神经网络学习笔记(三)——长短时记忆(LSTM)网络
LSTM网络是循环神经网络的一种特殊类型,它可以学习长期以来的信息,它是一种拥有三个“门”结构的特殊网络结构。
1.LSTM网络结构
原始RNN的隐藏层只有一个状态h,如图1(a),它对于短期的输入非常敏感。LSTM网络增加一个状态c,让它保存长期的状态,如图1(b)。
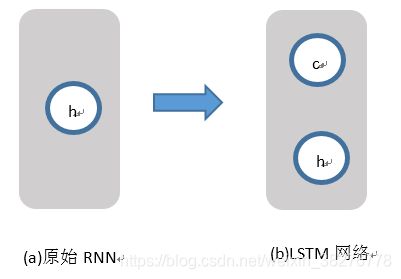
图1
新增状态c,称为单元状态。把图1(b)按照时间维度展开,如图2所示。
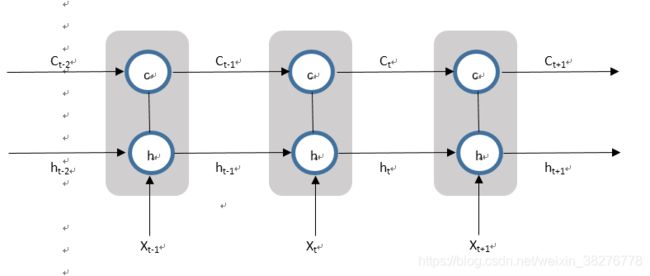
图2
由上图可以看出:在t时刻,LSTM网络的输入有三个,即当前时刻网络的 、上一时刻LSTM网络的输出值
、上一时刻LSTM网络的输出值 以及上一时刻的单元状态
以及上一时刻的单元状态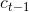 ;LSTM的输出有两个,即当前时刻LSTM网络输出值
;LSTM的输出有两个,即当前时刻LSTM网络输出值 和当前时刻的单元状态
和当前时刻的单元状态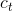 。注意、
。注意、 、
、 都是向量。
都是向量。
LSTM网络的关键就是怎么控制长期状态c。LSTM的思路:使用三个控制开关:第一个开关,控制继续保持长期状态c;第二个开关,控制把即时状态输入到长期状态c;第三个开关,控制是否把长期状态c作为当前的LSTM网络的输出。
2.LSTM前向计算
门实际上是一层全连接层,它的输入是一个向量,输出是一个0~1之间的实数向量。假设W是门的权重向量,b是偏置项,门可以表示为:。门的使用就是用门的输出两项按元素乘以需要控制的向量。当门的输出为0时什么都不能通过,当输出为1时什么都能通过,因为sigmoid函数值域是(0,1),使用门的状态是半开半闭的。
LSTM网络用两个门来控制单元状态c的内容,一个是遗忘门(Forget Gate),它决定上一时刻的单元状态有多少保留到当前时刻的单元状态;另一个是输出门(Input Gate)它决定了当前时刻网络的输入 有多少保存到单元状态。LSTM用输出门控制单元状态有多少输出到LSTM网络的当前输出值。
有多少保存到单元状态。LSTM用输出门控制单元状态有多少输出到LSTM网络的当前输出值。
遗忘门:![]() 。式中,
。式中,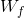 是遗忘门的权重矩阵,表示把两个向量连接成一个更长的向量,
是遗忘门的权重矩阵,表示把两个向量连接成一个更长的向量,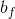 是遗忘门的偏置项,
是遗忘门的偏置项, 是sigmoid函数。如果输入维度是
是sigmoid函数。如果输入维度是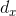 ,隐藏层的维度是
,隐藏层的维度是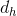 ,单元状态的维度是(通常),则遗忘门的权重矩阵的维度为。事实上,权重矩阵是由两个矩阵拼接而成的:一个是,它对应的输入项,其维度为;一个是,对应的输入项为,维度为,则前述权重矩阵可以写完为:
,单元状态的维度是(通常),则遗忘门的权重矩阵的维度为。事实上,权重矩阵是由两个矩阵拼接而成的:一个是,它对应的输入项,其维度为;一个是,对应的输入项为,维度为,则前述权重矩阵可以写完为:
遗忘门计算示意图如图3所示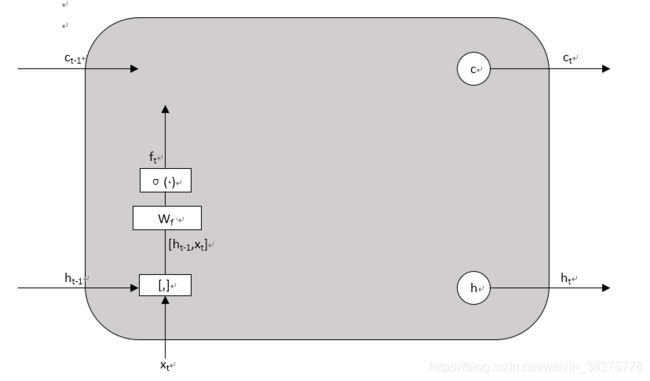
图3
输入门:,计算示意如图4所示。

接下来计算用于描述当前输入的单元状态,它是根据上一次的输出和本次的输入来计算的:
,计算示意如图5所示:
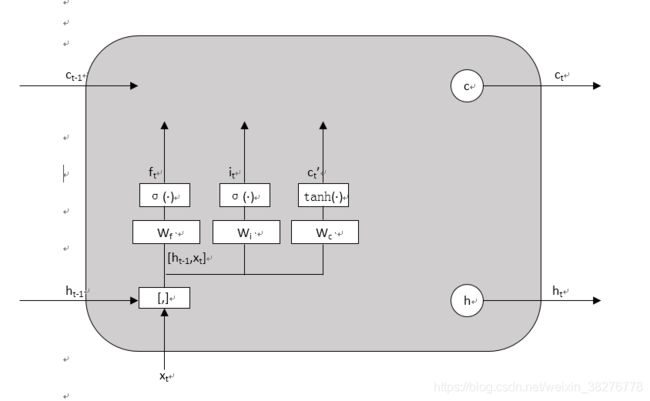
图5
现在计算当前时刻的单元状态。它由上次的单元状态按元素乘以遗忘门 ,再用当前输入的单元状态按元素乘以输出门
,再用当前输入的单元状态按元素乘以输出门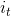 ,再将这两个积相加而产生的:,计算示意图如图6所示。
,再将这两个积相加而产生的:,计算示意图如图6所示。

图6
这样LSTM网络就把关于当前记忆和长期记忆组合在一起,形成新的单元状态。
输出门,它控制了长期记忆对当前输出的影响:,计算示意如图7所示。

图7
最终输出是由输出门和单元状态共同决定的:![]() ,计算示意如图8所示。
,计算示意如图8所示。
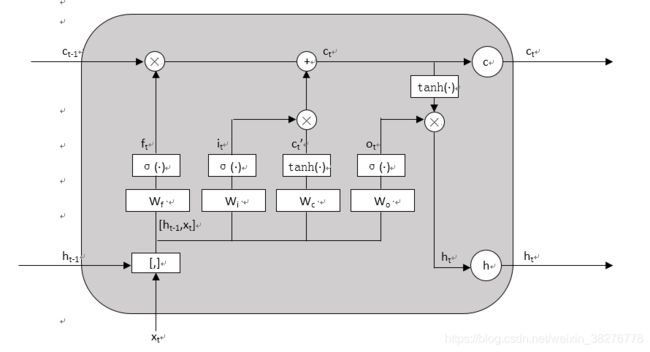
图8
3.仿真实例
利用单层LSTM网络对余弦函数consx的取值进行预测。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
hidden_size=30
timesteps=10
training_steps=1000
batch_size=32
training_examples=10000
testing_examples=1000
sample_gap=0.01
#序列的第i项和后面的timesteps-1项合在一起作为输入,第i+timsteps作为输出
def generate_data(seq):
x=[]#输入
y=[]#输出
for i in range(len(seq)-timesteps):
x.append([seq[i:i+timesteps]])#是(len(seq)-timesteps,timesteps,1)维的数组
y.append([seq[i+timesteps]])#为(len(seq)-timesteps,1)维数组
return np.array(x,dtype=np.float32),np.array(y,dtype=np.float32)
test_start=(training_examples+timesteps)*sample_gap#=100.1
test_end=test_start+(testing_examples+timesteps)*sample_gap#=100.1+10.1=110.2
train_x,train_y=generate_data(np.cos(np.linspace(
0,test_start,training_examples+timesteps,dtype=np.float32)))
#seq=np.cos(np.linspace(0,100.1,10010,float32))
#train_x(10000,10,1),train_y(10000,1)
test_x,test_y=generate_data(np.cos(np.linspace(
test_start,test_end,testing_examples+timesteps,dtype=np.float32)))
#seq=np.cos(np.linspace(100.1,110.2,1010,float32))
#test_x(1000,10,1),test_y(1000,1)
#定义LSTM网络模型函数
def lstm_model(x,y,is_training):
cell=tf.contrib.rnn.BasicLSTMCell(hidden_size)
outputs,_=tf.nn.dynamic_rnn(cell,x,dtype=tf.float32)
#time_major参数默认为false,此时输入是shape为[batch_size, max_time, input_size]的Tensor
#time_major为true时,是一个shape为[max_time, batch_size, input_size]的Tensor
#返回一对(outputs,state),state为最终状态,outputs形状根据time_major来决定
output=outputs[:,-1,:]
predictions=tf.contrib.layers.fully_connected(output,1,activation_fn=None)
#作用:添加一个完全连接层,参数:输入、输出的个数,激活函数默认为relu
if not is_training:
return predictions,None,None
loss=tf.losses.mean_squared_error(labels=y,predictions=predictions)
#y:真实的输出张量,predictions:预测的输出张量
train_op=tf.contrib.layers.optimize_loss(
loss,tf.train.get_global_step(),
optimizer="Adagrad",learning_rate=0.1)
return predictions,loss,train_op
#定义评估函数
def run_eval(sess,test_x,test_y):
ds=tf.data.Dataset.from_tensor_slices((test_x,test_y))
ds=ds.batch(1)
x,y=ds.make_one_shot_iterator().get_next()
with tf.variable_scope("model",reuse=True):
prediction,_,_=lstm_model(x,[0.0],False)
predictions=[]
labels=[]
for i in range(testing_examples):
p,l=sess.run([prediction,y])
predictions.append(p)
labels.append(l)
#计算rmse作为评价指标
predictions=np.array(predictions).squeeze()
#squeeze的作用是从数组的形状中删除单维条目,即把shape中为1的维度删除,
#如[[1],[2],[3]]->[1,2,3],形状从(3,1)变为(3,)
labels=np.array(labels).squeeze()
rmse=np.sqrt(((predictions-labels)**2).mean(axis=0))
#0->求每一列的均值
print("Root Mean Square Error is:%f"%rmse)
#对预测的cos函数曲线进行绘图
plt.figure()
plt.plot(predictions,"b-",label='predictions')
plt.plot(labels,"r:",label='real_cos')
plt.legend()
plt.show()
ds=tf.data.Dataset.from_tensor_slices((train_x,train_y))
#tf.data.Dataset.from_tensor_slices切分传入的 Tensor 的第一个维度,生成相应的 dataset
#对传入的(5,2)进行切分,最终产生的dataset有5个元素,每个元素的形状都是(2,)
#train_x(10000,10,1),train_y(10000,1) -->10000个(10,1)和10000个一维数组
ds=ds.repeat().shuffle(1000).batch(batch_size)
#shuffle将数据打乱,指定数目越大混乱的程度越大
#batch:一次取出batch_size行数据,最后一次可以小于batch_size
#repeat:数据集重复了指定次数
x,y=ds.make_one_shot_iterator().get_next()
#make_one_shot_iterator()建立单次Iterator对象,get_next()取出其中的对象
#定义模型,得到预测结果、损失函数和训练操作
with tf.variable_scope("model",reuse=True):
_,loss,train_op=lstm_model(x,y,True)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
#测试在训练之前的模型效果
print("evaluate model before training.")
run_eval(sess,test_x,test_y)
#训练模型
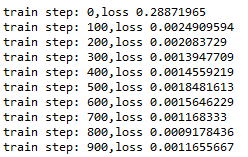
for i in range(training_steps):
_,l=sess.run([train_op,loss])
if i%100==0:
print("train step:",str(i)+",loss",str(l))
print("evaluate after training.")
run_eval(sess,test_x,test_y)实验结果:
训练前:
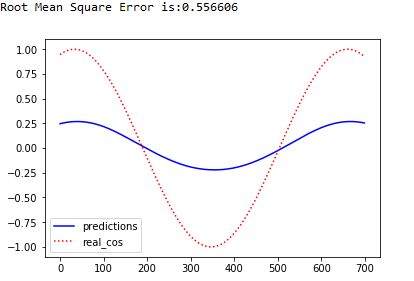
训练中:
训练后:

参考:包子阳《神经网络与深度学习》