD10005, 1.000 The visualized image saved in ./inference_results/04-91_254-145&472_529&567-529&567_164&552_145&472_529&485-0_0_3_25_24_24_24_29-148-355.jpg dt_boxes num : 1, elapse : 1.5868964195251465 rec_res num : 1, elapse : 0.2880706787109375 Predict time of ../imgtest/0475-90_238-143&505_599&600-599&600_186&586_143&509_577&505-0_0_3_30_25_27_27_32-60-74.jpg: 1.889s 皖AD61338, 0.999 The visualized image saved in ./inference_results/0475-90_238-143&505_599&600-599&600_186&586_143&509_577&505-0_0_3_30_25_27_27_32-60-74.jpg dt_boxes num : 1, elapse : 1.8920085430145264 rec_res num : 1, elapse : 0.2129814624786377 Predict time of ../imgtest/05-90_257-137&507_572&612-567&611_158&612_137&507_572&512-0_0_3_28_32_25_24_32-144-135.jpg: 2.119s 皖AD48108, 0.999 The visualized image saved in ./inference_results/05-90_257-137&507_572&612-567&611_158&612_137&507_572&512-0_0_3_28_32_25_24_32-144-135.jpg dt_boxes num : 1, elapse : 1.5059845447540283 rec_res num : 1, elapse : 0.19249367713928223 Predict time of ../imgtest/01-90_265-231&522_405&574-405&571_235&574_231&523_403&522-0_0_3_1_28_29_30_30-134-56.jpg: 1.779s 皖AD84566, 0.996 The visualized image saved in ./inference_results/01-90_265-231&522_405&574-405&571_235&574_231&523_403&522-0_0_3_1_28_29_30_30-134-56.jpg dt_boxes num : 1, elapse : 1.408339500427246 rec_res num : 1, elapse : 0.2727205753326416 Predict time of ../imgtest/03-103_253-267&425_483&565-483&565_271&497_267&425_480&483-0_0_3_25_25_33_25_25-110-47.jpg: 1.693s 皖AD11911, 1.000 The visualized image saved in ./inference_results/03-103_253-267&425_483&565-483&565_271&497_267&425_480&483-0_0_3_25_25_33_25_25-110-47.jpg dt_boxes num : 1, elapse : 1.2875909805297852 rec_res num : 1, elapse : 0.2051851749420166 Predict time of ../imgtest/0375-90_256-181&548_541&643-541&643_200&633_181&548_529&553-0_0_3_2_29_33_33_26-176-389.jpg: 1.506s 皖AD05992, 0.919 The visualized image saved in ./inference_results/0375-90_256-181&548_541&643-541&643_200&633_181&548_529&553-0_0_3_2_29_33_33_26-176-389.jpg dt_boxes num : 1, elapse : 1.5049629211425781 rec_res num : 1, elapse : 0.1887955665588379 Predict time of ../imgtest/0375-92_263-192&480_552&575-536&575_198&560_192&480_552&495-0_0_5_24_29_33_24_24-133-69.jpg: 1.705s 皖AF05900, 1.000 The visualized image saved in ./inference_results/0375-92_263-192&480_552&575-536&575_198&560_192&480_552&495-0_0_5_24_29_33_24_24-133-69.jpg dt_boxes num : 1, elapse : 1.393249273300171 rec_res num : 1, elapse : 0.19850969314575195 Predict time of ../imgtest/0425-88_255-205&515_553&627-528&596_205&627_224&532_553&515-0_0_3_25_27_30_33_33-72-8.jpg: 1.604s 皖AD13699, 1.000 The visualized image saved in ./inference_results/0425-88_255-205&515_553&627-528&596_205&627_224&532_553&515-0_0_3_25_27_30_33_33-72-8.jpg dt_boxes num : 1, elapse : 1.5836548805236816 rec_res num : 1, elapse : 0.19914793968200684 Predict time of ../imgtest/0475-68_277-140&493_368&683-368&570_162&683_140&590_350&493-0_0_5_25_29_32_32_30-170-444.jpg: 1.795s 皖AF15886, 0.999 The visualized image saved in ./inference_results/0475-68_277-140&493_368&683-368&570_162&683_140&590_350&493-0_0_5_25_29_32_32_30-170-444.jpg
!python tools/eval.py -c configs/rec/rec_mv3_tps_bilstm_attn.yml \
-o Global.checkpoints=./myoutput/rec_RARE_atten_new/best_accuracy2022-09-15 16:39:43,444-INFO: {'Global': {'debug': False, 'algorithm': 'RARE', 'use_gpu': True, 'epoch_num': 200, 'log_smooth_window': 20, 'print_batch_step': 20, 'save_model_dir': './myoutput/rec_RARE_atten_new', 'save_epoch_step': 100, 'eval_batch_step': 500, 'train_batch_size_per_card': 256, 'test_batch_size_per_card': 256, 'image_shape': [3, 32, 320], 'max_text_length': 8, 'character_type': 'ch', 'character_dict_path': '../word_dict.txt', 'loss_type': 'attention', 'tps': True, 'reader_yml': './configs/rec/rec_chinese_reader.yml', 'pretrain_weights': './pretrain_models/rec_mv3_tps_bilstm_attn/best_accuracy', 'checkpoints': './myoutput/rec_RARE_atten_new/best_accuracy', 'save_inference_dir': './inference/newimg_rec_rare', 'infer_img': None}, 'Architecture': {'function': 'ppocr.modeling.architectures.rec_model,RecModel'}, 'TPS': {'function': 'ppocr.modeling.stns.tps,TPS', 'num_fiducial': 20, 'loc_lr': 0.1, 'model_name': 'small'}, 'Backbone': {'function': 'ppocr.modeling.backbones.rec_mobilenet_v3,MobileNetV3', 'scale': 0.5, 'model_name': 'large'}, 'Head': {'function': 'ppocr.modeling.heads.rec_attention_head,AttentionPredict', 'encoder_type': 'rnn', 'SeqRNN': {'hidden_size': 96}, 'Attention': {'decoder_size': 96, 'word_vector_dim': 96}}, 'Loss': {'function': 'ppocr.modeling.losses.rec_attention_loss,AttentionLoss'}, 'Optimizer': {'function': 'ppocr.optimizer,AdamDecay', 'base_lr': 0.001, 'beta1': 0.9, 'beta2': 0.999}, 'TrainReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../train_data_rec.txt'}, 'EvalReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader', 'num_workers': 8, 'img_set_dir': '../..', 'label_file_path': '../val_data_rec.txt'}, 'TestReader': {'reader_function': 'ppocr.data.rec.dataset_traversal,SimpleReader'}}
W0915 16:39:44.065701 25553 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 70, Driver API Version: 11.2, Runtime API Version: 9.0
W0915 16:39:44.070394 25553 device_context.cc:260] device: 0, cuDNN Version: 7.6.
2022-09-15 16:39:46,158-INFO: Finish initing model from ./myoutput/rec_RARE_atten_new/best_accuracy
2022-09-15 16:39:47,598-INFO: Eval result: {'avg_acc': 0.8311688311688312, 'total_acc_num': 832, 'total_sample_num': 1001}
测试集部分识别结果展示

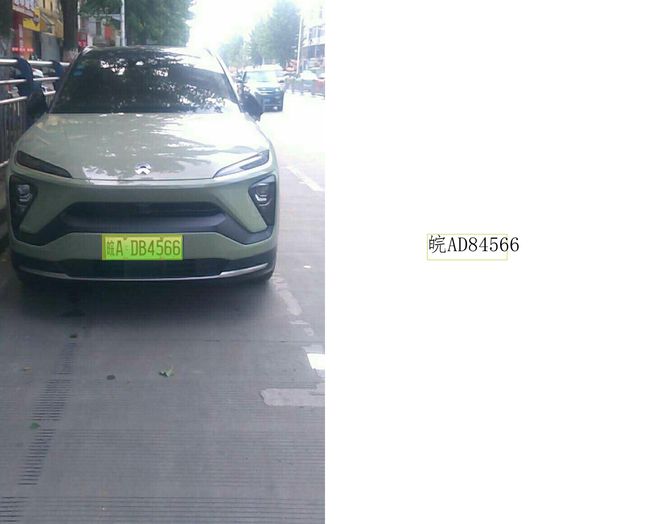
车牌识别项目小结:
基于Paddleocr完成深度学习车牌识别,项目分为车牌检测与车牌识别两部分,最终完整实现车牌识别目的,可以识别大部分车牌结果。针对本项目的识别准确度,后续优化可以增加数据增强方面内容、更换其他主干网络及对应参数调优,大家可以在此项目基础上进行扩充,欢迎评论区一起讨论!
项目分工:
Go_AI -- 模型训练及主代码编写 main.ipynb
天下一笑奈何 ---数据集整理与格式转换 Data.txt
Studio2213197-- Readme编写与整理 Readme.txt
三、 基于Yolov5的车辆检测
项目介绍
- 车辆检测技术大量应用于高速公路的监控设备中,可以进行车辆监控、车流量统计。本次主要使用YOLOV5检测网络对车辆进行检测,并且在残差单元中嵌入卷积注意力模块,强化学习细节特征,抑制冗余信息干扰。然后,将卷积注意力融入金字塔网络中用以区分不同重要信息,加强关键特征融合。在车辆VOC车辆数据集上进行实验,mAP达到0.79,左图为车辆检测效果。

数据集介绍
本数据集来源于百度飞浆公开数据集,数据集格式是xml格式的数据集,包含20522张图片,每张图片中标注了图中车辆的位置信息,使用xml格式进行标注。有car、van、bus等几类车型。

• 基于YOLov5和Paddle实现车辆检测,原项目借鉴链接,并在此基础上进行修改配置文件及数据集。
• 本项目提供3个预训练模型,分别为YOLOv5s、YOLOv5m、YOLOv5l,如果需要其他模型请在百度云盘下载code:dng9,并上传到相应文件夹,并修改训练评估命令
• 本项目车辆分为4类,分别为car、bus、van、others
项目流程
首先进行数据预处理,将数据集转换成YOLOV5标准格式,转换完成后将数据输入YOLOV5网络进行训练,经过测试,训练轮数为30轮时即可达到不错的检测精度。设置batchsize为128,网络的输入图片的尺寸为640*640。训练完成后mAP可以达到0.79。训练完成后进行检测,效果如图。
效果图

项目总结:
首先,构建交通流通流量预测模块。使用车流量相关数据,运用机器学习算法与深度学习算法按照不同时间对道路车流量进行流量预测。从侧解决交通拥堵问题,提示人们订制合理的出行计划,同时有利于交通部门规划交通政策。利
其次,运用计算机视觉技术构建智慧交通模块。从全局与个体角度出发,其一,通过车辆检测技术实现全局交通流量统计与监控,用于辅助交通流量预测;其二,通过车牌识别技术对个体违规车辆进行定位与认证,融合打造交通合理化分析系统。
作者博客:CSDN主页 (专注大数据与人工智能知识分享,欢迎关注!)
项目链接:基于Paddle的智慧交通预测系统 - 飞桨AI Studio
项目参考:https://aistudio.baidu.com/aistudio/projectdetail/739559