朱俊彦团队最新论文:用GAN监督学习给左晃右晃的猫狗加表情,很丝滑很贴合...
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
GAN又被开发出一项“不正经”用途。
给猫狗加表情:
给马斯克加胡子:
不管视频中的脑袋怎么左晃右晃,这些表情都能始终如一地贴合面部,且每一帧都表现得非常丝滑。
这就是朱俊彦等人的最新研究成果:
一种利用GAN监督学习实现的密集视觉对齐(Visual alignment)方法。
该方法的性能显著优于目前的自监督算法,在多个数据集上的性能都与SOTA算法相当,有的甚至还实现了两倍超越。

用GAN监督学习实现密集视觉对齐
视觉对齐是计算机视觉中光流、3D匹配、医学成像、跟踪和增强现实等应用的一个关键要素。
直白地说,比如在人脸识别中,就是不管一张脸是倒着立着还是歪着,任何角度都可以精确识别出哪块是眼睛哪块是鼻子。
而开创性的无监督视觉对齐方法Congealing,在MNIST digits这种简单的二值图像(binary images)上表现得出奇好,在处理大多数具有显著外观和姿势变化的数据集上就差了点。
为了解决这个问题,该团队提出了这个叫做GANgealing的新视觉对齐方法。
它是一种GAN监督算法,同时也受到Congealing的启发。
Congealing模型的框架如下:
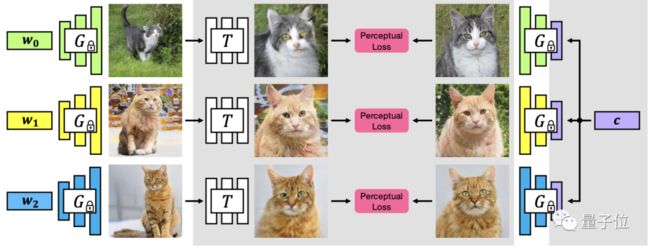
首先,在未对齐的数据上训练生成器G。
然后在生成器G的潜空间中通过学习模式c,来创建一个合成数据集以进行后续对齐。
接着使用该数据集训练空间变换网络T(STN,Spatial Transformer Networks),最后在预测和目标图像中使用感知损失将未对齐的图像映射到相应的对齐图像。
该算法的关键是利用GAN的潜空间(在未对齐的数据上训练)为STN自动生成成对的训练数据。
并且在这个GAN监督学习框架中,STN和目标图像实现联合学习模式,STN专门使用GAN图像进行训练,并在测试时推广到真实图像。
实际效果如何?
实验发现,GANgealing在八个数据集(自行车、狗、猫、汽车、马、电视等)上都能准确找出图片之间的密集对应关系。
其中,每个数据集的第一行表示未对齐的图像和数据集的平均图像(每行最右那张),第二行为转换后的对齐效果,第三行则显示图像之间的密集对应关系。
在图像编辑应用中,GANgealing可以只在平均图像(下图最左)进行示范,就能在数据集中的其他图像上实现同样的效果——不管这些图像的角度和姿势变换有多大。
比如第一行为给小猫加蝙蝠侠眼镜,最后一行为给汽车车身贴上黑色图案。
在视频编辑中,GANgealing在每一帧上的效果都相当丝滑,尤其是和监督光流算法(比如如RAFT)对比,差距非常明显:
因此作者也表示,GANgealing可以用在混合现实应用中。
而在定量实验中,GANgealing在非常精确的阈值(<2像素误差容限)条件下优于现有的监督方法,在有的数据集上甚至表现出很大的优势。
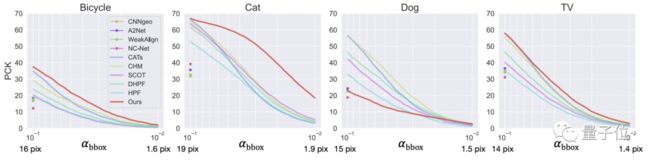
再在具有挑战的SPair-71K数据集上将GANgealing与几种自监督SOTA方法进行性能评估。
比的则是PCK-Transfer值(PCK,percentage of keypoints),它衡量的是关键点从源图像转换到目标图像的百分比。
结果发现,GANgealing在3个类别上的表现都明显优于目前的方法,尤其是在自行车和猫图集上实现了对自监督方法CNNgeo和A2Net的两倍超越。

当然,GANgealing在数据集图片与示例差太多时表现得就不太好,比如面对下面这种侧脸的猫以及张开翅膀的小鸟。

作者介绍
GANgealing的作者们分别来自UC伯克利、CMU、Adobe以及MIT。

一作为UC伯克利三年级的博士生Bill Peebles,研究方向为无监督学习,重点是图像和视频的深度生成模型。
目前在CMU担任助理教授的青年大牛朱俊彦也在其中。
通讯作者为Adobe Research的高级首席科学家Eli Shechtman,他发表了100多篇论文,曾获得ECCV 2002最佳论文奖、WACV 2018最佳论文奖、FG 2020最佳论文亚军以及ICCV 2017的时间检验奖等荣誉。
论文地址:
https://arxiv.org/abs/2112.05143
代码:
https://github.com/wpeebles/gangealing
项目主页:
https://www.wpeebles.com/gangealing