ResNet网络结构详解及代码复现
1. ResNet论文详解
1.1. Introduction
一般网络越深,特征就越丰富,模型效果也就越好。在深度重要的驱动下,出现了2个问题:
-
梯度消失和梯度爆炸:
- 梯度消失:误差梯度<1,当网络层数增多时,最终求的梯度会以指数形式衰减
- 梯度爆炸:误差梯度>1,当网络层数增多时,最终求的梯度会以指数形式增加
- 解决方式:
-
Xavier 初始化、Kaiming 初始化等
-
Batch Normalization
-
-
退化问题:在适当深度的模型中添加更多的层会导致更高的训练误差,如下图:
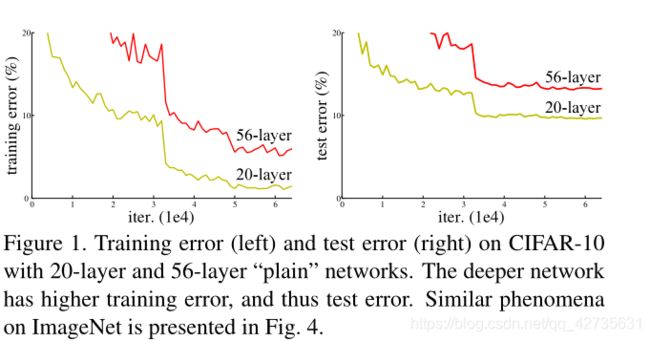
在本文中,我们通过残差结构来解决退化问题。
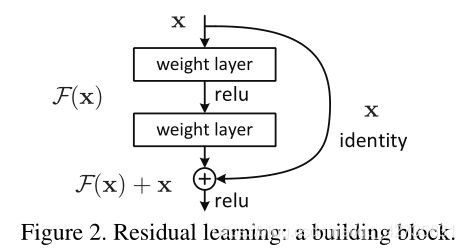
原本是通过堆叠非线性层来适合 H ( x ) H(x) H(x),现在是让这些非线性层来适合 F ( x ) F(x) F(x),原始映射被表示为: H ( x ) : = F ( x ) + x H(x):=F(x)+x H(x):=F(x)+x
- H ( x ) : H(x): H(x): 原本需要学习的映射
- F ( x ) : F(x): F(x): 现在需要学习的映射
- x : x: x: 单位映射,可以跳过一层或多层的连接(
shortcut connection)
实验表示:
- 极深残差网络很容易优化
- 很容易获得网络深度带来的准确性的提高
1.2. Deep Residual Learning
1.2.1 Residual Learning
退化问题表明:很难通过多个非线性层来逼近单位映射,因为如果可以的话,那么更深的模型的训练误差应该不大于更浅层的对应模型。而对应残差网络,如果单位映射为最优的话,求解器可以简单地将多个非线性层地权值置为0从而逼近单位映射。
1.2.2 Identity Mapping by Shortcuts
在本文中,残差块定义如下:
- x x x和 F F F的维度一致: y = F ( x , { W i } ) + x y=F(x,\{W_i\})+x y=F(x,{Wi})+x
- x x x和 F F F的维度不一致: y = F ( x , { W i } ) + W s x y=F(x,\{W_i\})+W_sx y=F(x,{Wi})+Wsx( W s W_s Ws用来匹配维度)
残差函数 F F F是灵活的,主要表现层数的个数和层的类别上
- 在本文的实验中涉及的 F F F,它有两层或三层,也可以有更多层,但是如果只有一层,则就类似于线性层: y = W 1 x + x y=W_1x+x y=W1x+x,我们没有观察到任何优势。
- 尽管上面公式表示法是全连接层,但它同样适用于卷积层
1.3. Network Architectures
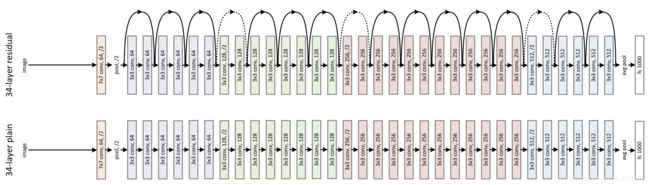
在一般网络结构的基础上,插入shortcut connection,将网络变为对应的残差网络。
当输入和输出的维数相同时:对应于上图的实线shortcut connection,处理方式:
- 直接使用单位映射
当输入和输出的维数不相同时:对应于上图的虚线shortcut connection,处理方式:
shortcut connection仍然使用单位映射,增加维数用0填充,此方法不引入额外的参数- 使用1x1卷积来匹配维度,文中称为
projection shortcut
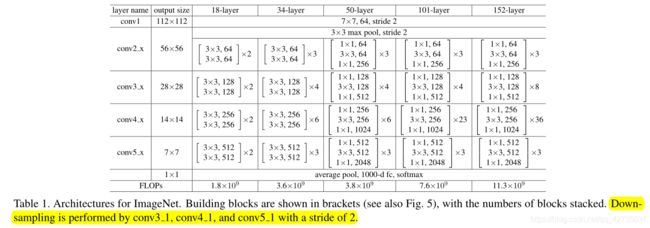
当跨越两种尺寸的特征图时,执行步幅为2的。有上表黄色部分可知。
1.4. Experiments
1.4.1 Residual Networks VS. Plain Networks
Plain Networks
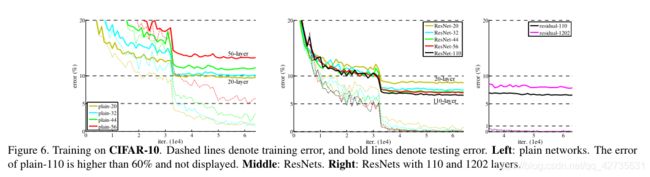
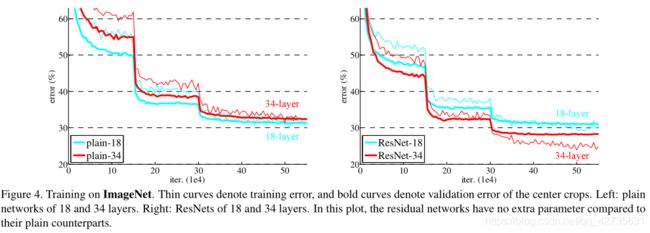
上图表示:34层网络比18层网络具有更高的验证误差,尽管18层网络的解空间是34层网络的子空间,但在整个训练过程中,34层网络的训练误差都比较大,这说明了退化问题
我们认为这种优化困难不可能是梯度消失引起的,因为这些网络都使用了BN进行训练,保证前向传播的信号具有非零方差。我们还验证了反向传播的梯度在BN上表现出健康的范数。所以向前和向后的信号都不会消失。
Residual Networks
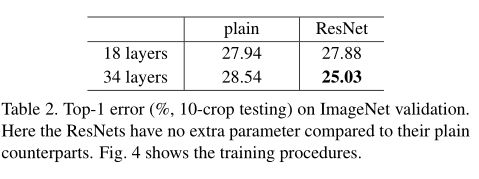
从图4和表2可知:
34层的残差网络比18层残差网络有着相当低的训练误差,并可推广到验证数据,这说明退化问题得到很好的解决,这说明了残差网络在极深网络的有效性- 通过比较
18层网络和18层残差网络,发现残差网络收敛的更快
1.4.2 Identity VS. Projection Shortcuts
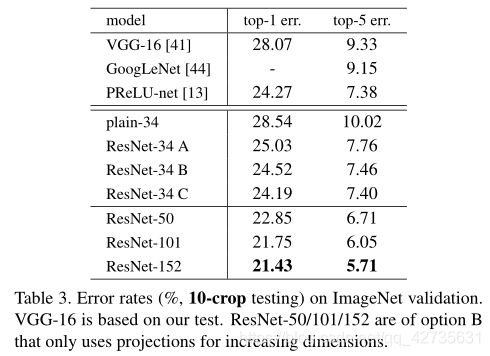
在表3中,我们比较了3个选项(projection:在文中指利用1x1卷积来进行改变维度)
A:用0填充以增加维度B:projection shortcuts用于增加维度,其他shortcuts为单位映射C:所有shortcuts均为projection
由表3可知:
B略优于A:A中的0填充的维度没有进行残差学习C略优于B:多个projection引入了额外的参数A、B和C的细小差异表明:projection对于解决退化问题不是必须的,因此在本文的其余部分,我们不使用C以减少内存/时间复杂度和模型的规模,使用B
1.4.3 Deeper Bottleneck Architectures
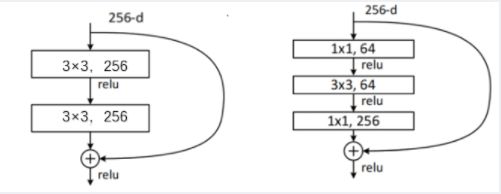
1x1卷积用于升维或降维,可以减少网络的参数
- 上图左:
256x3x3x256+256x3x3x256=1179648 - 上图右:
256x1x1x64+64x3x3x64+64x1x1x256=69632
故在更深的残差网络中,使用上图右的结构,可以大大减少网络的参数,减小模型的规模
2. 基于Pytorch代码复现
2.1 模型搭建
import torch.nn as nn
import torch
from torchsummary import summary
import torchvision.models as models
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.Conv2d(out_channel)
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel*self.expansion, kernel_size=1, stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, block_num, num_classes=1000, include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, block_num[0])
self.layer2 = self._make_layer(block, 128, block_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, block_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, block_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel*block.expansion)
)
layers = []
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def read_resnet34():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = models.resnet34(pretrained=True)
model.to(device)
print(model)
summary(model, input_size=(3, 224, 224))
def get_resnet34(flag, num_classes):
if flag:
net = models.resnet34(pretrained=True)
num_input = net.fc.in_features
net.fc = nn.Linear(num_input, num_classes)
else:
net = resnet34(num_classes)
return net
2.2 训练结果如下
- 训练数据集与验证集大小以及训练参数
Using 3306 images for training, 364 images for validation
Using cuda GeForce RTX 2060 device for training
lr: 0.0001
batch_size: 16
- 使用自己定义的网络训练结果
[epoch 1/10] train_loss: 1.309 val_acc: 0.555
[epoch 2/10] train_loss: 1.146 val_acc: 0.604
[epoch 3/10] train_loss: 1.029 val_acc: 0.643
[epoch 4/10] train_loss: 0.935 val_acc: 0.695
[epoch 5/10] train_loss: 0.919 val_acc: 0.615
[epoch 6/10] train_loss: 0.860 val_acc: 0.723
[epoch 7/10] train_loss: 0.841 val_acc: 0.690
[epoch 8/10] train_loss: 0.819 val_acc: 0.725
[epoch 9/10] train_loss: 0.800 val_acc: 0.745
[epoch 10/10] train_loss: 0.783 val_acc: 0.725
Best acc: 0.745
Finished Training
Train 耗时为:281.2s
- 使用预训练模型参数训练结果
[epoch 1/10] train_loss: 0.492 val_acc: 0.896
[epoch 2/10] train_loss: 0.327 val_acc: 0.896
[epoch 3/10] train_loss: 0.285 val_acc: 0.909
[epoch 4/10] train_loss: 0.273 val_acc: 0.904
[epoch 5/10] train_loss: 0.205 val_acc: 0.901
[epoch 6/10] train_loss: 0.245 val_acc: 0.898
[epoch 7/10] train_loss: 0.200 val_acc: 0.923
[epoch 8/10] train_loss: 0.196 val_acc: 0.923
[epoch 9/10] train_loss: 0.179 val_acc: 0.929
[epoch 10/10] train_loss: 0.173 val_acc: 0.926
Best acc: 0.929
Finished Training
Train 耗时为:281.3s
上一篇:GoogLeNet
下一篇:DenseNet
完整代码