【论文笔记_在线蒸馏、GAN】Online Multi-Granularity Distillation for GAN Compression

2021年。
摘要
生成性对抗网络(GAN)在生成优秀图像方面取得了巨大的成功,但是,由于计算成本高,内存使用量大,在资源有限的设备上部署GAN非常困难。尽管最近压缩GAN的努力取得了显著的成果,但它们仍然存在潜在的模型冗余,可以进一步压缩。为了解决这个问题,我们提出了一种新的在线多粒度蒸馏(OMGD)方案来获得轻量级的GAN,这有助于以较低的计算需求生成高保真图像。我们首次尝试将单级在线蒸馏推广到面向GAN的压缩,逐步升级的教师生成器有助于改进基于无鉴别器的学生生成器。互补的教师生成器和网络层提供了全面和多粒度的概念,以从不同维度增强视觉逼真度。在四个基准数据集上的实验结果表明,OMGD成功地在Pix2Pix和CycleGAN上压缩了40×MAC和82.5×参数,并且没有图像质量损失。这表明OMGD为在资源受限的设备上部署实时图像翻译提供了一个可行的解决方案。我们的代码和模型在以下网站公开:https://github.com/bytedance/OMGD
1.介绍
现有的压缩算法主要存在三个问题。首先,他们倾向于直接采用成熟的模型压缩技术[7,63,19],这些技术不是针对GAN定制的,也缺乏对GAN复杂特性和结构的探索。其次,他们通常将GAN压缩描述为一项多阶段任务。例如,[30]需要按顺序进行预训练、蒸馏、进化和微调。基于蒸馏的方法[30,31,13,9,8,49,24]应该预先训练教师生成器,然后蒸馏学生生成器。端到端方法对于减少多阶段设置中的复杂时间和计算资源至关重要。第三,目前最先进的方法仍然负担着高昂的计算成本。例如,最佳机型[31]需要3G Mac,这对于部署在轻量级边缘设备上来说要求相对较高。
为了克服上述问题,我们提出了一种新的在线多粒度蒸馏(OMGD)框架,用于学习高效的GAN。我们放弃了复杂的多级压缩过程,设计了一种面向GAN的在线蒸馏策略,一步获得压缩模型。我们可以从多个层次和粒度中挖掘潜在的互补信息,以帮助优化压缩模型。这些概念可以被视为辅助监督线索,对于突破低计算成本模型的容量瓶颈至关重要。OMGD的贡献总结如下:
1.据我们所知,我们首次尝试将蒸馏推广到GAN压缩领域的在线方案,并在无鉴别器和无事实依据的环境中优化学生生成器。该方案对教师和学生进行交替培训,反复渐进地推广这两个生成器。逐步优化的教师生成器帮助学生热身,并逐步引导优化方向。
2.我们进一步从两个角度将在线蒸馏策略扩展为多粒度方案。一方面,我们采用不同的基于结构的教师生成器,从更多样化的维度捕捉更多互补线索,提高视觉逼真度。另一方面,除了输出层的概念外,我们还将通道粒度信息从中间层传输到其他监控信号。
3.在广泛使用的数据集(如马)上进行大量实验→斑马[66],夏天→冬天[66],边缘→shoes[60]和cityscapes[12])证明,OMGD可以将两个基本条件GAN模型(包括pix2pix[23]和CycleGAN[66])的计算量减少40倍,而不会损失生成图像的视觉保真度。它揭示了OMGD对于各种基准数据集、不同的条件GAN、网络架构以及问题设置(成对或不成对)是高效和健壮的。与现有的竞争方法相比,OMGD有助于以更少的计算成本获得更好的图像质量(见图1和图2)。此外,OMGD 0.5×(仅需要0.333G Mac)的成功实现了令人印象深刻的结果,这为在资源受限的设备上部署提供了可行的解决方案,甚至打破了移动设备上实时图像翻译的障碍。

图2:OMGD和现有竞争方法(包括GAN压缩[30]、CA T[24]、DMAD[31]、GAN瘦身[49]、AutoGAN蒸馏器[13]和协同进化[45])之间的性能权衡,方形表示U型网络样式生成器,以及⭐是Res-Net风格。OMGD的计算成本大大低于这些方法。“基线”表示模型是用朴素的方法训练的。
2.相关工作
2.1GAN和GAN压缩
生成性对抗网络[16]在一系列计算机视觉任务上取得了令人印象深刻的成果,例如图像到图像的翻译[66,23,10,26,11,47,35],图像生成[39,40,34,64,5,4]和图像修复[36,58,48,62]。 尤其是Pix2Pix[23]在生成器和鉴别器之间进行最小-最大博弈,以使用成对的训练数据进行图像到图像的转换。CycleGAN[66]进一步扩展了GANs在弱监督环境下的图像翻译能力,在这种环境下,在训练阶段没有利用成对数据。尽管各种GAN方法最近取得了令人印象深刻的成功,但它们往往会占用越来越多的内存和计算成本[10,35,5],以支持其强大的性能,这与在资源受限设备上的部署相冲突。
近年来,面向GAN的压缩由于其在轻量级设备部署领域的潜在应用而成为一项重要任务。Shu等人[45]提出了关于引入共同进化算法以去除冗余滤波器以压缩CycleGAN的第一个初步研究。Fu等人[13]采用AutoML方法,并在目标计算资源约束的指导下搜索一个高效的生成器。Wang等人[49]提出了一个统一的GAN压缩优化框架,包括模型提取、通道修剪和量化。Li等人[30]设计了一个“一次性”生成器,通过权重共享将模型训练和架构搜索解耦。Li等人[31]提出了一种可微掩模和共同注意提取算法来学习有效的GAN。Jin等人[24]提出了一种一步剪枝算法,从教师模型中搜索学生模型。在这项工作中,我们设计了一个在线多粒度蒸馏(OMGD)方案。通过引入多粒度知识指导,学生生成器可以通过利用来自不同教师和层次的互补概念来增强,这从本质上提高了压缩模型的容量。
2.2知识蒸馏
知识蒸馏(KD)[19]是一种基本的压缩技术,在更大的教师模型或集合[6]的有效信息传递和监督下,对较小的学生模型进行优化。Hinton[19]通过最小化学生和教师网络之间的输出分布统计数据之间的距离来进行知识蒸馏。通过这种方式,学生网络试图学习dark知识[19],这些知识包含不同班级之间的相似性,这是真实标签无法提供的。Romero等人[41]进一步利用了中间层的特征映射概念来提高学生网络的性能。Zhou等人[65]提出,特征图的每个通道对应一个视觉模式,因此他们专注于从中间层的每个通道转移特征图的注意概念[53,54,55]。
此外,You等人[59]发现,多个教师网络可以为学习更有效的学生网络提供更全面的知识。MEIN[44]将大型复杂的培训团队压缩成一个单一的网络,该网络采用基于对抗的学习策略来引导预定义的学生网络从教师模型中转移知识。离线知识蒸馏需要在优化阶段建立一个经过预训练的教师模型,而在线KD同时优化教师和学生网络,或者仅仅优化一组学生同伴[51]。Anil等人[2]并行训练了两个结构相同的网络,这两个网络反复扮演学生和教师的角色。在本文中,我们采用了基于多粒度的在线蒸馏方案,旨在从教师生成器的互补结构和不同层次的知识中学习有效的学生模型。
3.策略
在本节中,我们首先介绍提出的在线GAN蒸馏框架,其中学生生成器不受鉴别器的约束,并尝试直接从教师模型学习概念。第3.2节介绍了多粒度蒸馏方案。多粒度概念[32]是通过互补的教师生成器和不同层次的知识获取的。我们在图3中展示了OMGD框架的整个流程。
3.1在线的GAN蒸馏
最近,一系列基于蒸馏的GAN压缩[30,31,13,9,8,49]采用了离线蒸馏方案,该方案利用预先培训的教师生成器优化学生生成器。在本文中,我们提出了一种面向信息的在线蒸馏算法来解决离线蒸馏中的三个关键问题。首先,传统离线蒸馏方法中的学生生成器应保持一定的容量,以保持与鉴别器的动态平衡,以避免模型崩溃[37,43]和梯度消失[3]。然而,我们的学生生成器不再与鉴别器紧密结合,鉴别器可以更灵活地训练并获得进一步的压缩。其次,预先培训的教师生成器无法引导学生逐步学习信息,并且容易导致在培训阶段过度拟合[17,27]。尽管如此,我们的教师生成器帮助预热学生生成器,并逐步引导优化方向。第三,由于评估指标是主观的,因此选择合适的预培训教师生成器并非易事[43]。然而,我们的方法不需要预先训练模型,这个选择问题就解决了。
教师生成器:我们遵循[23,66]中的损失函数和训练设置来训练教师生成器GT和鉴别器D。GT旨在学习一个函数,将数据从源域X映射到目标域Y。我们以Pix2Pix(23)为例,使用配对数据
(![]() ,其中xi∈ X和yi∈ Y)优化网络。生成器GT用于训练使xi映射到yi,而训练器D训练以区分GT生成的假图像与真实图像。目标形式化为:
,其中xi∈ X和yi∈ Y)优化网络。生成器GT用于训练使xi映射到yi,而训练器D训练以区分GT生成的假图像与真实图像。目标形式化为:

此外,引入了重构损失,以使GT的输出接近真实标签y:
![]()
GAN环境中的整体目标定义为:
![]()
学生生成器。在所提出的面向GAN的在线蒸馏方案中,学生生成器GS仅利用教师网络GT进行优化,并且可以在无鉴别器的环境中进行训练。GS的优化不需要同时使用真实标签y。也就是说,GS只学习具有类似结构(GT)的大容量生成器的输出,这大大降低了直接拟合y的难度。具体来说,我们在每个迭代步骤中反向传播GT和GS之间的蒸馏损失。通过这种方式,GS可以模仿GT的训练过程,逐步学习。
将GT/GS的输出表示为pt/ps,我们使用结构相似性(SSIM)损失[52]和感知损失[25]来衡量pt和ps之间的差异。SSIM损失[52]对局部结构变化敏感,这与人类视觉系统(HVS)类似。给定ps、pt、SSIM Loss,通过以下方式计算两幅图像的相似性:

其中,µs、µt是亮度估计的平均值,σ2s、σ2t是对比度的标准偏差,σts是结构相似性估计的协方差。C1、C2是避免分母为零的常数。
感知损失[25]包括特征重建损失Lfeature和风格重建损失Lstyle。Lfeature鼓励pt和ps具有类似的特征表示,这些特征表示由预先训练的VGG网络[46]测量。Lfeature正式定义为:
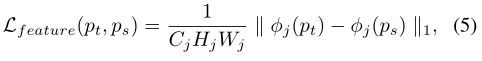
其中φj(x)是输入x的第j层φ的激活。Cj×Hj×Wj是φj(x)的尺寸。
引入Lstyle是为了减少风格特征的差异,例如颜色、纹理、常见图案等[14]。Lstyle可计算为:
![]()
其中Gφj(x)是VGG网络中第j层激活的Gram矩阵。
此外,引入总变化损失L T V[42]来提高生成图像的空间平滑度。我们使用四个超参数λSSIM、λfeature、λstyle、λTV来实现上述损失之间的平衡,因此总的在线KD损失LKD(pt,ps)通过以下公式计算:


图3:在线多粒度蒸馏框架的管道。学生生成器GS仅利用互补的教师生成器(GWT和GDT)进行优化,并且可以在无鉴别器和无背景真相的环境中进行培训。该框架从中间层和输出层转移不同层次的概念,进行知识提炼。整个优化是在在线蒸馏方案上进行的。也就是说,GWT、GDT和GS是同时逐步优化的。
3.2多粒度蒸馏方案
基于新颖的在线GAN蒸馏技术,我们进一步从两个角度将我们的方法扩展为多粒度方案:教师生成器的互补结构和来自不同层次的知识。在线多粒度蒸馏(OMGD)框架的整个流程如图3所示,我们使用更广泛的教师生成器GWT和更深入的教师生成器GDT来形式化GS的多目标优化任务。除了教师生成器的输出层,我们还通过通道蒸馏损失从中间层挖掘知识概念[65]。
多教师蒸馏。基于不同结构的教师生成器有助于从真实标签中捕捉更多互补的图像线索,并从不同角度提高图像翻译性能[59]。此外,多教师蒸馏设置可以进一步缓解过度拟合的问题。我们从深度和宽度两个互补维度将学生模型扩展为教师模型。给定一个学生生成器GS,我们扩展了GS的通道以获得更宽的教师生成器GWT。具体而言,卷积层的每个通道乘以通道扩展因子η。另一方面,我们在每个下采样和上采样层之后插入几个resnet块到GS中,以构建更深层的教师生成器GDT,其容量与GWT相当。
如图3所示,部分共享鉴别器被设计为共享前几层,并分离两个分支,以分别获得GWT和GDT的鉴别器输出。这种共享设计不仅提供了鉴别器的高度灵活性,而且还利用了输入图像的相似特性来改进生成器的训练[20]。我们直接将互补教师生成器提供的两个蒸馏损失合并为多教师设置中的KD损失:
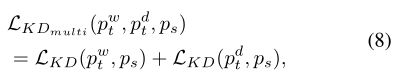
其中,pwt和pdt分别是GWT和GDT输出层的激活。
中间层蒸馏。输出层的概念没有考虑到教师网络的更多中间细节,因此我们进一步传输通道粒度信息,作为额外的监督信号,以促进GS。具体来说,我们计算通道方向的注意力权重[22,65],以测量特征图中每个通道的重要性。注意权重wc的定义如下:
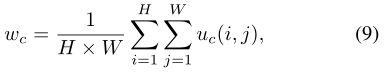
其中uc表示特征图的第c个通道。然后将一个1×1卷积层连接到GS的中间层,以扩展通道数,通道蒸馏(CD)损失计算如下:

其中n是要采样的特征映射的数量,c是特征映射的通道数量。wij是第i个特征图的第j个通道的注意权重。 综上所述,整个在线多粒度蒸馏目标形式化为:
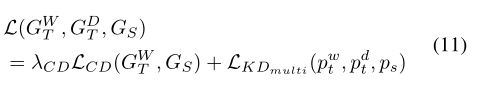
4.实验
见原文。