A-Star算法探索和实现(三)
本篇摘要
在上一篇中我们提出了四个问题,分别是:
1.障碍物生成出现“死胡同”问题,如何解决?
2.障碍物生成在网格的对角顶点处,是否具有意义?
3.路径周围存在障碍物时,按照对角线移动是否合理?
4.查找最佳路径的方式,除了权值这个判断条件,还需要附加什么条件来辅助寻找最佳路径或者如何改进寻找最佳路径的方式?
第一个问题针对的是随机生成的障碍物集合,是否存在使得起始点到终点的路径无解的情况,如果存在这种情况,我们就称其为“死胡同”问题,本篇我们将针对第一个问题进行探讨和解决。
解决方案
这个问题本质上是要检测当前生成的BlockNode集是否合理,如果合理,我们就可以执行A*算法查找最佳路径,否则重新生成一组BlockNode集再次进行检测,直到生成合理的BlockNode集为止。我们可以通过预寻路的方式去检测当前BlockNode集是否合理,具体步骤如下:
(1)
传入CurNode(初始为起始点Node),生成CurNode的NextNode集,生成BlockNode集。设CurNode坐标为(a,b),从NextNode集中获取x=a+1的Node集为xNodes,获取y=b+1的Node集为yNodes,设isContainX=False,isContainY=False。
(2)
①若xNodes包含于BlockNode集,则isContainX = True。
②若yNodes包含于BlockNode集,则isContainY = True。
(3)
③若isContainX = True 并且 isContainY = True,则为“死胡同”。
④若isContainX = False 并且 isContainY = False,从NextNode集中获取CurNode下一步最佳Node为neNode,且CurNode=neNode。
⑤若isContainX = True 并且 isContainY = False,则可从NextNode集中剔除xNodes,从NextNode集中获取CurNode下一步最佳Node为neNode,且CurNode=neNode。
⑥若isContainX = False 并且 isContainY = True,则可从NextNode集中剔除yNodes,从NextNode集中获取CurNode下一步最佳Node为neNode,且CurNode=neNode。
(4)
⑧若CurNode等于终点Node,则可到达终点。
⑨若CurNode不等于终点Node,重复执行(1)(2)(3)(4)步骤,直至出现“死胡同“或可到达终点。
(5)
⑩若检测结果为可到达终点,则指向A*算法寻找最佳路径,否则重新生成BlockNode集再次重复上述过程。
示例代码UML图

效果截图
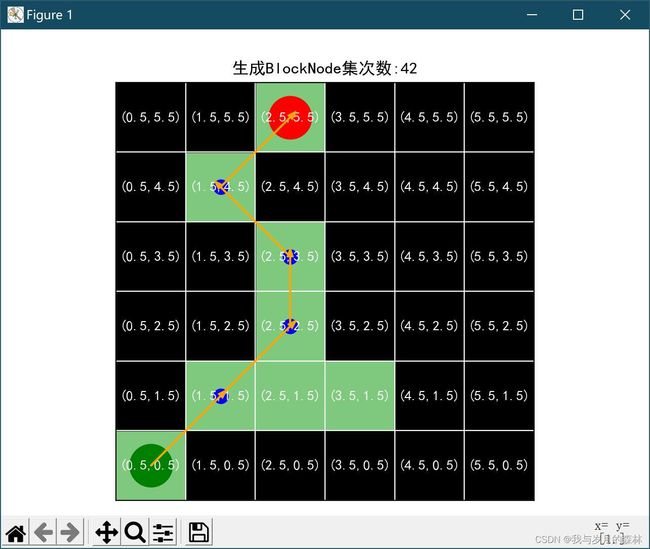
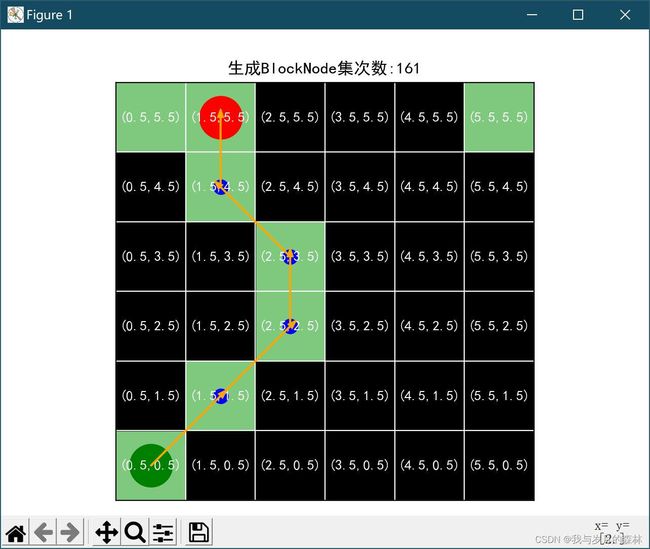
代码示例(Python)
Grid.py
import matplotlib.pyplot as pp
import numpy as np
from myCodes import SharedData as sd
from myCodes import Node as node
# 视图的构建和绘制
class Grid:
# 横纵坐标轴的刻度标记
__xLabels = []
__yLabels = []
# 网格单元格的信息
__data = None
# 是否完成初始化
__isInit = False
def __init__(self, p_rowsCount=6, p_colsCount=6):
if self.__isInit is False:
# 网格的行列数
self.__rowsCount = p_rowsCount
self.__colsCount = p_colsCount
# 将网格的行列数设置为共享信息
sd.SharedData.rowsCount = self.__rowsCount
sd.SharedData.colsCount = self.__colsCount
self.__isInit = True
# 绘制图形
def Draw(self):
"""绘制图形"""
pp.rcParams['font.sans-serif'] = ['SimHei']
pp.title(sd.SharedData.blockInfo)
# 获取坐标轴实例
v_ax = pp.gca()
self._AxisSet(v_ax)
self._GridValueSet(v_ax)
# 将数据以二维图片的形式进行显示
v_ax.imshow(self.__data, cmap='Accent', aspect='equal', vmin=0, vmax=255)
# 标记起始点和终点
self.Mark(sd.SharedNodes().GetStartNode(), 30, 'go')
self._PathNodeSet()
self.Mark(sd.SharedNodes().GetEndNode(), 30, 'ro')
# 布置网格线
pp.grid(visible=True, color='w')
pp.tight_layout()
pp.show()
# 标记所查找到的路径
def _PathNodeSet(self):
v_pathNodes = sd.SharedNodes().GetPathNodes()
v_length = len(v_pathNodes)
for i in range(v_length):
if 0 < i < v_length - 1:
self.Mark(v_pathNodes[i], 10, 'bo')
self._Arrow(v_pathNodes[i - 1], v_pathNodes[i])
elif i == v_length - 1:
self._Arrow(v_pathNodes[i - 1], v_pathNodes[i])
# 标记方法
@classmethod
def Mark(cls, p_node: node.Node, p_marksize: int, p_fmt: str):
"""
标记Node
**p_node**:表示待标记的Node
**p_marksize**:表示标记的尺寸大小
**p_fmt**:表示颜色和图形的样式描述
"""
v_x = p_node.nodePos.x
v_y = p_node.nodePos.y
pp.plot(v_x, v_y, p_fmt, markersize=p_marksize, zorder=1)
# 箭头指向方法
def _Arrow(self, p_firstNode, p_secondNode):
v_dx = p_secondNode.nodePos.x - p_firstNode.nodePos.x
v_dy = p_secondNode.nodePos.y - p_firstNode.nodePos.y
pp.arrow(p_firstNode.nodePos.x, p_firstNode.nodePos.y, v_dx, v_dy, color='orange', width=0.01, head_width=0.08,
zorder=3)
# 坐标轴设置
def _AxisSet(self, p_ax):
v_ax = p_ax
for i in range(1, self.__colsCount + 1):
self.__xLabels.append(str(i))
for i in range(1, self.__rowsCount + 1):
self.__yLabels.append(str(i))
# 隐藏刻度线
v_ax.tick_params(left=False, bottom=False, top=False, right=False)
# 生成Image Data
v_low = 1
if self.__rowsCount > self.__colsCount:
v_high = self.__rowsCount
else:
v_high = self.__colsCount
self.__data = np.random.randint(v_low, v_high, size=(self.__rowsCount + 1, self.__colsCount + 1))
# 设置横纵坐标轴的范围
pp.xlim(1, self.__colsCount)
pp.ylim(1, self.__rowsCount)
# 设置坐标轴的刻度标记
v_ax.set_xticks(np.arange(self.__colsCount), labels=self.__xLabels, visible=False)
v_ax.set_yticks(np.arange(self.__rowsCount), labels=self.__yLabels, visible=False)
# 设置坐标轴的横纵轴比例相等
v_ax.set_aspect('equal')
# 网格内容设置
def _GridValueSet(self, p_ax):
v_ax = p_ax
for i in range(self.__rowsCount + 1):
for j in range(self.__colsCount + 1):
v_str = '(' + str(i + 0.5) + ',' + str(j + 0.5) + ')'
v_ax.text(i + 0.5, j + 0.5, v_str, ha='center', va='center', color='w')Node.py
import random
from enum import Enum, unique
from myCodes import SharedData as sd
import threading as th
# Node坐标类
class NodePosition:
def __init__(self, p_x: float = 1, p_y: float = 1):
"""
Node坐标信息初始化
:param p_x: 横坐标值
:param p_y: 纵坐标值
"""
self.x = p_x
self.y = p_y
def __str__(self):
return '[' + str(self.x) + ',' + str(self.y) + ']'
# Node标签
@unique
class NodeTag(Enum):
PATHNODE = 1
BLOCKNODE = 2
# Node类
class Node:
def __init__(self, p_nodeName: str, p_nodePos: NodePosition):
"""
Node初始化
:param p_nodeName: Node名称
:param p_nodePos: Node的坐标信息
"""
self.nodeName = p_nodeName
self.nodePos = p_nodePos
# f=g+h,g代表从上一个点到该点的代价和,h代表从该点到终点的代价和,f代表总权值weight
self.f: int = 0
self.g: int = 0
self.h: int = 0
# Node的标签,用于判断是否为不可到达的Node,
self.nodeTag = NodeTag.PATHNODE
def SetWeight(self, p_f: int, p_g: int, p_h: int):
"""
设置Node的权值
:param p_f: 代表总权值weight, f = g + h
:param p_g: 代表从上一个点到该点的代价和
:param p_h: 代表从该点到终点的代价和
:return: 无返回值
"""
self.f = p_f
self.g = p_g
self.h = p_h
def __str__(self):
return '{nodeName:' + self.nodeName + ',nodeTag:' + self.nodeTag.name + ',nodePos:' + str(
self.nodePos) + ',f=' + str(
self.f) + ',g=' + str(
self.g) + ',h=' + str(self.h) + '}'
def __eq__(self, other):
if other is not None and self.nodePos.x == other.nodePos.x and self.nodePos.y == other.nodePos.y:
return True
return False
# Node工厂,用来创建和获取起始点Node和终点Node
class NodeFactory:
__lock = th.Lock()
__isCreateEndNode = False
__isCreateStartNode = False
__startNode: Node
__endNode: Node
# Node名称索引
__nameIndex = 1
# GenerateOneNode的Node索引
__rowIndex = 1
__colIndex = 1
__generateCount = 0
def __init__(self):
if self.__class__.__isCreateStartNode is False:
self._CreateStartNode()
sd.SharedNodes().SetStartNode(self.__class__.__startNode, 'SNSET')
if self.__class__.__isCreateEndNode is False:
self._CreateEndNode()
sd.SharedNodes().SetEndNode(self.__class__.__endNode, 'ENSET')
def __new__(cls, *args, **kwargs):
if hasattr(NodeFactory, '__instance') is False:
with cls.__lock:
if hasattr(NodeFactory, '__instance') is False:
NodeFactory.__instance = object.__new__(cls)
return NodeFactory.__instance
# 创建起始点Node
def _CreateStartNode(self):
v_nodePos = NodePosition(0.5, 0.5)
self.__class__.__startNode = Node('StartNode', v_nodePos)
self.__class__.__isCreateStartNode = True
# 创建终点Node
def _CreateEndNode(self):
v_startNode = self.__class__.__startNode
v_node = v_startNode
while v_node == v_startNode:
v_node = self.GenerateOneNode('EndNode', p_isRandom=True)
self.__class__.__endNode = v_node
self.__class__.__isCreateEndNode = True
def GenerateNodes(self, p_count, p_isRandom=False):
"""
生成指定数量的非重复Node集
:param p_count: 生成的Node的数量
:param p_isRandom: 是否随机生成,默认为False
:return: 返回一个列表
"""
v_list = []
v_index = 1
v_startNode = self.__class__.__startNode
v_endNode = self.__class__.__endNode
while len(v_list) < p_count:
v_node = self.GenerateOneNode('Node' + str(v_index), p_isRandom=p_isRandom)
if v_node is None:
break
else:
v_isRepeat = NodeCheck.RepeatCheck(v_list, v_node)
if v_isRepeat is False and v_node != v_startNode and v_node != v_endNode:
v_list.append(v_node)
v_index += 1
return v_list
def GenerateOneNode(self, p_name: str, p_isRandom=False):
"""
生成一个指定名称的Node
:param p_name: 生成的Node的名称
:param p_isRandom: 是否随机生成,默认为False,若为True则为非随机模式生成,将按照起始点从左至右&从下至上的顺序生成
:return: 默认会返回Node,在非随机生成模式下,当该方法生成完当前网格的所有Node后会进行重置并返回None,请保持对该方法的返回值是否为None的判断,避免陷入死循环
"""
v_rowsCount = sd.SharedData.rowsCount
v_colsCount = sd.SharedData.colsCount
v_x = 0.5
v_y = 0.5
if p_isRandom:
v_i = random.randint(0, v_rowsCount - 1)
v_x = v_i + 0.5
v_i = random.randint(0, v_colsCount - 1)
v_y = v_i + 0.5
else:
if self.__class__.__colIndex < v_colsCount:
if self.__class__.__rowIndex > v_rowsCount:
self.__class__.__rowIndex -= v_rowsCount
self.__class__.__colIndex += 1
v_x = (self.__class__.__rowIndex - 1) + 0.5
v_y = (self.__class__.__colIndex - 1) + 0.5
self.__class__.__rowIndex += 1
self.__class__.__generateCount += 1
else:
if self.__class__.__rowIndex <= v_rowsCount:
v_x = (self.__class__.__rowIndex - 1) + 0.5
v_y = (self.__class__.__colIndex - 1) + 0.5
self.__class__.__rowIndex += 1
self.__class__.__generateCount += 1
else:
self.__class__.__rowIndex = 1
self.__class__.__colIndex = 1
if self.__class__.__generateCount > v_rowsCount * v_colsCount:
self.__class__.__generateCount = 0
return None
v_nodePos = NodePosition(v_x, v_y)
v_node = Node(p_name, v_nodePos)
return v_node
def GenerateNextNodes(self, p_node: Node):
"""
获取某个Node下一步可以前往的Node集(NextNode集)
:param p_node: 待生成NextNode集的Node
:return: 若p_node为None则返回None,否则返回一个列表
"""
v_list = []
if p_node is not None:
v_p = p_node.nodePos
v_posList = [(v_p.x - 1, v_p.y), (v_p.x - 1, v_p.y + 1), (v_p.x, v_p.y + 1), (v_p.x + 1, v_p.y + 1),
(v_p.x + 1, v_p.y), (v_p.x + 1, v_p.y - 1), (v_p.x, v_p.y - 1), (v_p.x - 1, v_p.y - 1)]
v_nameList = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
for i in range(len(v_posList)):
v_nodeName = v_nameList[i] + str(self.__class__.__nameIndex)
v_nodePos = NodePosition(v_posList[i][0], v_posList[i][1])
v_node = Node(v_nodeName, v_nodePos)
v_list.append(v_node)
self.__class__.__nameIndex += 1
return v_list
return v_list
# Node或Node集的检测
class NodeCheck:
@classmethod
def RepeatCheck(cls, p_list: list[Node], p_node: Node):
"""
判断Node集中是否存在某个Node
:param p_list: Node集
:param p_node: 待检测的Node
:return: 存在返回True,否则返回False
"""
if p_list is not None and len(p_list) != 0:
for n in p_list:
if n == p_node:
return True
return False
@classmethod
def OutOfRange(cls, p_node: Node):
"""
判断Node是否超出了网格限定范围
:param p_node: 待检测的Node
:return:若超出了范围则返回True,否则返回False
"""
v_minX = 0.5
v_minY = 0.5
v_maxX = (sd.SharedData.rowsCount - 1) + 0.5
v_maxY = (sd.SharedData.colsCount - 1) + 0.5
v_x = p_node.nodePos.x
v_y = p_node.nodePos.y
if v_minX <= v_x <= v_maxX and v_minY <= v_y <= v_maxY:
return False
return True
@classmethod
def IsContainNodes(cls, p_listA: list[Node], p_listB: list[Node]):
"""
判断某个Node集(p_listA)是否包含另一个Node集(p_listB)
:param p_listA: 待检测的Node集
:param p_listB: 被包含的Node集
:return: 若p_listA包含p_listB则返回True,否则返回False,若p_listA为None也会返回False
"""
if p_listA is not None and len(p_listA) != 0:
if p_listB is None or len(p_listB) == 0:
return True
else:
for n in p_listB:
if cls.RepeatCheck(p_listA, n) is False:
return False
return True
return False
# Node或Node集的处理
class NodeDeal:
# 对角线移动一格的代价
__diagonalCost = 14
# 上下或左右移动一格的代价
__nonDiagonalCost = 10
@classmethod
def RemoveRepeateNode(cls, p_list: list[Node]):
"""
移除Node集中的重复Node
:param p_list: Node集
:return: 若p_list为None则返回None,否则返回一个列表
"""
if p_list is not None and len(p_list) != 0:
v_list = []
v_length = len(p_list)
for i in range(v_length):
v_isRepeate = False
for j in range(i + 1, v_length):
if p_list[i] == p_list[j]:
v_isRepeate = True
break
if v_isRepeate is False:
v_list.append(p_list[i])
return v_list
return p_list
@classmethod
def RemoveNode(cls, p_sourceList: list[Node], p_node: Node):
"""
移除Node集(p_sourceList)中的某个Node(p_node)
:param p_sourceList: 待处理的Node集
:param p_node: 参考Node
:return: 返回一个列表
"""
v_j1 = p_sourceList is not None and p_node is not None
if v_j1 and len(p_sourceList) != 0:
v_list = []
for n in p_sourceList:
if n != p_node:
v_list.append(n)
return v_list
return p_sourceList
@classmethod
def RemoveNodes(cls, p_sourceList: list[Node], p_refList: list[Node]):
"""
将一个Node集(p_sourceList)中另一个Node集(p_refList)的元素去除
:param p_sourceList: 待处理的原Node集
:param p_refList: 参考Node集
:return: 默认返回一个列表,若p_sourceList或p_refList为None则返回原Node集
"""
v_j1 = p_sourceList is not None and p_refList is not None
if v_j1 and len(p_sourceList) != 0 and len(p_refList) != 0:
v_list = []
for n in p_sourceList:
if NodeCheck.RepeatCheck(p_refList, n) is False:
v_list.append(n)
return v_list
return p_sourceList
@classmethod
def RemoveOutOfRangeNode(cls, p_list: list[Node]):
"""
移除Node集中超出网格范围的Node
:param p_list: 待处理的Node集
:return: 默认返回一个列表,如果p_list为None则返回None
"""
if p_list is not None and len(p_list) != 0:
v_list = []
for n in p_list:
if NodeCheck.OutOfRange(n) is False:
v_list.append(n)
return v_list
return p_list
@classmethod
def ReplaceNode(cls, p_list: list[Node], p_node: Node):
"""
替换Node集中与某个Node相同的Node
:param p_list: Node集
:param p_node: 用于替换的Node
:return: 若p_list和p_node为None则返回None,否则返回一个列表
"""
v_j1 = p_list is not None and p_node is not None
if v_j1 and len(p_list) != 0:
v_list = p_list
if NodeCheck.RepeatCheck(v_list, p_node):
for i in range(len(v_list)):
if v_list[i] == p_node:
v_list[i] = p_node
return v_list
return p_list
@classmethod
def SetWeightValue(cls, p_diagonalCost: int = 14, p_nonDiagonalCost: int = 10):
"""
设置diagonalCost(对角线移动权值)和nonDiagonalCost(非对角线移动权值)
:param p_diagonalCost: 对角线移动权值,默认为14
:param p_nonDiagonalCost: 非对角线移动权值,默认为10
"""
if p_diagonalCost >= 0:
cls.__diagonalCost = p_diagonalCost
if p_nonDiagonalCost >= 0:
cls.__nonDiagonalCost = p_nonDiagonalCost
@classmethod
def CalculateWeight(cls, p_list: list[Node], p_startNode: Node, p_endNode: Node):
"""
计算某个Node集相对起始点和终点的权值
:param p_list: 待计算权值的Node集
:param p_startNode: 起始点
:param p_endNode: 终点
:return: 默认返回一个列表,若p_list或p_startNode或p_endNode有一个为None则返回None
"""
v_j1 = p_list is not None and p_startNode is not None and p_endNode is not None
if v_j1 and len(p_list) != 0:
v_list = p_list
v_startNodeX = p_startNode.nodePos.x
v_startNodeY = p_startNode.nodePos.y
v_endNodeX = p_endNode.nodePos.x
v_endNodeY = p_endNode.nodePos.y
for n in v_list:
v_x = n.nodePos.x
v_y = n.nodePos.y
if v_x == v_y:
v_g = abs((v_x - v_startNodeX)) * cls.__diagonalCost
if v_endNodeX == v_endNodeY:
v_h = abs((v_endNodeX - v_x)) * cls.__diagonalCost
else:
v_h = abs((v_endNodeX - v_x)) * cls.__nonDiagonalCost + abs(
(v_endNodeY - v_y)) * cls.__nonDiagonalCost
else:
v_g = abs((v_x - v_startNodeX)) * cls.__nonDiagonalCost + abs(
(v_y - v_startNodeY)) * cls.__nonDiagonalCost
v_h = abs((v_endNodeX - v_x)) * cls.__nonDiagonalCost + abs(
(v_endNodeY - v_y)) * cls.__nonDiagonalCost
v_f = v_g + v_h
n.SetWeight(int(v_f), int(v_g), int(v_h))
return v_list
return p_list
@classmethod
def SortNodes(cls, p_list: list[Node], p_endMax=True):
"""
对Node集按照总权值(f)进行排序
:param p_list: 待排序的Node集
:param p_endMax: 是否按照总权值从小到大排序,默认为True
:return: 默认返回一个列表,若p_list为None则返回None
"""
if p_list is not None and len(p_list) != 0:
v_list = p_list
if p_endMax:
for i in range(0, len(v_list)):
for j in range(i + 1, len(v_list)):
if v_list[i].f > v_list[j].f:
v_node = v_list[i]
v_list[i] = v_list[j]
v_list[j] = v_node
else:
for i in range(0, len(v_list)):
for j in range(i + 1, len(v_list)):
if v_list[i].f < v_list[j].f:
v_node = v_list[i]
v_list[i] = v_list[j]
v_list[j] = v_node
return v_list
return p_listBlock.py
from myCodes import Grid as grid
from myCodes import Node as node
from myCodes import SharedData as sd
import threading as th
# 用于生成阻碍物
class Block:
__lock = th.Lock()
__blockCount = 0
__unCheckedNodes = []
__checkedNodes = []
__isImpassable = False
__generateNum = 0
def __init__(self, p_blcokCount: int = 5):
"""
:param p_blcokCount: 生成的障碍物的数量
"""
self.__class__.__blockCount = p_blcokCount
self.__endNode = sd.SharedNodes().GetEndNode()
def __new__(cls, *args, **kwargs):
if hasattr(Block, '__instance') is False:
with cls.__lock:
if hasattr(Block, '__instance') is False:
Block.__instance = object.__new__(cls)
return Block.__instance
# 用于生成Block
def Create(self):
v_list = []
v_curNode = sd.SharedNodes().GetStartNode()
while self._BlockNodeCheck(v_list, v_curNode) is False:
v_list = self._SelectNode()
self._Reset()
sd.SharedData.blockInfo = '生成BlockNode集次数:' + str(self.__class__.__generateNum)
v_list = self._GenerateBlock(v_list)
sd.SharedNodes().Submit(v_list)
self._MarkBlockNode(v_list)
# 生成BlockNode集
def _SelectNode(self):
v_list = node.NodeFactory().GenerateNodes(self.__class__.__blockCount, p_isRandom=True)
return v_list
# 对所生成的BlockNode集进行检测,若出现死胡同则重新生成BlockNode集
def _BlockNodeCheck(self, p_list, p_curNode):
# 若返回值为False:p_list为None,死胡同
# 若返回值为True:无死胡同
# p_list在这里代表的是生成的BlockNode集
v_isImpassable = self.__class__.__isImpassable
v_j1 = p_list is not None and p_curNode is not None and v_isImpassable is False
if v_j1 and len(p_list) != 0:
v_nextNodes = self._GetNextNodes(p_curNode, p_list)
v_XNodes = self._GetXNodes(p_curNode.nodePos.x + 1, v_nextNodes)
v_YNodes = self._GetYNodes(p_curNode.nodePos.y + 1, v_nextNodes)
v_isContainX = node.NodeCheck.IsContainNodes(p_list, v_XNodes)
v_isContainY = node.NodeCheck.IsContainNodes(p_list, v_YNodes)
if v_isContainX and v_isContainY:
self.__class__.__isImpassable = True
return False
elif v_isContainX is False and v_isContainY is False:
if v_nextNodes[0] == self.__endNode:
return True
else:
return self._BlockNodeCheck(p_list, v_nextNodes[0])
else:
if v_isContainX:
v_nextNodes = node.NodeDeal.RemoveNodes(v_nextNodes, v_XNodes)
else:
v_nextNodes = node.NodeDeal.RemoveNodes(v_nextNodes, v_YNodes)
if v_nextNodes[0] == self.__endNode:
return True
else:
return self._BlockNodeCheck(p_list, v_nextNodes[0])
return False
# 打印Node集的方法
def _Print(self, p_list, p_str=''):
v_str = p_str
for n in p_list:
v_str += str(n) + '---'
print(v_str)
# BlockNode集检测重置
def _Reset(self):
self.__class__.__isImpassable = False
self.__class__.__unCheckedNodes = []
self.__class__.__checkedNodes = []
self.__class__.__generateNum += 1
# 获取处理后的NextNode集
def _GetNextNodes(self, p_curNode, p_list):
v_uclist = self.__class__.__unCheckedNodes
self.__class__.__unCheckedNodes = node.NodeDeal.RemoveNode(v_uclist, p_curNode)
self.__class__.__checkedNodes.append(p_curNode)
v_nextNodes = node.NodeFactory().GenerateNextNodes(p_curNode)
v_nextNodes = node.NodeDeal.RemoveOutOfRangeNode(v_nextNodes)
v_nextNodes = node.NodeDeal.RemoveNodes(v_nextNodes, self.__class__.__unCheckedNodes)
v_nextNodes = node.NodeDeal.RemoveNodes(v_nextNodes, self.__class__.__checkedNodes)
v_nextNodes = node.NodeDeal.RemoveNodes(v_nextNodes, p_list)
v_nextNodes = node.NodeDeal.CalculateWeight(v_nextNodes, p_curNode, sd.SharedNodes().GetEndNode())
v_nextNodes = node.NodeDeal.SortNodes(v_nextNodes)
return v_nextNodes
# 获取xNodes
def _GetXNodes(self, p_x, p_list):
v_list = []
for n in p_list:
v_x = n.nodePos.x
if v_x == p_x:
v_list.append(n)
return v_list
# 获取yNodes
def _GetYNodes(self, p_y, p_list):
v_list = []
for n in p_list:
v_y = n.nodePos.y
if v_y == p_y:
v_list.append(n)
return v_list
# 生成Block
def _GenerateBlock(self, p_list):
if p_list is not None and len(p_list) != 0:
v_list = p_list
for n in v_list:
n.nodeTag = node.NodeTag.BLOCKNODE
return v_list
return p_list
# 标记生成Block的Node
def _MarkBlockNode(self, p_list):
if p_list is not None and len(p_list) != 0:
for n in p_list:
grid.Grid.Mark(n, 49, 'ks')SearchPath.py
from myCodes import SharedData as sd
from myCodes import Node as node
import threading as th
# 查找最佳路径
class SearchPath:
__lock = th.Lock()
# 对角线移动一格的代价
__diagonalCost = 14
# 上下或左右移动一格的代价
__nonDiagonalCost = 10
__nodeFactory: node.NodeFactory
__currentNode: node.Node
# 是否完成了初始化
__isInit = False
__openList = []
__closeList = []
# 网格行列数
__rowsCount = 0
__colsCount = 0
# x和y的最小值
__minX = 0.5
__minY = 0.5
# x和y的最大值
__maxX = 0
__maxY = 0
# 终点Node
__endNode: node.Node
def __init__(self):
if self.__class__.__isInit is False:
self.__class__.__nodeFactory = node.NodeFactory()
self.__class__.__currentNode = sd.SharedNodes().GetStartNode()
self.__class__.__openList.append(self.__class__.__currentNode)
self.__class__.__rowsCount = sd.SharedData.rowsCount
self.__class__.__colsCount = sd.SharedData.colsCount
self.__class__.__maxX = self.__class__.__rowsCount - 0.5
self.__class__.__maxY = self.__class__.__colsCount - 0.5
self.__class__.__endNode = sd.SharedNodes().GetEndNode()
self.__class__.__isInit = True
def __new__(cls, *args, **kwargs):
if hasattr(SearchPath, '__instance') is False:
with cls.__lock:
if hasattr(SearchPath, '__instance') is False:
SearchPath.__instance = object.__new__(cls)
return SearchPath.__instance
def Search(self, p_isPrint=False):
"""
查找最佳路径
:param p_isPrint: 是否在控制台打印最佳路径的Node集信息,默认为False
"""
while self._UpdateCurrentNode():
# 获取currentNode下一步可以前往的Node,并将它们保存在一个临时列表v_list中
v_list = self.__class__.__nodeFactory.GenerateNextNodes(self.__class__.__currentNode)
v_list = self._NodeCheck(v_list)
v_list = self._CalculateWeight(v_list)
v_list = self._SortNodes(v_list)
self._AddNode(v_list)
sd.SharedNodes().Submit(self.__class__.__closeList)
if p_isPrint:
self._PrintPath()
# 检查临时列表p_list中哪些Node不符合要求,保留符合要求的节点
def _NodeCheck(self, p_list):
if p_list is not None and len(p_list) != 0:
v_list1 = []
v_list2 = []
for n in p_list:
if node.NodeCheck.OutOfRange(n) is False:
v_list1.append(n)
for n in v_list1:
v_isInOpenList = node.NodeCheck.RepeatCheck(self.__class__.__openList, n)
v_isInCloseList = node.NodeCheck.RepeatCheck(self.__class__.__closeList, n)
v_isInBlockList = node.NodeCheck.RepeatCheck(sd.SharedNodes().GetBlockNodes(), n)
if v_isInOpenList is False and v_isInCloseList is False and v_isInBlockList is False:
v_list2.append(n)
return v_list2
return p_list
# 计算临时列表p_list中每个Node的权值
def _CalculateWeight(self, p_list):
if p_list is not None and len(p_list) != 0:
v_list = node.NodeDeal.CalculateWeight(p_list, self.__class__.__currentNode, self.__class__.__endNode)
return v_list
return p_list
# 根据临时列表p_list中每个Node的权值进行排序,权值越大越接近列表尾
def _SortNodes(self, p_list):
if p_list is not None and len(p_list) != 0:
v_list = node.NodeDeal.SortNodes(p_list)
return v_list
return p_list
# 将临时列表p_list拼接在openList的列表尾
def _AddNode(self, p_list):
if p_list is not None and len(p_list) != 0:
v_list = []
for i in range(len(p_list)):
v_n = p_list[i]
v_isInOpenList = node.NodeCheck.RepeatCheck(self.__class__.__openList, v_n)
v_isInCloseList = node.NodeCheck.RepeatCheck(self.__class__.__closeList, v_n)
if v_isInOpenList is False and v_isInCloseList is False:
v_list.append(v_n)
self.__class__.__openList.append(v_list[0])
return True
return False
# 打印最佳路径
def _PrintPath(self):
v_str = ''
v_length = len(self.__class__.__closeList)
for i in range(v_length):
if i < v_length - 1:
v_str += str(self.__class__.__closeList[i]) + '-->'
else:
v_str += str(self.__class__.__closeList[i])
print(v_str)
# 从openList中获取列表尾的元素,将之作为currentNode并加入closeList中,然后将其从openList中移除
def _UpdateCurrentNode(self):
if len(self.__class__.__openList) > 0:
self.__class__.__currentNode = self.__class__.__openList[0]
v_isInCloseList = node.NodeCheck.RepeatCheck(self.__class__.__closeList, self.__class__.__currentNode)
if v_isInCloseList is False:
self.__class__.__closeList.append(self.__class__.__currentNode)
del self.__class__.__openList[0]
if self.__class__.__currentNode == self.__class__.__endNode:
return False
return True
return FalseSharedData.py
from myCodes import Node as node
import threading as th
# 共享信息类
class SharedData:
# 网格行列数
rowsCount = 0
colsCount = 0
blockInfo = ''
# 共享Node和Node集
class SharedNodes:
__instanceLock = th.Lock()
__lock = th.Lock()
__sharedNodes = []
__pathNodes = []
__blockNodes = []
__isUpdatePathNodes = False
__isUpdateBlockNodes = False
__startNode: node.Node
__endNode: node.Node
def __init__(self):
node.NodeFactory()
def __new__(cls, *args, **kwargs):
if hasattr(SharedNodes, '__instance') is False:
with cls.__instanceLock:
if hasattr(SharedNodes, '__instance') is False:
SharedNodes.__instance = object.__new__(cls)
return SharedNodes.__instance
# 起始点Node的设置
def SetStartNode(self, p_node: node.Node, p_password: str = ''):
if p_node is not None and p_password == 'SNSET':
self.__class__.__startNode = p_node
# 终点Node的设置
def SetEndNode(self, p_node: node.Node, p_password: str = ''):
if p_node is not None and p_password == 'ENSET':
self.__class__.__endNode = p_node
def GetStartNode(self):
"""
获取起始点Node
:return: 返回Node
"""
v_node = node.Node(self.__class__.__startNode.nodeName, self.__class__.__startNode.nodePos)
v_node.f = self.__class__.__startNode.f
v_node.g = self.__class__.__startNode.g
v_node.h = self.__class__.__startNode.h
v_node.nodeTag = self.__class__.__startNode.nodeTag
return v_node
def GetEndNode(self):
"""
获取终点Node
:return: 返回Node
"""
v_node = node.Node(self.__class__.__endNode.nodeName, self.__class__.__endNode.nodePos)
v_node.f = self.__class__.__endNode.f
v_node.g = self.__class__.__endNode.g
v_node.h = self.__class__.__endNode.h
v_node.nodeTag = self.__class__.__endNode.nodeTag
return v_node
def GetPathNodes(self):
# 起初该方法是直接返回cls.__pathNodes,这就导致了数据安全性的问题,使得在外部可以直接修改这里pathNodes的数据,所以正确的做法应该像现在这样
# 声明一个新的列表,然后将cls.__pathNodes中的值添加进去,再将新的列表作为返回值传递出去,这说明在Python中直接传递内部的静态变量会传递其引用
"""
获取PathNode集
:return: 返回一个列表
"""
self._UpdateNodes(node.NodeTag.PATHNODE)
v_pathNodes = []
for n in self.__class__.__pathNodes:
v_pathNodes.append(n)
return v_pathNodes
def GetBlockNodes(self):
"""
获取BlockNode集
:return: 返回一个列表
"""
self._UpdateNodes(node.NodeTag.BLOCKNODE)
v_blockNodes = []
for n in self.__class__.__blockNodes:
v_blockNodes.append(n)
return v_blockNodes
def Submit(self, p_list: list[node.Node]):
"""
通过该方法可以实现Node集的添加、删除、修改,建议与GetPathNodes或GetBlockNodes方法配套使用
:param p_list: 修改后的Node集
:return: 无返回值
"""
v_list = node.NodeDeal.RemoveRepeateNode(p_list)
v_list = self._PollutionNodeCheck(v_list)
self._ReplaceSharedNodes(v_list)
self._AddToSharedNodes(v_list)
v_tag = self._GetNodesType(v_list)
self._DeleteSharedNodes(v_list, v_tag)
if v_tag == node.NodeTag.PATHNODE:
self.__class__.__isUpdatePathNodes = False
else:
self.__class__.__isUpdateBlockNodes = False
self._UpdateNodes(v_tag)
# 更新PathNode集和BlockNode集
def _UpdateNodes(self, p_tag):
if p_tag == node.NodeTag.PATHNODE:
if self.__class__.__isUpdatePathNodes is False:
with self.__class__.__lock:
v_list = []
for n in self.__class__.__sharedNodes:
if n.nodeTag == node.NodeTag.PATHNODE:
v_list.append(n)
self.__class__.__pathNodes = v_list
self.__class__.__isUpdatePathNodes = True
else:
if self.__class__.__isUpdateBlockNodes is False:
with self.__class__.__lock:
v_list = []
for n in self.__class__.__sharedNodes:
if n.nodeTag == node.NodeTag.BLOCKNODE:
v_list.append(n)
self.__class__.__blockNodes = v_list
self.__class__.__isUpdateBlockNodes = True
# 脏数据清理
def _PollutionNodeCheck(self, p_list):
if p_list is not None and len(p_list) != 0:
v_tag = self._GetNodesType(p_list)
if v_tag is None:
return p_list
v_list = []
for n in p_list:
if n.nodeTag == v_tag:
v_list.append(n)
return v_list
return p_list
# 获取当前Node集的种类:PathNode集或BlockNode集
def _GetNodesType(self, p_list):
if p_list is not None and len(p_list) != 0:
v_pathNodeCount = 0
v_blockNodeCount = 0
for n in p_list:
if n.nodeTag == node.NodeTag.PATHNODE:
v_pathNodeCount += 1
else:
v_blockNodeCount += 1
if v_pathNodeCount > v_blockNodeCount:
return node.NodeTag.PATHNODE
elif v_pathNodeCount < v_blockNodeCount:
return node.NodeTag.BLOCKNODE
else:
return None
return None
# Node集的修改功能
def _ReplaceSharedNodes(self, p_list):
if p_list is not None and len(p_list) != 0:
with self.__class__.__lock:
v_list = self.__class__.__sharedNodes
for n in p_list:
v_list = node.NodeDeal.ReplaceNode(v_list, n)
self.__class__.__sharedNodes = v_list
# Node集的添加功能
def _AddToSharedNodes(self, p_list):
if p_list is not None and len(p_list) != 0:
with self.__class__.__lock:
v_list = []
for n in p_list:
if node.NodeCheck.RepeatCheck(self.__class__.__sharedNodes, n) is False:
v_list.append(n)
self.__class__.__sharedNodes.extend(v_list)
# Node集的删除功能
def _DeleteSharedNodes(self, p_list: list, p_tag: node.NodeTag):
if p_list is not None and len(p_list) != 0:
with self.__class__.__lock:
if p_tag == node.NodeTag.PATHNODE:
v_nodes = self.__class__.__pathNodes
else:
v_nodes = self.__class__.__blockNodes
for n in v_nodes:
if node.NodeCheck.RepeatCheck(p_list, n) is False:
v_index = self.__class__.__sharedNodes.index(n)
del self.__class__.__sharedNodes[v_index]Main.py
from myCodes import SearchPath as sp
from myCodes import Grid as grid
from myCodes import Block as block
g = grid.Grid()
block.Block(28).Create()
sp.SearchPath().Search()
g.Draw()代码解说
这次主要针对“死胡同“问题进行了探索,我们采用了预寻路的方式检测当前生成的BlockNode集是否合理,这种方式的平均时间复杂度与障碍物Node与网格总Node的比值成正比,也就是说当我们的网格总Node数不变时,若生成的障碍物Node数量越多,往往重新生成BlockNode集的次数也会增多。除此之外我们优化了对Node类的管理,将之前杂乱的代码进行了重新分块,提炼出了数据层家族的新成员——NodeCheck类、NodeDeal类和SharedNodes类,NodeCheck类用于对Node或Node集进行检测,NodeDeal类用于对Node或Node集进行处理,SharedNodes类用于管理Node或Node集的获取,相当于一个Node仓库,目前我们将PathNode集和BlockNode集存放在其中,而且起始点Node和终点Node的获取也放在了这个仓库中,关于这个仓库的实现,我想在”A-Star算法探索和实现特别篇(一)“中进行记录。
下一篇将针对障碍物生成在网格对角顶点处是否具有意义进行进一步探索和实现
如果这篇文章对你有帮助,请给作者点个赞吧!