课程向:深度学习与人类语言处理 ——李宏毅,2020 (P26)
Constituency Parsing
李宏毅老师2020新课深度学习与人类语言处理课程主页:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
视频链接地址:
https://www.bilibili.com/video/BV1RE411g7rQ
图片均截自课程PPT、且已得到李宏毅老师的许可:)
考虑到部分英文术语的不易理解性,因此笔记尽可能在标题后加中文辅助理解,虽然这样看起来会乱一些,但更好读者理解,以及文章内部较少使用英文术语或者即使用英文也会加中文注释,望见谅
深度学习与人类语言处理 P26 系列文章目录
- Constituency Parsing
- 前言
- I Constituency Parsing 成分句法分析
-
- 1.1 Constituent 组成成分
- 1.2 Labels 组成成分的类别
- 1.3 Training targets 训练目标
- II Approach 解法
-
- 2.1 Chart-based Approach 基于图的方法
-
- 2.1.1 Task abstraction 任务抽象化
- 2.1.2 Classifier 分类器
- 2.1.3 Problem 问题
- 2.1.4 Inference 测试
- 2.2 Transition-based Approach 基于转变的方法
-
- 2.2.1 Modules 模块
- 2.2.2 Example 例子
- 2.2.3 RNN Grammar 一种深度学习模型决定 命令
- 2.2.4 RNN Grammar training 训练方式
- 2.2.5 Grammar as a Foreign Language 将语法视为一种语言
前言
在前一篇的上半篇中(P25)我们讲解了 Multilingual BERT,多语种BERT的神奇之处,零样本学习的跨语言学习能力以及有关猜想和实验。
而在本篇P26 和 下一篇P27,我们将进入 Parsing 句法分析,
在本篇P26中将讲解
Constituency Parsing 成分句法分析:把句子组织成短语的形式
在下一篇P27中将讲解
Dependency Parsing 依存句法分析:找出句子中词的依赖关系
本篇 Constituency Parsing 成分句法分析将讲解任务的基本概念、训练目标以及常用的两种解法,和深度学习在这些解法中的使用。
I Constituency Parsing 成分句法分析
1.1 Constituent 组成成分

Constituency Parsing 成分句法分析,是指判断句中某一些连续片段spans是不是一个 constituent 组成成分,以及这个 组成成分是什么类别。
在此,你可以将 constituent 组成成分理解为一个单位,某些词汇组合在一起可以构成一个单位,这个单位就是组成成分。举例来说,如上图,“deep learning is very powerful” 一句中有这样的组成成分:
”deep learning“ 是一个组成成分 NP 名词,
”very powerful“ 是一个组成成分 ADJP 形容词,
而”learning is very“ 不是一个组成成分。
1.2 Labels 组成成分的类别

有关constituent 组成成分的类别可参考上图,如”ADJP“ 代表形容词短语;”ADVP“代表副词短语;”NP“代表名词短语;”PP“代表”介词短语“;”S“代表一个子句等等…
1.3 Training targets 训练目标
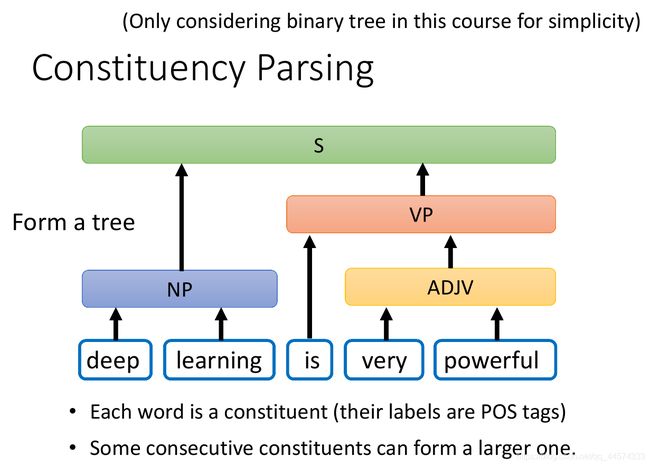
Constituency Parsing 成分句法分析要解决的问题是,如上图,给出一个句子,我们要找出句子中所有能够构组成成分的词汇段,以及该组成成分是哪个类别。把这些组成成分放在一起,便可得到这个句子的一个成分句法树,根节点是整个句子s,叶子是句中的每个词,左右子树的顶点是这棵树是一个组成成分以及其类别。
注:本课中仅考虑二叉树,其实每个顶点可以分出多个分支,有多个叶子。且我们主要关注deep learning怎么应用到成分句法分析上,因此忽略了语言学角度的专业知识等。
简而言之,成分句法分析的训练目标是:
任务一:找出句中所有的constituent 组成成分
任务二:给每一个constituent 组成成分一个类别标签
那上述问题,该怎么解呢?
II Approach 解法
有关上述问题的方法主要有两大类的解法:
Chart-based Approach 基于图的方法 和 Transition-based Approach 基于转变的方法
2.1 Chart-based Approach 基于图的方法
2.1.1 Task abstraction 任务抽象化
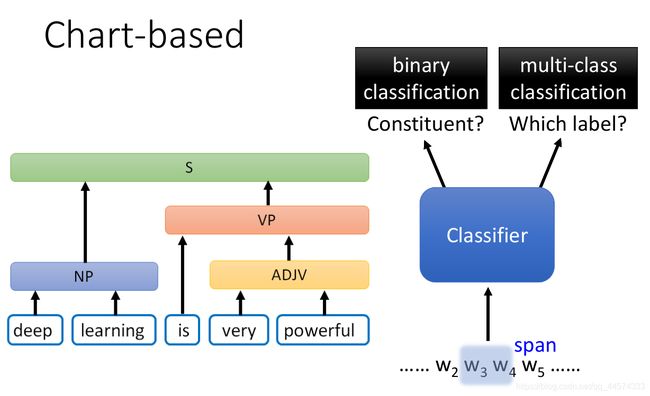
这种方法其实是由 CKY chart parsing的方法演化而来, Chart-based Approach 方法简单来讲就是训练一个二分类器和多分类器:
二分类器输入一个词汇段,判断它是否是一个constituent 组成成分
如果它是一个组成成分,多分类器输入该组成成分,即词汇段,输出该组成成分的类别,如”ADJP“形容词短语等等
此时,任务一:找出句中所有的constituent 组成成分, 就变成了一个二分类任务;任务二:给每一个constituent 组成成分一个类别标签 ,就变成了一个多分类任务。
2.1.2 Classifier 分类器
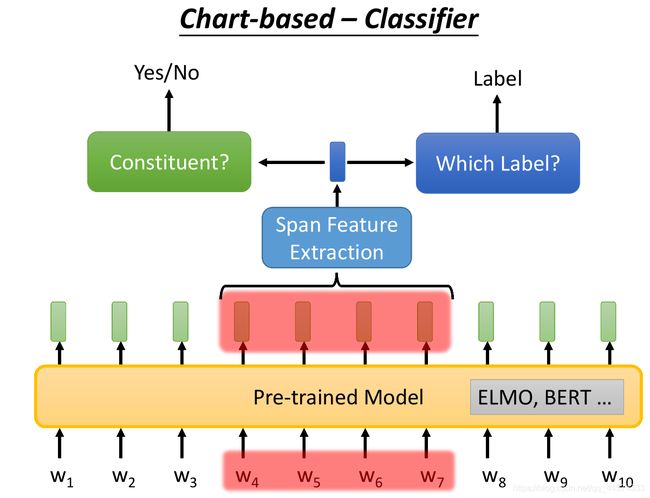
这个 Classifier 分类器,如上图:
首先,输入一串tokens序列,通过预训练模型ELMO、BERT等对其编码,得到序列中每个token的词向量表示。
然后,选出你想要判断的词汇段span,用一个Span Feature Extraction 将这一个词汇段的词向量序列抽取为一个向量表示。
最后,对这个向量进行分类判断,首先判断这个向量是否是一个组成成分,如果是,再进行多分类找出它的类别。
2.1.3 Problem 问题

但是如果仅仅按照上述2.1.2的训练方式去训练的话,可能会出现这样的一个问题:
我们会对由N个tokens组成的序列,进行每一段的穷举,一共会穷举得到 N ( N − 1 ) 2 \frac{N(N-1)}{2} 2N(N−1)个词汇段,并进行一一分类判断。此时,在某些片段的判断中可能出现的问题,如上图,我们的分类器并不是完美的,两个词汇段都被判断为是一个组成成分,但这两个词汇段是有交集的,而在句法分析上显然是没有有交集的组成成分,这是组不成一棵树的。
2.1.4 Inference 测试

为了避免上述问题,实际上,在测试时,我们是按照上图方式使用分类器的
给我们一个句子,我们会先穷举出所有的合理合法的树状结构,如上图,对”I am good“ 有两种可能的树状结构,用我们训练好的分类器对这两种树状结构进行分类判断输出,树中每颗子树是组成成分的分数。
对于第一种树,”I am“分数为0.1,”I am good“分数为0.9,第一棵树的分数便为0.1+0.9=1
对于第二种树,”am good“分数为0.8,”I am good“分数为0.9,第二棵树的分数便为0.8+0.9=1.7
因此,第二棵树更有可能是正确的树状结构,因此我们的输出也就是第二棵树的树状结构作为这个句子的成分句法树。
疑问解答:
Q:那我们该怎么穷举所有可能的树状结构呢?
A:这个时候就需要用到 CKY算法,一种动态规划算法。
Q:那我们该怎么训练呢?测试时是直接考虑整棵树的分数,而不是之前讲的单纯的分类,这样不就会导致训练和测试的不匹配了吗?
A:其实在训练的时候并不是简单的分类任务,它的训练目标是很复杂的,简而言之,会给正确的树一个最高的分数,一个错误的树较低的分数。
2.2 Transition-based Approach 基于转变的方法
除了上述Chart-based Approach 基于图的方法外,还有第二种解法:Transition-based Approach 基于转变的方法,这种方法类似于数据结构中的队列一样,通过各种命令来还原替代原队列。
2.2.1 Modules 模块

对于成分句法分析任务而言,其实我们要做的就是输入一串文字序列,输出表示这串文字序列的成分句法树,而这棵树形式上也是一串序列,因此有这样一种方法尝试用三种命令组成的序列来代替这棵树。
Transition-based Approach 基于转变的方法,如上图,主要由三个模块组成:
- Stack 栈;
- Buffer 缓存区;
- Actions 命令;
在操作开始,Stack 栈为空,Buffer 缓存区保存着输入的文字序列,Actions 命令由三个具体命令组成:
- CREATE(X):创造一个组成成分X,这个X便是组成成分的类别,如“ADJP”形容词短语、“S”子句等等,全部类别请见 本篇中 1.2 Labels 组成成分的类别
- SHIFT :从Buffer 缓存区 取一个token放到 Stack 栈中
- REDUCE:一个组成成分已生成结束,结束该组成成分的产生,是一个组成成分的结束符
上述描述可能有点抽象,让我们来看一个具体的例子
2.2.2 Example 例子

假如我们要对”deep learning is vert powerful“进行成分句法分析:
首先,对于 Stack 栈而言,它为空。对于 Buffer 缓存区 而言,它由“deep,learning,is,vert,powerful”组成,是一个列表。对于Action命令,它始终由上述三个命令组成:CREATE、SHIFT、REDUCE。
接下来,命令CREATE (S),代表开始生成句子,这是成分句法分析的初始字符,并把这个(S放到 Stack 栈里面。再针对Stack 栈和 Buffer 缓存区进行操作,CREATE (NP) 代表我们要创建一个名词短语,同样把(NP放到Stack 栈里。
然后,根据Buffer 缓存区里的值,得到命令:SHIFT,代表要将Buffer里的一个值放到栈里,即deep,同样再来一个SHIFT代表要将learning放到栈里。此时这个 NP 名词短语已经读入完成,将)放到栈中表示该名词短语读入结束。
同样,命令CREATE (VP),将(VP 放入栈中,代表开始产生动词短语,与上面同样的操作直至动词短语读入结束。
最后,经过上述操作后,记录下我们所使用的命令,我们的输入句“deep learning is vert powerful”的成分句法分析就可以变成一个由三种命令组成的序列,这个命令序列便是代表该句的成分句法分析的结果。
如果你还是没懂,你可以这样理解,“deep learning is vert powerful”的句法分析结果我们是知道的,那怎么用一串序列来表示这个结果呢?其实表示方法也是有很多种的,上述只是其中一种方法。
在我们可以通过命令序列表示这个成分句法分析结果后,我们便可以把这个成分句法分析任务抽象化为seq2seq问题,输入一串文字序列,输出一串命令序列。
那么Transition-based Approach 基于转变的方法的重点就是怎么决定何时要采取哪一种Action,如果不用基于规则的方法,我们显然需要一个用深度学习的模型来解决这个问题。
2.2.3 RNN Grammar 一种深度学习模型决定 命令

RNN Grammar 用RNN来决定何时采取哪一个命令, 我们分别用RNN读取 Stack 栈 和 Buffer 缓存区,以及之前采取过的命令也用RNN读过去,RNN都把最后一层的输出拿出来丢给一个网络,最终由这个网路来决定采取哪一个命令。
在此,你可能会觉得这种采取何种命令的训练方式应该会需要用到RL强化学习的方式去训练,其实不然,我们并不需要强化学习的方法。
2.2.4 RNN Grammar training 训练方式
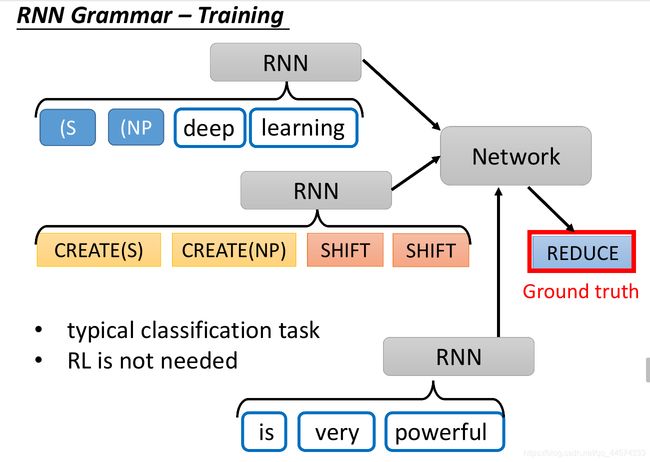
因为我们在训练时,是已经有正确答案了,我们知道在每一个状况下应该要采取什么命令才是对的,其实这仅仅是个不断进行多分类的任务而已。
2.2.5 Grammar as a Foreign Language 将语法视为一种语言

还有另外一种方法, Grammar as a Foreign Language 将语法视为一种语言的方法,老师将这种方法也归结为 Transition-based Approach 基于转变的方法,两者大同小异,只是讲法略有不同而已。这个方法就是直接用一个seq2seq模型”硬train一发“,把这种成分句法分析任务当作翻译任务来做。而为什么是翻译任务,因为在15年seq2seq模型主要还是应用于翻译上,也因此取了上图的论文题目。
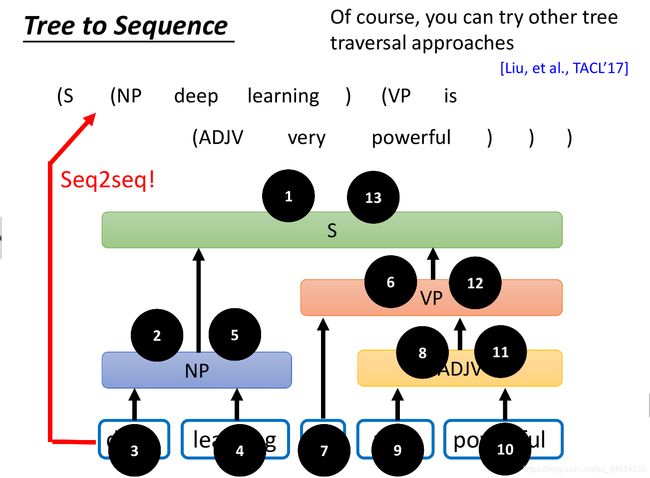
这种方法将树状结构表示成序列语言方法如上图,当然,这也是表示树的一种方法。
这种表示法的原则是从上到下,从左及右:
首先,对最上面的根节点S处理,表示为(S
之后,对根节点S的左子树NP处理,表示为(NP。同样在左子树NP中,对左叶子deep处理,表示为deep。对右叶子learning处理,表示为learning。左子树NP处理完成后,以)为结束。
然后,对根节点S的右子树VP处理,表示为(VP。同样在右子树VP中,对左叶子is处理,表示为is。对VP的右子树ADJV处理,表示为(ADJV。对右子树ADJV的左叶子very处理,表示为very。对右子树ADJV的右叶子powerful处理,表示为powerful。VP的右子树ADJV处理完毕,以)为结束。对根节点S的右子树VP处理完毕,以)为结束。
最后,根节点处理完毕,以)为结束。
上述表示结束后,就得到了如上图所示的这串序列语言。此时,我们仅仅需要一个seq2seq模型将成分句法分析想成翻译任务解决即可。
其实这种seq2seq想法和上面的RNN Grammar方法没有什么不同,都是一一对应处理的序列问题,只是说法略有不同。值得注意的是,这种seq2seq方法并不会出现成分序列不全的现象,就是说会不会出现生成的)少了一个这类的问题,实验上表明98%的可能性是不会的。
至此,句法分析其中的一种成分句法分析,把句子组织成短语的形式的有关内容到底结束。下一篇将讲解句法分析的另一部分,依存句法分析:找出句子中词的依赖关系。