【Transformer学习笔记】VIT解析
很久以前科学家做过一个生物实验,发现视觉神经元同样可以被训练来作听觉神经元之用。受此启发,不少计算机研究者也在寻找着机器学习领域的大一统–将CV任务和NLP任务使用相同或者类似的结构进行建模。
随着transformer在nlp领域已经杀出了一片天,便有研究者想用它来进军cv领域。Vit,vision transformer正是在此道路上跨出的一大步。
transformer是世界上最好的结构!(误)
原文地址
VIT整体结构

论文中的结构图还是十分简单易懂的,相信如果之前接触过Transformer系列,那么看懂这张图不是难事。
首先和在nlp领域中的应用一大不同,就是VIT只有encoder编码层,没有decoder。第二个不同可能就是输入从字符变成了切碎的图片。
其他的embedding(也就是linear projection)和position embedding,muti-head attention基本都是熟悉的配方。
输入转换
首先看输入,不同于cnn中滑动窗口式的卷积,VIT中直接采用了non-overlapping的分割方式,将一张图片分割成很多个大小一致的patches。
transformer系列的输入都很有意思。即使patches在一开始的时候是一个个图片块,也就是矩阵,最后为了向nlp中的词向量的表示看齐,都会被拉成条(flatten)。
即使图片有3通道,这三个通道也要被拉平后拼接。如下公式。
H × W × C → N × ( P 2 C ) H \times W \times C \rightarrow N \times (P^{2} C) H×W×C→N×(P2C)
其中H,W,C分别是图片的高,宽,通道。N是patches的总数, ( P , P ) (P,P) (P,P)是patches的大小。
这个公式的意思就是每个三维的图片块最后都被拉成一条了。
之后经过linear projection层进行映射,就得到了一个 N × D N \times D N×D大小的输入,同样,此处省略了batchsize。
位置编码
NLP中的位置编码用来记住词语的上下文关系,VIT中的位置编码同样也是为了记住图片之间的相对位置关系。
值得一提的是,VIT中仿照BERT的做法,加了一个classification patch,作为额外的输入。其大小为 1 × D 1\times D 1×D,和经过了linear projection的patch大小一致。这个patch加在了最前头。所以最终进入位置编码实际上有 N + 1 N+1 N+1个patches。
论文中使用的是可学习的一维位置编码,其实就是初始化了一个可学习的随机变量,加到了原本的输入上。
attention
VIT的encoder基本可以说是完全照搬了NLP中encoder的结构了,堆叠了很多层,每层执行一次多头注意力机制。
MLP其实也只是换了一个名字,所做的也是先升维再降维。
具体的可以看我的上一篇文章,里面有注意力机制的详解。
【Transformer学习笔记】Transformer开山之作: Attention is All you Need
如果把每层都看作一个黑盒子,其实encoder做的就是信息的融合,把每个patches的表示和其他所有patches进行融合,达到全局视野的效果。每层的输入和输出大小不变。
分类头
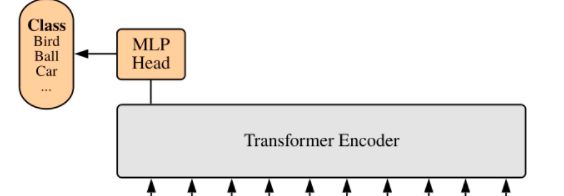
最后面的classification层中,并没有取所有的patches作为输入,因为在多头注意力机制中,每个patch其实都已经融合了所有的patches的信息,因此此处只取了一个,也就是前面提到的classification patch映射到物体种类数量进行分类。
总结
VIT将transformer引入了CV领域,并且对比现有的CNN方法,也在各类数据集上取得了不错的成果。
但是VIT只在分类work的比较好,因为它虽然有全局性,但是图片的平移不变形和尺度不变形它基本就没办了。
此外,它的计算复杂度也是比较惊人的,因为它的编码是像素级的,所以计算量会随着图片大小二次方地增长。