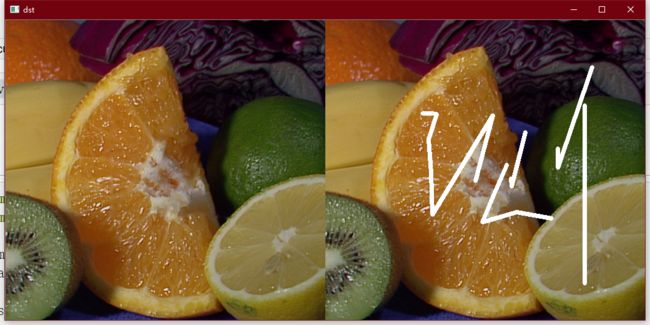十二.图像的分割与修复
图像的分割与修复
1. 图像分割的基本概念
图像分割: 将前景物体从背景中分离出来.
图像分割分为传统图像分割和基于深度学习的图像分割方法.
传统图像分割就是使用OpenCV进行的图像分割.
传统图像分割方法有:
- 分水岭法
- GrabCut法
- MeanShift法
- 背景扣除
2. 分水岭法
分水岭分割方法是基于图像形态学和图像结构来实现的一种图像分割方法.
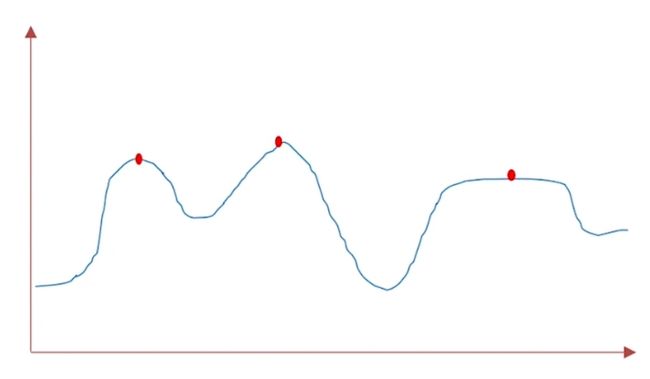
现实中我们可以或者说可以想象有山有湖的景象,那么那一定是水绕山,山围水的情形。当然在需要的时候,要人工构筑分水岭,以防集水盆之间的互相穿透。而区分高山(plateaus)与水的界线,以及湖与湖之间的间隔或 都是连通的关系,就是分水岭(watershed)。
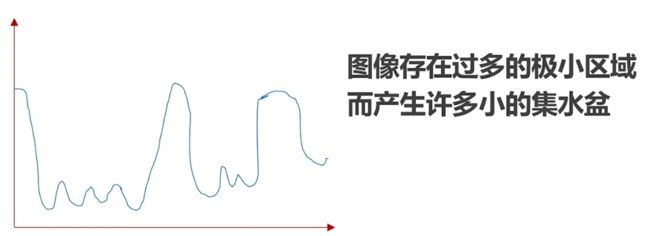
我们绘制灰度图像的梯度图, 可以得到近似下图的梯度走势.梯度低的地方我们可以认为是低洼区或者山谷, 梯度高的地方可以认为是山峰. 我们往山谷中注水, 为了防止山谷中的水溢出汇合我们可以在汇合的地方筑起堤坝, 可将堤坝看做是对图像分割后形成的边界. 这就是分水岭算法的基本原理.
分水岭法的问题
OpenCV中的分水岭法已经解决此问题.
分水岭法涉及的API
- distanceTransform(img, distanceType, maskSize)计算img中非零值到距离它最近的0值之间的距离
- img 要处理的图像
- distanceType 计算距离的方式: DIST_L1, DIST_L2
- maskSize:进行扫描时的kernel的大小, L1用3, L2用5
- connectedComponents(image[, labels[, connectivity[, ltype]]]) 求连通域, 用0标记图像的背景,用大于0的整数标记其他对象
- connectivity: 4, 8(默认)
- watershed(image, markers) 执行分水岭法
- markers: 它是一个与原始图像大小相同的矩阵,int32数据类型,表示哪些是背景哪些是前景。分水岭算法将标记的0的区域视为不确定区域,将标记为1的区域视为背景区域,将标记大于1的正整数表示我们想得到的前景。
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('water_coins.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh =cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 有一些细小的噪点和毛边
cv2.imshow('thresh', thresh)
# 通过开运算去掉噪点
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3,3))
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
cv2.imshow('opening', opening)
bg = cv2.dilate(opening, kernel, iterations=2) # sure background area
fg = cv2.erode(opening, kernel, iterations=2) # sure foreground area
# 剩下的区域(硬币的边界附近)还不能确定是前景还是背景。可通过膨胀图减去腐蚀图得到,下图中的白色部分为不确定区域
unknown = cv2.subtract(bg, fg) # 未知区域
cv2.imshow('gg', np.hstack((bg, fg, unknown)))
# 由于硬币之间彼此接触,我们使用另一个确定前景的方法,就是带阈值的距离变换。
# Perform the distance transform algorithm
dist_transform = cv2.distanceTransform(opening, cv2.DIST_L2, 5)
# Normalize the distance image for range = {0.0, 1.0}
cv2.normalize(dist_transform, dist_transform, 0, 1.0, cv2.NORM_MINMAX)
# Finding sure foreground area
ret, sure_fg = cv2.threshold(dist_transform, 0.5*dist_transform.max(), 255, cv2.THRESH_BINARY)
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(bg,sure_fg)
cv2.imshow('gg2', np.hstack((bg, sure_fg, unknown)))
cv2.imshow('dist_transform', dist_transform)
# 现在我们可以确定哪些是硬币区域,哪些是背景区域。然后创建标记(marker,它是一个与原始图像大小相同的矩阵,int32数据类型),表示其中的每个区域。分水岭算法将标记的0的区域视为不确定区域,将标记为1的区域视为背景区域,将标记大于1的正整数表示我们想得到的前景。
# 我们可以使用 cv2.connectedComponents() 来实现这个功能,它是用0标记图像的背景,用大于0的整数标记其他对象。所以我们需要对其进行加一,用1来标记图像的背景。
ret, markers = cv2.connectedComponents(sure_fg)
# print(markers)
# Add one to all labels so that sure background is not 0, but 1
markers = markers+1
# Now, mark the region of unknown with zero
# 这样处理后, 未知区域就是0, 背景就是1, 前景就是其他正整数
markers[unknown==255] = 0
# print(markers)
# 对得到的markers进行显示
markers_copy = markers.copy()
markers_copy[markers==0] = 150 # 灰色表示背景
markers_copy[markers==1] = 0 # 黑色表示背景
markers_copy[markers>1] = 255 # 白色表示前景
markers_copy = np.uint8(markers_copy)
cv2.imshow('markers_copy', markers_copy)
# 标记图像已经完成了,最后应用分水岭算法。然后标记图像将被修改,边界区域将被标记为-1
# 使用分水岭算法执行基于标记的图像分割,将图像中的对象与背景分离
markers = cv2.watershed(img, markers)
img[markers==-1] = [0,0,255] # 将边界标记为红色
# -1 表示边界, 1表示背景, > 1 表示前景
img[markers > 1] = [0, 255, 0]
print(markers)
print(markers.min(), markers.max())
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()





3. GrabCut
通过交互的方式获得前景物体.
- 用户指定前景的大体区域, 剩下的为背景区域.
- 用户可以明确指定某些地方为前景或背景.
- GrabCut采用分段迭代的方法分析前景物体, 形成模型树.
- 最后根据权重决定某个像素是前景还是背景.
这里不去介绍GrabCut算法的具体数学原理, 感兴趣的同学可以阅读GrabCut原论文:
GrabCut” — Interactive Foreground Extraction using Iterated Graph Cuts
GrabCut算法主要基于以下知识:
- k均值聚类
- 高斯混合模型建模(GMM)
- max flow/min cut
这里介绍一些GrabCut算法的实现步骤:
- 在图片中定义(一个或者多个)包含物体的矩形。
- 矩形外的区域被自动认为是背景。
- 对于用户定义的矩形区域,可用背景中的数据来区分它里面的前景和背景区域。
- 用高斯混合模型(GMM)来对背景和前景建模,并将未定义的像素标记为可能的前景或者背景。
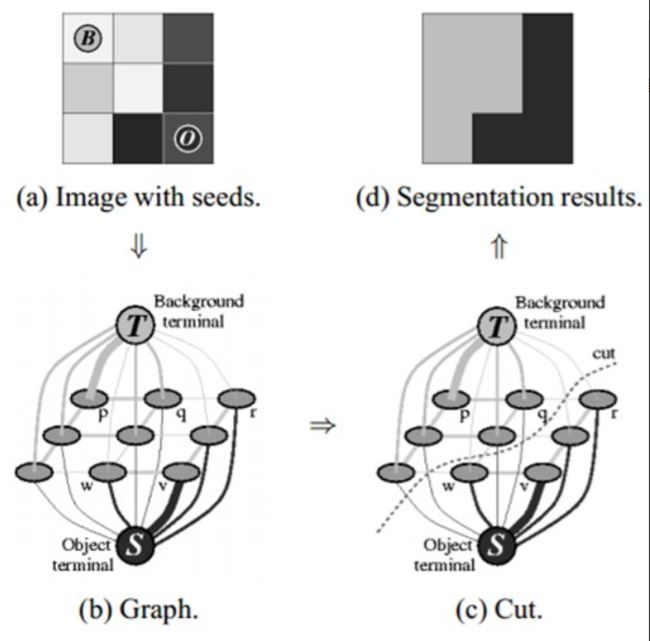
- 图像中的每一个像素都被看做通过虚拟边与周围像素相连接,而每条边都有一个属于前景或者背景的概率,这是基于它与周边像素颜色上的相似性。
- 每一个像素(即算法中的节点)会与一个前景或背景节点连接。
- 在节点完成连接后(可能与背景或前景连接),若节点之间的边属于不同终端(即一个节点属于前景,另一个节点属于背景),则会切断他们之间的边,这就能将图像各部分分割出来。下图能很好的说明该算法:
-
grabCut(img, mask, rect, bgdModel, fgdModel, iterCount[, mode]) -> mask, bgdModel, fgdModel
-
img——待分割的源图像,必须是8位3通道,在处理的过程中不会被修改
-
mask——掩码图像,如果使用掩码进行初始化,那么mask保存初始化掩码信息;在执行分割的时候,也可以将用户交互所设定的前景与背景保存到mask中,然后再传入grabCut函数;在处理结束之后,mask中会保存结果。mask只能取以下四种值:
GCD_BGD(=0),背景;
GCD_FGD(=1),前景;
GCD_PR_BGD(=2),可能的背景;
GCD_PR_FGD(=3),可能的前景。
-
如果没有手工标记GCD_BGD或者GCD_FGD,那么结果只会有GCD_PR_BGD或GCD_PR_FGD;
-
rect——用于限定需要进行分割的图像范围,只有该矩形窗口内的图像部分才被处理;
-
bgdModel——背景模型,如果为None,函数内部会自动创建一个bgdModel;bgdModel必须是单通道浮点型图像,且行数只能为1,列数只能为13x5;
-
fgdModel——前景模型,如果为None,函数内部会自动创建一个fgdModel;fgdModel必须是单通道浮点型图像,且行数只能为1,列数只能为13x5;
-
iterCount——迭代次数,必须大于0;
-
mode——用于指示grabCut函数进行什么操作,可选的值有:
GC_INIT_WITH_RECT(=0),用矩形窗初始化GrabCut;
GC_INIT_WITH_MASK(=1),用掩码图像初始化GrabCut;
GC_EVAL(=2),执行分割。
4. MeanShift图像分割
MeanShift严格来说并不是用来对图像进行分割的, 而是在色彩层面进行平滑滤波的.它会中和色彩分布相近的颜色, 平滑色彩细节, 侵蚀掉面积较小的颜色区域.
它以图像上任一点p为圆心, 半径为sp, 色彩幅值为sr进行不断迭代.经过迭代,将收敛点的像素值代替原来的像素值,从而去除了局部相似的纹理,同时保留了边缘等差异较大的特征。
import cv2
import numpy as np
img = cv2.imread('key.png')
mean_img = cv2.pyrMeanShiftFiltering(img, 20, 30)
imgcanny = cv2.Canny(mean_img, 150, 300)
contours, _ = cv2.findContours(imgcanny, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cv2.drawContours(img, contours, -1, (0, 0, 255), 2)
cv2.imshow('img', img)
cv2.imshow('mean_img', mean_img)
cv2.imshow('canny', imgcanny)
cv2.waitKey(0)
cv2.destroyAllWindows()
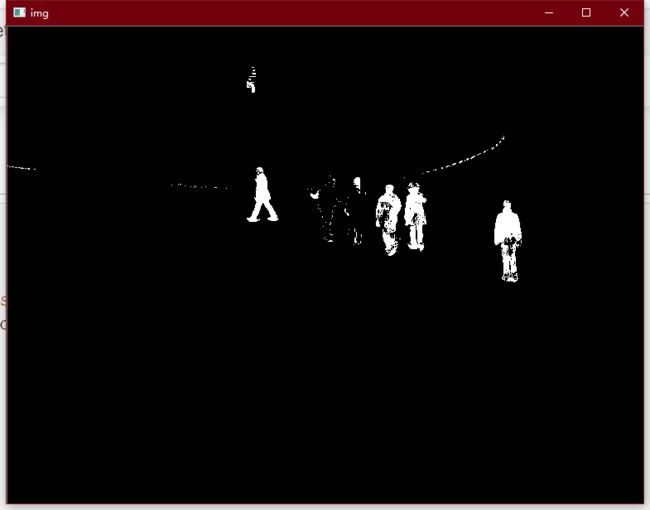
5. 视频前后景分离
- 视频是一组连续的帧(一幅幅图片组成)
- 帧与帧之间关系密切(GOP: group of pictures)
- 在GOP中, 背景几乎是不变的.
- 混合高斯模型为基础的前景/背景分割算法
- createBackgroundSubtractorMOG([, history[, nmixtures[, backgroundRatio[, noiseSigma]]]])
- history: 进行建模的时候需要多长时间的参考帧, 默认是200ms
- nmixtures: 高斯范围值, 默认为5.
- backgroundRatio: 背景比例, 默认0.7
- noiseSigma:降噪, 默认为0, 表示自动降噪.
- 以上参数一般不需要修改, 默认即可.
import cv2
import numpy as np
cap = cv2.VideoCapture('./vtest.avi')
mog = cv2.bgsegm.createBackgroundSubtractorMOG()
while(True):
ret, frame = cap.read()
if not ret:
break
fgmask = mog.apply(frame)
cv2.imshow('img',fgmask)
k = cv2.waitKey(10)
if k ==27:
break
cap.release()
cv2.destroyAllWindows()
6. 其他对视频前后景分离的方法
-
MOG2: 同MOG类似, 不过对亮度产生的阴影有更好的识别, 缺点是会产生很多细小的噪点.
-
createBackgroundSubtractorMOG2
- history: 默认500毫秒
- …
- detectShadows: 是否 检测阴影, 默认True
-
GMG去背景: 静态背景图像估计和每个像素的贝叶斯分割, 抗噪性更强.
-
createBackgroundSubtractorGMG
- initializationFrames: 初始化帧数, 默认120帧.
import cv2
import numpy as np
cap = cv2.VideoCapture('./vtest.avi')
mog = cv2.bgsegm.createBackgroundSubtractorGMG()
while(True):
ret, frame = cap.read()
if not ret:
break
fgmask = mog.apply(frame)
cv2.imshow('img',fgmask)
k = cv2.waitKey(10)
if k ==27:
break
cap.release()
cv2.destroyAllWindows()
7. 图像修复
-
OpenCV中图像修复的技术——基本思想很简单:用相邻像素替换这些坏标记,使其看起来像邻居。
-
inpaint(src, inpaintMask, inpaintRadius, flags[, dst])
-
src要修复的图片
-
inpaintMask: 图像的掩码,单通道图像,大小跟原图像一致,inpaintMask图像上除了需要修复的部分之外其他部分的像素值全部为0
-
inpaintRadius: 每个点的圆心邻域半径.
-
flags: 修复的使用的算法. INPAINT_NS, INPAINT_TELEA
- cv2.INPAINT_NS(Fluid Dynamics Method 流体力学算法)
- cv2.INPAINT_TELEA(Fast Marching Method 快速行进算法)
-
import cv2
import numpy as np
img = cv2.imread('inpaint.png')
mask = cv2.imread('inpaint_mask.png', 0)
dst = cv2.inpaint(img, mask, 5, cv2.INPAINT_TELEA)
cv2.imshow('dst', np.hstack((dst, img)))
cv2.waitKey(0)
cv2.destroyAllWindows()