爬虫攻守道 - 2023最新 - Python Selenium 实现 - 数据去伪存真,正则表达式谁与争锋 - 爬取某天气网站历史数据
前言
前面写过3篇文章,分别介绍了反爬措施,JS逆向+ajax获取数据,以及正则表达式匹配开头、结尾、中间的用法。第3篇算是本文 Python Selenium 爬虫实现方案的子集,大家可以参照阅读。
另外本意是“攻守”,不知道为何输入法给的都是“功守道”,前面没有注意全都写错了。已经纠正重新发布。
- 网站的反爬措施分析
- JS逆向,ajax获取数据
- 正则表达式 - 匹配开头、结尾、中间
在这个爬虫案例中,我遇到的最难部分甚至都不是破解各种反爬措施和梳理网站逻辑,而是正则表达式的书写、测试和验证,在后者上耗费的心力远超前者。
js 逆向方案,只需要从 js 代码中匹配参数名、函数名,正则使用范围还相对有限。
而在本文提到的 Selenium 方案中,因为需要从页面的静态源代码中提取数据,而其中又夹杂了很多网站为反爬做的通过不同 css 样式包裹的假数据 —— 真中有假,假中有真。这样就需要做很多替换处理,而替换的前提正是匹配 —— 如何正确匹配,并且高效匹配 —— 是这个方案能够成功的关键。
正文
龙套登场
因为数据是经过渲染后才展示,直观感知就是页面打开后不是第一时间就能看到数据,以及通过浏览器查看的源代码中找不到数据。
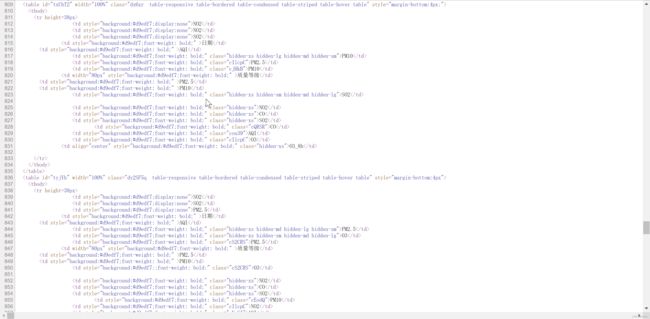
无论标准的 request 还是 Scrapy 提供的 request,能够拿到的都只是这个找不到数据的网页源代码,像下面这样,只有包含样式的3个 Table,没有数据。巧妇难为无米之炊,没有米(数据),何来炊(提取)。
而Selenium 的不同(牛逼)之处是,他提供了1个属性 page_source,这个page_source 就能够拿到渲染后的页面源代码。我们可以把他保存到本地。如下图。可以看到每个Table 都已经填充了数据。
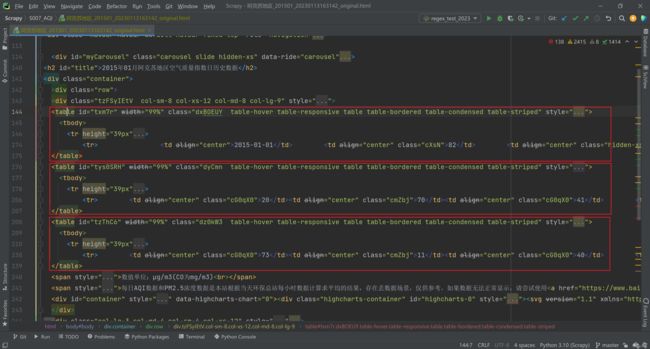
在 网站的反爬措施分析 这篇文章中,我们已经讲过网站针对 Selenium 做的反爬措施,在代码中都需要相应地解决掉。完整代码如下。
apath = r'F:\Python\Scrapy\S007_AQI\S007_AQI\.wdm\drivers\chromedriver\win32\108.0.5359\chromedriver.exe'
url = request.url
if 'daydata' in url:
city = request.meta['city']
month = request.meta['month']
options = webdriver.ChromeOptions()
options.add_argument(r'ignore-certificate-errors')
options.add_argument(r"--headless")
options.add_argument(
r'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36')
options.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
driver = webdriver.Chrome(service=Service(apath), options=options)
# Selenium 模式也会被网站监测,所以需要在网站的监测代码执行前,先执行下面的代码调整navigator属性
# 使用 headless 无头模式的话,还需要配置 plugins
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
Object.defineProperty(navigator, 'plugins', {
get: () => [1, 2, 3, 4, 5],
})
"""
})
driver.get(url)
# 返回Selenium 浏览器的参数
# print("当前浏览器内置user-agent:", driver.execute_script('return navigator.userAgent'))
# print("当前浏览器内置user-agent-plugins:", driver.execute_script('return navigator.plugins.length'))
# print("当前浏览器内置user-agent-languages:", driver.execute_script('return navigator.languages'))
time.sleep(3)
# page_source 是渲染后的页面源代码,类型为字符串,包含了想要的数据
page_source = driver.page_source
driver.close()
# 为了便于对照,根据拿到 page_source 的时间,先保留1份原始文本,
response_time = time.strftime("%Y%m%d%H%M%S")
with open("{}_{}_{}_original.html".format(city, month, response_time), 'w', encoding='utf-8') as f:
f.write(page_source)主角上阵
现在渲染前、后的网页源代码我们都已拿到,让我们告别龙套 Selenium,该是主角 正则表达式 大显身手的时候了。
前言中提到匹配是关键,其实匹配也有前提,就是要找到规律。好在这个案例中假数据规律都比较明显,我们一个个来看。
真table vs 假table
严格来讲,没有全部是假数据的 假table,也没有全部是真数据的 真table。对,他就是这么神奇和牛逼。在所谓的“假Table” 中,也能找到和“真Table”一致的数据 —— 你可以打开浏览器访问页面,然后和源代码逐行逐列逐单元格进行数据比对,虽然很费功夫,但这确实是事实,你需要接受。
另1个非常明显的佐证是实现页面渲染的 js 代码,在这个名为 showTable 的函数中,入参 items是ajax 接口返回的 json 格式数据,通过 items.foreach 遍历,对3个 Table(3个不同 id)渲染。在每个Table的 td 标签中,都有包含了 假的Math.random() 和 真的item.天气字段 数据。而且出现的位置随机,字段随机。
假数据肯定是不会在页面展示的,他只是反爬措施的一部分。换句话说,用来迷惑或者拦截掉那些水平一般的爬虫。我们当然可以找到控制展示的逻辑,然后逐个 td 匹配进而替换,但毫无疑问这样效率极低,没有必要直接在最小范围操作。即便这样做了,那些所谓“假Table”中剩下的真数据,怎么处理?—— 最终还是要回到 Table 范畴。
既然是这样,我们就直接在 Table 层面来找不同 —— 找到“真Table”,剔除“假Table”。
首先你会发现id 不同,但这个 id 是每次请求后都会变化的随机字符串,不能作为比较的凭证。
其次是class引用样式的名称不同,但他和 id 一样,也是随机变化的,即便他们对应的内容都是 display:none
所以接下来,我们就找到内容固定的 style 部分,能看出来2个 Table 包含了对 position 属性的设置,而另1个没有。没有设置的这颗独苗,你可以在再和页面做一遍数据比对,虽然多了些页面没展示的,但是页面展示的数据都在这里。对的,这就是我们的目标。
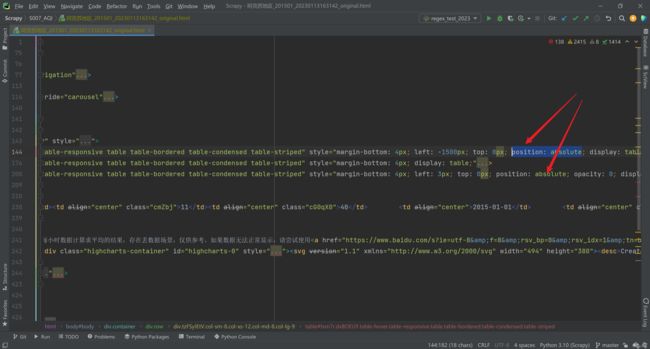
让我们请出这个前不见古人后不见来者的正则表达式。这里有2行额外的代码,用来将源代码中的 eval 部分(会转换为js 代码,可以看我的 js 逆向文章)替换为空,因为这部分内容太长了,长到令人发指,会严重影响后续匹配的效率和时间。
# 可以先移除Script 中的eval,否则太长了,移除后 size 会减少很多
# 正则匹配也是运算,应该尽可能减小匹配范围
regex_script = r"eval\(.*"
page_source = re.sub(regex_script, '', page_source)
# 调试需要,用于统计程序运行时间
s1_time_start = time.time()
# 样式中没有设置 position 的Table,就是包含真实数据的,保留。将另外2个 替换为空
# 一步到位的正则表达式
re_one_step = r"(?=)[\s\S])*?position[\s\S]*?(?<=<\/table>)"
page_source, count = re.subn(re_one_step, '', page_source)
print('{}_{}: {} fake tables have been removed within {}s'.format(city, month, count,time.time() - s1_time_start)))
# 调试需要,我们再保存1份剩下了 “真Table”的网页源代码
with open("{}_{}_{}_removefaketable.html".format(city, month, response_time), 'w', encoding='utf-8') as f:
f.write(page_source) 另外使用了 re.subn 函数而不是常见的 re.sub,re.subn 会返回1个元组,其中第1个元素是替换后的字符串,第2个元素是替换次数。便于我们观察调试信息。即使这里毫无疑问地只有2个Table会被替换。
真td vs 假td
现在我们拿到了包含真实数据的Table。重申:他只是包含,并不是全部,这很重要。我们来看 2015-01-01 的数据,页面上在这行展示了9个数据,而Table 的 tr 中提供了19个 td,也就是19个数据。
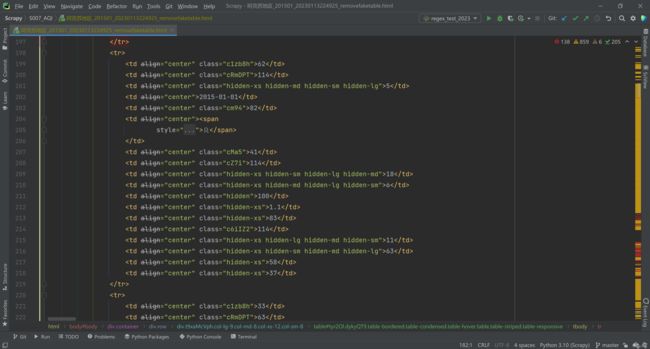
19个数据,我们没有办法通过数字本身去识别真伪,对于爬虫来讲他们毫无意义。只有那些人类可读的 hidden 样式,以及那些很明显是随机字符串的样式名称,在默默诉说着什么。以页面上没有展示数字20和70为例,当你按下 Ctrl 同时点击那些随机字符串,会发现他们对应的真实样式,全部是 display:none。好了,电影《寒战》经典台词:“rule number 1” —— 用来剔除伪数据的第1条样式出炉。
但从19个甚至更多数据得到9个有效数据,rule number 1 还远远不够。我们还找到了剩下的3个 rule:
- rule number 2: 直接就是 display:none
- rule number 3: hidden-lg —— 这个很特别 lg 是大型设备上隐藏,参考阅读:Bootstrap 响应式实用工具
- rule number 4: 直接就是 hidden
- rule number 5: 没有了,hidden-xs 不是,hidden-sm 和 hidden-md 也不是 —— 就是这么牛逼,hidden 也区分不同的适用对象
正则表达式,请继续你的表演。
第1步,得到全部td。对于1份正常——纯真没有无邪的数据来说,td 数量应该是9的倍数 —— 因为页面上就展示9个字段,再结合天数,假设每天都有数据,那 td 不外乎288(31天 + 1表头),279(30天 + 1表头),161(28天 + 1表头)——即便不是每天都有数据,td 数量等于9的倍数这个铁律是没跑的。但实际在不同请求当中,因为随机伪数据的存在,得到的td 数量都是随机的。我们也把他打印出来。
第2步,在全部td 中,对前面得到的4种样式排名不分先后进行逐个匹配,匹配到就意味着属于将要被隐藏的数据,直接将这个td 替换为空。需要注意的是,对于名称是随机字符串的样式 —— rule number 1 来说,是先在源代码全文中匹配用{} 包含的display:none,然后提取出 { 前面的这个字符串,平均数量10个左右,你会得到1个列表,再然后在 td 中匹配这些字符串并替换 —— 这和 rule number 2 直接将 display:none 明文写在td样式中的处理逻辑不同。
第3步,可选,为了和第1步的结论呼应,我们再匹配1次td,得到td 的数量,以确认我们的处理逻辑是正确的。
# 在保留的 table 中匹配出所有的 td
regex_td = r""
tds = re.findall(regex_td, page_source)
print('{}_{}: total {} tds been found'.format(city, month, len(tds)))
# 对假数据的隐藏,网站使用了4种不同的css样式来控制,目前就找到4种。将包含这4种样式的 td 全部替换为空
# 第1种 直接就是display:none
# 第2种 使用了样式别名,名称是随机字符串,但内容固定是 display:none,需要通过内容反向拿到样式别名
# 第3种 hidden-lg - 这个很特别 lg 是大型设备上隐藏
# 第4种 hidden
regex_td_css1 = r"display:none"
for td in tds:
if re.findall(regex_td_css1, td):
page_source = page_source.replace(td, '')
# 将包含 display:none 隐藏样式的 td 其实就是假数据,替换为空
# display:none 是最终效果,实际在代码里是随机字符串,而且好几个,所以先找到 css 定义中内容为 display:none 的样式名称
regex_td_css2 = r"(.*?)\s*{\n\s*display: none;"
class_ndisplays = re.findall(regex_td_css2, page_source)
# print('class_ndisplays', len(class_ndisplays))
# 将包含这些样式的 td 替换为空
for class_ndisplay in class_ndisplays:
class_ndisplay = class_ndisplay.replace('.', '').strip()
for td in tds:
if re.findall(class_ndisplay, td):
page_source = page_source.replace(td, '')
# 将包含 hidden-lg 隐藏样式的 td 其实就是假数据,替换为空
regex_td_css3 = "hidden-lg"
for td in tds:
if re.findall(regex_td_css3, td):
page_source = page_source.replace(td, '')
# 将包含 hidden 隐藏样式的 td 其实就是假数据,替换为空
regex_td_css4 = r"\"hidden\""
for td in tds:
if re.findall(regex_td_css4, td):
page_source = page_source.replace(td, '')
# 可选,再次匹配,现在得到的是包含真实数据的 td
# 经过前面的处理,得到的有效td 数量应该固定为 (天数 + 表头)* 9列
# (31 + 1)*9 = 288 或者 (30+1)*9 = 279
regex_td = r""
tds_real = re.findall(regex_td, page_source)
print('{}_{}: {} tds which contain real data been left'.format(city, month, len(tds_real)))
终于!!!彻底!!!我们拿到了只剩真实数字(注意是数字!卖个关子,你还会继续发现惊喜和意外。哈哈哈哈哈)的网页源代码!!!每一个 tr 都只有9条 td,可以再来和页面做个比对,数字完全一致。9真是这个案例的吉祥数字。细心的同学会发现两边数字的次序不同,对,因为图左是浏览器请求,图右是Python 代码请求。没错,每次请求拿到的数据顺序也是变化的。
到这里,我们把这个经过 Scrapy middleware 处理的网页源代码封装后发给 Scrapy Spider,在Spider 中做最后的数据提取。这里的提取我们用了 xpath
第1步,从页面中找出全部 tr,数量最多32个。
第2步,需要先从第1个 tr (也就是表头)中提取天气指标字段保存成列表,因为顺序不固定,所以每次都要提取,好让剩下的 tr 中的数字逐个对应到指标,这样最终的数据才有意义。因为只有1个 tr 需要这样处理,所以放在了 else 逻辑中,而用if 来处理绝大多数的 tr。
第3步,也就是 if 逻辑中,逐个提取数据,用指标列表作为key,提取到的数字作为 value,保存进字典 item.
其他一些额外的逻辑就是对表头的字符串处理,为了让不同的爬虫能套用同1套item 定义
def parse_month(self, response):
# 这里拿到的 response,应该是已经剔除掉全部伪数据的(包括表头伪数据)
# print(response.meta)
city = response.meta['city']
month = response.meta['month']
item = S007AqiItem()
# xpath 得到 tr,每个页面上 tr 最多32个 (31天 + 1表头)
trows = response.xpath('//tr')
print('{}_{}: {} rows been found'.format(city, month, len(trows)))
# 定义1个列表,用于储存表头字段
theaders_original = []
theaders_purified = []
# 循环,提取每个 tr 下的 td 中的数据
for trow, trow_count in zip(trows, list(range(0, len(trows)))):
# 每个 tr 里面包含 9个 td
tdatas = trow.xpath('./td')
# 提取剩余的31行
if trow_count != 0:
tdata_count = 0
for tdata in tdatas:
data = tdata.xpath('./text()').extract_first()
item['{}'.format(theaders_purified[tdata_count])] = data
tdata_count = tdata_count + 1
item['city'] = city
item['month'] = month
print(item)
# 第1个 tr 里面是表头,单独提取
else:
for tdata in tdatas:
field_name = tdata.xpath('./text()').extract_first()
theaders_original.append(field_name)
# 表头名称转换,变成英文小写,这样可以和使用ajax 方式的爬虫共用1个 item
if field_name == "日期": field_name = 'day'
elif field_name == "质量等级": field_name = 'quality'
elif field_name == "O3_8h": field_name = 'o3'
elif field_name == "PM2.5":field_name = 'pm2_5'
else: field_name = field_name.lower()
# 空列表不能直接使用数字索引赋值
theaders_purified.append(field_name)
print('{}_{}: original table headers : {}'.format(city, month, theaders_original))
print('{}_{}: purified table headers : {}'.format(city, month, theaders_purified))
真th vs 假th
前面红色字体处卖了个关子,拿到真实数字并不意味着万事大吉。为什么强调数字?—— 因为还有例外,就是表头。对,大部分情况下,表头也是写在 td 里的,这样只需要1套处理 td 的逻辑。但是哈但是,哈哈哈哈哈哈,你还会遇到表头写在 th 中的情况 —— 我没找着规律,似乎是在连续快速请求的情况下会出现。
为了让我们的爬虫更健壮,我们把这种情况也纳入考量。找到 th 是第1步,之后可以考虑在 th 中匹配 css rule 1-4,把假 th 剔除,但想想就闹心,难不成又来4次 for 循环? 所以换个思路,我们把所有的 th 替换为 td,放在td 处理逻辑前面,这样后续只处理 td 就好了。哈哈哈哈哈,你有张良计我有过墙梯。
# 表头也是包含了伪造数据的,也需要剔除 表头通过2种形式提供,
# 一种是放在 td 里的,可以和数据一起处理
# 另一种是放在 th 里,所以还需要增加 th 的匹配判断
# 保留下来的 Table 中, td 是一定有的,th 不一定有
# 最简单的方式就是把 th 替换为 td,这样就不用在 th 里依次判断4种隐藏样式
regex_th = r""
# 无论最终是否执行替换,正则匹配都会执行。所以把 re.findall 换成 re.subn
# 正则匹配后得到match,如果其中有闭合的(),就会生成 group,也就是分组
# 正则将之间的内容匹配出来,得到分组,用\1表示
# 将匹配到的分组内容保留,两端替换为td的开合标签
page_source, count = re.subn(regex_th, r"", page_source)
if count > 0:
print('{}_{}: field names are inside of 另类的 span
做完了前面的全部,你会发现结果里少了点什么,对,表头拿到了,数字拿到了,但是质量等级这个指标没有被提取出来 —— 为什么?回去看网页源代码,会发现质量等级是在 td 标签内部又嵌套了一层的 span 标签里。那好办,我们for 循环所有td,在td 里先找着 span 标签,然后提取其中的文本,用文本把这整个span 替换,这样把质量等级字段也处理成和其他字段一致的形式。
# 质量等级 是在 td 内部又包了1层 span 标签,为了和其他数据统一逻辑,我们把span 内的文本提取出来
# 然后用这个文本 把整个 span 标签替换掉
regex_span = r"" # 结果要包含开头的
regex_span_text = r"(?<=>).+(?=<)" # 结果不要包含开头的 < 和 结尾的 >, 只取<> 之间的内容
for td in tds:
span_tag = re.findall(regex_span, td)
if span_tag:
span_text = re.findall(regex_span_text, span_tag[0])[0]
page_source = page_source.replace(span_tag[0], span_text)
############################华丽丽的分割线##########################################
# 上面这个是最开始的写法,看上去就非常臃肿
# 下面这个是改良写法,看上去就非常牛逼
# 效果是把 质量等级 质量等级
# \3 是因为质量等级在正则匹配结果的第3个分组
regex_span = r"(?=)[\s\S])*((.*?)<\/span>)<\/td>"
page_source, count = re.subn(regex_span , r'\3 ', page_source)
到这里,目前所有的意外都被我们处理掉了,数据 —— 所有的美好如期而至。无图无真相,来看个视频吧。视频被压缩得太厉害了,将就看吧。
Selenium 爬取某天气网站数据
结语
上面放的那个视频,我做了剪辑,中间砍掉了大概50s的样子。从这里也能看出 Selenium 方案的天然劣势:慢。除了 Selenium 自身之外,文本处理耗费了相当长的时间,有这功夫,js逆向 + ajax 请求方案至少爬10个页面吧。但这不失为1种可行方案 —— 在熟悉和熟练掌握正则表达式的前提下。
Todo
在现在这个基础上,还能想到的几个时长优化思路:
第1:4个隐藏样式匹配那里,对全部td做了4次循环,而且是用了 re.findall 然后 replace。撇开 rule number 1 需要逆向找到字符串再处理外,其他3个rule 其实可以考虑使用 re.subn(regex_rule2 | regex_rule3 | regex_rule4 , '', td) —— 1次性匹配3个正则其中1个,同时替换,这样可以减少2次 for 循环,而且代码简洁度大大提升。
第2:简化 span 的处理逻辑,新的代码已经放上去了,7行代码精简成了2行,但是正则表达式更牛逼 —— 复杂了。
这2个思路共通的地方是 将 re.findall + for 循环 + replace ,替换为 re.sub。 区别在于前面这个方案是不断缩小范围,后面这个是直接在大范围内(其实也可以改小)。总的来说是 replace 可以被干掉。但是实际性能和效率对比如何,待进一步考证吧。