【自动驾驶】决策规划面试准备(持续更新)
前言
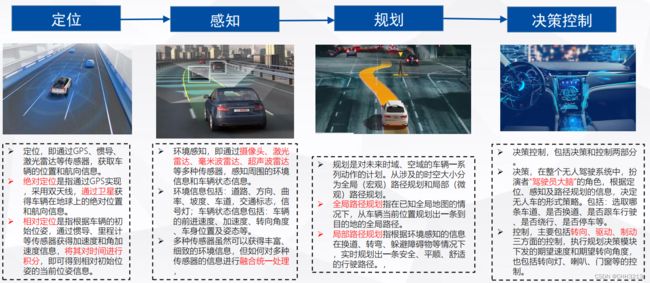
自动驾驶模块间的关系
参考:https://zhuanlan.zhihu.com/p/546950489

高精地图(HD Map)
-
HD Map是信息更为复杂、精确的地图,可以记录交通标志的位置、交通限速信息、静态障碍物、地标建筑。
-
对于定位,识别、匹配 HD map 中的地图元素,可以根据相对位置辅助定位;
-
对于感知,可以为感知划定ROI,比如记录信号灯的位置和高度,提高感知效率;
-
对于规划,地图对全局规划(routing)来说是必须的,对决策(behavior decision)和局部规划(motion planning)来说,可以提供可行驶区域和障碍物信息。
-
目前高精地图的行业标准是OpenDRIVE格式。
定位
-
通过GPS或者RTK等获取自身车辆位姿信息。在已知的 HD map 中较为准确的确定自身位置。
-
定位的手段主要包括GNSS/IMU、激光雷达、视觉。GNSS是根据参照物(卫星)的距离进行差分定位,IMU是通过惯性测量自身状态进行定位,激光雷达和视觉既可以通过匹配定位,也可以通过里程计定位。GNSS遇到遮挡会丢失信号,IMU累计误差较大,激光雷达和视觉也会受到天气影响,自动驾驶汽车定位方案都是将多种传感器的数据进行融合。
感知
-
通过相机、雷达等传感器获取环境信息,如障碍物(其他汽车和人也算是障碍物)、车道线等。感知的具体任务包括图像分割、点云分割、车道线检测、车辆检测、行人检测、交通标志检测、目标跟踪等。
- 相机可以分辨物体颜色,但也因此容易发生混淆,比如特斯拉装上与背影天空融为一体的白色卡车;
- 激光雷达可以测量距离,数据纬度高、数据量大,价格高,受天气影响;
- 雷达分辨率低
-
感知与决策规划模块是相对比较独立的,可以理解为,自动驾驶汽车在 HD map 中进行决策规划,而感知在 HD map 中加入了更多动态信息。
预测
-
预测其实和决策规划很类似,预测是求解其他车辆未来的状态,规划是求解自身车辆未来的状态。预测和运动规划一样,也分为基于数据驱动的方法和基于模型的方法,但定义有所不同,举个例子:
- 基于模型的方法建立直行和换道的模型,然后将目标状态与面各种模型进行匹配,这种方法对于变化环境的预测能力显然是有限的。
- 基于数据驱动的方法显然无法处理没有学习过的场景。
需要预测的状态包括障碍车辆的车道变化序列、行人运动轨迹、车辆运动轨迹等。重点和难点是考虑交通参与者之间的交互关系,因此数据驱动的方法在预测中比在规划中使用的更多。在最终生成轨迹时,并不一定要像规划一样建立一个优化问题,而是建立为一个更容易解决的插值问题。
规划
-
规划分为全局路径规划和局部路径规划。在自动驾驶中,全局路径规划被称为Rounting,而局部规划被称为Motion Planning。
-
规划是指根据上游感知、定位的环境信息、车辆速度、加速度等信息规划出一条最优路径、速度输出控制模块。
-
全局规划并不依赖 HD map 、环境感知等,是一项在导航软件在中比较成熟的技术,经常使用的是A*搜索算法。有些自动驾驶系统中会提到决策模块(behavior decision),但是很多自动驾驶系统都不再设为一个单独的模块。比如在全局规划决定了在一个路口需要执行还是转弯 ,因此其实也决策了要走哪个车道;运动规划模块在生成局部轨迹时,也会对各个车道进行比较,决策走哪个车道。决策的过程其实是融合在各个模块之中的。
控制
- 根据规划输出结果,控制方向盘转向及车辆加减速,最终达到控制车辆以适当的车速沿着期望路径行驶的目的。控制又分为横向控制和纵向控制,横向控制就是控制车辆转向,纵向控制就是车辆加减速。
- 控制的核心控制理论(Control Theory),包括状态模型建立、控制器设计、性能分析的各种方法。
- 对于实际工程中的控制问题,我们不能眼高手低,只关注控制器,而是要关注整个系统的分析。比如:
- 汽车的控制输入是方向盘转角、油门、制动,输出是侧向速度和纵向速度和横摆角速度,是一个MIMO系统;
- 横向控制与纵向控制是可以解耦的;
- 状态要建立在车辆坐标系上,而不是地图坐标系,是一个非惯性系;
- 方向盘和前轮转角之间有差速器;
- 车辆行驶中质心是会发生变化的,在设计控制器需要讨论是否考虑在车辆模型之内等等。
坐标系转换
1. Frenet坐标系介绍
1.1 Cartesian坐标系
-
一般情况下,我们使用Cartesian坐标系(笛卡尔坐标系)来描述物体的坐标,但对于车辆来说,笛卡尔坐标系并不是最佳选择。因为即使知道了笛卡尔坐标系下车辆的位置信息,也难以表达车辆与道路之间的相对位置,导致二者之间的相对关系不明确。
-
因此,传统规划算法在笛卡尔坐标系下规划出的路径对于开放道路有良好的效果,但是对于公路环境,忽略车道信息导致路径的自由度太高而容易违反道路交通规则。
1.2 Frenet坐标系
Frenet坐标系在无人驾驶领域被普遍使用,特别是在城市、高速等道路交通环境下无人驾驶的路径规划系统中。
Frenet坐标系使用道路的中心线作为参考线,使用参考线的切线向量和法线向量建立坐标系。相比笛卡尔坐标系,Frenet坐标系简化了路径规划问题。
下图是自动驾驶车辆在全局坐标系与Frenet坐标系中的位置示意。

假设自动驾驶车辆在全局坐标系下的坐标为 ( x , y ) (x,y) (x,y),从车辆的位置 ( x , y ) (x,y) (x,y)向参考线 T T T作投影,投影点为 F F F,则点 F F F与车辆位置 ( x , y ) (x,y) (x,y)的距离即为横向位移 d d d(方向为参考线当前的法向,称为横向,Lateral);从参考线的起始点到投影点 F F F的曲线距离即为纵向位移 s s s(方向沿着参考线,称为纵向,即Longitudinal)。
基于Frenet坐标系,将自动驾驶车辆每时每刻的位置状态分解在 s s s和 d d d两个方向来描述车辆的运动状态,从而在轨迹曲线拟合时,减少处理坐标信息的工作量。
参考线
Frenet坐标系是依附于参考线的,因此参考线在整个规划过程中是必不可少的。在百度Apollo自动驾驶项目中其也被称为参考线(Reference Line),读者请注意区分参考线与车道线,车道线其实是指车道两侧的分界线,是两条;参考线可以取为车道线边界围成区域的中心线,是一条。在轨迹规划之前要先生成参考线,那么参考线是怎么来的呢?一般是先根据起点和目标点进行路线规划,根据路线经过的道路从高精地图中查找对应的道路中心线或者边界线,将所有道路的道路中心线拼接起来并进行光滑处理,防止出现间断或者跳变,因为一旦有不连续或者不光滑就会导致Frenet坐标系的不连续。这样就得到了一条光滑的参考线。
决策控制部分
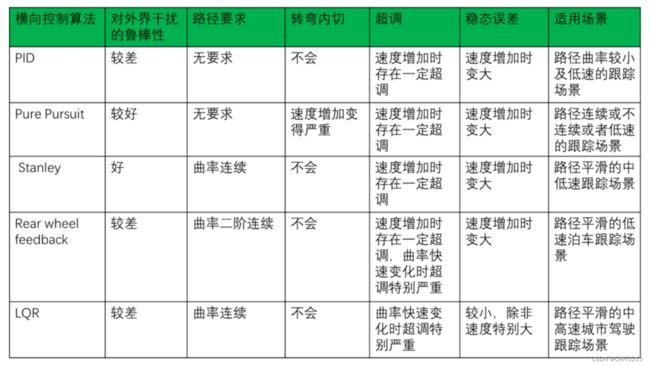
1. Pure Pursuit(纯追踪)算法
1.1. 原理
纯追踪算法的原理很简单,就是单车模型通过调整前轮转向 δ \delta δ运动,使得车辆后轴中心刚好可以经过当前规划的路点。换句话说,此时的后轴中心为圆弧切点,车辆纵向车身为切线。通过控制前轮转角 δ \delta δ, 使车辆可以沿着一条经过目标路点(goal point)(或者叫预瞄点)的圆弧行驶。
该算法会根据机器人的当前位置在路径上移动预瞄点,直到路径的终点。可以想象成机器人不断追逐它前面的一个点。
总结如下:
基于当前车辆后轴中心位置,在参考路径上向 l d l_d ld (自定义,称为前视距离)的距离匹配一个预瞄点。假设车辆后轴中心点可以按照一定的转弯半径 R R R行驶抵达该预瞄点,然后根据预瞄距离 l d l_d ld、转弯半径 R R R、车辆坐标系下预瞄点的朝向角 2 α 2\alpha 2α之间的几何关系确定前轮转角。
1.2. 模型适配
纯跟踪算法是把车看成一个阿克曼模型进行几何解算的,本质是不适合差速车或者麦轮车的
1.3. 前视距离调整
前视距离的调整需要根据机器人运行的实际情况来进行调整。
前视距离是整个Pure Pursuit控制器的重要参数。往前看的距离是机器人从当前位置应沿着路径观察的距离,以计算转角控制命令。
在低速的情况下合理调整前视距离可以实现较好的路径跟踪效果,较小的前视距离能使机器人更加精确地追踪路径,但可能会引起机器人控制的不稳定甚至震荡;
较大的前视距离可以使机器人跟踪路径更加平滑,但不能精确地跟踪原始的路径,在大转角处会出现曲率大、转向不足的情况。
1.4 特点
- 挑战:预瞄点的选取/前视距离的选择
- 对不连续的轨迹有较好的效果
2. PID算法
PID控制算法是结合比例、积分和微分三种环节于一体的控制算法,PID控制的实质就是根据输入的偏差值,按照比例、积分、微分的函数关系进行运算,运算结果用以控制输出。
PID可以如下表示:
u ( t ) = K p e ( t ) + K i ∫ 0 t e ( τ ) d τ + K d d d t e ( t ) = K p [ e ( t ) + 1 T i ∫ 0 t e ( τ ) d τ + T d d d t e ( t ) ] (1) \tag{1} \begin{matrix} \mathrm{u}(t)&=K_{p} e(t)+K_{i} \int_{0}^{t} e(\tau) d \tau+K_{d} \frac{d}{d t} e(t)\\ &=K_{p} \left[e(t)+\frac{1}{T_i}\int_{0}^{t} e(\tau) d \tau+T_{d} \frac{d}{d t} e(t)\right] \end{matrix} u(t)=Kpe(t)+Ki∫0te(τ)dτ+Kddtde(t)=Kp[e(t)+Ti1∫0te(τ)dτ+Tddtde(t)](1)
任何闭环控制系统的首要任务是要稳(稳定)、准(准确)、快(快速)的响应命令。PID的主要工作就是如何实现这一任务。
PID控制器的比例单元 ( P) 、积分单元(I)和微分单元(D)分别对应目前误差、过去累计误差及未来误差。若是不知道受控系统的特性,一般认为PID控制器是最适用的控制器.
-
增大比例环节将加快系统的响应,它的作用于输出值较快,但不能很好稳定在一个理想的数值,不良的结果是虽较能有效的克服扰动的影响,但有余差出现,过大的比例系数会使系统有比较大的超调,并产生振荡,使稳定性变坏。
-
积分环节能在比例的基础上消除稳态误差,它能对稳定后有累积误差的系统进行误差修整,减小稳态误差。
-
微分环节具有超前作用,对于具有容量滞后的控制通道,引入微分参与控制,在微分项设置得当的情况下,对于提高系统的动态性能指标,有着显著效果,它可以使系统超调量减小,减小震荡,稳定性增加,动态误差减小。
在调整的时候,我们要做的任务就是在系统结构允许的情况下,在这三个参数之间权衡调整,达到最佳控制效果,实现稳、准、快的控制特点。
在实际应用中,主要有以下不足:
-
在实际工业生产过程往往具有非线性、时变不确定,难以建立精确的数学模型,常规的PID控制器不能达到理想的控制效果;
-
在实际生产现场中,由于受到参数整定方法烦杂的困扰,常规PID控制器参数往往整定不良、效果欠佳,对运行工况的适应能力很差。
1. 位置式PID
位置式PID是当前系统的实际位置,与你想要达到的预期位置的偏差,进行PID控制
设采样时间为 T T T ,公式(1)中的积分项可以用下式近似
∫ 0 t e ( τ ) d τ = T ∑ j = 0 k e j \int_{0}^{t} e(\tau) d \tau=T\sum_{j=0}^{k} e_j ∫0te(τ)dτ=Tj=0∑kej
微分项可近似为(后向差分法)
d e ( t ) d t = e k − e k − 1 T \frac{d e\left(t\right)}{d t}=\frac{e_k-e_{k-1}}{T} dtde(t)=Tek−ek−1
故公式(1)化为
u k = K p { e k + T T i ∑ j = 0 k e j + T d T [ e k − e k − 1 ] } = K p e k + K i ∑ j = 0 k e j + K d [ e k − e k − 1 ] (2) \tag{2} \begin{matrix} u_k&=K_{p}\left\{e_k+\frac{T}{T_i} \sum_{j=0}^{k} e_j+\frac{T_{d}}{T}[e_k-e_{k-1}]\right\}\\ &=K_{p} e_k+K_{i} \sum_{j=0}^{k} e_j+K_{d}[e_k-e_{k-1}] \end{matrix} uk=Kp{ek+TiT∑j=0kej+TTd[ek−ek−1]}=Kpek+Ki∑j=0kej+Kd[ek−ek−1](2)
当采样时间足够小时,能够获得最够精确的结果,离散控制过程与连续过程非常接近。
位置式PID的公式有地方写为
u k = K p e k + K i T ∑ j = 0 k e j + K d T [ e k − e k − 1 ] u_k=K_{p} e_k+K_{i}T \sum_{j=0}^{k} e_j+\frac{K_{d}}{T}[e_k-e_{k-1}] uk=Kpek+KiTj=0∑kej+TKd[ek−ek−1]
公式2的写法是把采样时间也并入到积分和微分系数里了。
2. 增量式PID
位置式PID算法有一定的缺点:一是计算量大,需要对e(k)进行累加;二是如果意外出现计算错误,会使执行机构出现大幅度动作,容易发生危险。
增量式 PID 是指数字控制器的输出只是控制量的增量 ∆ u k ∆u_k ∆uk 。 当执行机构需要的控制量是增量,而不是位置量的绝对数值时,可以使用增量式 PID 控制算法进行控制。
增量式 PID 控制算法公式为:
Δ u k = u k − u k − 1 = K p ( e k − e k − 1 ) + K i e k + K d ( e k − 2 e k − 1 + e k − 2 ) = K p ( e k − e k − 1 + T T i e k + T d e k − 2 e k − 1 + e k − 2 T ) = K p ( 1 + T T i + T d T ) e k − K p ( 1 + 2 T d T ) e k − 1 + K p T d T e k − 2 ) = A e k + B e k − 1 + C e k − 2 其中 A = K p ( 1 + T T i + T d T ) B = K p ( 1 + 2 T d T ) C = K p T d T (3) \tag{3} \begin{aligned} \Delta u_{k}&=u_{k}-u_{k-1}\\ &=K_p\left(e_k-e_{k-1}\right)+K_ie_k+K_d\left(e_k-2e_{k-1}+e_{k-2}\right)\\ &=K_p\left(e_{k}-e_{k-1}+\frac{T}{T_i} e_{k}+T_d \frac{e_{k}-2 e_{k-1}+e_{k-2}}{T}\right) \\ &=\left.K_p\left(1+\frac{T}{T_i}+\frac{T_d}{T}\right) e_{k}-K_p\left(1+\frac{2 T_d}{T}\right) e_{k-1}+K_p \frac{T_d}{T} e_{k-2}\right) \\ &= A e_{k}+B e_{k-1}+C e_{k-2} \\ \\ \text { 其中 } \quad \mathrm{A} &=K_p\left(1+\frac{T}{T_i}+\frac{T_d}{T}\right) \\ \mathrm{B}&=K_p\left(1+\frac{2 T_d}{T}\right) \\ \mathrm{C}&=K_p \frac{T_d}{T} \end{aligned} Δuk 其中 ABC=uk−uk−1=Kp(ek−ek−1)+Kiek+Kd(ek−2ek−1+ek−2)=Kp(ek−ek−1+TiTek+TdTek−2ek−1+ek−2)=Kp(1+TiT+TTd)ek−Kp(1+T2Td)ek−1+KpTTdek−2)=Aek+Bek−1+Cek−2=Kp(1+TiT+TTd)=Kp(1+T2Td)=KpTTd(3)
增量式PID根据公式可以很好地看出,一旦确定了 K p 、 K i 、 K d K_p、K_i 、K_d Kp、Ki、Kd,只要使用前后三次测量值的偏差, 即可由公式求出控制增量;
得出的控制量 Δ u k \Delta u_k Δuk对应的是近几次位置误差的增量,而不是对应与实际位置的偏差 ,因此没有误差累积。
3. PID的积分饱和及处理方法
位置式PID在积分项达到饱和时,误差仍然会在积分作用下继续累积,一旦误差开始反向变化,系统需要一定时间从饱和区退出,所以在 u ( k ) u(k) u(k)达到最大和最小时,要停止积分作用,并且要有积分限幅和输出限幅。
1. 积分分离法
积分分离法的基本思路是当被调量与设定值偏差较大时,取消积分作用,以免积分作用使得后期超调量太大;当被控量接近给定值时,重新引入积分控制。
具体方法是依据实际情况人为设定一个阈值 ε \varepsilon ε >0;当e(k)的绝对值大于ε时,取消积分项,采用PD控制;当e(k)绝对值小于等于 ε \varepsilon ε 时,使用通常的PID控制。用公式表达如下:
u ( k ) = K p e ( k ) + β K i ∑ j = 0 k e ( j ) + K d [ e ( k ) − e ( k − 1 ) ] β = { 1 , ∣ e ( k ) ∣ ≤ ε 0 , ∣ e ( k ) ∣ > ε \begin{aligned} u(k) &=K_p e(k)+\beta K_i \sum_{j=0}^k e(j)+K_d[e(k)-e(k-1)] \\ \beta &=\left\{\begin{array}{l}1,|e(k)| \leq \varepsilon \\ 0,|e(k)|>\varepsilon\end{array}\right.\end{aligned} u(k)β=Kpe(k)+βKij=0∑ke(j)+Kd[e(k)−e(k−1)]={1,∣e(k)∣≤ε0,∣e(k)∣>ε
2. 遇限削弱积分法(抗积分饱和算法)
遇限削弱积分法,实现方法是,当控制量进入饱和区时,便不再进行积分项累加,而只执行削弱积分的运算;在计算u(k)时,先判断u(k-1)是否已经超出最大的控制量,如果已经有u(k-1) > Umax,则只累加负偏差;如果已经有u(k-1) < Umin,则只累加正偏差。
使用遇限削弱积分法,可以使得控制量u(k)的计算值不会偏离实际能控制的量太远,这样当需要反向调节时能较快地响应,避免输出长时间停留在饱和区,不会产生过多的超调量。
3. 变速积分法
变速积分法,主要思想是,改变积分项的累加速度:当误差值e(k)绝对值很大时,减慢积分速度;当误差值e(k)绝对值很小时,加快积分速度。
这个方法相当于积分分离法的强化版;积分分离法在误差较大时,直接去除了积分量,误差较小时才引入积分量,属于有和无的变化;而变速积分法,对积分量的调节要缓和一些。
至于加快和减慢由何种方法实现,可以由用户自己定义,最简单的方法就是构造一个随e(k)负相关变化的函数f(e(k))作为系数,在计算积分量时,用e(k)*f(e(k))来代替e(k)累加。
4. PID整定方法
https://blog.csdn.net/zyboy2000/article/details/9418257
传统的PID经验调节大体分为以下几步:
- 关闭控制器的I和D元件,加大P元件,使产生振荡。
- 减小P,使系统找到临界振荡点。
- 加大I,使系统达到设定值。
- 重新上电,观察超调、振荡和稳定时间是否符合系统要求。
- 针对超调和振荡的情况适当增加微分项。
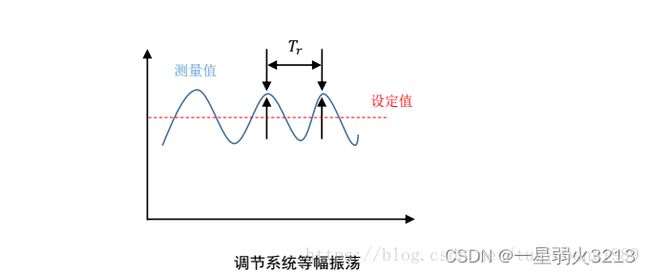
Ziegler-Nichols方法即临界比例度法:
-
首先去除PID控制器中的积分与微分作用,取较小的比例增益Kp值,并投入闭环运行;
-
将Kp由小变大,直至阶跃响应产生等幅振荡;
-
根据下表的经验公式,选择PID参数

-
按照“先P后I最后D”的操作顺序,将经验值参数输入调节器后再次运行调节系统,观察过程变化情况。多数情况下系统均能 稳定运行,如果还未到达理想控制状态,对参数微调即可。
-
有的过程控制系统,当调节器比例度调到最小刻度值时,系统仍不产生等幅振荡,对此将最小刻度的比例度作为临界比例度进 行调节器参数整定。
3. Stanly算法
前轮反馈控制(Front wheel feedback)也就是常说的Stanley方法,其核心思想是基于车辆前轴中心点的路径跟踪偏差量对方向盘转向控制量进行计算。
Stanley方法是一种基于横向跟踪误差的非线性反馈函数,并且能实现横向跟踪误差指数收敛于0。

原理:将总误差分为两部分,即前轮转角控制变量 δ \delta δ由两部分构成:
- 一部分是航向误差引起的转角,即当前车身方向与参考轨迹最近点的切线方向的夹角 θ e \theta_e θe;
- 另一部分是横向误差引起的转角,即前轮速度方向与参考轨迹最近点的切线方向所成的夹角 δ e \delta_e δe。
小结:Pure pursuit与Stanley 算法简单对比
Pure pursuit 与 Stanley 两个方法都是基于对前轮转角进行控制来消除横向误差。
Pure pursuit算法的关键在于预瞄点的选取:其距离越短,控制精度越高,但可能会产生震荡;预瞄距离越长,控制效果趋于平滑,震荡减弱。实际调试只需根据上述规则以及应用需求调整预瞄系数即可。
Stanley 算法的控制效果取决于控制增益,它缺少Pure pursuit算法的规律性,调试时需要花一定精力去寻找合适的控制增益值。
优缺点
- Stanley控制器在平滑路径上具有准确的跟踪性能
- 但在路径曲率处的快速变化会导致较大的跟踪误差
4. 后轮位置反馈
后轮反馈控制(Rear wheel feedback)是利用后轮中心的跟踪偏差来进行转向控制量计算的方法。它属于Frenet坐标系的一个应用。通过选择合适的李雅普诺夫函数设计控制率,只要设计的李雅普诺夫函数能够满足稳定性判据即可。
选择不同的系统方程,和最终不同的 李雅普诺夫形式,可以得到不同的控制率,这些不同的形式都可以使系统稳定。得到控制率后,再考虑如何通过车辆方向盘转角进行控制,使得车辆实际的控制量趋近于期望控制量,可以选择前馈加反馈的形式,前馈就是那个arctan(wL/R)之类的式子,反馈就是pid就行。
5. LQR控制算法
原理:LQR在基本控制理论的基础上,进一步设计一个代价函数,用于优化控制量,使得代价函数的值尽可能地小
代价函数一般设置为系统达到稳定状态以及状态偏差最小和控制量较小。
研究对象为以状态空间方程形式给出的线性系统。
这是一个典型的多目标无约束优化问题,选取代价函数(目标函数)为
J = 1 2 ∫ 0 ∞ x T Q x + u T R u d t J=\frac{1}{2} \int_{0}^{\infty} x^{T} Q x+u^{T} R u d t J=21∫0∞xTQx+uTRudt
其中,Q、R分别是需要设计的半正定矩阵和正定矩阵。
代价函数 J J J需要达到最小值,那么在 t t t趋近于无穷时,状态向量 x ( t ) x(t) x(t)肯定趋近于0,即是达到了系统稳态;同理, t t t趋近于无穷时,控制向量 u ( t ) u(t) u(t)也会趋近于0,意味着,随着时间的推移,需要对系统施加的控制量会越来越小,意味着使用最小的控制量使得系统达到了最终控制目标,反映的是控制能量的损耗优化。
Q Q Q为半正定的状态加权矩阵, R R R为正定的控制加权矩阵,两者通常取为对角阵。 Q Q Q矩阵元素变大意味着希望状态量能够快速趋近于零; R R R 矩阵元素变大意味着希望控制输入能够尽可能小,它意味着系统的状态衰减将变慢。比如, Q 11 Q_{11} Q11选取较大的值,会让 x 1 x_1 x1很快的衰减到0;所以, Q 、 R Q、R Q、R的选取,要综合看具体的实际应用场景来调节。
在轨迹跟踪中,前一项优化目标表示跟踪过程路径偏差的累积大小,第二项优化目标表示跟踪过程控制能量的损耗,这样就将轨迹跟踪控制问题转化为一个最优控制问题。
求解方法:
-
使用osqp库优化求解
-
求解代数里卡提方程
连续LQR的算法步骤如下:
- 选择参数矩阵Q,R(分别满足半正定和正定)
- 求解Riccati方程得到矩阵P
- 根据P计算增益 K = R − 1 B T P K=R^{-1}B^{T}P K=R−1BTP
- 计算控制量 u ∗ = − K x u^*=-Kx u∗=−Kx
离散情况下的LQR推导有最小二乘法和动态规划算法。
离散时间下的LQR算法步骤
采用LQR算法进行控制率求解的步骤概括为:
-
确定迭代范围 N N N,预设精度 E P S EPS EPS
-
设置迭代初始值 P = Q f P=Q_{f} P=Qf,其中 Q f = Q Q_f=Q Qf=Q
-
循环迭代, t = 1 , … , N t=1, \ldots, N t=1,…,N
P n e w = Q + A T P A − A T P B ( R + B T P B ) − 1 B T P A P_{new}=Q+A^{T} P A-A^{T} P B\left(R+B^{T} P B\right)^{-1} B^{T} P A\\ Pnew=Q+ATPA−ATPB(R+BTPB)−1BTPA
若 ∣ ∣ P n e w − P ∣ ∣ < E P S ||P_{new}-P||∣∣Pnew−P∣∣<EPS :跳出循环;否则: P = P n e w P=P_{new} P=Pnew -
计算反馈系数 K = − ( R + B T P n e w B ) − 1 B T P n e w A K=-\left(R+B^{T} P_{new}B\right)^{-1} B^{T} P_{new} A K=−(R+BTPnewB)−1BTPnewA
-
最终得优化的控制量 u ∗ = K X u^{*}=K X u∗=KX
6. MPC算法
MPC是一种基于模型的优化控制策略。主要包括预测模型,滚动优化,反馈校正三个部分。
-
其优点在于具有显式处理约束的能力。这是因为:将约束加到未来的输入,输出或者状态量上,就可以改变模型对于系统未来动态行为的预测,且可以将约束放在一个在线求解的二次规划或者非线性规划问题中。
-
MPC控制器优化得到的控制输出也是系统在未来有限时间步的控制序列。 当然,由于理论构建的模型与系统真实模型都有误差,所以,实际上更远未来的控制输出对系统控制的价值很低,故MPC仅执行输出序列中的第一个控制输出。
原理总结:在有约束的前提下(凸约束),寻找一组控制序列,使得优化函数在未来N步中的值尽可能地小,同时只执行第一个动作,进行滚动优化。
优缺点:
- 优点
考虑了实际约束, 是LQR算法的改进版本,相比起LQR算法要更加准确 - 缺点
计算量稍大
6.1 整体流程
将预测状态估计的部分称为预测区间(Predictive Horizon),指的是一次优化后预测未来输出的时间步的个数。
将控制估计的部分称为控制区间(Control Horizon),在得到最优输入之后,我们只施加当前时刻的输入u(k),即控制区间的第一位控制输入。
过小的控制区间,可能无法做到较好的控制,而较大的控制区间,比如与预测区间相等,则会导致只有前一部分的控制范围才会有较好的效果,而后一部分的控制范围则收效甚微,而且将带来大量的计算开销。
模型预测控制在k时刻共需三步;
-
第一步:获取系统的当前状态;
-
第二步:基于 u ( k ) , u ( k + 1 ) , u ( k + 2 ) . . . u ( k + m ) u(k),u(k+1),u(k+2)...u(k+m) u(k),u(k+1),u(k+2)...u(k+m)进行最优化处理;
离散系统的代价函数可以参考
J = ∑ k m − 1 E k T Q E k + u k T R u k + E N T F E N J=\sum_{k}^{m-1}E_k^TQE_k+u_k^TRu_k+E_N^TFE_N J=k∑m−1EkTQEk+ukTRuk+ENTFEN
其中 E N E_N EN表示误差的终值,也是衡量优劣的一种标准。
-
第三步:只取 u ( k ) u(k) u(k)作为控制输入施加在系统上。
在下一时刻重复以上三步,在下一步进行预测时使用的就是下一步的状态值,我们将这样的方案称为滚动优化控制(Receding Horizon Control)。

6.2 MPC与LQR比较
从以下几个方面进行阐述:
- 研究对象:是否线性化
- 状态方程:是否离散化
- 目标函数:误差和控制量的极小值
- 工作时域:预测时域,控制时域,滚动优化,求解一次
- 求解方法:QP求解器,变分法求解黎卡提方程
- LQR和MPC的优缺点:滚动优化,求解时域,实时性,算力,工程常用方法
不同点
-
首先,LQR的研究对象是线性系统,而MPC的研究对象可以是线性系统,也可以是非线性系统。不过现在很多的做法都是将非线性系统线性化,然后进行相关计算,具体要根据自己的工程情况来确定哪种方式比较好。
-
其次,MPC的目标函数,一般都是多个优化目标乘以不同权重然后求和的方式。虽然方式不同,不过都是对达到控制目标的代价累计。
-
最后,工作时域上的不同,LQR的计算针对同一工作时域,在一个控制周期内,LQR只计算一次,并将此次计算出的最优解下发给控制器即可;而MPC是滚动优化的,在每一个采样周期内计算得到一组控制序列,但是只是将第一个控制的值发给控制器。
-
LQR没有考虑到约束,MPC独有的带约束以及有限时间窗口的滚动优化,可以实现较为理想的控制
-
MPC仅考虑未来几个时间步,一定程度上牺牲了最优性。
6.3 MPC 特点
-
基于模型的预测
在MPC算法中,需要一个描述对象动态行为的模型,这个模型的作用是预测系统未来的动态。即能够根据系统k时刻的状态和k时刻的控制输入,预测到k+1时刻的输出。在这里k时刻的输入正是用来控制系统k+1时间的输出,使其最大限度的接近k+1时刻的期望值。故我们强调的是该模型的预测作用,而不是模型的形式。
-
滚动优化
因为外部干扰和模型失配的影响,系统的预测输出和实际输出存在着偏差,如果测量值能测到这个偏差,那么在下一时刻能根据这个测量到偏差的测量值在线求解下一时刻的控制输入,即优化掉了这个偏差值。若将求解的控制输出的全部序列作用于系统,那么k+1时刻的测量值不能影响控制动作,也就是说测量值所包括的外部干扰或模型误差信息得不到有效利用。故我们将每个采样时刻的优化解的第一个分量作用于系统,在下一个采样时刻,根据新得到的测量值为初始条件重新预测系统的未来输出并求解优化解,继续讲这个时刻的优化解的第一个分量作用于系统,这样重复至无穷。
故预测控制不是采用一个不变的全局优化目标,而是采用时间向前滚动式的有限时域优化策略。这也就是意味着优化过程不是一次离线进行,而是反复在线进行的。
路径规划部分
7. Dijkstra算法
迪杰斯特拉算法是从一个节点遍历其余各节点的最短路径算法,解决的是有权图中最短路径问题。它的主要特点是以起始点为中心向外层层扩展(广度优先遍历思想),直到扩展到终点为止。是图搜索算法的一种。
- 引进两个点集S和U。初始时S中只有一个起点,S的作用是记录已求出最短路径的节点(以及相应的最短路径长度);而U则是记录还未确定最短路径的节点(以及该节点到起点D的距离)。
- 初始时,数组S中只有起点D,而数组U中是除起点D之外的节点集合,并且数组U中记录各节点到起点D的距离。如果节点与起点D不相邻,距离设为无穷大。
- 然后,从数组U中找出路径最短的节点K,并将其加入到数组S中;同时,从数组U中移除节点K。接着,更新数组U中的各节点到起点D的距离。
- 不断重复这个过程,直到遍历完所有节点。
7.1 算法说明
Dijkstra算法过程包括了三个循环,第一个循环的时间复杂度为 O ( n ) O(n) O(n),第二、三个循环为循环嵌套,时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
可以看出,Dijkstra最短路径算法的执行时间和占用空间与图(或网)中结点数目有关,当结点数目较大时,Dijkstra算法的时间复杂度急剧增加。当图规模较大时,直接应用该算法就会存在速度慢或空间不够的问题。所以在大的城市交通网络图中直接应用Dijkstra最短路径算法是很困难的。
路径规划作为无人驾驶汽车导航系统的重要功能模块,其算法的优劣是非常重要的,评价该算法的主要性能指标是它的实时性和准确性。Dijkstra算法作为经典的路径规划算法,在实验地图数据量较小情况下会得到很好的规划结果,但在实验地图数据量较大情况下很难满足路径规划的实时性要求。
7.2 最短路径的最优子结构性质
如果 P ( i , j ) = { V i … V k … V m … V j } P(i,j)=\{V_i…V_k…V_m…V_j\} P(i,j)={Vi…Vk…Vm…Vj}是从顶点 i i i到 j j j的最短路径, k k k和 m m m是这条路径上的一个中间顶点,那么 P ( k , m ) P(k,m) P(k,m)必定是从 k k k到 m m m的最短路径。
证明:反证法
假设 P ( i , j ) = { V i … V k … V m … V j } P(i,j)=\{V_i…V_k…V_m…V_j\} P(i,j)={Vi…Vk…Vm…Vj}是从顶点 i i i到 j j j的最短路径,则有 P ( i , j ) = P ( i , k ) + P ( k , m ) + P ( m , j ) P(i,j)=P(i,k)+P(k,m)+P(m,j) P(i,j)=P(i,k)+P(k,m)+P(m,j)。而 P ( k , m ) P(k,m) P(k,m)不是从 k k k到 m m m的最短距离,那么必定存在另一条从 k k k到 m m m的最短路径 P ′ ( k , m ) P'(k,m) P′(k,m),那么 P ( i , j ) = P ( i , k ) + P ′ ( k , m ) + P ( m , j ) < P ( i , j ) P(i,j)=P(i,k)+P'(k,m)+P(m,j)
8. A星算法
https://blog.csdn.net/weixin_44332774/article/details/107214754
8.1 算法原理
A*(A-Star)算法是一种静态路网中求解最短路径最有效的直接搜索方法,也是解决许多搜索问题的有效算法,广泛应用于室内机器人路径搜索、游戏动画路径搜索等。它是图搜索算法的一种。
A*算法是一种启发式的搜索算法,它是基于深度优先算法(Depth First Search, DFS)和广度优先算法(Breadth First Search, BFS)的一种融合算法,按照一定原则确定如何选取下一个结点。
启发式搜索算法指的是,从起点出发,先寻找起点相邻的栅格,判断它是否是最好的位置,基于这个最好的栅格再往外向其相邻的栅格扩展,找到一个此时最好的位置,通过这样一步一步逼近目标点,减少盲目的搜索,提高了可行性和搜索效率。
深度优先搜索算法的思想是,搜索算法从起点开始进行搜索(初始状态下待搜索区域内所有结点均未被访问),与周围所有邻点进行比较,选择其中距离终点最近的点进行存储,然后再以该邻点为基础对比其周围未被访问的所有邻点,仍然选择距离终点最近的邻点存储。若访问结点到达终点或访问完所有结点仍未到达终点,则视为搜索失败。成功搜索所存储的结点连接而成的路径即为起点到终点的路径。
广度优先搜索的原理是,从初始点出发依次访问与它相连接的邻点,访问完毕后再从这些邻点出发访问邻点的邻点,但是要保证先被访问的邻点的邻点要比后被访问的邻点的邻点先访问,直至图中所有已被访问的结点的邻点都被访问到。如果此时图中尚有未被访问的结点,则需要选取一个尚未被访问的结点作为个新的初始点,继续搜索访问,直到图中所有的结点都被访问一遍为止。
因此深度优先算法与广度优先搜索算法从过程上存在较大差异。深度优先算法优先选择离目标点最近的结点,而广度优先搜索算法优先选择离初始点最近的点。基于深度优先算法,能以最快的速度找到一条连接初始点到目标点的路径,但不能保证路径的最优性(例如以路径最短为标准);广度优先搜索算法则必然能找到最短的路径,但由于需要遍历所有的结点,其计算复杂程度更大。基于这两种算法的优缺点,A*算法基于启发函数构建了代价函数,既考虑了新结点距离初始点的代价,又考虑了新结点与目标点距离的代价。
-
A*算法使用一个路径优劣评价公式(启发函数)为:
f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n)- f(n) 是从初始状态经由状态n到目标状态的代价估计,
- g(n) 是从初始状态到状态n的实际代价,
- h(n) 是从状态n到目标状态的最佳路径的估计代价。
-
A*算法需要维护两个状态表,分别称为
openList表和closeList表。openList表由待考察的节点组成,closeList表由已经考察过的节点组成。 -
启发函数可以根据需求设计。
8.2 算法步骤
-
首先把起点加入 openList 。
-
重复如下过程:
-
遍历 openList ,查找 F 值最小的节点,把它作为当前要处理的节点。
-
把这个节点移到 closeList 。
-
对当前方格的 8 个相邻方格:
◆ 如果它是不可抵达的或者它在 closeList 中,忽略它;
◆ 如果它不在 openList 中,则把它加入 openList ,并且把当前方格设置为它的父节点,记录该方格的 f , g , h f,g,h f,g,h值。
◆ 如果它已经在 openList 中,检查这条路径 ( 即经由当前方格到达它那里 ) 是否更好,用 g g g 值作参考,更小的 g g g 值表示这是更好的路径。如果 g g g值更小,把该节点的父节点设置为当前方格,并重新计算它的 g g g 和 h h h 值。
-
-
停止搜索的情况有两种:
-
把终点加入到了openList 中,此时路径已经找到了
-
查找终点失败,并且 openList 是空的,此时没有路径。
-
-
保存路径。使用回溯的方法,从终点开始,每个方格沿着父节点移动直至起点,这就是最终搜索到的路径。
8.3 优缺点
A星算法比Dijkstra算法厉害在使用了启发信息。
8.4 启发函数可以高估还是低估?
参考:https://www.zhihu.com/question/39866705
直观理解:A算法每次按照估价函数最小的原则来选取节点。假设估价函数估计的代价等于实际代价,那么我直接就选取到最优路径上的各个节点了;而A算法中估价函数估计的代价总是比实际代价更小一点,并且随着选取节点数量的增多,估价函数估计的代价越来越接近于实际代价,从而不存在选取了更长路径的情况。(因为如果存在更短的路径,那么它的估计代价应该更小,因此优先被选取)。


8.5 A星优化
参考:https://blog.csdn.net/qq_42391248/article/details/119727974
优化A*一般从以下四个方面着手
-
openlist(开放集合)
-
getNeighbour(获取当前节点的邻居节点)
-
F=G+H+C(启发式函数)
-
map(地图)
1. 长距离导航
当距离很大,中间有很多障碍物时,A星的算法就会遇到瓶颈,不断加入的可行走点使得排序速度越来越慢,最后可能造成CPU阻塞无法动弹。其实路径不是非得实时计算出来才好,我们可以把一些常用的路径,在离线下算好放在数据文件中,游戏开启时放在内存里,当需要寻路到那个节点或者那个节点附近时,就可以取出来直接使用,而不再需要计算。
比如 A到B 我们已经算法路径并存放在了内存里,当我们在A附近,要寻路到B附近时,就可以先寻路到A,再调出A到B的路径,再计算B到目的的路径。
另一种方法为制作导航点的方式。比如在一座城市里,有4个出口点,这个4个出口点就可以称为导航点,去目的地的路上肯定会经过这4个点的其中一个,我们在寻路时可以先寻找到最近的一个出口的导航点,当到达导航点后,再次寻找到目的地去的路径,有可能在这条路径上,还有一些导航点,继续寻找最近的导航点,依次类推,直到没有导航点可寻时,则直接寻路到目的地。
2. A星的排序算法优化
每次插入open列表的点后,open就不再是有序的队列了,所以每次去拿最小值时都需要重新排序。排序的时间消耗随着队列长度的增大而增大,其实有很大一部分A星的性能消耗都在排序上。
其实可以不排序,而使用找到插入位置并插入的方法,让队列永远保持有序状态。因为open队列在插入前是有序的,所以我们可以选用二分查找算法来找到插入的位置。每次插入时都使用二分查找算法查找插入点,那么每次的插入复杂度为 O ( log N ) O(\log N) O(logN),比快排一次的 O ( N log N ) O(N\log N) O(NlogN)要快很多。
3. 多次频繁A星寻路的优化
多次频繁寻路中,对A星算法中每个运算,每行代码的运算细节都会有比较重大的考验。
- 比如我们在查看一个节点是否为被取过的节点,即是否为Close,很多人都会在Close里取寻找该节点是否存在,这个操作明显就没有考虑到性能的消耗,要在Close列表中找节点,就相当于遍历一遍所有已经找过的节点,Close里的节点越多,越浪费CPU,而且是不只一次浪费,每个循环都会浪费一次,性能消耗巨大。
- 因此我们通常的做法是把节点作为一个实例,在实例中添加IsClose的变量,来判断是否被取过,或者说是否Close。
但这种方法还是不够,因为IsClose变量是要初始化的,每次寻路都要将前面寻路过的痕迹抹去才能开始全新的寻路过程。
这就是又一个被很多人忽视的初始化的性能消耗,每次在A星寻路开始前,需要将IsClose的变量初始化为false,就需要遍历整个数据来初始化。每次都要遍历整个数据的话,A星算法无论优化的多快都无济于事了,因为初始化的性能消耗就已经将A星的性能消耗完全盖掉了。如果初始化的性能消耗需要遍历整个数据,那么优化A星算法的意义何在。
其实可以用一个变量就能判断IsClose的方法,无需初始化。 - 我们可以在寻路类中设置一个属性变量FindIndex,或者专门为寻路服务的静态变量也可以,而每个寻路节点中也存有一个变量FindIndex,每次寻路前都对FindIndex++,在判断IsClose时,当节点中的FindIndex与寻路类中FindIndex一致时说明已经被当次寻路算法取出过,否则两者不一样,说明这个节点没有被取出过,当节点被取出时,节点里的FindIndex则设置为当前寻路类中的FindIndex值,以表明该节点已经被这次寻路算法取出过。
8. 混合A星算法
基本介绍
混合A星可以看成是探索树方法和A星算法的混血儿。混合A星算法使用了两种启发信息的组合,这两种启发一种“考虑机器人运动约束不考虑环境障碍物”,一种刚好相反“不考虑运动约束考虑障碍物”,如下图所示。这个“考虑运动约束不考虑障碍物”的启发信息就是大名鼎鼎的Reeds-Shepp曲线的长度,“不考虑运动约束考虑障碍物”的启发信息就是传统A星算法搜索到目标的路径的长度。混合A星算法选择两者的最大值作为最终的启发信息。为什么要使用这两种启发信息?作者是这样解释的,使用第一种(“考虑约束不考虑障碍物”)是为了防止机器人从错误的方向到达目标,作者说实际实验中使用这种启发比不使用的效率提高了一个数量级,看来是必不可少了。使用第二种(“考虑障碍物不考虑约束”)是为了防止在断头路或者U型障碍物里浪费时间。有没有同时既考虑运动约束也考虑障碍物的启发信息呢?目前还没有。

启发信息唯一的作用是给搜索算法提供指引、让算法更“聪明”,从而优先搜索有可能产生解的区域,不要在没必要的区域浪费时间。因为搜索的范围越多计算量越大效率越低,所以启发信息提供的指导越准确,最终算法的效率就越高。启发信息既然只是提供指导,那么它的计算量就不能太大,不能喧宾夺主,要是计算量太大就没有意义了。
混合A星使用的Reeds-Shepp曲线的长度和A星得到的最优解不是非常快(跟欧式距离比),但是还是可以接受的。作者也发现了,Reeds-Shepp曲线和A星得到的最优解这两个启发信息既然不依赖障碍物,那就可以提前把所有离散节点的启发信息一次性都算好存起来,然后在搜索过程中直接查询,这种用空间换时间的策略也是一种解决办法。启发信息必须满足一些要求,最重要的一个要求是,不能高估,可以低估。低估的意思是启发信息的大小比实际解的值要小,即便你不知道实际解的值(比如最短距离),但是你可以估计它的下限。这里采用的两个启发信息都是低估,所以是合理的,从两个低估里取最大值当然还是低估,所以仍然是合理的。
栅格问题
栅格就是对空间的一种划分,当然不是唯一的划分方式。栅格在混合A星方法中起到什么作用呢,或者说为什么要使用栅格?仅仅是为了继承A星的特点吗。如果是这样的话,那么栅格并不是必须的。为什么呢?因为每次的扩展都会产生有限的子节点,同理子节点的子节点也是有限个的,所以直接对子节点应用A星搜索的代价计算方法和选择方法就可以了。所以混合A星使用栅格真正的目的是限制节点对空间的覆盖。
共占栅格问题
在扩展子节点的时候,如果移动的距离比栅格的范围小,那就有可能与自己的父节点位于同一个栅格,下图展示了这种情况。
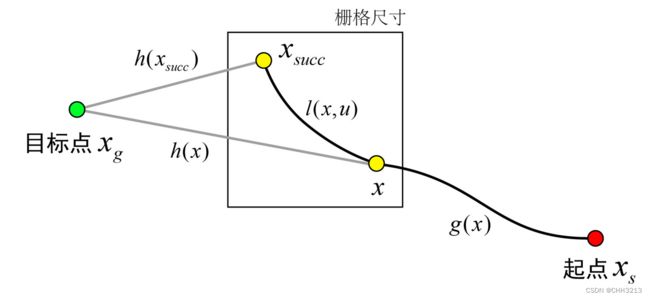
在这种情况下,子节点 x s u c c x_{succ} xsucc的代价值永远大于父节点 x x x的代价值,由于 A ∗ A^* A∗算法总是优先挑选代价值小的节点,所以后果就是子节点 x s u c c x_{succ} xsucc永远不会被选中。看上图,假设父节点 x x x的已用代价是 g ( x ) g(x) g(x),它的启发代价是 h ( x ) h(x) h(x) 。子节点扩展的代价是 l ( x , u ) l(x,u) l(x,u),子节点 x s u c c x_{succ} xsucc的启发代价是 h ( x s u c c ) h(x_{succ}) h(xsucc),启发函数总是具有consistent的性质,因此满足三角形不等式:三角形任意两边长之和大于第三边长,所以有 l ( x , u ) + h ( x s u c c ) > h ( x ) l(x,u)+h(x_{succ})>h(x) l(x,u)+h(xsucc)>h(x),虽然扩展的边不是直线但是必然不会比直线短,所以不等式总是成立。又因为父节点 x x x的总代价 f ( x ) = g ( x ) + h ( x ) f(x)=g(x)+h(x) f(x)=g(x)+h(x),而子节点 x s u c c x_{succ} xsucc的总代价 f ( x s u c c ) = g ( x ) + l ( x , u ) + h ( x s u c c ) f(x_{succ})=g(x)+l(x,u)+h(x_{succ}) f(xsucc)=g(x)+l(x,u)+h(xsucc),所以很显然下式成立(当然前提是代价都是正数)。
g ( x ) + l ( x , u ) + h ( x s u c c ) > g ( x ) + h ( x ) g(x)+l(x,u)+h(x_{succ})>g(x)+h(x) g(x)+l(x,u)+h(xsucc)>g(x)+h(x)
为了解决这个问题,作者提出了放大父节点代价的思想,具体就是给父节点的总代价加一个常数。这个常数记为tieBreaker(“tie break”翻译为“打破僵局”),它是个正数。如果 f ( x s u c c ) < f ( x ) + t i e B r e a k e r f(x_{succ})
如果子节点与父节点占据同一个栅格,那就不能再把子节点的前向指针指向父节点,而应该换成爷爷节点(也就是父节点的父节点) 。
但是如果子节点的前向指针指向爷爷节点可能又会导致另一个问题,中间会空出一部分。因为运动约束,每个节点都是从唯一的父节点通过运动方程递推生成的,直接将前向指针指向爷爷节点会导致这段路径不符合机器人约束,因为你改变了出发点。
在百度的无人驾驶项目中的混合A*代码中,直接将扩展的距离设置成了栅格的对角线。因为对角线是一个栅格能容纳的最大距离(仅对直线来说),这样便可以保证子节点与父节点不会占据一个栅格。也因为采用了这样的设计,百度没有考虑这种共占的情况,所以也没有进行判断。
算法特点
需要设置的参数有:
- 机器人控制量采样值
- 空间离散的分辨率。空间离散的分辨率如何选择呢?机器人每次运动的距离如何设置呢,显然与空间分辨率有关,如果分辨率太小,计算量就太大;如果分辨率太大,机器人运动距离太小,那么每次生成的节点都在一个栅格里,探索树就没办法扩展。
启发函数如何选取?
论文中讨论了几种启发函数,一种是考虑约束但不考虑障碍物的RS曲线的长度,一种是不考虑约束但是考虑障碍物的普通A星算法搜索出来的路径长度。
● 混合A星适用于什么场景?
存在障碍物的环境,低速、有运动约束的机器人或无人车。在无人驾驶上具体可以用于停车场的自动泊车的路径规划。
● 混合A星的缺点是什么?
混合A星一个比较大的问题是,它输出的路径质量一般比较差,这里差的意思是指路径包含一些不必要的拐弯或者倒车动作,这就是为什么一般在混合A星之后再优化一下,或者把混合A星当成一个给优化算法提供初始路径的子模块,而不是单独使用。
还有,混合A星也是一种依赖分辨率的方法,受制于分辨率,它要么有可能找不到解,要么花的时间太多,实时性不好。
算法改进
- 双向探索,即不仅在起点向终点扩展,也从终点向起点扩展。这在终点障碍物密集时比较有效。
- 变分辨率,不使用均匀一致的分辨率,在障碍物附近使用较高的分辨率,远离障碍物时使用低分辨率,减少不必要的计算。
- 轨迹片段仿真使用连续变化的控制量。
前进后退
混合A星算法输出的是一条路径,该路径由一连串离散的坐标点组成。如果你想在路径基础上添加速度构成一条轨迹,可以这么做:前进时设置速度为正值,后退时设置速度为负值,在前进和后退相接的点设置速度为0。这样做需要判断什么时候是前进,什么时候是后退。判断方法是计算机器人航向角 θ r \theta_r θr与相邻路径点构成的向量 θ p \theta_p θp的夹角 Δ θ \Delta\theta Δθ。
9. RRT算法
9.1 基于随机采样的路径规划算法
-
基于随机采样的路径规划算法适用于高维度空间,它们以概率完备性(当时间接近无限时一定有解)来代替完备性,从而提高搜索效率。
-
基于随机采样的运动规划算法的基本思路是:通过对状态空间均匀随机采样来构建一个连通图,当初始、目标状态都在图中或者都可以连接到图中时,则问题得以解决。基于随机采样的算法不需要对状态空间自由区域进行显式建模,由碰撞检测来验证轨迹的可行性即可。
-
基于随机采样的路径规划算法又分为单查询算法(single-query path planning)以及渐近最优算法(asymptotically optimal path planning),前者只要找到可行路径即可,侧重快速性,后者还会对找到的路径进行逐步优化,慢慢达到最优,侧重最优性。单查询方法包括概率路图算法(Probabilistic Road Map, PRM)、快速随机扩展树算法(Rapidly-exploring Random Tree, RRT)、RRT-Connect算法等,渐近最优算法有RRT*算法等。
9.2 算法原理
-
RRT算法是一种单查询算法,目标是尽可能快的找到一条从起点到终点的可行路径。
-
RRT算法模拟树木生长时树根不断向四周扩散的过程。
-
如下图,
- 算法通常将起点作为根节点 x i n i t x_{init} xinit,加入到随机树的节点集合中。
- 从可行区域内随机选取一个节点 x r a n d x_{rand} xrand,并在已生成的树中利用欧氏距离判断距离 x r a n d x_{rand} xrand最近的点 x n e a r x_{near} xnear。
- 从 x n e a r x_{near} xnear与 x r a n d x_{rand} xrand的连线方向上扩展固定步长 u u u,得到新节点 x n e w x_{new} xnew(如果 x n e a r x_{near} xnear与 x r a n d x_{rand} xrand间的距离小于步长,则直接将 x r a n d x_{rand} xrand作为新节点 x n e w x_{new} xnew)。
- 若 x n e w x_{new} xnew和 x n e a r x_{near} xnear之间无障碍物,将 x n e w x_{new} xnew加入到随机树的节点集合中,同时将 x n e a r x_{near} xnear作为 x n e w x_{new} xnew的父节点,将边 ( x n e a r , x n e w ) (x_{near},x_{new}) (xnear,xnew)加入到随机树的边集中
- 若这两个节点间有障碍物,则重新选择 x n e a r x_{near} xnear并进行扩展。
- 循环执行以上步骤,直到随机树的叶节点包含了目标点,并从中找出一条各节点连接成的从起点至终点的无碰撞路径。

上述是基础的RRT算法流程,它的采样过程是完全随机的,但是我们可以在采样时以一定的概率直接采样终点作为 x r a n d x_{rand} xrand ,加快搜索速度。
9.3 RRT算法的优缺点
优点
RRT算法适用范围广、参数简单、高维空间规划性能优秀。既能够用于机械臂的运动力学规划,也可用于机器人或无人机等进行路径规划。
在使用 RRT算法进行路径规划时,若能够获得全局环境并进行建模,可进行全局路径规划。若无法获得全局环境,如自动驾驶汽车路径规划问题,能够在动态规划中对局部地图进行规划以生成局部路径,也为无人机等高维空间的路径规划提供了可行方案。
缺点
在扩展节点时从无障碍区域内随机选择节点,会导致产生部分无用节点,节点利用率低,增加算法随机性的同时也降低了算法的收敛速度。
由于随机树扩展时会判断 x n e a r x_{near} xnear和 x r a n d x_{rand} xrand连线方向上有无障碍物,若有障碍物则会放弃在该方向上扩展节点。 因此当路径中包含障碍物之间形成的狭窄通道时,使用RRT算法规划路径有一定几率无法规划出最优路径。
10. RRT-Connect算法
- RRT-Connect算法在RRT的基础上引入了双树扩展环节,分别以起点和目标点为根节点同时扩展随机树从而实现对状态空间的快速搜索。
- 当两棵树建立连接时可认为路径规划成功。
- 通过一次采样得到一个采样点 ,然后两棵搜索树同时向采样点方向进行扩展,加快两棵树建立连接的速度。相较于单树扩展的RRT算法,RRT-Connect加入了启发式步骤,加快了搜索速度,对于狭窄通道也具有较好的效果。
10.1 算法步骤
- 每一次迭代中,开始步骤与原始的RRT算法一样,都是采样随机点然后进行扩展。
- 然后扩展完第一棵树的新节点 _{} qnew后,以这个新的目标点 _{} qnew作为第二棵树扩展的方向。
- 同时第二棵树扩展的方式略有不同,首先它会扩展固定步长得到 ′ ′_{} q′new,如果没有碰撞,继续往相同的方向扩展第二步,直到扩展失败或者 ′ = ′_{}=_{} q′new=qnew表示与第一棵树相连了,即connect了,整个算法结束。
- 每次迭代中必须考虑两棵树的平衡性,即两棵树的节点数的多少(也可以考虑两棵树总共花费的路径长度),交换次序选择“小”的那棵树进行扩展。
10.2 RRT-Connect的特点
这种双向的RRT技术具有良好的搜索特性,比原始RRT算法的搜索速度、搜索效率有了显著提高。
- 首先,Connect算法较之前的算法在扩展的步长上更长,使得树的生长更快;
- 其次,两棵树不断朝向对方交替扩展,而不是采用随机扩展的方式,特别当起始位姿和目标位姿处于约束区域时,两棵树可以通过朝向对方快速扩展而逃离各自的约束区域。
- 这种带有启发性的扩展使得树的扩展更加贪婪和明确,使得双树RRT算法较之单树RRT算法更加有效。
RRT-Connect和RRT一样,都是单查询算法,最终路径并不是最优的。
11. RRT*算法
RRT*算法是一种渐近最优算法,属于RRT算法的优化。
渐近最优的意思是随着迭代次数的增加,得出的路径是越来越优化的,因此要想得出相对满意的优化路径,需要一定的运算时间。
算法流程与RRT算法流程基本相同,不同之处主要在于两个地方:
-
首先,重新为 x n e w x_{new} xnew选择父节点。
- 不同于RRT中直接选择 x n e a r e s t x_{nearest} xnearest作为 x n e w x_{new} xnew的父节点,我们需要重新为 x n e w x_{new} xnew选择父节点,使得 x n e w x_{new} xnew到起点的cost能够最小。至于cost的定义,可以是路径的长度。
- 父节点的选择可以是该节点附近相连的所有点,一般是在新产生的节点 x n e w x_{new} xnew 附近以定义的半径范围 r r r内寻找所有的近邻节点 X n e a r X_{near} Xnear,作为替换 x n e w x_{new} xnew 原始父节点 x n e a r x_{near} xnear 的备选
- 我们需要依次计算起点到每个近邻节点 X n e a r X_{near} Xnear 的路径代价 加上 近邻节点 X n e a r X_{near} Xnear 到 x n e w x_{new} xnew 的路径代价,取路径代价最小的近邻节点 x m i n x_{min} xmin作为 x n e w x_{new} xnew 新的父节点
-
其次,就是在重新选完父节点后,为该节点的所有近邻节点重新布线,即
rewire,布线的原则是使所有节点到起点的cost最小
示意过程如下:

12. PRM算法
12.1 算法原理
概率路图算法是一种典型的基于采样的路径规划方法。它主要分为两个阶段:学习阶段, 查询阶段。
学习阶段
应用PRM算法进行路径规划时,首先在将连续空间转换成离散空间后,在离散空间中采样一个无碰撞的点(随机撒点,剔除落在障碍物上的点),以该点为中心,在一定的半径范围内搜索其邻域点,并将其连接形成路径,随后进行碰撞检测,若无碰撞,则保留该路径。
查询阶段
当空间中所有采样点均完成上述步骤后,再应用图搜索算法搜索出可行路径。
12.2 PRM算法的优缺点
优点
该算法原理简单,容易实现,只需要调整参数即可实现不同场景的路径规划,且不需要对环境中的障碍物进行精确建模,在高维空间和动态环境中的路径规划有很大优势。
缺点
但该算法存在狭窄通路问题: 空白区域采样点密集,障碍物密集处采样点又相对较少,可能无法得到最短路径。而且参数的设置对路径规划的结果影响较大,采样点的数量、邻域的大小设置不合理均可能导致路径规划失败(如采样点设置过少导致生成的路径过少未覆盖起终点、邻域设置过大导致过多的路径无法通过碰撞检测)。
所以PRM是概率完备且不最优的算法。
13. 人工势场法
13.1 基本思想
-
人工势场法的基本思想是在障碍物周围构建障碍物斥力势场,在目标点周围构建引力势场,类似于物理学中的电磁场
-
被控对象在这两种势场组成的复合场中受到斥力作用和引力作用,斥力和引力的合力指引着被控对象的运动,搜索无碰的避障路径。
-
更直观而言, 势场法是将障碍物比作是平原上具有高势能值的山峰, 而目标点则是具有低势能值的低谷。
-
引力势场主要与汽车和目标点间的距离有关, 距离越大, 汽车所受的势能值就越大; 距离越小, 汽车所受的势能值则越小
-
决定障碍物斥力势场的因素是汽车与障碍物间的距离, 当汽车未进入障碍物的影响范围时, 其受到的势能值为零; 在汽车进入障碍物的影响范围后, 两者之间的距离越大, 汽车受到的势能值就越小, 距离越小, 汽车受到的势能值就越大。
13.2 缺点与改进
1. 目标不可达的问题
由于障碍物与目标点距离太近,当汽车到达目标点时,根据势场函数可知,目标点的引力降为零,而障碍物的斥力不为零,此时汽车虽到达目标点, 但在斥力场的作用下不能停下来,从而导致目标不可达的问题。
2. 陷入局部最优的问题
车辆在某个位置时,无法向前搜索避障路径。
出现局部最优主要有两种情况:
- 汽车受到的障碍物的斥力和目标点的引力之间的夹角近似为180°,几乎在同一条直线上,就会出现汽车在障碍物前陷入局部最优的问题。

- 如果若干个障碍物的合斥力与目标点的引力大小相等、方向相反,则合力为0,智能汽车自身判断到达势能极小值的位置,但没有到达期望的目标点位置。由于合力为零,汽车就会陷在势能极小的位置,无法继续前进和转向,以致无法到达期望的目标点。

3. 改进障碍物斥力势场函数
通过改进障碍物斥力势场函数来解决局部最优和目标不可达的问题;在传统人工势场法的障碍物斥力场模型中加入调节因子,使斥力势场函数不仅跟汽车到障碍物的距离有关,还跟汽车与目标点的距离有关。 汽车只有到达目标点时, 斥力和引力才同时减小到零, 从而使局部最优和目标不可达的问题得到解决。
14. 样条曲线法
样条曲线法主要用于路径的平滑。
14.1 贝塞尔曲线法
贝塞尔曲线是应用于二维图形应用程序的数学曲线,由一组称为控制点的向量来确定,给定的控制点按顺序连接构成控制多边形,贝塞尔曲线逼近这个多边形,进而通过调整控制点坐标改变曲线的形状。控制点的作用是控制曲线的弯曲程度
贝塞尔曲线只需要很少的控制点就能够生成较复杂的平滑曲线。该方法能够保证输入的控制点与生成的曲线之间的关系非常简洁、明确。
对于车辆系统,规划的轨迹应满足以下准则: 轨迹连续;轨迹曲率连续; 轨迹容易被车辆跟随,且容易生成。
贝塞尔曲线是参数化曲线,n次贝塞尔曲线由n+1个控制点决定。
14.2 贝塞尔曲线性质
贝塞尔曲线具有许多性质,这里就列举几个在自动驾驶运动规划中的常见性质。
-
性质1: P 0 P_0 P0和 P n P_n Pn分别位于贝塞尔曲线的起点和终点;
-
性质2:几何特性不随坐标系的变换而变化;
-
性质3:起点和终点处的切线方向与和特征多边形的第一条边及最后一条边分别相切,换句话说,可根据曲线的起始点和终止点的切线方向确定车辆起始点姿态和目标点姿态;
-
性质4:若要求两端弧线拼接在一起依然是曲率连续的,必须要求两段弧线在连接处的曲率是相等的;
-
性质5: 至少需要三阶贝塞尔曲线(四个控制点)才能生成曲率连续的路径。
- 城市环境下局部路径规划,如贝塞尔曲线能够拟合直道和弯道,在曲率变化较大的地方可以选用两个贝塞尔曲线来拟合。
- 无人驾驶车辆的运动规划,目标轨迹曲率是连续的且轨迹的曲率不超过车辆可行驶轨迹曲率的限制。
15. B样条曲线法
贝塞尔曲线有以下缺陷:
-
确定了多边形的顶点数(n+1个),也就决定了所定义的Bezier曲线的阶次(n次),这样很不灵活。
-
当顶点数( n+1 ) 较大时, 曲线的次数较高,曲线的导数次数也会较高,因此曲线会出现较多的峰谷值。
-
贝塞尔曲线无法进行局部修改。
B样条曲线除了保持Bezier曲线所具有的优点外,还弥补了上述所有的缺陷。即: 可以指定阶次; 移动控制点仅仅改变曲线的部分形状,而不是整体。
16. 曲线插值法
-
曲线插值的方法是按照车辆在某些特定条件(安全、快速、高效)下, 进行路径的曲线拟合,常见的有多项式曲线、双圆弧段曲线、正弦函数曲线、贝塞尔曲线、 B样条曲线等。
-
曲线插值法的核心思想就是基于预先构造的曲线类型,根据车辆期望达到的状态(比如要求车辆到达某点的速度和加速度为期望值),将此期望值作为边界条件代入曲线类型进行方程求解,获得曲线的相关系数(简单地说就是待定系数法!)。
-
曲线所有的相关系数一旦确定,轨迹规划随之完成。
多项式曲线分为三次多项式曲线、 五次多项式曲线、 七次多项式曲线
- 针对三次多项式曲线,最多能确定每一个期望点的两个维度的期望状态,一般来说就是位置和速度。
{ x ( t ) = a 0 + a 1 t + a 2 t 2 + a 3 t 3 y ( t ) = b 0 + b 1 t + b 2 t 2 + b 3 t 3 (1) \tag{1} \left\{\begin{array}{l} x(t)=a_{0}+a_{1} t+a_{2} t^{2}+a_{3} t^{3} \\ y(t)=b_{0}+b_{1} t+b_{2} t^{2}+b_{3} t^{3} \end{array}\right. {x(t)=a0+a1t+a2t2+a3t3y(t)=b0+b1t+b2t2+b3t3(1)
- 针对五次多项式曲线,最多能确定每一个期望点的三个维度的期望状态,一般来说就是位置、速度、加速度。
{ x ( t ) = a 0 + a 1 t + a 2 t 2 + a 3 t 3 + a 4 t 4 + a 5 t 5 y ( t ) = b 0 + b 1 t + b 2 t 2 + b 3 t 3 + b 4 t 4 + b 5 t 5 (2) \tag{2} \left\{\begin{array}{l} x(t)=a_{0}+a_{1} t+a_{2} t^{2}+a_{3} t^{3}+a_{4} t^{4}+a_{5} t^{5} \\ y(t)=b_{0}+b_{1} t+b_{2} t^{2}+b_{3} t^{3}+b_{4} t^{4}+b_{5} t^{5} \end{array}\right. {x(t)=a0+a1t+a2t2+a3t3+a4t4+a5t5y(t)=b0+b1t+b2t2+b3t3+b4t4+b5t5(2)
- 针对七次多项式曲线,最多能确定每一个期望点的四个维度的期望状态,一般来说就是位置、速度、 加速度、加加速度(加加速度称为
jerk,加加加速度称为snap,无人机轨迹规划中有用到snap)
{ x ( t ) = a 0 + a 1 t + a 2 t 2 + a 3 t 3 + a 4 t 4 + a 5 t 5 + a 6 t 6 + a 7 t 7 y ( t ) = b 0 + b 1 t + b 2 t 2 + b 3 t 3 + b 4 t 4 + b 5 t 5 + b 6 t 6 + b 7 t 7 (3) \tag{3} \left\{\begin{array}{l} x(t)=a_{0}+a_{1} t+a_{2} t^{2}+a_{3} t^{3}+a_{4} t^{4}+a_{5} t^{5}+a_{6} t^{6}+a_{7} t^{7} \\ y(t)=b_{0}+b_{1} t+b_{2} t^{2}+b_{3} t^{3}+b_{4} t^{4}+b_{5} t^{5}+b_{6} t^{6}+b_{7} t^{7} \end{array}\right. {x(t)=a0+a1t+a2t2+a3t3+a4t4+a5t5+a6t6+a7t7y(t)=b0+b1t+b2t2+b3t3+b4t4+b5t5+b6t6+b7t7(3)
17. 车辆运动学模型
一般考虑运动学模型时,将车辆模型简化成单车模型。认为车辆轮胎沿着车身坐标系的轮胎转向角和轮胎的速度方向是一致的,即前后轮的滑移角都为0。该条件假设成立前提的是车辆速度很低(<5m/s),此时轮胎产生的横向力(侧偏力)很小,可以忽略。
18. 车辆动力学模型
在运动学模型中,我们假设了单车模型中前后轮的速度矢量与轮子方向一致。当车辆速度很高时,单车模型中前后轮的速度矢量不再与轮子方向一致。此时运动学模型就不能准确地描述车辆的运动状态,这就需要使用动力学模型对车辆进行建模。
车辆单车模型中需要考虑两个维度的信息,这两个维度分别指代表车辆横向位置信息的 y y y和表示车辆偏航角信息的 ψ \psi ψ。他们可以大致分为两类: 纵向力(Longitudinal force) 和 横向力(Lateral force), 纵向力就是使车辆前后移动的力量,而横向力则促使车辆在横向移动,在力的相互作用过程中,轮胎起着决定性的作用(根据一定的物理常识,轮胎是车辆运动的一个重要的力的来源)。
建立如下坐标系,X,Y表示全局坐标系,x,y则表示车身坐标系,x轴方向沿车辆中轴方向向前,y轴方向朝右,其车辆中心在质心位置。车辆的状态信息表示为 ( x , y , ψ , v ) (x,y,\psi,v) (x,y,ψ,v),即 x , y x,y x,y方向上的位置,偏航角和速度。
19. Dubins 曲线
Dubins 曲线不考虑车辆后退(汽车只能朝前开),且不允许出现尖瓣。Dubins曲线是在满足曲率约束和规定的始端和末端的切线方向的条件下,连接两个二维平面(即X-Y平面)的最短路径。Dubins曲线如下图所示。

Dubins曲线可以表示成3个运动基本动作的组合(即左转 L L L、右转 R R R、直行 S S S),一般将一种组合称之为一种word。
| 符号 | 含义 | 绕单位圆 |
|---|---|---|
| L | 左转 | 逆时针 |
| R | 右转 | 顺时针 |
| S | 直走 | 直走 |
Dubins 给出了充分的路径集合,该集合里所包含的曲线叫做最佳路径。但是这个充分集合很小,对于每种特定终点情况下的集合中,最多只有6条可选曲线,分别表示如下:
{ L R L L S L L S R R L R R S R R S L } (1) \tag{1} \left\{\begin{array}{lllllll} L R L & L S L & L S R & R L R & R S R & R S L \end{array}\right\} {LRLLSLLSRRLRRSRRSL}(1)
为什么是6条可选的曲线?
由于连续两次做同一种基本运动和做一次基本运动是等效的,所以 word经过排列组合后的有效种类有12个(除了上述6个还有其余6个: S L S , S R S , S L R , S R L , R L S , L R S SLS, SRS, SLR, SRL, RLS, LRS SLS,SRS,SLR,SRL,RLS,LRS)。论文又证明最短路径只在12种中的6种word中即公式(1)去选取。
Dubins 证明了,一个最优路径一定是由分段圆弧 (单位圆) 和线段组成的平滑曲线,且最多 3 部分组成。可以进一步简化表示为如下形式:
C C C → { L R L R L R } C S C → { L S L R S R L S R R S L } (2) \tag{2} \begin{array}{llllllll} C C C & \rightarrow & \{ & L R L & R L R & \}\\ C S C & \rightarrow & \{ & L S L & R S R & L S R & R S L & \} \end{array} CCCCSC→→{{LRLLSLRLRRSR}LSRRSL}(2)
等式 (2) 中符号含义如下:
| 符号 | 含义 |
|---|---|
| C | 单位圆弧 |
| S | 一条直线段 |
一个word表示相应的一类路径,对于 L L L和 R R R,其下标表示旋转的角度;对于 S S S,其下标表示行驶的直线距离。比如下图的 ( R α S d L γ ) (R_{\alpha}S_{d}L_{\gamma}) (RαSdLγ) 。
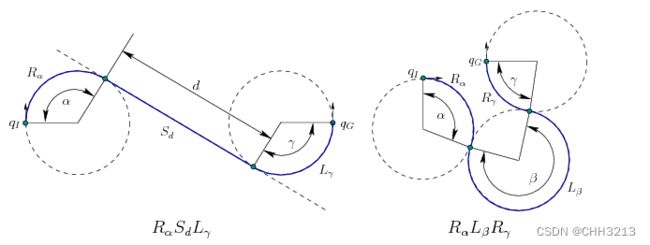
综上,Dubins曲线路径被定义为:
在最大曲率限制下,平面内两个有方向的点间的最短可行路径是 C L C CLC CLC路径或 C C C CCC CCC路径,或是他们的子集,其中 C C C表示圆弧段, L L L表示与 C C C相切的直线段。
可能的疑惑:
-
两点之间不是直线最短吗,为什么要加入圆弧?
因为这是在带有方向的初始位置 (起始位姿点)和终止位置 (终止位姿点)间寻找最短路径,所以这是两个位姿点间的最短路径,而不是单纯的两个坐标点间的最短路径。
-
最短路径在最小半径的时候取到的前提是在无障碍的情况下
总结
- Dubins曲线是开环的,考虑到实际车辆行驶中的不确定性, Dubins还存在动态性的问题。
- Dubins曲线能够用于RRT等路径规划算法中,在原始RRT中,树枝的生长是直线生长(找到最近点,建立直线连接),对于汽车来说,不可能一直都能实现沿直线树枝行驶,因此在新节点和整棵随机树的关联上,可以选择使用Dubins曲线,使得各节点之间有一个连续、光滑、满足车辆运动学的连接。
- Dubins曲线是不对称的,从A点到B点的最短距离,并不一定等于B点到A点的最短距离。相对的,Reeds Shepp曲线是对称的。
20. ReedsShepp 曲线
Reeds-Shepp 算法简称 RS,基于 Dubins 算法进行改进,将反向运动(汽车允许后退,挂倒挡)加入到规划中,这就使得在某些情况下可以得出比 Dubins 曲线更优的解。
曲线示例如下:

如上图可以知道,在 Reeds-Shepp 曲线的路径中,允许尖瓣存在。
字段组合
在字段中的字母上加入上标,用来表示运动方向,表示如下:
| 符号 | 含义 | 绕单位圆 |
|---|---|---|
| L + L^+ L+ | 向前左转 | 逆时针 |
| L − L^- L− | 向后左转 | 顺时针 |
| R + R^+ R+ | 向前右转 | 逆时针 |
| R − R^- R− | 向后右转 | 顺时针 |
| S + S^+ S+ | 向前直走 | / |
| S − S^- S− | 向后直走 | / |
使用 C 、 S C、S C、S 字符可以给出如下集合:
C C C ← { C + C − C + C + C − C − C + C + C − C + C β + C β − C − C + C β − C β − C + } C S C ← { C + S + C + C − C π / 2 + S + C + C + S + C π / 2 + C − C − C π / 2 + S + C π / 2 + C − } (1) \tag{1} \begin{aligned} &C C C \leftarrow\left\{\quad C^{+} C^{-} C^{+} \quad C^{+} C^{-} C^{-} \quad C^{+} C^{+} C^{-} \quad C^{+} C_{\beta}^{+} C_{\beta}^{-} C^{-} \quad C^{+} C_{\beta}^{-} C_{\beta}^{-} C^{+}\right\}\\ &C S C \leftarrow\left\{\quad C^{+} S^{+} C^{+} \quad C^{-} C_{\pi / 2}^{+} S^{+} C^{+} \quad C^{+} S^{+} C_{\pi / 2}^{+} C^{-} \quad C^{-} C_{\pi / 2}^{+} S^{+} C_{\pi / 2}^{+} C^{-}\right\} \end{aligned} CCC←{C+C−C+C+C−C−C+C+C−C+Cβ+Cβ−C−C+Cβ−Cβ−C+}CSC←{C+S+C+C−Cπ/2+S+C+C+S+Cπ/2+C−C−Cπ/2+S+Cπ/2+C−}(1)
通过反转等式 (1) 的符号可以获得新的的字段。上式 (1) 中, C π / 2 + C^+_{\pi/2} Cπ/2+表示相应的 L L L或 R R R的转过的角度为 π / 2 \pi/2 π/2 , C β C β C_{\beta}C_{\beta} CβCβ组合表示相应的弧段拥有相等的长度。
为了以紧凑的表示,避免 ± \pm ± ,可以写出充分路径的列表如下:
C C C ← { C ∣ C ∣ C C ∣ C C C C ∣ C C C β ∣ C β C C ∣ C β C β ∣ C } C S C ← { C S C C ∣ C π / 2 S C C S C π / 2 ∣ C C ∣ C π / 2 S C π / 2 ∣ C } (2) \tag{2} \begin{aligned} &C C C \leftarrow\left\{\begin{array}{ccccc} C|C| C & C \mid C C & C C \mid C & C C_{\beta} \mid C_{\beta} C & C\left|C_{\beta} C_{\beta}\right| C \end{array}\right\}\\ &C S C \leftarrow\left\{\begin{array}{llll} C S C & C \mid C_{\pi / 2} S C & C S C_{\pi / 2} \mid C & C\left|C_{\pi / 2} S C_{\pi / 2}\right| C \end{array}\right\} \end{aligned} CCC←{C∣C∣CC∣CCCC∣CCCβ∣CβCC∣CβCβ∣C}CSC←{CSCC∣Cπ/2SCCSCπ/2∣CC∣ ∣Cπ/2SCπ/2∣ ∣C}(2)
其中, ∣ | ∣表示车辆运动朝向由正向转为反向或者由反向转为正向。
将上述word分别带下标,如 C α ∣ C β ∣ C γ C_{\alpha}|C_{\beta}| C_{\gamma} Cα∣Cβ∣Cγ,其中 α , β , γ \alpha, \beta, \gamma α,β,γ分别表示旋转的角度(弧度制)。 S S S带下标 d d d表示行走的直线距离为 d d d。它们的范围如下表所示:

将 C C C替换为 L L L或 R R R ,通过简单的变换,则共有 48 种字段组合。这种简单变换包括时间翻转(timeflip)、反射(reflect)和向后变换(backwards)。
面试常见问题
1. 解释卡尔曼滤波
-
卡尔曼滤波是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。因为观测数据中包括系统中的噪声和干扰的影响,因此最优估计也可以当作是滤波的过程。
-
Kalman filter具有非常类似的结构,有预测值和实际观测值的参与去不断更新所谓的滤波增益。 -
Kalman filter采用了噪音和系统状态的统计学信息,一般以最小化mean-squared error(均方差)为优化目标,来给出原输入信号的最优估计(optimal estimation),这个estimation的最优性(optimality)是以最小均方差为准的
-
所谓的estimation就包含三种处理信号的方法:filtering(滤波),smoothing(平滑) 和 prediciton(预测)。在第二个层面的理解中,我们把filtering理解为:根据到目前时间 为止的信号的所有信息,来还原信号的部分或者全部信息。
2. 曲率在车辆操控上最直观的体现
车辆的位置与路径的偏差越大,车速越小,当路径的曲率越大,车速越小,通俗地讲就是进弯道前减速,进直道可以加速。
3. 曼哈顿距离与欧式距离的优缺点
曼哈顿距离:
曼哈顿距离中的距离计算公式比欧氏距离的计算公式看起来简洁很多,只需要把两个点坐标的 x 坐标相减取绝对值,y 坐标相减取绝对值,再加和。
从公式定义上看,曼哈顿距离一定是一个非负数,距离最小的情况就是两个点重合,距离为 0,这一点和欧氏距离一样。
曼哈顿距离和欧氏距离的意义相近,也是为了描述两个点之间的距离,不同的是曼哈顿距离只需要做加减法,这使得计算机在大量的计算过程中代价更低,而且会消除在开平方过程中取近似值而带来的误差。不仅如此,曼哈顿距离在人脱离计算机做计算的时候也会很方便。
欧式距离:
虽然这是一种常见的距离测量方法,但欧几里得距离并不是尺度不变的,这意味着计算出的距离可能会根据特征的单位而有所偏斜。通常情况下,在使用这种距离测量之前,需要对数据进行归一化。
此外,随着数据维度的增加,欧几里得距离的作用就越小。这与维度的诅咒有关,它涉及到高维空间的概念,并不像我们直观地期望的那样,从二维或三维空间中发挥作用。
4. 想保证车辆曲率连续最少需要几阶约束
从曲率的公式出发看的话,若要求曲率连续变化,则要求至少二阶导数连续。

5. 汽车的运动学模型和二自由度动力学模型的区别是什么
动力学模型:输入力和力矩,输出为速度或角速度。
运动学模型:输入速度或角速度,输出为位置和姿态
- 运动学模型是对车辆在低速下的描述,低速运动下,忽略了轮胎的侧偏现象,忽略了车辆的侧向运动;
- 动力学模型是车辆高速运动时的描述,主要加入考虑了轮胎的侧偏运动;
- 除此之外,还有基于动力学模型的跟踪误差模型
6. 路径规划,轨迹规划有啥区别
-
路径规划(Path/Motion Planning),是在不考虑临时或者移动的障碍物的前提下,对车辆在空间上的变化的规划;
-
轨迹规划(Trjectory Planning)一般轨迹规划包括横向规划和纵向规划,横向规划主要输出 trajectory 中的 x, y, s,纵向规划主要填充轨迹上各点期望速度 ds/dt。一般横纵解耦规划方案先规划横向,再规划纵向。轨迹规划包含时间信息。
7. 最优控制
- 泛函数是函数的函数,即它的输入是函数,输出是实数。
- 变分法
8. 优化方法
无约束最优化方法的核心问题是选择搜索方向。
1. 梯度下降法
梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。
一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。
梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。
核心思想归纳:
-
初始化参数,随机选取取值范围内的任意数;
-
迭代操作:
a)计算当前梯度;
b)修改新的变量;
c)计算朝最陡的下坡方向走一步;
d)判断是否需要终止,如否,返回a); -
得到全局最优解或者接近全局最优解。
最速下降法越接近目标值,步长越小,前进越慢。梯度下降法的搜索迭代示意图如下图所示:
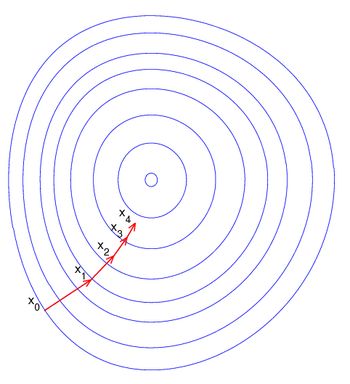
缺点:靠近极小值时收敛速度减慢;直线搜索时可能会产生一些问题;可能会“之字形”地下降。
2. 牛顿法
https://blog.csdn.net/sinat_29244519/article/details/101872198
牛顿法的基本思想就是:在极小点附近用二阶Taylor 多项式近似目标函数 f ( x ) f(x) f(x) ,进而求出极小点的估计值。



从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。
缺点:
- 牛顿法是一种定长迭代算法(没有步长因子),每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。牛顿法面临的另外一个问题是Hessian矩阵可能不可逆,从而导致这种方法失效。
- 在高维情况下这个矩阵非常大,计算和存储都是问题。
- 在小批量的情况下,牛顿法对于二阶导数的估计噪声太大。
- 目标函数非凸的时候,牛顿法容易受到鞍点或者最大值点的吸引。
3. 拟牛顿法
拟牛顿法的思想是不计算目标函数的Hessian矩阵然后求逆矩阵,而是通过其他手段得到Hessian矩阵或其逆矩阵的近似矩阵。具体做法是构造一个近似Hessian矩阵或其逆矩阵的正定对称矩阵,用该矩阵进行牛顿法的迭代。
拟牛顿法和梯度下降法一样只要求每一步迭代时知道目标函数的梯度。通过测量梯度的变化,构造一个目标函数的模型使之足以产生超线性收敛性。这类方法大大优于梯度下降法,尤其对于困难的问题。另外,因为拟牛顿法不需要二阶导数的信息,所以有时比牛顿法更为有效。如今,优化软件中包含了大量的拟牛顿算法用来解决无约束,约束,和大规模的优化问题。
4. 共轭梯度法
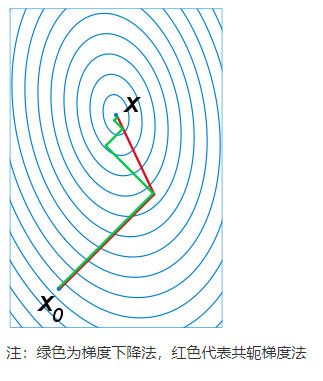
共轭梯度法的基本思想是把共轭性与最速下降方法相结合 ,利用已知点处的梯度构造一组共轭方向 ,并沿这组方向进行搜索 ,求出目标函数的极小点。
共轭梯度法是介于梯度下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了梯度下降法收敛慢的缺点,又避免了牛顿法需要存储和计算Hesse矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。 在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。
具体的实现步骤请参加wiki百科共轭梯度法。下图为共轭梯度法和梯度下降法搜索最优解的路径对比示意图:
9. 汽车的轮胎特性是什么
10. 自动驾驶控制模块的输入输出是什么?和规划是什么关系

11. Lattice planner和Em planner
https://blog.csdn.net/IHTY_NUI/article/details/115977861
https://zhuanlan.zhihu.com/p/492988036
-
Lattice 是网格化采样。路径规划采样:向前取若干个距离,每个距离采样不同横向距离,从而获得多排采样点,使用多项式连接不同排采样点获得候选路径;纵向规划采样:采样多各前方时间,每个时间采样不同距离形成一列候选距离,沿时间向前使用多项式连接各列候选距离形成候选距离随时间变化的纵向曲线。路径与纵向规划采样合并后得到候选轨迹,根据 cost 函数选取 cost 最低的最优轨迹输出;
-
EM-Planner是具体的规划实施类,它基于高精地图、导航路径及障碍物信息作出实际的驾驶决策,包括路径、速度等方面。
首先使用DP(动态规划)方法确定初始的路径和速度,再利用QP(二次规划)方法进一步优化路径和速度,以得到一条更平滑的轨迹,既满足舒适性,又方便车辆操纵。
为了寻求更优质更平滑,体感更好的路径,需要使用二次规划的方法寻找。需要的限制条件有:曲率和曲率连续性、贴近中心线、避免碰撞。
12. 无人车规划轨迹的宗旨是什么
安全和舒适。
13. 油门刹车标定表
原理:输入油门开度和期望速度和刹车开度,记录在当前油门量随着时间的累积的速度和加速度数据,记录多组油门刹车量,拟合成一个三维空间的曲面。
13. 有限状态机(Finite-State Machine)
- https://blog.csdn.net/Rickey_lee09/article/details/104653571
- https://blog.csdn.net/qq_35635374/article/details/121626001
- https://blog.csdn.net/u013528298/article/details/88948525

定义
自动驾驶中,车辆根据当前环境选择合适的驾驶行为,如停车、换道、超车、避让、缓慢行驶等模式,状态机模型通过构建有限的有向连通图来描述不同的驾驶状态以及状态之间的转移关系,从而根据驾驶状态的迁移反应式地生成驾驶动作。
组成
一个有限状态机通常包含如下几部分:
- 输入集合:通常也叫刺激集合,包含我们考虑到的状态机可能收到的所有输入。
- 输出集合:即FSM能够作出的响应的集合,这个集合也是有限的,很多情况下FSM并不一定有输出,即 为空集。
- 状态集合:我们通常使用有向图来描述FSM内部的状态和转移逻辑,我们使用符号 S 来表示有向图中状态的集合。
- FSM通常有一个固定的初始状态(不需要任何输入,状态机默认处于的状态。
- 结束状态集合,是状态机 S 的子集,也有可能为空集(即整个状态机没有结束状态),通常使用符号 F 表示。
- 转移逻辑:即状态机从一个状态转移到另一个状态的条件(通常是当前状态和输入的共同作用)。
缺点
有限状态机模型因为简单、易行,是无人驾驶领域目前最广泛的行为决策模型,但该类模型忽略了环境的动态性和不确定性,此外,当驾驶场景特征较多时,状态的划分和管理比较繁琐,多适用于简单场景下,很难胜任具有丰富结构化特征的城区道路环境下的行为决策任务。
14. 分层有限状态机
- 状态太多时,不好维护,于是将状态分类,把那些同一类型的状态机做为一个状态机,然后再做一个大的状态机,来维护这些子状态机。
- 相比于FSM,HFSM新增了一个超级状态(Super-state):本质上也就是将性质同一类型的一组状态合为一个集合,超级状态之间也有转移逻辑。这也就意味着HFSM不需要为每一个状态和其他所有状态建立转移逻辑,由于状态被归类,类和类之间存在转移逻辑,那么类和类之间的状态转移可以通过继承这个转移逻辑来实现,这里的转换继承就像面向对象编程中通过多态性让子类继承超类一样。
15. 决策树vs行为树
https://blog.csdn.net/ecidevilin/article/details/78061693
-
决策树就是为了制定决策。行为树是为了控制行为。让我来讲讲。它俩最主要的区别在于遍历的方式,而且布局方式和节点“类型”也不一样。
-
决策树每一次都从根到叶节点分析。为了让决策树正确工作,每个父节点的子节点都要能表达出父节点所有可能的决策。如果一个节点可以应答“是,否,可能”,那么那必须有三个子节点:“是”节点、“否”节点和“可能”节点。这就意味着,在到达结束节点前,总是可以遍历到某个底层节点。这种遍历总是向下的。如图所示:

-
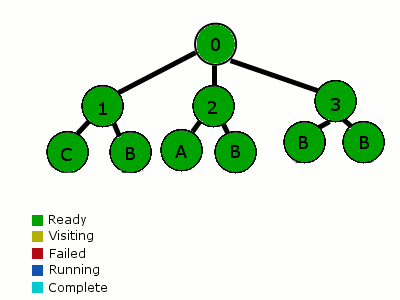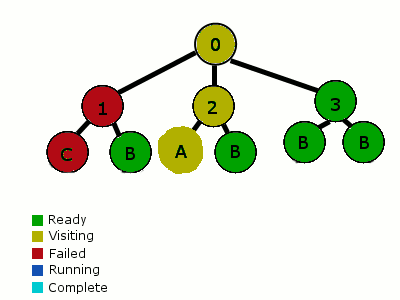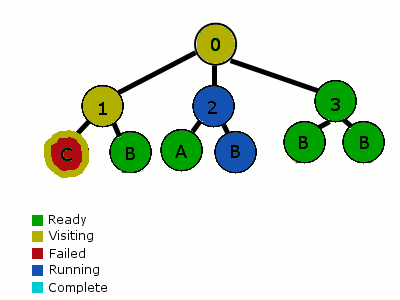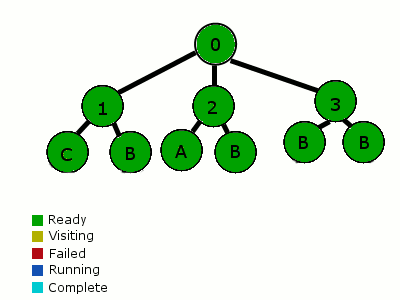
行为树有不一样的分析方法。第一次从根节点开始(这里所有的父节点作为选择器),并且从左到右分析每个子节点。这些子节点按优先级排列。如果一个子节点所有的条件都满足,就开始它的行为。当一个节点开始一个行为,这个节点被设置为“运行中”,并返回这个行为。下一次分析这棵树的时候,重新检查最高优先级的节点,当走到“运行中”节点时,它便知道从它暂停的地方继续执行它。在到达结束状态之前,这个节点可以包含一系列的行动和条件。任意条件失败,遍历器便会返回到父节点。父选择器接着移动到下一个优先级的子节点上。
-
遍历从根节点开始,走到1号子节点,检查子节点的条件(例如“周围是否有滴人?”)。这个条件失败了,遍历器返回树(根节点)并移动到2号节点。2号节点执行了一个行动(例如寻路)和一个行为(例如沿路线走)。“沿路线走”的行为被设置为“运行中”,并且行为树返回状态“运行中”。失败和完成的节点会返回“待命”。接着下一次我们检查这个树,我们再次从最高优先级的节点开始。它又失败了,所以我们执行到2号节点。在2号节点,我们发现有一个“运行中”的行为。当我们发现这个行为完成了,那么我们把它标记成“完成”并返回。然后这颗行为树就被重置了,并准备好再次开始。
行为树vs有限状态机

16. 部分可观察马尔可夫决策过程
部分可观察马尔可夫决策过程(partially observable Markov decision processes,POMDP)是环境状态部分可知动态不确定环境下序贯决策的理想模型,其核心点在于,agent无法知道自己所处的环境状态,需要借助于额外的传感器,或者与其他的agent进行交互等方式才能获知自己的state,能够客观、准确地描述真实世界,是随机决策过程研究的重要分支。
17. 速度规划
速度规划的目标是在给定的局部路径曲线上, 在满足反馈控制的操作限制及符合行为决策的输出结果这两个前提下, 将路径点赋予速度及加速度信息。速度规划主要考虑的是对动态障碍物的规避。
常用方法
速度规划有以下常见的方法:
- 对路径指定线加速度来生成速度: 线加速度可以是某一常数, 或是由比例-微分控制器来生成,
- 样条插值: 在给定时间内通过一段给定路径的速度生成问题。其解决方案是将时间域划分为若干区间, 使用速度关于时间的三次样条函数来插值。这一方法容易产生加速度变化率较大的问题。
- 函数拟合: 直接用速度关于路径长度的二次多项式来生成速度。这种方法较为简单。
- 目标时刻点法: 速度规划部分首先根据对障碍物未来运动状态的预测, 在规划路径与时间这两个维度构成的二维图中标记障碍物在未来一段时间内所占据的区域。以目标汽车当前车速匀速通过规划路径所需的时间为基准, 根据一定原则创建一组目标时刻点, 在此二维图中以目标时刻点为目标点搜索产生一组速度规划方案。
- QP算法: 这一方法引人了S-T图的概念,并把自动驾驶汽车速度规划归纳为S-T图上的搜索问题进行求解。S-T图是一个关于给定局部路径纵向位移和时间的二维关系图。任何一个S-T图都基于一条已经给定的轨迹曲线。根据自动驾驶汽车预测模块对动态障碍物的轨迹预测,每个动态障碍物都会在这条给定的路径上有投影, 从而产生对于一定S-T区域的覆盖。
18. 自动驾驶任务中的强化学习
https://www.eet-china.com/mp/a155448.html
在自动驾驶中,RL 可以完成的任务有:控制器优化、路径规划和轨迹优化、运动规划和动态路径规划、为复杂导航任务开发高级驾驶策略、高速公路、交叉路口、合并和拆分的基于场景的策略学习,预测行人、车辆等交通参与者的意图,并最终找到确保安全和执行风险估计的策略。
强化学习架构分为网络训练和网络部署两个阶段:在网络训练阶段,使用左中右三个相机的图像作为 CNN(Convolutional Neural Network,卷积神经网络)的输入,同时使用人类驾驶员的转向指令作为训练信号。经训练后的 CNN 仅以中心相机的图像作为输入,直接输出转向控制动作。End-to-end 架构以计算机的方式理解图像信息,可在全局范围内进行优化求解,可以更直观的实现驾驶功能,拥有更好的场景泛化性。
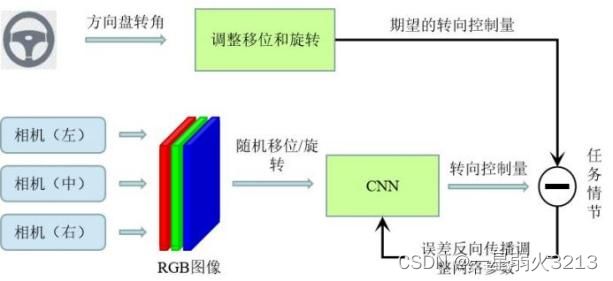
为了成功地将 DRL 应用于自动驾驶任务,设计适当的状态空间、动作空间和奖励函数非常重要。
状态空间
自动驾驶汽车常用的状态空间特征包括:本车的位置、航向和速度,以及本车的传感器视野范围内的其他障碍物。此外,我们通常使用一个以车辆为中心的坐标系,并在其中增强车道信息,路径曲率、自主的过去和未来轨迹、纵向信息等。我们通常会使用一个鸟瞰图来展示这些信息。
动作空间
车辆的控制策略需要操纵一系列执行器,比如方向盘,油门和刹车(暂时不考虑其他的执行器)。有一点需要注意的是,这些控制器都是在连续空间中运行的,而大多数 DRL 控制器属于离散空间。因此我们需要选择合适的时间步长。
运动规划和轨迹优化
运动规划是确保目标点和目的地点之间存在路径的任务。但是动态环境和变化的车辆动力学中的路径规划是自动驾驶中的一个难题,比如通过十字路口,或者并入高速公路。有许多文章在这方面做了尝试,并获得了不错的效果
19. 强化学习在自动驾驶中应用的看法
https://zhuanlan.zhihu.com/p/34089913
强化学习可以克服传统方式依赖先验环境建模的问题,可以直接实现通过从感知到控制功能的映射。
强化学习在自动驾驶的决策规划中的一个重要任务就是在复杂交互场景中做出安全且合理的决策规划,常见的复杂交互场景例如窄路会车,分道合道,无保护左转,环岛等,很难用传统的规划决策算法来很好的解决。强化学习与仿真交互产生学习到的连续决策能力将会是有效的解决方案。
从仿真训练测试到实车落地是一个典型的Sim-to-Real问题,强化学习从仿真到现实世界往往会遇到数据偏移和模型偏差。在自动驾驶的问题下,Sim-to-Real需要解决这几个方面的问题:
- 一是感知方面,真实世界和仿真环境的感知信号存在着数据偏移;
- 二是环境交互模型方面,真实世界和仿真环境的物理学模型会存在一点的偏差;
- 三是行为模式方面,真实世界里的车辆和行人的行为模式很可能与仿真环境不一致,一些细粒度的交互(例如眼神,手势)无法在仿真环境里面有效建模。
Sim-to-Real的gap通常可以通过domain adaptation,domain randomization(例如感知)和system learning/identification(例如环境模型)来一定程度上减轻,但完全消除Sim-to-Real的gap仍然具有挑战。