论文阅读:Dehaze-GLCGAN: Unpaired Single Image Dehazing Via Adversarial Training

目录
- 1. 摘要
- 2. 网络结构
-
- 2.1 整体结构
- 2.1 网络详情
-
- 1) 生成器
- 2) 判别器
- 3. 损失函数
-
- 3.1 对抗损失
- 3.2 循环一致性损失
- 3.3 颜色损失
- 3.4 循环感知损失
- 3.5 总损失
- 4. 读后感
1. 摘要
本文提出了一个名为Global-Local Cycle-consistent Generative Adversarial Network(Dehaze-GLCGAN)的去雾网络。该网络包含两个生成器和四个判别器。两个生成器分别用于从雾图产生去雾图和从无雾图产生雾图。四个判别器,两个为全局判别器,两个为局部判别器。全局判别器用于判别整张图像,局部判别器用于判别局部图像块。
2. 网络结构
2.1 整体结构
网络的整体结构如图1:

领域 A A A为雾图,领域 B B B为无雾图。 G A G_A GA用于将 A A A的图像转换成 B B B的图像, G B G_B GB用于将 B B B的图像转换成 A A A的图像。 D A g l o b a l D_A^{global} DAglobal用于判断一张雾图是从A中取样的还是 G B G_B GB生成的, D B g l o b a l D_B^{global} DBglobal用于判断一张无雾图是从B中取样的还是 G A G_A GA生成的。 D A l o c a l D_A^{local} DAlocal用于判断一个局部雾图块是从A中取样裁剪的还是 G B G_B GB生成的雾图裁剪的, D B l o c a l D_B^{local} DBlocal用于判断一个局部无雾图块是从B中取样裁剪的还是 G A G_A GA生成的无雾图裁剪的。
局部块是从图像中随机裁剪的5个大小为64×64的块。通过消融实验,证实了添加 D A l o c a l D_A^{local} DAlocal和 D B l o c a l D_B^{local} DBlocal的效果更好。
2.1 网络详情
两个生成器使用相同的网络框架,同样所有的生成器也是使用相同的网络框架,只不过输入的图像尺寸不同。
1) 生成器
G A G_A GA框架如图2所示。
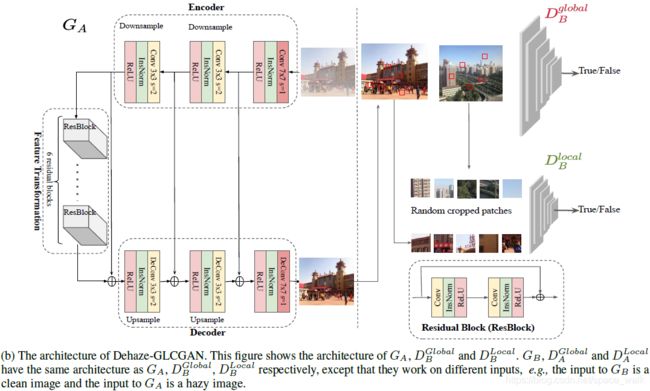
G A G_A GA有三个模块,分别是编码器,特征转换器和解码器。编码器中首先是一个卷积层外带实例标准化和ReLU激活函数,接着是两个下采样块。特征转换器包含了六个残差块,残差块如图2右下角所示。编码器首先时两个用反卷积层的上采样块,和编码器是镜像结构。
G B G_B GB与 G A G_A GA有着相同的框架。
2) 判别器
图2右边部分展示了 D B g l o b a l D_B^{global} DBglobal和 D B l o c a l D_B^{local} DBlocal。 D A g l o b a l D_A^{global} DAglobal和 D B g l o b a l D_B^{global} DBglobal有着相同的框架, D A l o c a l D_A^{local} DAlocal和 D B l o c a l D_B^{local} DBlocal有相同的框架。全局判别器在雾不均匀的图像上会判别失败,所以才引入了局部判别器用于判别从图像随即裁剪的局部图像块。
3. 损失函数
3.1 对抗损失
全局判别器损失:
L D G l o b a l = E x r ∼ P r e a l [ ( D ( x r ) − 1 ) 2 ] + E x f ∼ P f a k e [ ( D ( x f ) − 0 ] ) 2 ] (1) \left.L_{D}^{G l o b a l}=E_{x_{r} \sim P_{r e a l}}\left[\left(D\left(x_{r}\right)-1\right)^{2}\right]+E_{x_{f} \sim P_{f a k e}}\left[\left(D\left(x_{f}\right)-0\right]\right)^{2}\right] \tag{1} LDGlobal=Exr∼Preal[(D(xr)−1)2]+Exf∼Pfake[(D(xf)−0])2](1)
全局生成器损失:
L G G l o b a l = E x r ∼ P f a k e [ ( D ( x f ) − 1 ) 2 ] (2) L_{G}^{G l o b a l}=E_{x_{r} \sim P_{f a k e}}\left[\left(D\left(x_{f}\right)-1\right)^{2}\right] \tag{2} LGGlobal=Exr∼Pfake[(D(xf)−1)2](2)
局部判别器损失:
L D L o c a l = E x r ∼ P r e a l − p a t c h e s [ ( D ( x r ) − 1 ) 2 ] + E x f ∼ P f a k e − p a t c h e s [ ( D ( x f ) − 0 ) 2 ] (3) L_{D}^{L o c a l}=E_{x_{r} \sim P_{r e a l-p a t c h e s}}\left[\left(D\left(x_{r}\right)-1\right)^{2}\right]+E_{x_{f} \sim P_{f a k e-p a t c h e s}}\left[\left(D\left(x_{f}\right)-0\right)^{2}\right] \tag{3} LDLocal=Exr∼Preal−patches[(D(xr)−1)2]+Exf∼Pfake−patches[(D(xf)−0)2](3)
局部生成器损失:
L G L o c a l = E x f ∼ P f a k e − p a t c h e s [ ( D ( x f ) − 1 ) 2 ] (4) L_{G}^{L o c a l}=E_{x_{f} \sim P_{f a k e-p a t c h e s}}\left[\left(D\left(x_{f}\right)-1\right)^{2}\right] \tag{4} LGLocal=Exf∼Pfake−patches[(D(xf)−1)2](4)
3.2 循环一致性损失
循环一致性损失如下。具体看这篇博客。
L c y c l e ( G A , G B ) = E x ∼ p data ( x ) [ ∥ ( G B ( G A ( x ) ) − x ) ∥ ] 1 + E y ∼ p data ( y ) [ ∥ ( G A ( G B ( y ) ) − y ) ∥ ] 1 (5) \begin{aligned} L_{c y c l e}\left(G_{A}, G_{B}\right)=& \ E_{x \sim p_{\text {data}(x)}}\left[\left\|\left(G_{B}\left(G_{A}(x)\right)-x\right)\right\|\right]_{1} \\ +&\ E_{y \sim p_{\text {data}(y)}}\left[\left\|\left(G_{A}\left(G_{B}(y)\right)-y\right)\right\|\right]_{1} \end{aligned} \tag{5} Lcycle(GA,GB)=+ Ex∼pdata(x)[∥(GB(GA(x))−x)∥]1 Ey∼pdata(y)[∥(GA(GB(y))−y)∥]1(5)
3.3 颜色损失
颜色损失如下:
L c o l o r ( A , B ) = ∥ ( A b l u r r e d − B b l u r r e d ) ∥ 2 2 (6) L_{ {color}}(A, B)=\left\|\left(A_{ {blurred}}-B_{{blurred}}\right)\right\|_{2}^{2} \tag{6} Lcolor(A,B)=∥(Ablurred−Bblurred)∥22(6)
其中 A A A和 B B B分别为增强图像和无雾图像, A b l u r r e d A_{blurred} Ablurred和 B b l u r r e d B_{blurred} Bblurred分别为 A A A和 B B B经过高斯模糊处理后的图像。
文中说该损失用于测量增强图像(Enhance image)和无雾图像(haze-free image)之间的差距,但是没有说该增强图像是什么。 颜色损失在《Dslr-quality photos on mobile devices with deep convolutional networks》这篇文章中提出,文章是关于图像复原的,所以有增强图像。但是本文中,我不太清楚这个增强图像具体指什么。两种猜测:
第一,增强图像是指去雾图像,但是本文是无配对图像对的数据集,所以并不存在雾图的Ground-Truth。
第二,去除一张无雾图像 y y y,增强图像指的是 G A ( G B ( y ) ) G_A(G_B(y)) GA(GB(y))。这和循环一致性损失相似。
但是感觉都不对,以后如果看懂了会回来补充的。
3.4 循环感知损失
循环感知损失如下。具体看这篇博客。
L o s s C P ( I h ) = 1 W i , j H i , j ∑ x = 1 W i , j ∑ y = 1 H i , j ( σ i , j ( I h ) − σ i , j ( G ( I h ) ) ) 2 (7) {Loss}_{C P}\left(I_{h}\right)=\frac{1}{W_{i, j} H_{i, j}} \sum_{x=1}^{W_{i, j}} \sum_{y=1}^{H_{i, j}}\left(\sigma_{i, j}\left(I_{h}\right)-\sigma_{i, j}\left(G\left(I_{h}\right)\right)\right)^{2} \tag{7} LossCP(Ih)=Wi,jHi,j1x=1∑Wi,jy=1∑Hi,j(σi,j(Ih)−σi,j(G(Ih)))2(7)
本文中使用的是在ImageNet Dataset上预训练好的VGG-16中第2和第5池化层提取出的特征图。
3.5 总损失
Dehaze-GLCGAN的总损失函数定义如下:
L o s s t o t a l = L global G A N + L local G A N + L global Cycle + L local Cycle + L global C P + L local C P + L global color + L local color (8) \begin{aligned} {Losstotal}=& \ L_{\text {global}}^{G A N}+L_{\text {local}}^{G A N}+L_{\text {global}}^{\text {Cycle}}+L_{\text {local}}^{\text {Cycle}} \\ +& \ L_{\text {global}}^{C P}+L_{\text {local}}^{C P}+L_{\text {global}}^{\text {color}}+L_{\text {local}}^{\text {color}} \end{aligned} \tag{8} Losstotal=+ LglobalGAN+LlocalGAN+LglobalCycle+LlocalCycle LglobalCP+LlocalCP+Lglobalcolor+Llocalcolor(8)
4. 读后感
除了生成器的框架,本文其余部分基本来自其他论文。判别器框架和局部判别器思想来自《Enlightengan: Deep light enhancement without paired supervision》,对抗损失来自《Least squares generative adversarial networks》,循环一致性损失和循环感知损失来自《Cycle-Dehaze: Enhanced CycleGAN for Single Image Dehazing》,颜色损失来自《Dslr-quality photos on mobile devices with deep convolutional networks》。