论文分享:「FED BN」使用LOCAL BATCH NORMALIZATION方法解决Non-iid问题

本次分享内容基于ICLR 2021收录的一篇文章:《FED BN: FEDERATED LEARNING ON NON-IID FEATURES VIA LOCAL BATCH NORMALIZATION》,这篇论文主要探讨了使用LOCAL BATCH NORMALIZATION方法解决Non-iid问题。围绕这篇论文的分享将分为4个部分:
1、BATCH NORMALIZATION及其解决Non-iid问题的方法;
2、Non-iid问题及常用的sota解决方法;
3、FED BN及其解决Non-iid问题的方法;
4、围绕论文实验分析FED BN效果与价值。
话题一、BATCH NORMALIZATION及其解决Non-iid问题的方法
1. BATCH NORMALIZATION
BATCH NORMALIZATION是在**明文机器学习中比较常用且效果较好的一种方法,**它可以很好的解决feature scaling的问题,包括层与层之间internal Covariate Shift 的问题。
那么什么是feature shift呢,我们来举个例子

如图任务是识别图片内容是不是玫瑰花,右侧绿色小圈是玫瑰花,红色则不是,蓝色则表分类边界。虽然上下2组图的任务相同,但是肉眼可见其特征分布明显不同。**这种分布状态在训练时就会导致收敛困难,需要更多的步骤来抵消scale不同所带来的影响才能最终收敛。**这种feature scale差异在和权重进行矩阵相乘时,会产生一些偏离较大的差异值,这个差异值在网络中会影响后面的层,并且偏离越大影响越明显。BN的作用则是将输入标准化,缩小 scale 的范围。其结果就是可以提高梯度的收敛程度,并提升训练速度。
那么BN是怎么来的呢?
在早些时期,网络相对扁平的时候有一种方法Whiten(白化):对输入数据做单位方差的正态分布转换,可以加速网络收敛。在深度网络中随着网络深度的不断增加,每层特征值分布会逐渐的向激活函数的输出区间的上下两端(激活函数饱和区间)靠近,如此继续就会导致梯度消失,影响训练收敛。一些工作包括Relu, Resnet和BN等就是尝试解决这个问题。**既然whiten可以加速收敛,那么是否深度网络中对每一层做whiten就可以加速收敛?**由这种设想便产生了BN,其作用就是保证机器学习的iid假设,保证每个隐层节点的激活输入分布固定,降低feature shift对模型训练造成的影响。
那BN怎么做?
训练阶段

1、取batch数据计算均值
2、取batch数据计算方差
3、做normalize
4、通过训练得到scale 和shift参数
这里normalize在后的过程中还涉及了两个参数**:γ及β,一个对应scale,一个对应shift**,是对其进行一个平移操作的参数。为什么需要这两个参数?我们以sigmoid激活函数来进行举例;论文作者在设计时默认将BN添加在激活函数之前,如果在得出normalize 后不添加线性变化,则会导致大部分输入结果停留在线性空间。但线性空间的多层叠加却是无效的,相较之一层线性网络没有任何区别,即削弱了整个网络的表达能力**。故而需要添加γ及β参数进行转换,使其找到线性和非线性之间的平衡点,**如此既能享受到非线性表达的好处,又可以避免它落在两端影响收敛速度。

在预测流程中,则没有batch 的概念,我们需要使用全部的待预测数据求均值,然后求抽样方差,最后使用这两个参数,对其进行转化并在预测中使用。
优点小结:
1、可以极大地提升训练速度及收敛速度,可以使用较大的学习率
2、可以增强学习的效果
3、调参过程会变简单,因为BN的使用对初始值的敏感度降低
缺点小结:
1、训练和预测的结果存在些许的不一致
2、单个batch的计算需要增加计算量
话题二、iid
iid,即独立同分布,假设训练数据和测试数据满足相同分布,是通过训练数据获得的模型能够在测试集上获得较好效果的基本前提保证。但是在部分联邦场景下,数据源不同使得这一假设很难被满足。关于iid的分类参考相关论文可划分为五种情形:
1、Feature distribution skew,即特征分布偏移(以前文玫瑰花识别为例,x 的特征不一致,但label 分布一致);
2、Label distribution skew,即特征分布呈现一致,但每一方的label都是不相同(如不同的人所认得的字的合集不同);
3、Quantity skew,即数据量不同;
4、Same label but different feature,即我们所熟知的垂直场景**,每一方都有一些数据,这些数据共享一个label;**
5、Same feature but different label,特征相同但label不同,即多任务学习。

如上图(图引自于)所示,将数据及常用方法与对应可解决的问题进行划分,FED BN解决的就是特征分布偏移的问题。
解决iid问题的经典联邦算法
1. Fed-AVG
Fed-AVG是联邦学习中的经典算法之一,主要解决两个问题:通信问题和Client数量问题。
通信问题,即相较于SGD方法需要在每一代迭代之后将梯度(gradient)或权重(weight)发至服务端进行聚合,需要增加很多通信量和计算量。Fed-AVG则允许在客户端在本地完成一些step之后再到服务端做聚合,通过增加客户端的计算减少整体的通信,并且Fed-AVG并不需要每一次所有Client都参加,进一步可以降低通信和计算量。该工作从理论上证明了Fed-avg的收敛性。
Fedavg的收敛路径如下图所示:
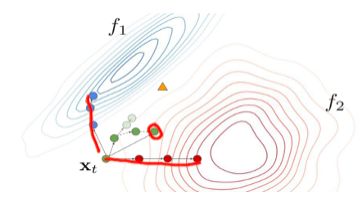

Fed-AVG的流程为:
1、server 把全局模型下发至每个client
2、各个client 使用local数据通过等其他优化方法进行迭代,得到gradient或weight,并加密发送给server
3、Server对收到的gradient和weight进行聚合得到global g/w,发送给各个clients
4、Client收到global g/w 对其本地的模型进行更新
2. FedProx
FedProx是在Fed-AVG基础上进行了一些演化,作者引入了proximal term 这一概念做约束,将学习目标由F(x) 变为了H(x),目的是使得本地更新不要太过远离初始 global model,在容忍系统异构性的前提下减少 Non-IID 的影响。用γ作为本地迭代的 proxy,值越小更新精度越高。

FedProx整体流程基本上和fed-avg是一样的,差异在于loss函数做了修改,增加了约束项。

所以每轮下降的梯度变成了

3. Scaffold
Scaffold也是从fed-avg的基础上演化过来的non-iid策略,通过在随机过程control variates(guess)来克服client drift来进行联邦学习。scaffold想既能看到自己的数据,又能看到server 的数据啊,这样的话自己学习的方向就可以尽量往global这边靠,避免发散不收敛。但是server的数据是看不到的,所以就去猜,为了猜server的梯度方向,作者给了C和Ci的概念,Ci是梯度, C是合相梯度,这里假设合相梯度是server想要优化的方向,拿合相梯度和本次计算出来的梯度求了一个差,就可以得到优化应该去的方向。所以对于这个算法,不仅要更新参数,还要更新猜测项。
算法流程如下:

可以看到和fed-avg的区别在于多了ci和c,每一个client计算的ci是对本方多轮迭代的gradient进行平均得到的,server的C是对各个方面得到的ci进行平均得到。

话题三:FedBN
FedBN这篇工作最大的贡献在于他提出了如何在联邦学习场景下使用batch normalization策略,来解决feature shift问题,同时可以利用BN来加速训练。
•文章通过在局部模型中加入批量归一化层(BN)解决联邦学习数据异构性中feature shift这种情况
•Feature shift:
•y为标签,x为特征,文章将feature shift定义为以下情况:

•例如:医学成像中不同的扫描仪/传感器,自动驾驶中不同的环境分布(公路和城市),使得本地客户端的样本分布不同于其他客户端。
•与FedAvg类似,FedBN也进行局部更新和模型聚合,不同的是,FedBN假设局部模型有批量归一化层(BN),且BN的参数不参与聚合。

收敛性分析:
作者用NTK做了一系列形式化证明,得出的结论是:在feature shift场景下,FedBN的收敛比FedAvg更快更光滑
Experiment:
实验选了5个来自不同域且带有feature shift性质的数据集(不同域的数据具有异构性和相同的标签分布),具体包括SVHN、USPS、 MNIST-M、MNIST、SynthDigits。文章预先对这五个数据集进行预处理,控制无关因素,例如客户之间样本数量不平衡问题,使BN的作用在实验中更加易于观察。

各个数据集之间分布的差异图

模型提供了一个简单的CNN网络,每一层后边都加了一个BN ReLU
实验一

从上面5个数据集和模型setting 可以看出,不管从收敛质量还是从收敛速度来说,都是要比FedBN以及FedAVG要好。

上图是3个实验:
a图表明了不同的local update step 对收敛性的影响。横轴是Epochs 其实是local update step 的概念。纵轴是test accuracy。
1、可以看出local update step和testing_acc负相关
2、fedBn全程比fed-avg表现优异
3、尤其是我们看下最终收敛后的结果,fedbn表现的更加稳定
图b是表示不同的本地数据集大小对于收敛的影响,横轴 percentage,即本地拿出百分之多少的数据进行训练,纵轴是testing accuracy。我们可以看出,测试的准确度在local client只贡献20%数据时候明显下降,但是对应于singleset的提升是反向的,数据量越少对于性能的提升越大,所以表明fedbn适合在单方非持有大量数据的联合训练中使用。
图c是表明不同异构性对于收敛的影响,作者这里试图回答一个问题异构性在什么程度时FedBN会比FedAVG位置好。这里的实验把每1方的数据都切分成了10份,一共有5个数据,总共50份数据,所以横坐标总数为50。
1、开始时每个dataset选一个数据集来参与训练
2、然后逐渐的增加clients,要保持n倍clients数量
3、More clients -> less heterogeneity
假设数据集更多,客户端更多,他的异构性就会更低。得出结论是,在任何设置下,FedBN都比FedAVG效果要更好一点。
接下来是和SOTA的比较,对比的方法为Fed Prox,Fed Avg,还有Single set(把数据都拉到一方去进行训练,仍有non-iid特性)。因为FedBN的模型里边加了BN,所以结果相较Singleset要更好一点,因为BN把一些“data shift”做了处理,降低了non-iid数据的影响。FedBN和其他的相比的话,指标都要好一些,尤其是在svhn 这个数据上,提升的幅度是最明显,将近有10%。这个数据的特点就是特征很高,差异很大。所以这个方法对特征差异大的数据是比较有效的。同时FedBN在多次跑的时候,error的方差最小,训练出的模型稳定性更好。
最后我们FedBN看一下在真实数据集下的表现:这里文章选择了自然图像数据集Office-Caltech10,它有4个数据源Office-31(3个数据源)、Caltech256,每个clients分配了4个数据源中的一个,所以数据在clients之间是Non-iid的。
第二个数据源是DomainNet,包含了从6个数据来源的自然图像数据集分别是:(Clipart,Infograph,Painting,Quickdraw,Real,Sketch),划分方法和上面的Cal10是一样的。
第三个数据集从ABIDE I数据集选取,包含了4个医学数据集**(NYU,USM,UM,UCLA)**每一方被看做一个client。

结果和分析:
从结果可以看出,FedBN在各方面全面超越了当前的 SOTA工作。而且,我们可以看到FedBN除了QuickDraw数据集外,都获得了相对优势的结果,甚至优于SingleSet的结果,BN在解决feature shift提升模型效果上有其显著的优势。
上述的结果也给我们在医学健康领域使用FedBN提供了信心,因为医疗场景下的数据的特征往往是有限数量,离散分布,而且是有feature shift的。
总结:
这篇工作提出了FedBN,给出了在联邦场景下使用BN来缓解feature shift的方法,并证明了其收敛性和有效性。FedBN的方法和通信、优化器方法是正交的,在实际使用中可以组合使用。FedBN在算法是对FedAvg只做了很小的改动,在实际中还可以与其他联邦strategy进行结合使用(Pysyft、TFF等已集成)。FedBN已经在医学健康,自动驾驶等领域被证明是很有效的策略,这些场景的数据的特点是,不同方的本地数据由于存在feature shift导致的non-iid。关于数据安全性,BN层的数据对于整个交互和聚合是不可见的(Invasible),所以一定程度上增加了对本地数据攻击的困难。