数据挖掘案例实战:利用LDA主题模型提取京东评论数据(四)
泰迪智能科技(数据挖掘平台:TipDM数据挖掘平台)最新推出的数据挖掘实战专栏
专栏将数据挖掘理论与项目案例实践相结合,可以让大家获得真实的数据挖掘学习与实践环境,更快、更好的学习数据挖掘知识与积累职业经验
专栏中每四篇文章为一个完整的数据挖掘案例。案例介绍顺序为:先由数据案例背景提出挖掘目标,再阐述分析方法与过程,最后完成模型构建,在介绍建模过程中同时穿插操作训练,把相关的知识点嵌入相应的操作过程中。
为方便读者轻松地获取一个真实的实验环境,本专栏使用大家熟知的Python语言对样本数据进行处理以进行挖掘建模。
————————————————
使用LDA模型进行主题分析
1、了解LDA主题模型
(1)主题模型介绍
主题模型在自然语言处理等领域是用来在一系列文档中发现抽象主题的一种统计模型。传统判断两个文档相似性的方法是通过查看两个文档共同出现的单词的多少,如TF(词频)、TF-IDF(词频-逆向文档频率)等,这种方法没有考虑到文字背后的语义关联,例如在两个文档共同出现的单词很少甚至没有,但两个文档是相似的,因此在判断文档相似性时,需要使用主题模型进行语义分析并判断文档相似性。
如果一篇文档有多个主题,则一些特定的可代表不同主题的词语会反复的出现,此时,运用主题模型,能够发现文本中使用词语的规律,并且把规律相似的文本联系到一起,以寻求非结构化的文本集中的有用信息。例如热水器的商品评论文本数据,代表热水器特征的词语如“安装”“出水量”“服务”等会频繁地出现在评论中,运用主题模型,把热水器代表性特征相关的情感描述性词语与应的特征词语联系起来,从而深入了解用户对热水器的关注点及用户对于某一特征的情感倾向。
(2)LDA主题模型
潜在狄利克雷分配,即LDA模型(Latent Dirichlet Allocation,LDA)是由Blei等人在2003年提出的生成式主题模型⑱。生成模型,即认为每一篇文档的每一个词都是通过“一定的概率选择了某个主题,并从这个主题中以一定的概率选择了某个词语”。LDA模型也被称为三层贝叶斯概率模型,包含文档(d)、主题(z)、词(w)三层结构,能够有效对文本进行建模,和传统的空间向量模型(VSM)相比,增加了概率的信息。通过LDA主题模型,能够挖掘数据集中的潜在主题,进而分析数据集的集中关注点及其相关特征词。
LDA模型采用词袋模型(Bag Of Words,BOW)将每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信息。
定义词表大小为L,一个L维向量(1,0,0,...,0,0)表示一个词。由N个词构成的评论记为。假设某一商品的评论集D由M篇评论构成,记为。M篇评论分布着K个主题,记为。记a和b为狄利克雷函数的先验参数,q为主题在文档中的多项分布的参数,其服从超参数为a的Dirichlet先验分布,f为词在主题中的多项分布的参数,其服从超参数b的Dirichlet先验分布。LDA模型图如图1所示。
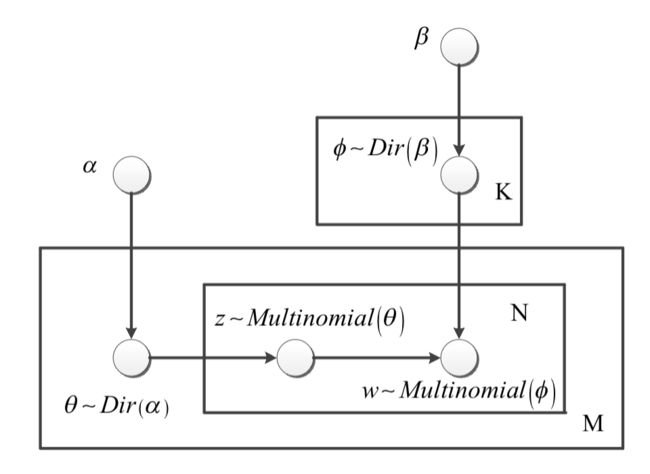
图1 LDA模型结构示意图
LDA模型假定每篇评论由各个主题按一定比例随机混合而成,混合比例服从多项分布,记为式(1)。
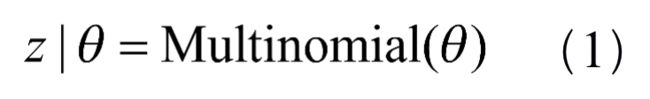
而每个主题由词汇表中的各个词语按一定比例混合而成,混合比例也服从多项分布,记为式(2)。

在评论dj条件下生成词wi的概率表示为式
其中,P(wi|z=s)表示词属于第s个主题的概率,P(z=s|dj)表示第s个主题在评论dj中的概率。
LDA主题模型是一种无监督的模式,只需要提供训练文档,它就可以自动训练出各种概率,无需任何人工标注过程,节省大量人力及时间。它在文本聚类、主题分析、相似度计算等方面都有广泛的应用,相对于其他主题模型,其引入了狄利克雷先验知识。因此,模型的泛化能力较强,不易出现过拟合现象。
LDA主题模型可以解决多种指代问题,例如:在热水器的评论中,根据分词的一般规则,经过分词的语句会将“费用”一词单独分割出来,而“费用”是指安装费用,还是热水器费用等其他情况,如果简单的进行词频统计及情感分析,是无法识别的,这种指代不明的问题不能购准确的反应用户情况,运用LDA主题模型,可以求得词汇在主题中的概率分布,进而判断“费用”一词属于哪个主题,并求得属于这一主题的概率和同一主题下的其他特征词,从而解决多种指代问题。
建立LDA主题模型,首先需要建立词典及语料库,如代码清单1所示。
代码清单1 建立词典及语料库
import pandas as pdimport numpy as npimport reimport itertoolsimport matplotlib.pyplot as plt# 载入情感分析后的数据posdata = pd.read_csv("../data/posdata.csv", encoding='utf-8')negdata = pd.read_csv("../data/negdata.csv", encoding='utf-8')from gensim import corpora, models# 建立词典pos_dict = corpora.Dictionary([[i] for i in posdata['word']]) # 正面neg_dict = corpora.Dictionary([[i] for i in negdata['word']]) # 负面# 建立语料库pos_corpus = [pos_dict.doc2bow(j) for j in [[i] for i in posdata['word']]] # 正面neg_corpus = [neg_dict.doc2bow(j) for j in [[i] for i in negdata['word']]] # 负面
2、寻找最优主题数
基于相似度的自适应最优LDA模型选择方法,确定主题数并进行主题分析。实验证明该方法可以在不需要人工调试主题数目的情况下,用相对少的迭代,找到最优的主题结构。具体步骤如下。
(1)取初始主题数k值,得到初始模型,计算各主题之间的相似度(平均余弦距离)。
(2)增加或减少k值,重新训练模型,再次计算各主题之间的相似度。
(3)重复步骤②直到得到最优k值。
利用各主题间的余弦相似度来度量主题间的相似程度。从词频入手,计算它们的相似度,用词越相似,则内容越相近。
假定A和B是两个n维向量,A是(A1,A2,...,An),B是(B1,B2,...,Bn),则A与B的夹角θ的余弦值通过式(4)计算。
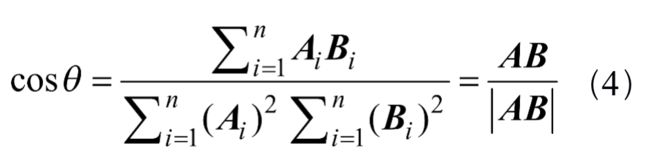
使用LDA主题模型,找出不同主题数下的主题词;每个模型各取出若干个主题词(比如前100个),合并成一个集合;生成任何两个主题间的词频向量;计算两个向量的余弦相似度,值越大就表示越相似;计算个主题数的平均余弦相似度,寻找最优主题数,如代码清单2所示。
代码清单2 主题数寻优
# 构造主题数寻优函数def cos(vector1, vector2): # 余弦相似度函数dot_product = 0.0;normA = 0.0;normB = 0.0;for a,b in zip(vector1, vector2):dot_product += a*bnormA += a**2normB += b**2if normA == 0.0 or normB==0.0:return(None)else:return(dot_product / ((normA*normB)**0.5))# 主题数寻优def lda_k(x_corpus, x_dict):# 初始化平均余弦相似度mean_similarity = []mean_similarity.append(1)# 循环生成主题并计算主题间相似度for i in np.arange(2,11):lda = models.LdaModel(x_corpus, num_topics=i, id2word=x_dict) # LDA模型训练for j in np.arange(i):term = lda.show_topics(num_words=50)# 提取各主题词top_word = []for k in np.arange(i):top_word.append([''.join(re.findall('"(.*)"',i)) \for i in term[k][1].split('+')]) # 列出所有词# 构造词频向量word = sum(top_word,[]) # 列出所有的词unique_word = set(word) # 去除重复的词# 构造主题词列表,行表示主题号,列表示各主题词mat = []for j in np.arange(i):top_w = top_word[j]mat.append(tuple([top_w.count(k) for k in unique_word]))p = list(itertools.permutations(list(np.arange(i)),2))l = len(p)top_similarity = [0]for w in np.arange(l):vector1 = mat[p[w][0]]vector2 = mat[p[w][1]]top_similarity.append(cos(vector1, vector2))# 计算平均余弦相似度mean_similarity.append(sum(top_similarity)/l)return(mean_similarity)# 计算主题平均余弦相似度pos_k = lda_k(pos_corpus, pos_dict)neg_k = lda_k(neg_corpus, neg_dict)# 绘制主题平均余弦相似度图形from matplotlib.font_manager import FontPropertiesfont = FontProperties(size=14)#解决中文显示问题plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = Falsefig = plt.figure(figsize=(10,8))ax1 = fig.add_subplot(211)ax1.plot(pos_k)ax1.set_xlabel('正面评论LDA主题数寻优', fontproperties=font)ax2 = fig.add_subplot(212)ax2.plot(neg_k)ax2.set_xlabel('负面评论LDA主题数寻优', fontproperties=font)
运行代码清单2,可得主题间平均余弦相似度图,如图2所示。
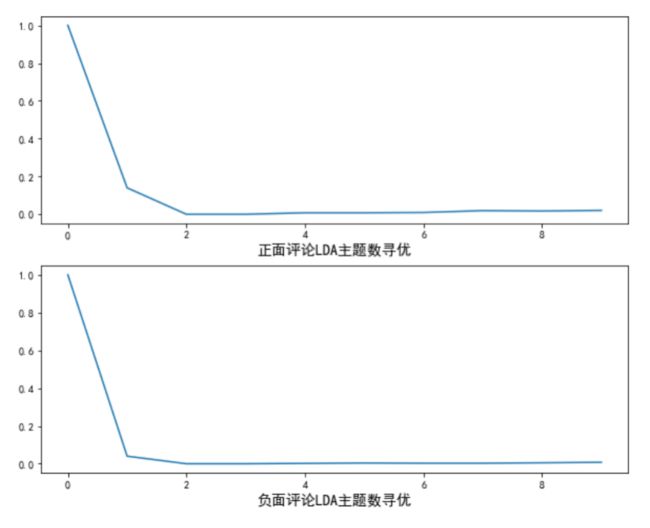
图2 主题间平均余弦相似度图
由图2可知,对于正面评论数据,当主题数为2或3时,主题间的平均余弦相似度就达到了最低。因此,对正面评论数据做LDA,可以选择主题数为3。对于负面评论数据,当主题数为3时,主题间的平均余弦相似度就达到了最低。因此,对负面评论数据做LDA,可以选择主题数为3。
(3) 评价主题分析结果
根据主题数寻优结果,使用Python的gensim模块对正、负面评论数据分别构建LDA主题模型,设置主题数为3经过LDA主题分析后,每个主题下生成10个最有可能出现的词语以及相应的概率,如代码清单3所示。
代码清单3 LDA主题分析
# LDA主题分析pos_lda = models.LdaModel(pos_corpus, num_topics=3, id2word=pos_dict)neg_lda = models.LdaModel(neg_corpus, num_topics=3, id2word=neg_dict)pos_lda.print_topics(num_words=10)neg_lda.print_topics(num_words=10)
运行代码清单3,可得LDA主题分析结果如表1与表2所示。
表1 美的正面评价潜在主题
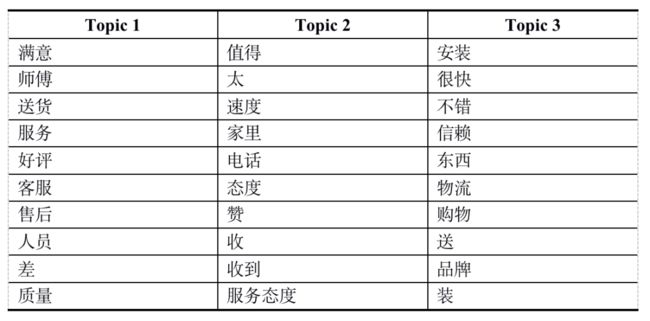
表1反映了美的正面评价文本中的潜在主题,主题1中的高频特征词,即关注点主要是师傅、不错、售后服务等,主要反映美的安装师傅服务好等;主题2中的高频特征词,即关注点主要是物流、价格等,主要反映热水器的发货速度快,及品牌价格实惠等;主题3中的高频特征词,即不错、满意、质量、好评等,主要反映京东美的产品质量不错。
表2 美的负面评价潜在主题
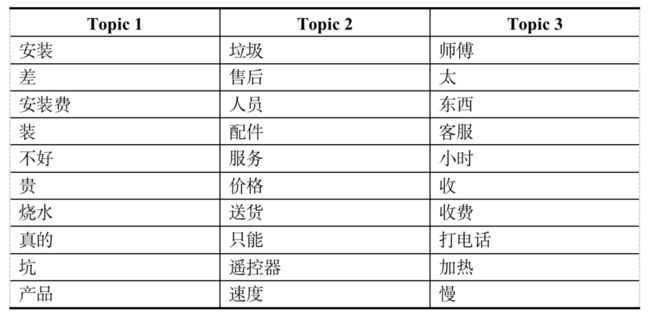
表2反映了美的负面评价文本中的潜在主题,主题1中的高频特征词主要关注点在安装、安装费、收费这几方面,可能存在安装师傅收费过高等问题;主题2中的高频特征词主要与售后、服务这几方面,反映该产品售后服务差等问题;主题3中的高频特征词主要与加热功能有关,即主要反映的是美的热水器加热性能存在问题。
综合以上对主题及其中的高频特征词分析得出,美的热水器的优势有以下几个方面:价格实惠、性价比高、外观好看、服务好。相对而言,用户对美的热水器的抱怨点主要体现在美的热水器安装的费用高及售后服务差等。
因此,用户的购买原因可以总结为以下几个方面:美的是大品牌值得信赖,美的热水器价格实惠,性价比高。
根据对京东平台上,美的热水器的用户评价情况进行LDA主题模型分析,对美的品牌提出以下2点建议。
(1)在保持热水器使用方便、价格实惠等优点基础上,对热水器进行加热功能上的改进,从整体上提升热水器的质量。
(2)提升安装人员及客服人员的整体素质,提高服务质量,更加注重售后服务。建立安装费用收取明文细则,并进行公开透明,减少安装过程的乱收费问题。适度降低安装费用和材料费用,以此在大品牌的竞争中凸显优势。
可以通过大数据挖掘平台TipDM数据挖掘平台进行实操