pytorch学习之swin-transformer算法读后感
目录
1、下采样/上采样
(1)下采样的作用?通常的方式
(2)上采样的原理和常用方式
2、self.register_buffer()
3、torch运算符@和*
4、nn.ModuleList()以及与nn.Sequential的区别
(1)nn.ModuleList
(2)与nn.Sequential的区别
5、nn.Module.apply方法
6、torch.roll函数
7、torchvision数据处理
(1)torchvision.datasets.ImageFolder()
(2)torchvision.transforms.transforms.Resize(256)
(3)torchvision.transforms.CenterCrop(size).
(4)torchvision.transforms.ToTensor():
(5)torchvision.transforms.Normalize
(6)torchvision.transforms.Compose
8、torch.utils.data.DataLoader数据加载
(1)sampler采样器
(2)pin_memory参数
(3)sampler.set_epoch
1、下采样/上采样
(1)下采样的作用?通常的方式
下采样的作用:减少计算量;增大感受野。
下采样的方式:
- 采用stride为2的池化层,如max-pooling和average-pooling,目前通常使用max-pooling,因为他计算简单而且能够更好的保留纹理特征
- 采用stride为2的卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层代替pooling可以得到更好的效果,当然同时也增加了一定的计算量。
(2)上采样的原理和常用方式
在CNN中,由于输入图像通过CNN提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(如图像的语义分割),这个使图像由小分辨率到大分辨率的操作叫做上采样。它的实现一般有3种方式:
- 插值,一般使用双线性插值
- 反卷积(transpose conv),通过对输入feature map间隔填充0,再进行标准的卷积计算,可以使得输出feature map的尺寸比输入更大
- Up-pooling – max unpooling && Avg Unpooling – max unpooling,在对称的max pooling位置记录最大值的索引位置,然后在unpooling阶段时将对应的值放置到原先最大值位置,其余位置补0.
2、self.register_buffer()
该方法的作用是定义一组参数,这些参数在模型训练时不会更新,但是保存模型时,该组参数又作为模型参数不可或缺的一部分被保存。
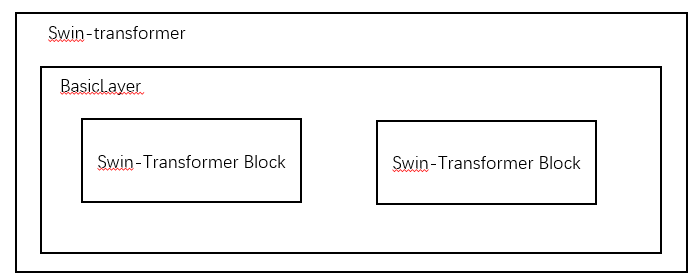
比如在swin-transformer结构中,swin-transformer套了多层的BasicLayer,而每一个BasicLayer中又套了多个Swin-Transformer Block。假如在某个Swin-Transformer Block对象中调用了self.register_buffer(‘name’, tensor)函数,则该tensor变量会注册到该swin-transformer对象的’name’属性下。

比如上例中调用了self.register_buffer(‘attn_mask’, None),swin-transformer初始化完成之后,一层层解析则得到如上的结果。
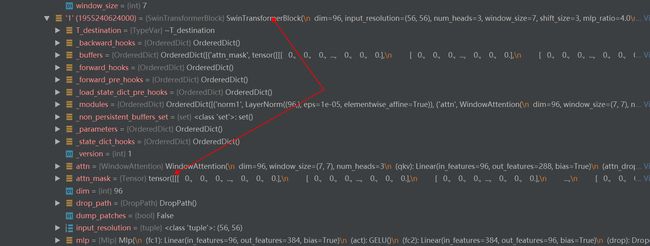
比如上例中调用self.register_buffer(‘attn_mask’, attn_mask),则得到如上的结果。
3、torch运算符@和*
@表示矩阵相乘
*表示矩阵点乘
a = torch.tensor([[1,2], [3,4]])
b = torch.tensor([[4,5], [6,7]])
c = a@b
d = a*b
print(c)
print(d)
计算结果为:
tensor([[16, 19],
[36, 43]])
tensor([[ 4, 10],
[18, 28]])
4、nn.ModuleList()以及与nn.Sequential的区别
(1)nn.ModuleList
不用于一般的list,加入到nn.ModuleList里面的module是会自动注册到整个网络上的,同时module的parameters也会自动添加到网络中。若使用python的list,则不会做这些事情
(2)与nn.Sequential的区别
- nn.Sequential内部实现了forward函数,因此可以不用写forward函数。而nn.ModuleList则没有实现内部forward函数
- nn.Sequential可以使用OrderDict对每层进行命名
- nn.Sequential里面的模块按照顺序进行排列,所以必须确保前一个模块的输出大小和下一个模块的输入大小是一致的。而nn.ModuleList并没有定义一个网络,它只是将不同的模块存储在一起,这些模块之间并没有什么先后顺序可言。同时因为第1个原因,网络的执行顺序是根据forward函数来决定的。
5、nn.Module.apply方法
使用方法:apply(fn),fn是应用于每个子模块的函数
作用:将fn递归地应用于每个子模块(由.children()返回)以及自身,典型用途包括初始化模型的参数。
示例:
import torch
import torch.nn as nn
def init_weights(m):
print(m)
if type(m) == nn.Linear:
m.weight.fill_(1.0)
print(m.weight)
with torch.no_grad() :
net = nn.Sequential(nn.Linear(2,2), nn.Linear(2,2))
net.apply(init_weights)
返回:
Linear(in_features=2, out_features=2, bias=True) --子模块1
Parameter containing:
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
Linear(in_features=2, out_features=2, bias=True) --子模块2
Parameter containing:
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
Sequential( --自身
(0): Linear(in_features=2, out_features=2, bias=True)
(1): Linear(in_features=2, out_features=2, bias=True)
)
6、torch.roll函数
 ->(步骤1)
->(步骤1) 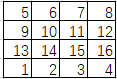 ->(步骤2)
->(步骤2) 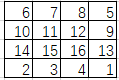
步骤1:torch.roll(a, shifts=-1, dims=0)
步骤2:torch.roll(b, shifts=-1, dims=1)
7、torchvision数据处理
(1)torchvision.datasets.ImageFolder()
仅读取ImageNet格式的数据
(2)torchvision.transforms.transforms.Resize(256)
按照比例把图像最小的一个边长缩放到256,另一边按照相同比例缩放。
(3)torchvision.transforms.CenterCrop(size).
依据给定的size从中心裁剪。
若size为sequence,则为(h,w)
若为int,则(size, size)
(4)torchvision.transforms.ToTensor():
转换为tensor格式,这个格式可以直接输入进神经网络
(5)torchvision.transforms.Normalize
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
对像素值进行归一化处理
(6)torchvision.transforms.Compose
将transforms组合在一起,而每一个transforms都有自己的功能。最终只要使用定义好的train_transformer就可以循序处理transforms的要求。
8、torch.utils.data.DataLoader数据加载
data_loader_train = torch.utils.data.DataLoader(
dataset_train, sampler=sampler_train,
batch_size=config.DATA.BATCH_SIZE,
num_workers=config.DATA.NUM_WORKERS,
pin_memory=config.DATA.PIN_MEMORY,
drop_last=True,
)
(1)sampler采样器
定义示例如下:
sampler_train = torch.utils.data.DistributedSampler(dataset_train, num_replicas=num_tasks, rank=global_rank, shuffle=True)
分布式采样器,数据被平分到多块gpu上,每个epoch被分配到每块卡上的数据都一样。
(2)pin_memory参数
pin_memory就是锁页内存,创建DataLoader时,设置pin_memory=True,则意味着生成Tensor数据最开始是属于内存中的锁页内存,这样将内存的Tensor转移到GPU的显存就会更快一些。
主机中的内存有两种存在方式:一是锁页,二是不锁页。
锁页内存存放的内容在任何情况下都不会与主机的虚拟内存进行交换(虚拟内存就是硬盘),而不锁页内存在主机内存不足时数据会存放在虚拟内存中。显卡中的显存全部是锁页内存。
当计算机的内存充足的时候,可以设置pin_memory=True。当系统卡住,或者交换内存使用过多的时候,设置pin_memory=False。Pytorch默认情况下pin_memory=False。
(3)sampler.set_epoch
在分布式模式下,需要在每个epoch开始时调用set_epoch()方法,然后再创建DataLoader迭代器,以使shuffle操作能够在多个epoch中正常工作。否则,dataloader迭代器产生的数据将始终使用相同的顺序。
示例:
sampler = DistributedSampler(dataset) if is_distributed else None
loader = DataLoader(dataset, shuffle=(sampler is None),
sampler=sampler)
for epoch in range(start_epoch, n_epochs):
if is_distributed:
sampler.set_epoch(epoch)
train(loader)