ShuffleNet V2(2018 CVPR)
| 论文标题 | ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design |
|---|---|
| 论文作者 | Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, Jian Sun |
| 发表日期 | 2018年07月01日 |
| GB引用 | > Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, et al. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design[J]. Lecture Notes in Computer Science, 2018, 11218: 122-138. |
| DOI | 10.1007/978-3-030-01264-9_8 |
论文地址:https://arxiv.org/pdf/1807.11164
摘要
本文主要介绍了深度卷积神经网络(CNN)架构设计中的两个原则:直接指标(如速度)应该优先于间接指标(如计算复杂度),并且这些指标应该在目标平台上进行评估。作者通过分析现有CNN结构的速度和准确率表现,并提出了四个实用的设计指南,包括增加通道数、减少通道数、使用残差连接以及采用空间填充卷积等。基于这些指南,作者提出了一种新的CNN结构——ShuffleNet V2,在GPU和ARM平台上进行了验证实验,结果表明该结构比之前的网络更快速且准确率更高。本文的研究成果对于实际应用中高效CNN架构的设计具有重要意义。
全文摘要
- 直接指标比间接指标更重要:在神经网络的设计中,传统上使用浮点运算次数(FLOPs)作为衡量计算复杂度的间接指标,但这并不足以反映实际性能。论文强调应关注目标平台的直接指标,例如速度、延迟等。
- 新的设计原则:作者基于对现有高效网络的性能分析,提出了四条设计指南:
- 保持输入输出通道数的平衡,以减少内存访问成本(MAC)。
- 在使用组卷积时,注意不会引入过高的内存访问成本。
- 避免网络的过度碎片化,因为这会降低并行处理的效率。
- 认识到元素级操作(如ReLU、加法等)在运行时的影响。
- ShuffleNet V2的设计与实验:根据上述指南,作者设计了ShuffleNet V2。新架构在多个层级的计算复杂度下,实现了比之前的ShuffleNet V1和MobileNet V2更高的速度和准确率。特别是在低计算预算条件下,ShuffleNet V2对移动设备具有更好的适应性和性能表现。
- 实用性与行业应用:研究不仅基于理论推导,还通过在不同平台(GPU和ARM)上进行的实验验证了设计指南的有效性,为实际应用提供了重要参考。
研究问题
如何在考虑直接指标(如速度)的情况下设计高效的神经网络架构?
研究方法
实验研究: 通过在两个广泛采用的硬件平台上进行一系列控制实验,验证了所提出的网络架构设计指南,并提出了一个新的网络结构称为ShuffleNet V2。
比较研究: 对比了ShuffleNet V2与其他几种轻量级神经网络架构(如MobileNet v2、Xception等)在不同计算复杂度下的性能,展示了ShuffleNet V2在速度和准确性方面的优越性。
混合方法研究: 结合了理论分析与实际实验,不仅分析了不同网络结构的设计原则,还通过具体的实现和优化来验证这些原则的有效性。
研究思路
这篇论文的研究思路主要集中在深度卷积神经网络(CNN)的高效架构设计,强调直接度量(如速度)而非间接度量(如FLOPs)在实际应用中的重要性。
理论基础:
该研究基于深度学习领域中已有的许多前沿网络架构,尤其是轻量级神经网络(如ShuffleNet、MobileNet等)的设计思想。论文指出,传统的方法大多依赖于FLOPs(浮点运算次数)作为网络复杂度的衡量标准,而FLOPs虽然是一个重要的性能指标,但并不反映实际的运行速度或延迟,因此,研究强调直接度量如推理速度的重要性。
模型:
-论文提出了一种新的网络架构,名为ShuffleNet V2。该模型通过引入新的操作(如channel split)、对构建块进行优化,以实现更高效的特征通道管理和信息流动。ShuffleNet V2通过增加模型容量(例如使用更多的特征通道)来提高识别精度,同时保持低的计算复杂度。
实验设计: 论文进行了一系列控制实验,对比不同网络架构(如ShuffleNet v1、MobileNet v2等)的运行时间与速度,并对不同参数设置(如输入通道比例、分组卷积数量等)对网络性能的影响进行了定量分析。
指导原则:
通过实验,论文总结出四个实用的设计指导原则(G1至G4)以优化网络设计,具体包括:
- G1: 使用均衡的通道宽度以最小化内存访问成本(MAC)。
- G2:过多的分组卷积会增加内存访问成本。
- G3: 网络碎片化会降低并行化度,影响运行速度。
- G4: 元素级操作需要被重视,因为它们的运行时间占比较高。
高效网络设计实用指南
我们的研究是在两种广泛采用的硬件上进行的,它们具有行业级的卷积神经网络 (CNN) 库优化。我们注意到我们的 CNN 库比大多数开源库更有效率。因此,我们可以确保我们的观察结果和结论对工业实践具有重要性和实质性意义。
GPU。使用单个NVIDIA GeForce GTX 1080Ti。卷积库为CUDNN 7.0 [23]。我们还启用了CUDNN的基准测试功能,以选择不同卷积的最佳算法。
ARM。高通骁龙810。我们使用基于 Neon 的高度优化实现。单线程用于评估。
其他设置包括:打开所有优化选项(例如张量融合,用于减少小操作的开销)。 输入图像大小为 224×224。 每个网络都是随机初始化并评估了 100 次。 使用平均运行时间。
为了开展我们的研究,我们分析了两个最先进的网络ShuffleNet v1 [15] 和MobileNet v2 [14] 的运行时间性能。它们在ImageNet分类任务上都具有很高的效率和准确性。它们都被广泛用于低端设备,如移动设备。尽管我们只分析了这两个网络,但我们注意到它们代表了当前的趋势。它们的核心是组卷积和深度卷积,这也是其他一些最先进的网络(例如ResNeXt [7]、Xception [12]、MobileNet [13] 和CondenseNet [16])的关键组件。
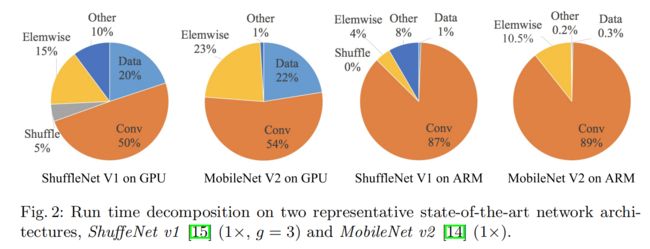
如图 2 所示,整体运行时间被分解为不同的操作。请注意,浮点运算 (FLOPS) 指标仅考虑卷积部分。尽管这部分消耗了大部分时间,但其他操作(包括数据输入/输出、数据洗牌和元素级操作(AddTensor、ReLU 等)也占用了相当多的时间。因此,浮点运算是对实际运行时间的足够准确的估计。
根据这一观察,我们从多个方面对运行时(速度)进行了详细的分析,并为高效网络架构设计提供了几个实用的指导原则。
G1)等通道宽度可以最小化内存访问成本(MAC)。现代网络通常采用深度可分离卷积[12,13,15,14],其中大多数复杂性来自逐点卷积(即 1×1 卷积)[15]。我们研究了 1×1 卷积核的形状。该形状由两个参数指定:输入通道数 c 1 c_1 c1和输出通道数 c 2 c_2 c2。假设特征图的空间大小为 h × w h×w h×w,则 1×1 卷积的浮点运算次数为 B = h w c 1 c 2 B=hwc_1c_2 B=hwc1c2。
为了简化问题,我们假设计算设备中的缓存足够大以存储完整的特征图和参数。因此,内存访问成本(MAC),或内存访问操作次数,为 M A C = h w ( c 1 + c 2 ) + c 1 c 2 \mathrm{MAC}=hw(c_1+c_2)+c_1c_2 MAC=hw(c1+c2)+c1c2。注意这两个术语分别对应于输入/输出特征图和内核权重的内存访问。
从均值不等式,我们有
M A C ≥ 2 h w