深度学习理论向应用的过渡课程【北京大学_TensorFlow2.0笔记】学习笔记(十二)——Embedding,LSTM,GRU
目录
1、Embedding
使用RNN实现输入一个字母预测下一个字母(Embedding)
使用RNN实现输入四个连续字母预测下一个字母(Embedding)
2、使用RNN实现股票预测
3、LSTM
可以这样理解
如何用TF实现LSTM
使用LSTM实现股票代码
4、GRU
如何用TF实现GRU
使用GRU实现股票代码
1、Embedding
独热码:位宽要求与词汇量一致,若词汇量增大则过于稀疏,非常浪费资源;映射之间是独立的,没有表现出关联性。
Embedding:单词编码方式,使用低维向量实现编码,可通过神经网络实现优化,能表达出单词之间的相关性。
tf.keras.layers.Embedding(词汇表大小,编码维度)
编码维度:用几个数字表达一个单词
如:对1-100进行编码,[4]编码为[0.25, 0.1, 0.11]
tf.keras.layers.Embedding(100,3)
x_train维度:[送入样本数,循环核时间展开步数]
使用RNN实现输入一个字母预测下一个字母(Embedding)

在Squential搭建网络时,增加Embedding层,先对输入数据进行编码,生成一个5*2的可训练参数矩阵,实现编码可训练。
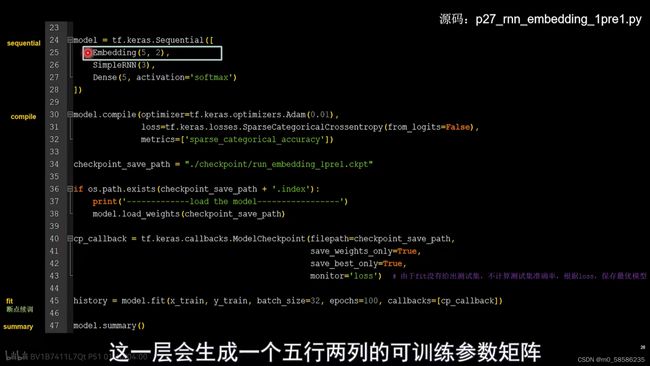

参数提取和acc/loss可视化与使用one-hot进行一预测一的代码完全一致(可对比笔记十一)
使用RNN实现输入四个连续字母预测下一个字母(Embedding)

2、使用RNN实现股票预测





3、LSTM
RNN可通过记忆体实现短期记忆,进行连续数据的预测,但当连续数据的序列变长时,会使展开时间步过长,在BP更新参数时,梯度要按时间步连续相乘,会导致梯度消失。

可以这样理解
“LSTM就是你听我讲课的过程,现在脑袋里记住的内容,是今天PPT1-45页的长期记忆Ct。Ct由两部分组成,一部分与上一时刻的长期记忆Ct-1有关,另一部分与现在的记忆Ct~有关。
过去记忆即1-44页的内容,即上一时刻的长期记忆Ct-1,不可能全部记住,因此要乘以遗忘门ft,乘积项表示留存在脑中对过去的记忆。
现在的记忆是正在讲的内容,由两部分构成,一部分是正在讲的45页PPT即当前时刻的输入xt,另一部分是前44页PPT的短期记忆留存ht-1,大脑将这两部分归纳成为Ct~,再乘以输入门it,与过去记忆一同存储为长期记忆。
当给朋友复述这一讲时,不可能一字不落的全都讲出来,讲述的是留存在脑中的长期记忆Ct 经过输出门ot筛选之后的内容,这就是记忆体的输出ht”

当有多层循环网络时,第二层循环网络的输入xt,就是第一层网络的输出ht。
如何用TF实现LSTM
tf.keras.layers.LSTM(记忆体个数,return_sequences=是否返回输出)
return_sequences=True——各时间步输出ht
return_sequences=False——仅在最后时间步输出ht(默认)
例子
model = tf.keras.Sequential([
LSTM(80,return_sequences=True),
Dropout(0.2),
LSTM(100),
Dropout(0.2),
Dense(1)
])使用LSTM实现股票代码
(改动处只有下两图方框内部分,其余内容与RNN实现股票预测完全一致)


4、GRU
记忆体ht融合了长期记忆和短期记忆,ht包含了过去信息ht-1和现在信息ht~。
现在信息ht~是过去信息ht-1过重置们与当前输入的共同决定。
更新门和重置门的取值范围在0-1之间。
前向传播时直接使用记忆体更新公式,就可以算出每个时刻的ht值了。

如何用TF实现GRU
tf.keras.layers.GRU(记忆体个数,return_sequences=是否返回输出)
return_sequences=True——各时间步输出ht
return_sequences=False——仅在最后时间步输出ht(默认)
通常最后一层用False,中间层用True
例子
model = tf.keras.Sequential([
GRU(80,return_sequences=True),
Dropout(0.2),
GRU(100),
Dropout(0.2),
Dense(1)
])使用GRU实现股票代码
(将“LSTM”全部改为"GRU",其余内容与LSTM实现股票预测完全一致)