Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
论文地址:https://arxiv.org/abs/2006.04388
论文代码:https://github.com/implus/GFocal
一阶段检测器基本将目标检测定义为密集的分类和定位(即包围框回归)。分类通常采用Focal Loss优化方法,锚框定位通常在狄拉克分布下学习。一阶段检测器最近的一个趋势是引入单个预测分支来估计定位质量,其中预测的质量有助于分类,从而提高检测性能。本文探讨了质量估计、分类和定位三个基本要素的表示方法。在现有的实践中发现了两个问题:
(1)训练和推理在质量估计和分类上的使用不一致(即单独训练但在测试中综合使用);
(2)当存在歧义和不确定性时,在复杂场景中经常出现的delta分布在定位上不灵活。为了解决这些问题,作者为这些元素设计了新的表示形式。具体地,将质量估计合并到类预测向量中,形成定位质量和分类的联合表示,并使用一个向量来表示锚框位置的任意分布。改进了两个分支表示,消除了不一致的风险,并准确地描述了真实数据中的灵活分布,但包含连续的标签,这超出了Focal Loss的范围。然后作者提出广义焦点损失(GFL),将焦点损失从其离散形式推广到连续版本,以获得成功的优化。在COCO测试开发中,在相同的骨干和训练设置下,GFL使用ResNet-101骨干实现45.0%的AP,超过了最先进的SAPD(43.5%)和ATSS(43.6%),具有更高或相当的推理速度。
一、文章简介
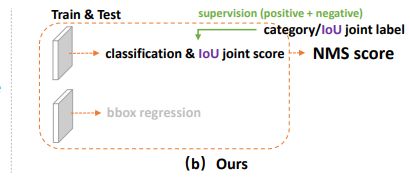
近年来,密集检测器逐渐成为目标检测的主流,同时对包围框表示及其定位质量估计的关注也带来了快速的进展。具体来说,边界框表示被建模为一个简单的Dirac delta分布,该分布在过去的几年里得到了广泛的应用。在FCOS中普及当在推断过程中对非最大抑制(NMS)进行排序过程,将质量估计与分类置信度结合(通常相乘)作为最终得分时,预测额外的定位质量(例如IoU评分或中心度评分)会带来检测精度的持续提高。尽管它们取得了成功,但作者观察到,在现有的实践中存在以下问题:
训练和推理对定位质量估计和分类分数的使用不一致:
(1)在最近的密集检测器中,定位质量估计和分类评分通常是独立训练的,但在推理过程中会综合使用(如乘法)(图1(a);(2)定位质量估计的监督目前只分配给正样本,这是不可靠的,因为负样本可能有机会有不可控制的更高质量的预测(图2(a))。这两个因素导致了训练和测试之间的差距,并可能降低检测性能,例如,在NMS中,随机高质量分数的负样本例子可能会排在预测质量较低的正面例子之前


固定的边框表示:
广泛使用的锚框表示可以看作是目标框坐标的狄拉克delta分布。但是,它没有考虑数据集中的模糊性和不确定性(见图3中图形边界的不清晰)。虽然最近的一些研究将锚框模型为高斯分布,但过于简单,无法捕捉到锚框位置的真实分布。实际上,真实的分布可以是更任意更灵活的,而不需要像高斯函数一样对称。

由于遮挡、阴影、模糊等原因,很多物体的边界不够清晰,以至于真实标签(白框)有时不可信,狄拉克分布有限,不能表明这类问题。相反,边界框一般分布的学习表示可以通过其形状反映底层信息,其中较平缓的分布表示不清楚和模糊的边界(见红色圆圈),尖锐的分布表示明确的情况。我们的模型预测的锚框被标记为绿色。
为了解决上述问题,作者设计了新的锚框及其定位质量表示。
对于定位质量:
作者建议将其与分类得分合并为一个单一且统一的表示:一个分类向量,其在ground-truth类别指数处的值表示其对应的定位质量(通常是本文中预测框与对应的ground-truth框之间的IoU得分)。这样,将分类评分和IoU评分统一为一个联合和单一变量(表示为classiationiou联合表示),可以端到端方式训练,同时在推理过程中直接使用(图1(b))。因此,它消除了训练-测试的不一致性(图1(b)),并加强了定位质量和分类之间的相关性(图2 (b))。此外,负样本的监督将以0为分数,从而整体质量预测变得更加机密和可靠。它特别有利于密集物体探测器,因为它们对整个图像中定期采样的所有候选对象进行排名
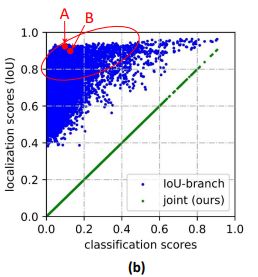
上图中的散点图表示随机抽样的实例及其预测得分,其中蓝色点清楚地说明了单独表示的预测分类得分和预测IoU得分之间的弱相关性。红色圆圈中的部分包含许多可能的样本,具有较大的定位质量预测,这些负样本影响可能排在真正的正样本影响之前。相反,我们的联合表示(绿点)迫使它们相等,从而避免了这种风险。
对于边界框表示:
作者建议通过直接学习其连续空间上的离散概率分布来表示锚框位置的任意分布(本文称之为一般分布),而不引入任何其他更强的先验(如高斯)。因此,可以获得更可靠和准确的锚框估计,同时知道它们的各种潜在分布
下图描述了delta分布,高斯分布和提出的一般分布的思想,其中假设从刚性(delta)到柔性(一般)。下表中列出了关于这些分布的几个关键比较。可以观察到,高斯假设的损失目标实际上是一个动态加权L2损失,其训练的权值与预测方差σ有关。它在某种程度上类似于delta(标准L2损失)在边缘级优化时。此外,还不清楚如何将高斯假设集成到IOU的损失公式中,因为它严重耦合了目标表示的表达式与其优化目标。因此,它不能享受基于iou的优化的好处。相比之下,本文提出的广义分布解耦了表示和损失目标,使其在任何类型的优化中都是可行的,包括边缘级和锚框级。
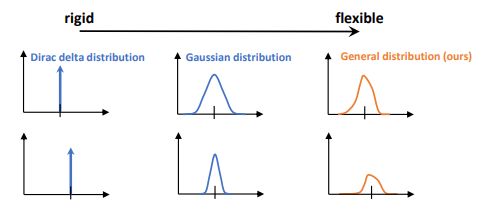
 三种分布的比较。边级别表示在四个方向上的优化,而框级别则表示将边界框作为一个整体考虑的基于IOU的损失。
三种分布的比较。边级别表示在四个方向上的优化,而框级别则表示将边界框作为一个整体考虑的基于IOU的损失。

delta分布(包括由表5分析的高斯分布)的边界框回归对特征扰动更为敏感,鲁棒性较差,易受噪声影响,如上图所示。证明了一般分配法比其他分配法具有更大的效益。
三种分布的图解,从刚性(狄拉克)到柔性(一般)分布。建议的一般分布更灵活,因为它的形状可以是任意的。与此相反,狄拉克δ分布的根在不动点上,高斯分布的根相对刚性对称的表达,对真实数据分布的建模有较大的局限性。
改进后的表示对优化提出了挑战。传统上,密集检测器的分类分支采用焦损(FL)来优化。FL可以通过重塑标准交叉熵损失来成功地处理类不平衡问题。但是,对于提出的分类-IoU联合表示,除了仍然存在不平衡的风险外,我们还面临一个新的问题,即连续的IoU标签(0 1)作为监督,因为原有的FL目前只支持离散的{1,0}类别标签。我们通过将FL从{1,0}离散版本扩展到它的连续版本,称为广义焦损(GFL),成功地解决了这个问题。与广义线性算法不同的是,广义线性算法考虑的是一种非常普遍的情况,即全局最优解能够以任意期望的连续值为目标,而不是离散值。更具体地说,本文可以将GFL细分为质量焦损(Quality Focal Loss, QFL)和分布焦损(Distribution Focal Loss, DFL),分别对改进的两种表示进行优化:DFL使网络在任意灵活的分布下快速专注于学习目标包围框连续位置周围值的概率。
本文贡献如下:
展示了GFL的三个优势:(1)当一级检测器易于附加质量估计时,它弥合了训练和测试之间的差距,导致分类和定位质量的更简单、联合和有效的表示;
(2)较好地模拟了锚框的灵活底层分布,提供了更多信息和更准确的框位置;(3)在不引入额外开销的情况下,可以持续提高单级探测器的性能。
二、实现细节
定位质量的表示:Fitness NMS、IoU- net、MS R-CNN、FCOS和IoU-aware都是利用单独的分支以IoU或中心分数的形式执行定位质量评估。正如第1节所提到的,这种单独的表述导致训练和测试之间的不一致,以及不可靠的锚框预测。PISA和IoU-balance并没有引入额外的分支,而是根据它们的定位质量在分类损失中赋予不同的权重,旨在增强分类评分与定位精度的相关性。然而,权重策略不改变分类损失目标的最优值。
锚框回归表示:Dirac delta分布一直影响过去研究的边界框表示。近年来,通过引入预测方差,采用高斯假设来学习不确定性。遗憾的是,现有的表示形式要么过于严格,要么过于简化,无法反映真实数据中复杂的底层分布。在本文中,作者进一步放宽假设,直接学习更任意、更灵活的边界框的一般分布,同时具有更丰富的信息和更准确的结果。
Focal Loss (FL):最初的FL是为了解决在训练过程中前景类和背景类之间经常存在极端不平衡的单阶段目标检测场景。FL的典型形式如下:

其中y{1,0}代表类的标签,p[0,1]表示标签为y = 1的类的估计概率。γ是可调聚焦参数。具体来说,FL由一个标准交叉熵部分 l o g ( p t ) log(p_t) log(pt)和一个动态缩放因子部分 ( 1 − p t ) γ (1-p_t)^ γ (1−pt)γ组成,其中缩放因子 ( 1 − p t ) γ (1-p_t)^ γ (1−pt)γ在训练过程中自动降低易识别类的贡献,并迅速将模型集中在困难的例子上。
Quality Focal Loss (QFL):为了解决上述训练阶段和测试阶段不一致的问题,作者提出了一种定位质量(即IoU评分)和分类评分(简称“classification-IoU)的联合表示,它的监督软化了标准的one-hot标签,并可以将类别标签变的连续 y ∈ [ 0 , 1 ] y\in[0,1] y∈[0,1](见下图中的分类分支)。其中,y = 0表示质量得分为0的负样本, 0 < y < = 1 0

由于提出的classification - iou联合表示需要对整个图像进行密集监督,并且仍然存在类别不平衡的问题,所以必须继承FL的思想。然而,当前形式的FL只支持{1,0}离散标签,但是新标签包含小数。因此,对FL的两个部分进行扩展,以便在联合表示的情况下能够成功训练:
(1)将交叉熵部分对数 l o g ( p t ) log(p_t) log(pt)扩展为如下版本:

(2)将比例因子部分 ( 1 − p t ) γ (1-p_t)^γ (1−pt)γ广义化为估计σ与其连续标记y之间的绝对距离,即 ∣ y − σ ∣ β ( β > = 0 ) |y-σ|^β (β>=0) ∣y−σ∣β(β>=0),这里|·|保证了非负性。随后,结合上述两个扩展部分来制定完整的损失目标,这被称为质量焦点损失(QFL)
![]() 其中,σ = y是QFL的全局最小解,在下图中,显示了QFL在质量标签y = 0.5下不同β值的曲线。
其中,σ = y是QFL的全局最小解,在下图中,显示了QFL在质量标签y = 0.5下不同β值的曲线。

类似于FL,QFL公式的第一项为调制因子,当一个例子的质量估计不准确,偏离标签y时,调制因子就比较大,因此更注重学习这个困难的例子。当质量估计变得准确时,即σ→y,因子趋近于0,对估计良好的例子的损失下降加权,其中参数β平滑地控制下降率。
Distribution Focal Loss (DFL):采用该位置到边界框四周的相对偏移量作为回归目标(见下图的回归分支)。传统的边界框回归模型操作中,回归标签y为delta分布 δ ( x − y ) δ(x − y) δ(x−y),且满足 ∫ − ∞ ∞ δ ( x − y ) d x = 1 \int_{-\infty}^\infty {δ(x − y)} \,{\rm d}x=1 ∫−∞∞δ(x−y)dx=1,通常通过全连接层实现。

根据第1节的分析,作者建议直接学习基本的一般分布P(x),而不是delta或高斯假设,不引入任何其他先验。已知标签y的最小值为 y 0 y_0 y0,最大值为 y n y_n yn且其范围为 y n ( y 0 ≤ y ≤ y n , n ∈ n + ) y_n(y_0\leq y\leq y_n, n\in n^ +) yn(y0≤y≤yn,n∈n+),可以由模型得到y的估计值 y ^ \hat{y} y^( y ^ \hat{y} y^也满足 y n ( y 0 ≤ y ^ ≤ y n , n ∈ n + ) y_n(y_0\leq \hat{y} \leq y_n, n\in n^ +) yn(y0≤y^≤yn,n∈n+)得出:
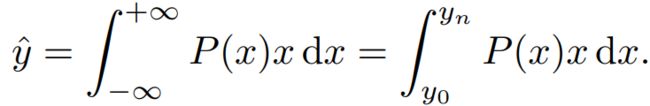
与卷积神经网络一致们将连续域上的积分转换为离散表示,将范围 [ y 0 , y n ] [y_0, y_n] [y0,yn]离散化为集合 { y 0 , y 1 , … , y i , y i + 1 , … , y n − 1 , y n } \{y_0, y_1,…, y_i, y_{i+1},…, y_{n-1}, y_n\} {y0,y1,…,yi,yi+1,…,yn−1,yn},间隔为 Δ \Delta Δ(简单起见,设 Δ = 1 \Delta= 1 Δ=1)。因此,给定离散分布性质 J α ( x ) = ∑ i = 0 n P ( y i ) = 1 J_\alpha(x) = \sum_{i=0}^n P(y_i)=1 Jα(x)=∑i=0nP(yi)=1,回归估定值 y ^ \hat{y} y^可以表示为:

因此,P(x)可以通过由n + 1个单元组成的softmax S(·)轻松实现,简化可得, P ( y i ) P(y_i) P(yi)表示为 S i S_i Si。请注意, y ^ \hat{y} y^可以用传统的损失目标(如SmoothL1、IoU loss或GIoU loss)进行端到端的训练。但是P(x)有无穷多种取值组合,最终的积分结果为y,如图下图所示,这可能会降低学习效率。

直观的看(1)和(2)相比,分布(3)更紧凑,在包围框估计上更有可信和更精确,这促使我们通过明确鼓励接近目标y的值的高概率来优化P(x)的形状。此外,通常情况下,最合适的优先位置如果存在,将不会远离原始标签。因此,引入了分布焦点损失(distributed Focal Loss, DFL),它通过显式地扩大 y i y_i yi和 y i + 1 y_{i+1} yi+1的概率(最接近y的两个数值, ( y i ≤ y ≤ y i + 1 (y_i\leq \ y\leq y_{i+1} (yi≤ y≤yi+1),迫使网络快速聚焦在标签y附近的值上。由于边界框的学习只针对正样本,不存在类不平衡的风险,所以用QFL中的完全交叉熵部分来定义DFL:
![]()
DFL的目标是扩大目标y周围值(即 y i 和 y i + 1 y_i和y_{i+1} yi和yi+1)的概率。DFL的全局最小解,即

可以保证估计回归目标 y ^ \hat{y} y^无限接近对应的标签y,即
![]()
这也保证了它作为损失函数的正确性。
Generalized Focal Loss (GFL):QFL和DFL可以统一为一种通用形式,本文称之为广义焦损(GFL)。假设一个模型估计两个变量 y l , y r ( y l < y r ) y_l,y_r(y_l

最终预测它们的线性组合:
![]()
预测 y ^ \hat{y} y^对应的连续标签y也满足 y l ≤ y ≤ y r y_l≤y≤y_r yl≤y≤yr。以绝对距离 ∣ y − y ^ ∣ β ( β ≥ 0 ) |y-\hat{y}|^β (β\geq0) ∣y−y^∣β(β≥0)为调节因子,GFL的具体公式为:
![]()
GFL性质: G F L ( p y l , p y r ) GFL(p_{yl},p_{yr}) GFL(pyl,pyr)满足如下情况达到全局最小值:
![]()
这也意味着估计量 y ^ \hat{y} y^完全匹配连续标签y,即 y ^ = y l p y l ∗ + y r p y r ∗ = y \hat{y} = ylp^∗_{yl} +y_rp^∗_{yr} = y y^=ylpyl∗+yrpyr∗=y,原来的FL和QFL、DFL都是GFL的特殊情况。请注意,GFL可以应用于任何一级检测器。改进后的检测器与原检测器有两个不同之处。首先,在推断过程中,直接将分类评分(结合质量估计的联合表示)作为NMS评分,如果存在(如FCOS和ATSS中的中心性),则不需要乘以任何单个质量预测。第二,回归分支的最后一层用于预测每个位置的包围框n + 1个输出,而不是1个输出,这带来的额外计算成本可以忽略不计。
用GFL训练密集探测器:=用GFL定义训练损失L:

其中 L Q L_Q LQ为QFL, L D L_D LD为DFL。通常, L B L_B LB表示GIoU损失。 N p o s N_{pos} Npos代表正样本的数量。 λ 0 λ_0 λ0(通常默认为2)和 λ 1 λ_1 λ1(实际上是1/4,在四个方向上的平均)分别是LQ和LD的平衡权重。计算金字塔特征映射上所有位置z的总和。 1 { c z ∗ > 0 } 1_\{c_z^*>0\} 1{cz∗>0}为指示函数,当 c z ∗ > 0 {c_z^*>0} cz∗>0为1否则为0。
三、实验分析:
(一)、QFL与DFL的分析

(二)、整体实验

四、彩蛋:
为什么IOU分支总是比中心度分支好?
原始论文中的消融研究也表明,对于FCOS/ATSS, IoU作为定位质量的衡量指标始终优于中心度量。作者发现中心性的主要问题在于它的定义导致了意想不到的小的ground-truth标签,这使得一组可能的ground-truth边界框极难被召回(如下图)。从图中示的标签分布中,观察到大多数IoU标签大于0.4,而中心标签却趋向于更小(甚至接近于0)。中心标签的小值阻止了一组真实边界框被召回,因为它们在NMS的最终得分可能会很小,因为它们的预测中心分数已经被这些非常小的信号监督了。

下图也反映出了两者之前的区别;

文章写的很好,有兴趣的同学可以读读原文,受益匪浅!