01机器学习基础
本章主要介绍机器学习中的重要概念、数据处理方法、一些应用等
文章目录
- 一、人工智能、机器学习、深度学习之间的关系
- 二、机器学习概述
-
- 1.基本概念
- 2.损失函数(Loss Function):
- 3.过拟合和欠拟合
- 三、机器学习方法分类
-
- 1.有监督学习(Supervised Learning)
- 2.无监督学习(Unsupervised Learning)
- 3.半监督学习(Semi-Supervised Learning)
- 4.深度学习(Deep Learning)
- 5.强化学习(Reinforcement Learning)
- 四、数据预处理
-
- 1.数据清洗
- 2.数据集拆分
- 五、机器学习的应用
- 六、本章小练习
一、人工智能、机器学习、深度学习之间的关系
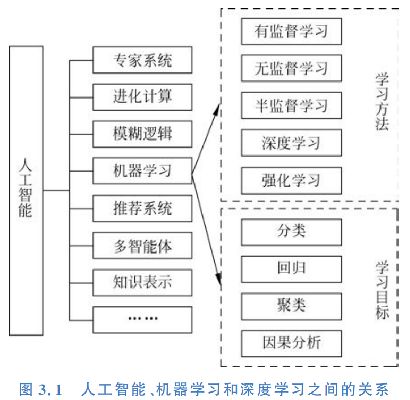
人工智能是一门研究用于模拟、延伸和拓展人的智能的理论和方法的学科;
机器学习是一种实现人工智能的方法;而深度学习又是机器学习下面的一个子模块;
它通过模拟人脑实现相应的功能;应用场景主要包含手机,机器翻译、自动驾驶,语音识别,医疗,安防等
二、机器学习概述
机器学习(Machine Learning) 就是让机器通过学习数据来完成任务的算法
1.基本概念
以预测下雨为例:
在预测下雨之前,我们需要获取一些特征(Feature)或属性(Attribute),特征是输入变量,即简单线性回归中的 x 变量,复杂的比如是否出现了朝霞、晚霞、空气湿度、温度、云量等,我们将这些特征表示为一个d 维的特征向量(FeatureVector),记作 x = [ x 1 , x 2 , . . . , x d ] T \pmb{x} =\left [ x_{1} ,x_{2},...,x_{d}\right ]^{T} xx=[x1,x2,...,xd]T,向量的每一个维度代表一个特征,总共选取了d 个特征;
特征有对应的标签(Label),标签是我们要预测的事物,即简单线性回归中的 y 变量,标签可以是连续的,如下雨量、下雨持续时间;标签也可以是离散的,比如是否会下雨;标签的选取与要完成的任务有关;
标签是连续值,这样的机器学习任务叫回归问题,例如预测波士顿的房价;
标签是离散值,这样的机器学习任务叫分类问题,例如垃圾分类;
标签是标记序列,这样的机器学习任务叫标注问题,它是分类问题的推广,例如自然语言处理中的词性标注
一组记录好的特征值及其它的标签叫一个样本(Sample)或实例(Instance),一组样本构成的集合叫数据集(Dataset),数据集要分为两部分:训练集和测试集,这两个集合要不相交。
例如我们的任务是预测是否下雨,为了完成这个任务,我们用一个函数y来帮我们预测,它可以实现直接输入变量x(云量)(真实预测是比较复杂的,输入变量是比较多的,这里只是简单举个例子),就可以得到结果(是否下雨),函数y是由变量x和一个参数 θ \theta θ决定的,这个参数 θ \theta θ我们最开始是不知道的,只有通过不断地调试,才能找到一个比较合适的 θ \theta θ使这个函数预测的正确率比较高。

这个需要确定的拟合函数y叫做模型(Model),找这个参数 θ \theta θ 的合适值的过程就叫做训练(Traininng)或学习(Learning)
学习的目的是找到一个最好的模型,而这样一个模型应当是输 入 空 间 至 输 出 空 间 映 射 集 合 中 的 一 个 映 射,这 个 映 射 集 合 称 为 假 设 空 间(HypothesisSpace)。换句话说,学习的目的就在于从这个假设空间中选择出一个最好的元素。
2.损失函数(Loss Function):
又叫做代价函数(Cost Function),用来衡量函数模型的预测值f(x)与样本真实值Y的差异,常见的有平方损失函数 y = 1 2 ( Y − f ( x ) ) 2 y=\frac{1}{2}(Y-f(x))^{2} y=21(Y−f(x))2
3.过拟合和欠拟合
过拟合(Overfitting):训练误差降低,测试误差提高的现象;一般导致此产生的原因有 :训练集的样本过大,噪声过多,不能很好地反应数据的真实分布;主要原因是训练数据量不足以及模型能力过强或模型函数过于复杂;
欠拟合(Underfitting):模型过于简单而导致训练误差一直很大
三、机器学习方法分类
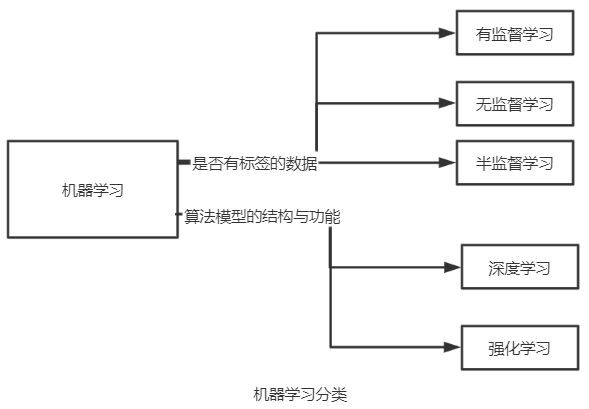
1.有监督学习(Supervised Learning)
是指利用带标签的样本来优化算法的参数,使其性能提高的过程;
数据集的样本不仅有特征,还有标签;
优点:模型性能好,精度高;
缺点:需要人为参与,耗时耗力,获取数据成本高;
2.无监督学习(Unsupervised Learning)
是指算法根据没有标签的样本来解决各种问题的过程;
数据集的样本只有特征,没有标签,这些标签是模型根据特征按某种规则归纳出的;
优点:不需要人为参与,训练数据量可以更大;
缺点:对于同样的特征点,使用不同的迭代初始值可能会得到完全不同的结果,即难以衡量高维数据的相似度,直观的评价标准还是具有人为的主观性;
代表性的算法有:聚类算法和主成分分析PCA;
3.半监督学习(Semi-Supervised Learning)
是有监督学习和无监督学习的一种结合方法,既利用了有标签的数据,也利用了无标签的数据;
优点:人为参与度较少,准确率较高
4.深度学习(Deep Learning)
是指深层的人工神经网络结构,这种结构通过深度的网络不断提取高层次的特征来达到非常优秀的结果。深度学习是一种基于数据表征学习的方法,动机在于模拟人脑的分析过程,从底层特征到高层特征一一建模。
深度学习有几种比较有代表性的网络结构,比如前馈神经网络———多层感知机(MultiLayerPerceptron,MLP)和卷积神经网络 (Convolutional NeuralNetwork,CNN),反 馈 神 经 网 络———循环神经网络(Recurrent NeuralNetwork,RNN)
5.强化学习(Reinforcement Learning)
是通过智能体(Agent)以试错的方式进行的学习;智能体不断与环境进行交互来获得奖励或者惩罚,目标是使
智能体最终获得的奖励值最大(奖惩机制)。
强化学习非常适合于那些没有绝对的正确标准的任务,如棋牌类对弈、公路自动驾驶策略、游戏中的人机对战等。
四、数据预处理
1.数据清洗
1)目的:清除数据集中的“脏”数据
2)脏数据:残缺、错误、重复数据等;
3)数据清洗的步骤:分析数据、残缺数据处理、错误数据处理、重复数据处理等;
4)缺少数据的处理方法:
- 直接删去;
- 赋一个常量(0或Unknown);
- 赋均值或中位数;
- 插补法;
- 建模法(通过建模来推理预测);
5)错误数据又叫做异常值,离群点;
2.数据集拆分
训练迭代次数太多很有可能引起过拟合,而训练迭代次数不足会导致欠拟合,我们不知道训练的次数应该选取多少为优。因此,我们还需要另外一个与它们都不相交的集合———验证集(ValidationDataset)
故将数据集拆分为以下三类:
① 训练集:用来模型迭代训练的数据集;
②验证集;用来预防过拟合的发生,辅助训练过程的数据集;
③测试集;用来评估最后训练好的模型性能的数据集;
数据集的划分方法:
1)留出法:一般选70%的样本作为训练集,30%的样本作为测试集,没有验证集;
2)K-折交叉验证法:将原始数据均分为K个互斥的集合,获取K组训练集-测试集,从而进行K次训练和测试,最终再通过K次交叉验证得到评估结果;
3)自助法:通过自助采样方式进行,对数据集做有放回的抽样;简言之就是在m个样本的数据集中取m次作为训练样本,这样有些样本可能在训练集中出现多次,有些则可能从未出现
五、机器学习的应用
主要是以下几类:
1.分类问题——图像识别、垃圾邮件识别
2.预测问题——股价预测、房价预测
3.排序问题——点击率预估、推荐
4.生成问题——图像生成、图像风格转换、图像文字描述
六、本章小练习
鸢尾花分类:

原书代码:https://aistudio.baidu.com/aistudio/projectDetail/101812
我自己的是在原来的基础上增加了一些注释,方便理解,如果对您也有帮助,那就是我莫大的荣幸。
https://aistudio.baidu.com/aistudio/projectdetail/4840723
原书代码合集:https://aistudio.baidu.com/aistudio/projectdetail/101810