FreeDOM —— 一个可迁移的网页信息抽取模型
⬆⬆⬆ 点击蓝字
关注我们
AI TIME欢迎每一位AI爱好者的加入!
在网页中抽取结构化信息是一种非常重要的知识获取(Knowledge Discvoery)方式。为了构建一个领域的知识图谱,往往需要从涉及这个领域的众多网站中抽取结构化信息,从而促进知识库的补全和扩展。然而,每个网站都有不同的结构和对应的抽取规则(wrapper),如果用人力来编写每个网页独自使用的规则,那么效率会大打折扣。为此,提出了一个可迁移的信息抽取模型,FreeDOM。它可以只用很少的初始标注网站数据,自动扩展到同领域的其他网站。该模型在公开数据集SWDE上得到了最优的效果且不需要渲染网页得到的视觉特征,更加轻便。

林禹臣,美国南加州大学(USC)计算机系三年级博士生,导师为Xiang Ren教授。研究方向为自然语言处理与人工智能方向的应用。专注在信息抽取(Information Extraction)、常识推理 (Commonsense Reasoning)、符号-神经计算 (Neuro-Symbolic Computation)等方向。已在ACL, EMNLP, KDD, WWW 等会议上发表多篇论文。

一、引言
讲者以汽车为例,介绍了此项工作面向的应用场景。在每一个domain(关于汽车、电影、图书等),有很多的entities(比如某个型号的汽车),在一个domain中往往有很多网站介绍不同的entity。针对在网页文档中进行信息抽取,讲者限定了模型的输入:detail page, 即关于某一个entity的具体页面,比如:关于某一部电影的详细页面或者是关于某一具体型号汽车的详细介绍等;输出为:期望得到相关类型的结构化信息,比如:汽车型号、价格、引擎以及燃油信息构成的一条data record extraction。
网页文档中进行信息抽取的应用有哪些呢?它可用于构建某一行业或某一个具体领域的知识图谱,或应用于问答系统、推荐系统中。
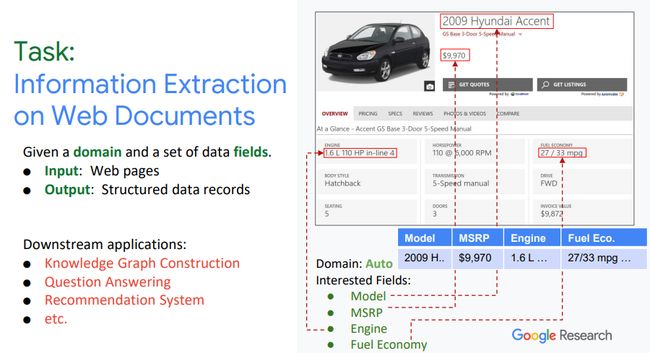
图1. 网页中的信息抽取
假想:在一个具体的,不同的entity的detail page具有相似的结构。当只有三五个感兴趣的网站需要抽取时,可以1):针对每一个website进行基于规则的matching program,常见的有wrapper方法;或者2):通过人工标注,进行有监督的模型学习。这两种方法的缺点在于:泛化性低,只能应用在已标注或编写规则的网站中。那么,当有成百上千未标注的websites,上述方法就过于昂贵、需要大量的人工。因此,此项研究的核心问题在于:如何学习到一个可迁移的信息抽取模型?从而只用少量的网站标注进行学习,从而扩展到大量的未标注的网站。

图2. 可迁移信息抽取模型的必要性
二、问题描述
应用场景例子:假如想要构建一个关于课程信息(course)的知识库,课程信息来源于不同学校的网站,每个网站具有不同的结构。期望抽取的信息包括有:Name, Course Number, Instructor, Time, Location, Email, Textbook, Description等。希望采用很少个初始带标签的网站信息(如MIT, Harvard, USC)去训练一个可迁移的抽取模型,但该模型可被应用在训练过程中没有见过的网站(如图中的Univ 1,2,3,…)上(这些网站包含了所期望抽取的信息,但具有不同的网页结构)。当有了这样一个可迁移的抽取模型之后,通过后处理就可以构建一个课程知识库了。(类似的应用场景可以扩展到比如建立一个关于人工智能的学者主页信息的知识图谱构建上)。
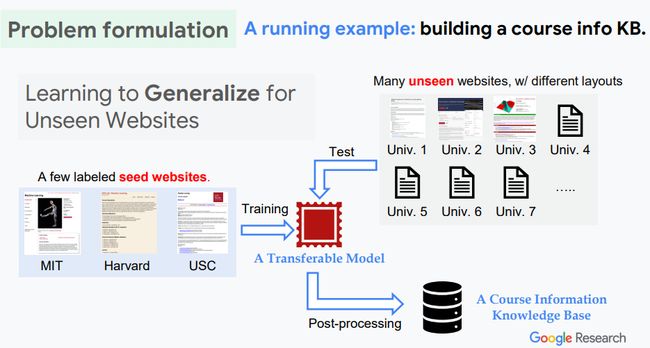
图3.关于网页中信息抽取问题的描述
如何表征一个网页?一是基于网页渲染(rendering)的方法,通过下载外部的文件包括,CSS,JS以及图片等带有样式的文字去渲染网页,但耗费更多的计算资源;二是直接使用HTML代码,但信息的structure没有表现出来。提出一种半结构化的数据结构即DOM Tree,既有structure信息,且每一个node信息较容易得到,因此任何一个网页可由树特征表征节点间的层级结构。基于DOM Tree,可将信息抽取任务转化为node classification,也就是判断每一个node中是否包含想得到的信息以及哪种类型的信息。None表示不包含任何想要的数据。

图4.网页信息的几种结构形式
三、模型构建
提出FreeDOM模型,包括两个阶段:第一阶段:基于DOM Tree学习每一个node的local feature;但只用了node的局部信息,不包括与邻居node间的结构信息,因此提出第二阶段,以掌握node之间互相依赖关系,比如当一个node为引擎信息时,另一个相邻节点为燃料信息,这样的一个pattern。在应用阶段,可直接采用unsee的网页进行测试得到最终的结构化数据。

图4. FreeDOM的概览图
类似于supervise-learning的方法,提取一些node的feature。主要由三部分组成:node本身的文本(Element of …);node之前的文本,称为preceding tokens(Textbook);基于node的一些离散信息(比如,node的类型;是否包含url;是否包含数字等)。为获得node的feature,经过word embedding table以及character embedding table双路编码sentences以及preceding tokens,以对整个文本信息建模并得到vectors;对于离散的信息经过trainable embedding,可由pooling得到feature vectors;最后concatenate三者的feature vectors作为整个node的表征,再由MLP进行分类,其中None表示该node不包含所需的数据。讲者解释为什么选择用基于character的embedding? 主要是因为对于课程编号、时间、地点这些本身具有很少字的信息,采用word embedding得到的信息非常少。

图5. 模型第一阶段算法结构图
然而,仅仅使用local的node表征带来了一些问题,一是:具有迷惑性的local features。比如下图所示,两次出现Time,紧邻Instructor 的Time更可能表示为课程的上课时间;紧邻TA Office的Time更可能表示为教室开放的时间。二是:缺失类似于Textbook这样的词。在训练中会发现类似的网页结构,即Time 和Location往往会挨在一起,Textbook总是出现在Overview或者Description的下面。因此,可通过加强这种猜测,学习一些node之间的dependency,以更好的做决策。

图6. 仅适用local node表征带来的问题
为解决上述问题,作者团队提出了通过pair-wise modeling建模节点间的dependency。该思路是指通过编码每一对node-pair,并学习其关系类型Value-Value,Value-None,None-Value,None-None,来判断给定node pair是否为Value-Value。具体地,node pair的representation也是由三部分组成:模型第一阶段学习到的node表征;node的HTML Tag的embedding,即XPath的sequence;以及node的position,可从标签body开始往下数。同样地,concatenate三者的feature vectors作为给定relational node-pair features。由Classification model 判断node-pair的关系类型,同时可结合第一阶段得分,删除第一阶段中False Positive的节点。因此,第二阶段算法的提出,可保证分类结果既结合节点的local features,也结合邻居节点的prediction score。

图7. 模型第二阶段算法结构图
在具体应用中,主要存在以下3个问题:
(1)网页中有很多nodes,如何做简化?
可以定义一个variable nodes,即只关注不同页面里具有不同数据的节点。
(2)依旧存在大量的node-pairs?
基于第一阶段分类结果的confidence,可以选择排名前m个节点做classification。
(3)对网站做具体的constrains?
根据网站固定的layout,采用多数投票的方式排除outlier predictions。
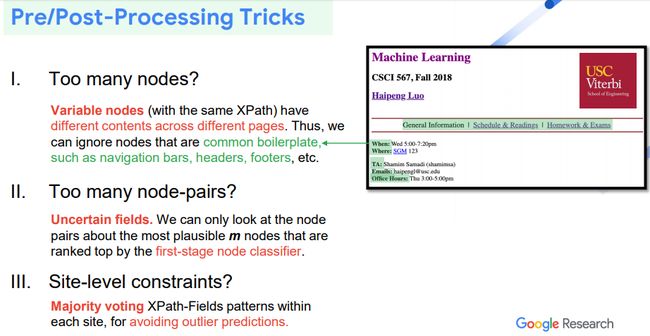
图8. 模型处理前后的tricks
四、实验结果
采用SWDE数据集进行实验,其包含有8个不同的领域,每个领域有10个不同的网站,且有4~5个data fields。讲者选择K个websites 作为training data,选择10-K个websites 作为testing data,同时给定K 选择10种不同组合情况,最终取10种不同实验的平均值。
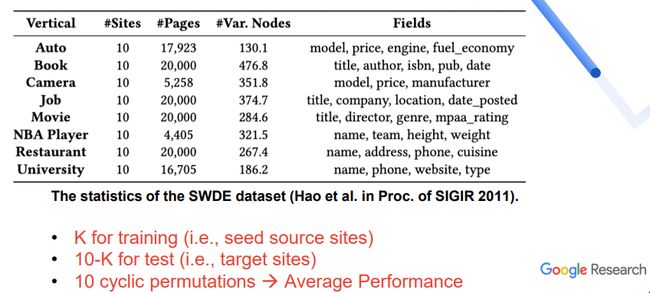
图8. SWDE数据集的统计结果
讲者采用FreeDOM模型的两个变种与baseline methods进行对比,其中只考虑第一阶段模型FreeDOM-Node Labeling的效果与Render-Full相近;而两阶段都采用时的模型FreeDOM-Full出现了明显的提升。
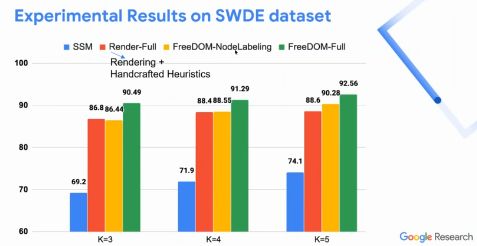
图9. 在SWDE数据集上的实验结果
进一步,通过Ablation Study的实验,说明FreeDOM模型较传统的序列化模型具有显著的优势。当discrete features在某些领域不适用时,讲者对不采用discrete features的模型进行实验,也达到了不错的效果。
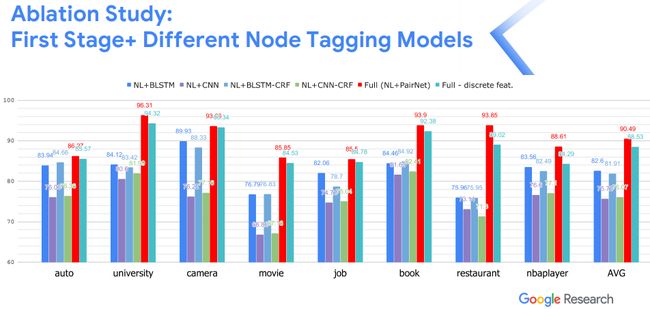
图10. 基于FreeDOM模型进行的ablation study
五、总结与展望
讲者介绍了一种新型的基于神经网络的模型,即可迁移的信息抽取模型,可在网页中实现信息抽取任务,该方法没有使用渲染过程,直接使用DOM Tree结构做pairwise modeling,在SWDE数据集上也达到了最优的效果。
同时讲者介绍了未来工作的方向:(1)在开放领域进行信息抽取;(2)考虑学习一种self-training 得到HTML documents 的表征。

图11. 总结与展望
整理:刘美珍
审稿:林禹臣
排版:田雨晴
AI Time欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY

AI Time是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(点击“阅读原文”下载本次报告ppt)
(直播回放:https://www.bilibili.com/video/BV1Jk4y117ff)