一文掌握遥感地块变化检测(基于PaddleSeg实现)
目录
一、概述
二、数据准备
三、训练和评估
3.1 环境准备
3.2 模型原理概述
3.3 训练和评估
四、测试及可视化
五、与其它模型比对
5.1 模型代码修改
5.2 模型性能比对
参考文献
一、概述
人们几乎每天都在对自然环境进行改造,小到建筑物的修建、大到填海造陆,而这些动态发展对于自然环境的利弊则需要监控与分析。
遥感变化检测,顾名思义,就是利用多张静态的遥感图像所反应的信息,在相互比较、多种处理手段下获取各种地表信息动态变化的方式。遥感变化检测的工作对象是同一地区不同时期的图像。
简单理解,遥感变化检测类似一款名为“找茬”的游戏:给定两幅图像,要求玩家在指定时间内寻找图像中不同的地方。洞察力与记忆力比较高的人可能会是玩这个游戏的高手,但是对于两幅不同时间点的遥感影像来说,如果仅仅凭借人的观察与记忆去对两幅影像“找茬”将是一个费时费力的工作。因此我们希望借助人工智能(深度学习)技术高效、自动的找到两幅遥感影响的不同之处。
 同一地区不同时间段的两幅遥感图像(最终要获得变化的区域)
同一地区不同时间段的两幅遥感图像(最终要获得变化的区域)
对于遥感影像的变化检测来说,如果仅仅只是判断两幅图片是否不同可能无法达到我们的任务要求,大多数时候我们不仅要知道两幅影像不一样,还要知道究竟是哪里不一样,并且还要把不一样的地方表示出来,如上图所示,最后白色区域就是我们需要检测出来的变化区域。这种像素级的检测任务跟现有的图像语义分割很相似,只不过遥感变化检测输入的是两张图片,而一般的语义分割任务输入的是一张图片。因此,我们可以借用语义分割的一些方法来实现遥感变化检测。
本文基于PaddleSeg语义分割套件实现地块变化检测。具体实现时,将同一地块的前期与后期两张图片进行拼接,而后输入给语义分割网络进行变化区域的预测。
二、数据准备
本案例使用WHU dataset数据集,该数据集覆盖了2011年2月发生6.3级地震并在随后几年重建的地区。本文已经对该数据集进行了预处理,所有图像全部裁剪为512x512大小,并且按照训练集、验证集、测试集的形式分拆了数据。处理后的数据集下载地址:飞桨AI Studio - 人工智能学习与实训社区
具体的,该数据集包含train512、test512和val512三个部分,每个部分有first、second和masks三个文件夹分别保存时段一、时段二的图像和对应的建筑变化标签(三个文件夹中对应文件的文件名都相同,这样就可以使用replace只从first中就获取到second和masks中的路径),list的每一行由空格隔开。
首先我们使用下面的脚本查看下该数据集信息:
import cv2
import matplotlib.pyplot as plt
# 读取图像
T1 = cv2.cvtColor(cv2.imread('dataset/WHU_dataset/train512/first/WHU_building_online_detect_34_67.jpg'), cv2.COLOR_BGR2RGB)
T2 = cv2.cvtColor(cv2.imread('dataset/WHU_dataset/train512/second/WHU_building_online_detect_34_67.jpg'), cv2.COLOR_BGR2RGB)
lab = cv2.imread('dataset/WHU_dataset/train512/masks/WHU_building_online_detect_34_67.jpg', cv2.IMREAD_GRAYSCALE)
# 展示
plt.figure(figsize=(30, 10))
plt.subplot(131);plt.imshow(T1);plt.title('Time1')
plt.subplot(132);plt.imshow(T2);plt.title('Time2')
plt.subplot(133);plt.imshow(lab);plt.title('Label')
plt.savefig("result/demo_show.jpg")展示效果如下:
 样例数据展示(从左到右依次为:遥感图1、遥感图2、变化区域图)
样例数据展示(从左到右依次为:遥感图1、遥感图2、变化区域图)
为了方便后面实现语义分割任务,我们需要对数据建立索引文件,具体代码如下:
import os
def creat_data_list(dataset_path, mode='train'):
'''
创建txt文件列表
'''
with open(os.path.join(dataset_path, (mode + '_list.txt')), 'w') as f:
A_path = os.path.join(os.path.join(dataset_path, mode+'512'), 'first')
A_imgs_name = os.listdir(A_path)
print(mode + '共有文件'+ str(len(A_imgs_name)))
A_imgs_name.sort()
for A_img_name in A_imgs_name:
A_img = os.path.join(A_path, A_img_name)
B_img = os.path.join(A_path.replace('first', 'second'), A_img_name)
label_img = os.path.join(A_path.replace('first', 'masks'), A_img_name)
f.write(A_img + ' ' + B_img + ' ' + label_img + '\n') # 写入list.txt
print(mode + '_data_list 已生成')
# 创建三个list.txt用于训练、评估、测试
dataset_path = 'dataset/WHU_dataset' # data的文件夹
creat_data_list(dataset_path, mode='train')
creat_data_list(dataset_path, mode='test')
creat_data_list(dataset_path, mode='val')执行上述操作后,在dataset/WHU_dataset目录下会生成train_list.txt、val_list.txt和test_list.txt文件,有了这三个文件后面就能很方便的执行训练、评估和测试了。
三、训练和评估
3.1 环境准备
本文使用PaddleSeg套件来实现遥感变化检测任务。这里注意,虽然该任务名为“检测”任务,但是本质上还是属于语义分割任务,需要把变化区域按照像素级的方式标记出来。
本文选用国产飞桨PaddlePaddle作为深度学习主框架,并且使用配套的PaddleSeg图像分割套件来开发。PaddleSeg如同一个工具箱一样,涵盖了高精度和轻量级等不同方向的大量高质量分割模型,并提供了多个损失函数和多种数据增强方法等高级功能,用户可以根据使用场景从PaddleSeg中选择出合适的图像分割方案,从而更快捷高效地完成图像分割应用。PaddleSeg的主要特点包括4点:一是提供了50+的高质量预训练模型。二是提供了模块化的设计,支持模型的深度调优;三是高性能计算和显存优化;四是同时支持配置化驱动和API调用两种应用方式,兼顾易用性和灵活性。
本文使用版本如下:
- PaddlePaddle:2.2.2
- PaddleSeg:release/2.4
对于一般的语义分割任务来说,输入图像是3通道的彩色图像,而对于遥感变化检测任务来说输入有两张图像,为了能够方便的实现遥感变化检测,我们可以按照通道将两张图片级联来作为输入,这样的话,相比一般的语义分割任务我们的输入就变成了6通道,但是整个输出和评估都是一样的。
首先从github官网下载最新的PaddleSeg套件,然后安装该套件(这里注意,由于后面我们需要对该套件模型代码进行修改,因此,建议采用本地安装方式,不要使用pip install paddleseg这种在线安装方式):
cd PaddleSeg
sudo python setup.py install接下来我们首先要做的就是创建数据集读取管道,定义一个数据集读取文件changedataset.py,内容如下:
import os
import cv2
import numpy as np
import paddle
from paddle.io import Dataset
from paddleseg.transforms import Compose
class ChangeDataset(Dataset):
'''
自定义数据读取类
'''
def __init__(self, dataset_path, mode, transforms=[], num_classes=2, ignore_index=255):
list_path = os.path.join(dataset_path, (mode + '_list.txt'))
self.data_list = self.__get_list(list_path)
self.data_num = len(self.data_list)
self.transforms = Compose(transforms, to_rgb=False) # 一定要设置to_rgb为False,否则这里有6个通道会报错
self.is_aug = False if len(transforms) == 0 else True
self.num_classes = num_classes # 分类数
self.ignore_index = ignore_index # 忽视的像素值
def __getitem__(self, index):
'''
两幅图像按照通道进行级联
'''
A_path, B_path, lab_path = self.data_list[index]
A_img = cv2.cvtColor(cv2.imread(A_path), cv2.COLOR_BGR2RGB)
B_img = cv2.cvtColor(cv2.imread(B_path), cv2.COLOR_BGR2RGB)
image = np.concatenate((A_img, B_img), axis=-1) # 将两个时段的数据concat在通道层
label = cv2.imread(lab_path, cv2.IMREAD_GRAYSCALE)
if self.is_aug:
image, label = self.transforms(im=image, label=label)
image = paddle.to_tensor(image).astype('float32')
else:
image = paddle.to_tensor(image.transpose(2, 0, 1)).astype('float32')
label = label.clip(max=1) # 把标签文件0-255变为0-1
label = paddle.to_tensor(label[np.newaxis, :]).astype('int64')
return image, label
def __len__(self):
return self.data_num
def __get_list(self, list_path):
'''
读取list.txt并转为list
'''
data_list = []
with open(list_path, 'r') as f:
data = f.readlines()
for d in data:
data_list.append(d.replace('\n', '').split(' '))
return data_list有了上述数据集读取文件,下面就可以进行训练了。
3.2 模型原理概述
本文使用UNet++模型来训练。UNet++是亚利桑那州立大学在读博士生周纵苇于2018年发表的论文,是以UNet为基础进行魔改的网络结构。
UNet是语义分割领域常用方法,其本质是一个编码器-解码器网络,如下图所示:
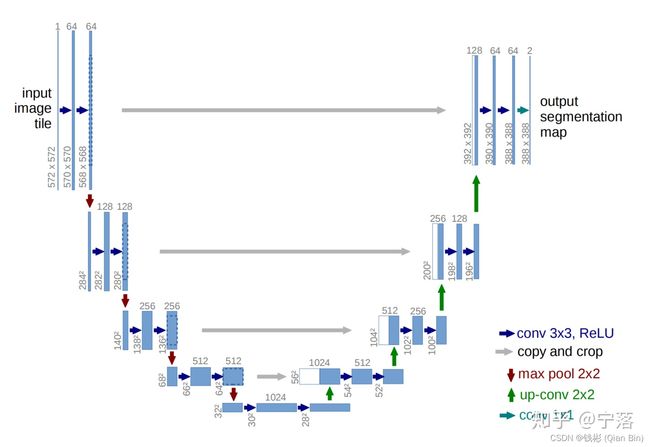
左边可以理解为编码器,通过不断的卷积和下采样能够将图像的特征进行提取出来,右边可以理解为解码器,通过上采样和卷积将特征进行解码还原为需要的信息。编码器和解码器之间通过skip-connection来互补充信息提升分割性能。现在医学图像分割领域的相当一部分论文的网络结构都是以编码器-解码器结构基础的,可以说很多论文所应用的网络都是UNet的魔改版本,包括本文使用的UNet++。
在UNet++中,作者认为skip-connection这种直接连接方式过于粗糙,会造成连接的两个卷积层输入拥有较大的语义差别,而这种语义差别会加大网络的学习难度,同时作者认为如果进行连接的卷积层的特征图具有相当程度的语义相似性,那么整个网络的学习难度会大大减少。
为什么会有语义不一致性呢,我们将U-Net的网络结构平铺展开,可以看到第一次下采样之前的特征图会被送到相当靠后的卷积层中进行特征的直接连接。然而我们知道,在深度卷积网络中,随着网络层数的加深,卷积层所输出的特征会越来越抽象,前几层网路所获得的特征可能是线条,边缘之类的特征,那最后一层可能就是更加抽象的特征。
在这里使用抽象这个词有点儿玄学,不过很轻松的就能够理解这种语义差别的由来:网络的前几层感受野比较小,所提取的特征必然只和局部相关,而最后几层网络的感受野相当之大,所提取的特征有相当大可能是一些全局特征,同网络的前面几层相差很大那就成为了必然的事情。
那么如果将差异较大的浅层特征、深层特征进行直接连接,由于两者间较大的差异,想使用差异如此之大的浅层特征去对深层特征进行补充必然会加大网络的学习难度。
因此,为了减少语义差别,U-Net++在U-Net的直接连接的基础之上增加了类似于Dense结构的卷积层,并融合了下一阶段卷积的特征。完整模型结构如下图所示:

以X(1,2)为例:它是由X(1,0),X(1,1)和进行上采样之后X(2,1)组成。
以上就是U-Net的网络结构了。简单来理解,UNet++是一种更密集的UNet网络模型,更详细的内容请参考原论文。
3.3 训练和评估
训练脚本train_demo.py如下:
import paddle
from paddleseg.models import UNetPlusPlus
from paddleseg.models.losses import BCELoss
from paddleseg.core import train
from paddleseg.utils import get_sys_env
from paddleseg.transforms import Resize
from changedataset import ChangeDataset
# 定义数据集读取器
dataset_path = 'dataset/WHU_dataset'
transforms = [Resize([512, 512])]
train_data = ChangeDataset(dataset_path, 'train', transforms)
val_data = ChangeDataset(dataset_path, 'val', transforms)
# 定义优化器及损失
epochs = 10
batch_size = 6
iters = epochs * 2153 // batch_size
base_lr = 2e-4
losses = {}
losses['types'] = [BCELoss()]
losses['coef'] = [1]
# 定义运行环境
env_info = get_sys_env()
place = 'gpu' if env_info['Paddle compiled with cuda'] and env_info[
'GPUs used'] else 'cpu'
paddle.set_device(place)
model = UNetPlusPlus(in_channels=6, num_classes=2, use_deconv=True)
# paddle.summary(model, (1, 6, 1024, 1024)) # 可查看网络结构
lr = paddle.optimizer.lr.CosineAnnealingDecay(base_lr, T_max=(iters // 3), last_epoch=0.5) # 余弦衰减
optimizer = paddle.optimizer.Adam(lr, parameters=model.parameters()) # Adam优化器
# 训练
train(
model=model,
train_dataset=train_data,
val_dataset=val_data,
optimizer=optimizer,
save_dir='result',
iters=iters,
batch_size=batch_size,
save_interval=int(iters/10), # 总共保存10个模型
log_iters=10,
num_workers=4,
losses=losses,
use_vdl=True)
单机单卡训练:
python train_demo.py单机多卡训练:
export CUDA_VISIBLE_DEVICES=0,1,2,3
python -m paddle.distributed.launch train_demo.py本文使用4张显卡训练,训练耗时大概是1小时左右。
使用下面的命令可以通过网页查看训练过程曲线:
visualdl --logdir result训练过程曲线如下所示:
 训练损失函数变化
训练损失函数变化
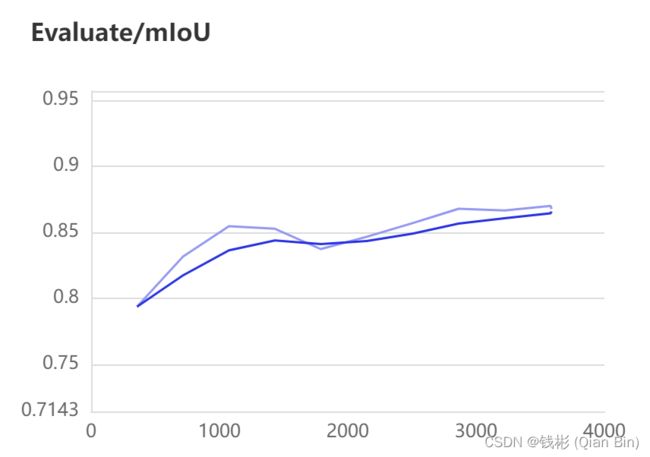 mIOU变化
mIOU变化
最终评估结果如下:
| 背景IOU | 前景IOU | 平均mIOU |
| 0.9838 | 0.7561 | 0.8699 |
从验证集上看到整体的检测精度还是比较高的。
四、测试及可视化
本小节我们基于上述训练好的模型进一步来测试样本。
测试代码如下:
import paddle
from paddleseg.models import UNetPlusPlus
from paddleseg.transforms import Resize
import matplotlib.pyplot as plt
from changedataset import ChangeDataset
# 加载数据集
dataset_path = 'dataset/WHU_dataset'
transforms = [Resize([512, 512])]
test_data = ChangeDataset(dataset_path, 'test', transforms)
# 加载模型
model_path = 'result/best_model/model.pdparams' # 加载得到的最好参数
model = UNetPlusPlus(in_channels=6, num_classes=2, use_deconv=True)
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
# 读取test数据并显示
for idx, (img, lab) in enumerate(test_data):
if idx == 90: # 查看第2个
m_img = img.reshape((1, 6, 512, 512))
m_pre = model(m_img)
s_img = img.reshape((6, 512, 512)).numpy().transpose(1, 2, 0)
# 拆分6通道为两个3通道的不同时段图像
s_A_img = s_img[:,:,0:3]
s_B_img = s_img[:,:,3:6]
lab_img = lab.reshape((512, 512)).numpy()
pre_img = paddle.argmax(m_pre[0], axis=1).reshape((512, 512)).numpy()
plt.figure(figsize=(20, 20))
plt.subplot(2,2,1);plt.imshow(s_A_img.astype('int64'));plt.title('Time 1')
plt.subplot(2,2,2);plt.imshow(s_B_img.astype('int64'));plt.title('Time 2')
plt.subplot(2,2,3);plt.imshow(lab_img);plt.title('Label')
plt.subplot(2,2,4);plt.imshow(pre_img);plt.title('Change Detection')
plt.savefig("result/result.jpg")
break测试效果如下:

可以看到准确的将变化区域检测了出来,但是整体边界与groundtruth还不完全吻合,后面还可以再进行优化。
五、与其它模型比对
5.1 模型代码修改
前面我们使用的是UNetPlusPlus模型,这个模型预留了输入通道数的接口,因此我们在调用时不需要修改模型代码就可以直接使用。但是PaddleSeg里面其它模型大部分都没有预留这个接口,而我们的模型输入是6通道的,因此,需要微改模型底层的代码。
下面以UNet模型为例,讲解如何修改底层模型(注意,PaddleSeg一定要使用本地安装方式,这样方便我们直接修改模型代码,不要使用pip install paddleseg这种在线方式)。
另外,每次修改了PaddleSeg底层模型后需要重新卸载和安装PaddleSeg。
修改位置位于PaddleSeg套件目录下:
PaddleSeg/paddleseg/models/找到其中的unet.py文件。由于UNet包括Encode和Decode两部分,我们只需要找到Encode的forward部分,然后修改对应的输入通道数即可。具体的,找到Encoder这个类,然后修改代码如下:
self.double_conv = nn.Sequential(
layers.ConvBNReLU(3, 64, 3), layers.ConvBNReLU(64, 64, 3))修改为:
self.double_conv = nn.Sequential(
layers.ConvBNReLU(6, 64, 3), layers.ConvBNReLU(64, 64, 3))具体的修改需要对照原始模型的写法,找到模型最开始推理的地方,修改输入通道数即可。
然后按照前面的内容,修改一下训练脚本中model定义即可,然后重新开始训练。
完整训练代码如下:
import paddle
from paddleseg.models import UNet
from paddleseg.models.losses import BCELoss
from paddleseg.core import train
from paddleseg.utils import get_sys_env
from paddleseg.transforms import Resize
from changedataset import ChangeDataset
# 定义数据集读取器
dataset_path = 'dataset/WHU_dataset'
transforms = [Resize([512, 512])]
train_data = ChangeDataset(dataset_path, 'train', transforms)
val_data = ChangeDataset(dataset_path, 'val', transforms)
# 定义优化器及损失
epochs = 10
batch_size = 6
iters = epochs * 2153 // batch_size
base_lr = 2e-4
losses = {}
losses['types'] = [BCELoss()]
losses['coef'] = [1]
# 定义运行环境
env_info = get_sys_env()
place = 'gpu' if env_info['Paddle compiled with cuda'] and env_info[
'GPUs used'] else 'cpu'
paddle.set_device(place)
# 定义模型
model = UNet(num_classes=2, use_deconv=True)
lr = paddle.optimizer.lr.CosineAnnealingDecay(base_lr, T_max=(iters // 3), last_epoch=0.5) # 余弦衰减
optimizer = paddle.optimizer.Adam(lr, parameters=model.parameters()) # Adam优化器
# 训练
train(
model=model,
train_dataset=train_data,
val_dataset=val_data,
optimizer=optimizer,
save_dir='result_unet',
iters=iters,
batch_size=batch_size,
save_interval=int(iters/10), # 总共保存10个模型
log_iters=10,
num_workers=4,
losses=losses,
use_vdl=True)
通过上面的方法,我们就可以方便的切换实现多种语义分割模型的比对。
另外,对于需要提供backbone的模型,例如deeplabv3,我们需要修改models/backbones下的相关文件。例如使用backbone为resnet_vd50,那么我们需要修改resnet_vd.py,然后找到对应的代码:
self.conv1_1 = ConvBNLayer(
in_channels=3,
out_channels=32,
kernel_size=3,
stride=2,
act='relu',
data_format=data_format)修改为:
self.conv1_1 = ConvBNLayer(
in_channels=6,
out_channels=32,
kernel_size=3,
stride=2,
act='relu',
data_format=data_format)最后在模型训练的时候,修改相关代码如下:
from paddleseg.models import DeepLabV3P
from paddleseg.models.backbones import ResNet50_vd
model = DeepLabV3P(num_classes=2,backbone=ResNet50_vd())通过上面的方式,我们就可以很容易的替换模型进行精度测试了。
5.2 模型性能比对
| 方法 | 背景IoU | 前景IoU | 平均mIoU | 模型大小 |
| UNetPlusPlus | 0.9838 | 0.7561 | 0.8699 | 35.4M |
| UNet | 0.9837 | 0.7575 | 0.8706 | 49.1M |
| HarDNet | 0.9826 | 0.7465 | 0.8645 | 16.1M |
| DeepLabV3Plus | 0.9810 | 0.7250 | 0.8530 | 104.6M |
本文尝试了几种算法模型,具体见上表。可以发现,并不是模型越重效果越好,例如DeepLabV3Plus模型大小是104M,但是它的评估结果反而最差。可能的原因是数据量太少,已经过拟合了,大模型没有“喂饱”。
对于这个数据集来说,基本上以UNet为主的算法可以很容易达到mIoU>=0.86的精度,想要继续大幅提高精度,一种思路就是使用迁移学习或者大量扩充数据集来提高大模型的精度。
参考文献
【1】Zhou, Zongwei, Md Mahfuzur Rahman Siddiquee, Nima Tajbakhsh, and Jianming Liang. "Unet++: A nested u-net architecture for medical image segmentation." In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, pp. 3-11. Springer, Cham, 2018.