34 - Swin-Transformer论文精讲及其PyTorch逐行复现
文章目录
- 1.结构图
- 2. 两种方法实现Patch_Embedding
-
- 2.1 imag2embed_naive 通过unfold展开函数
- 2.2 imag2embed_conv 通过conv卷积函数
- 3. 多头自注意力(Multi_Head_Self_Attention)
-
- 3.1 如何计算多头自注意力机制复杂度
- 3.2 构建Window MHSA并计算其复杂度
- 3.3 基于窗口的多头自注意力
- 4. Shift window MHSA及其Mask
-
- 4.1 构建步骤如下:
- 4.2 代码
- 4.3 Patch_Merging
- 5. 构建swinTransformerBlock
- 6. 构建Swin-Transformer-Model
1.结构图
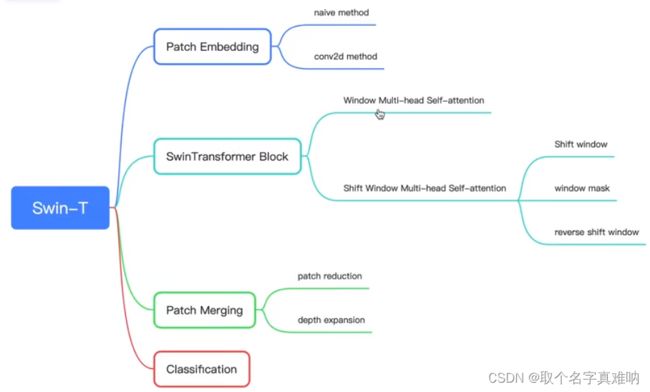
Swin-Transformer是一个新的视觉Transformer,Swin=shift+window(移动窗口),可以作为计算机视觉的基础架构backbone,swin-transformer提供了三种特性,第一是层级的结构,第二是将自注意限制在大小一定的窗口里,这样就可以将自注意力的复杂度跟图片大小呈线性关系,,第三是通过移动窗口的形式进行每个window之间的信息交流
2. 两种方法实现Patch_Embedding
2.1 imag2embed_naive 通过unfold展开函数
- 基于pytorch_unfold的API来将图片进行分块,也就是模仿卷积的思路,设置kernel_size=stride=patch_size,得到分块后的图片
- 得到格式为[bs,num_patch,patch_depth]的张量
- 将张量与形状为[patch_depth,model_dim_C]的权重矩阵进行乘法操作,即可得到形状为[bs,num_patch,model_dim_C]的patch_embedding
import torch
from torch import nn
from torch.nn import functional
import math
def imag2emb_naive(image,patch_size,wweight):
"""直观方法去实现patch_embedding"""
# image.shape=[bs,channel,h,w]
patch = F.unfold(image,kernel_size=(patch_size,patch_size),
stride=(patch_size,patch_size)).transpose(-1,-2)
patch_embedding = patch @ weight
return patch_embedding
2.2 imag2embed_conv 通过conv卷积函数
- patch_depth是等于input_channel
*patch_size*patch_size - model_dim得到格式为[bs,num_patch,patch_depth]的张量
- 将形状为[patch_depth,model_dim_C]的权重矩阵转换为[model_dim_C,input_channel,patch_size,patch_size]的卷积核
- 调用Pytorch的conv2d API得到卷积的输出张量,形状为[bs,output_channel,height,width]
- 转换为[bs,num_patch,model_dim_C]的格式,即为path_embedding
def image2emb_conv(image,kernel,stride):
# bs*oc*oh*ow
conv_output = F.conv2d(image,kernel,stride=stride)
bs,oc,oh,ow = conv_output.shape
patch_embedding = conv_output.reshape((bs,oc,oh*ow)).transpose(-1,-2)
return patch_embedding
- 测试代码
import torch
from torch.nn import functional as F
# method_1 : using unfold to achieve the patch_embedding
# step_1: unfold the image
# step_2: unfold_output@weight
def image2embed_naive(image, patch_size, weight):
"""
:param image: [bs,in_channel,height,width]
:param patch_size:
:param weight : weight.shape=[patch_depth=in_channel*patch_size*patch_size,model_dim_C]
:return: patch_embedding,it shape is [batch_size,num_patches,model_dim_C]
"""
# patch_depth = in_channel*patch_size*patch_size
# image_output.shape = [batch_size,num_patch,patch_depth=in_channel*patch_size*patch_size]
image_output = F.unfold(image, kernel_size=(patch_size, patch_size),
stride=(patch_size, patch_size)).transpose(-1, -2)
# change the final_channel dimension from patch_depth to model_dim_C
patch_embedding = image_output @ weight
return patch_embedding
# using F.conv2d to achieve the patch_embedding
def image2embed_conv(image, weight, patch_size):
# image =[batch_size,in_channel,height,width]
# weight = [out_channels,in_channels,kernel_h,kernel_w]
conv_output = F.conv2d(image, weight=weight, stride=patch_size)
bs, oc, oh, ow = conv_output.shape
patch_embedding = conv_output.reshape(bs, oc, oh * ow).transpose(-1,-2)
return patch_embedding
batch_size = 1
in_channel = 2
out_channel = 5
height = 3
width = 4
input = torch.randn(batch_size, in_channel, height, width)
patch_size = 2
weight1_depth = in_channel * patch_size * patch_size
weight1_model_c = out_channel
weight1 = torch.randn(weight1_depth,weight1_model_c)
weight2_out_channel = weight1_model_c
weight2 = weight1.transpose(0,1).reshape(weight1_model_c,in_channel,patch_size,patch_size)
output1 = image2embed_naive(input, patch_size, weight1)
output2 = image2embed_conv(input, weight2, patch_size)
# flag the check output1 is the same for output2
# if flag is true ,they are the same
flag = torch.isclose(output1,output2)
print(f"flag={flag}")
print(f"output1={output1}")
print(f"output2={output2}")
print(f"output1.shape={output1.shape}")
print(f"output2.shape={output2.shape}")
# 输出结果
# flag=tensor([[[True, True, True, True, True],
# [True, True, True, True, True]]])
# output1=tensor([[[ -0.3182, -2.0556, -0.4092, 0.8453, 3.8825],
# [ 4.1530, -2.4645, -0.8912, 3.9692, -11.5213]]])
#output2=tensor([[[ -0.3182, -2.0556, -0.4092, 0.8453, 3.8825],
# [ 4.1530, -2.4645, -0.8912, 3.9692, -11.5213]]])
#output1.shape=torch.Size([1, 2, 5])
#output2.shape=torch.Size([1, 2, 5])
3. 多头自注意力(Multi_Head_Self_Attention)
3.1 如何计算多头自注意力机制复杂度
- 基于输入X进行三个映射分别得到q,k,v
- 此步复杂度为 3 L C 2 3LC^2 3LC2 ,其中L为序列长度,C为特征大小 - 将q,k,v拆分成多头的形式,注意这里的多头各自计算不影响,所以可以与bs维度进行统一看待
- 计算 q k T qk^T qkT,并考虑可能的研发,即让无效的两两位置之间的能量为负无穷,掩码是在shift window MHSA中会需要,而在window MHSA中暂不需要
- 此步复杂度为 L 2 C L^2C L2C
- 计算概率值与V的乘积
- 此步复杂度为 L 2 C L^2C L2C
- 对输出进行再次映射
- 此步复杂度为 L C 2 LC^2 LC2
- 总体复杂度为 4 L C 2 + 2 L 2 C 4LC^2+2L^2C 4LC2+2L2C
from torch import nn
class MultiHeadSelfAttention(nn.Module):
def __init__(self,model_dim,num_head):
super(MultiHeadSelfAttention, self).__init__()
self.num_head=num_head
self.proj_linear_layer = nn.Linear(model_dim,3*model_dim)
self.final_linear_layer = nn.Linear(model_dim,model_dim)
def forward(self,input,additive_mask=None):
bs,seqlen,model_dim = input.shape
num_head = self.num_head
head_dim = model_dim//num_head
# proj_output=[bs,seqlen,3*model_dim]
proj_output = self.proj_linear_layer(input)
# 3*[bs,seqlen,model_dim]
q,k,v = proj_output.chunk(3,dim=-1)
q = q.reshape(bs,seqlen,num_head,head_dim).transpose(1,2)
# q=[bs,num_head,seqlen,head_dim]
q = q.reshape(bs*num_head,seqlen,head_dim)
# k=[bs,num_head,seqlen,head_dim]
k = k.reshape(bs,seqlen,num_head,head_dim).transpose(1,2)
k = k.reshape(bs*num_head,seqlen,head_dim)
v = v.reshape(bs,seqlen,num_head,head_dim).transpose(1,2)
v = v.reshape(bs*num_head,seqlen,head_dim)
if additive_mask is None:
attn_prob = F.softmax(torch.bmm(q,k.transpose(-1,-2))/math.sqrt(head_dim),dim=-1)
else:
additive_mask = additive_mask.tile(num_head,1,1)
attn_prob = F.softmax(torch.bmm(q,k.transpose(-2,-1))/math.sqrt(head_dim)+additive_mask,dim=-1)
output = torch.bmm(attn_prob,v)
output = output.reshape(bs,num_head,seqlen,head_dim).transpose(1,2)
output = output.reshape(bs,seqlen,model_dim)
return attn_prob,output
3.2 构建Window MHSA并计算其复杂度
- 将patch组成的图片进一步划分为一个个更大的window
- 首先需要将三维的patch embedding转换成图片格式
- 使用unfold来将patch划分成window
- 在每个window内部计算MHSA
- window 数目其实可以跟batchsize进行统一对待,因为window与window之间没有交互计算
- 关于计算复杂度
- 假设窗的边长为W,那么计算每个窗的总体复杂度是 4 W 2 C 2 + 2 W 4 C 4W^2C^2+2W^4C 4W2C2+2W4C
- 假设patch的总数目为L,那么窗的数据为 L / W 2 L/W^2 L/W2
- 因此,W-HMSA的总体复杂度为 4 L C 2 + 2 L W 2 C 4LC^2+2LW^2C 4LC2+2LW2C
- 此处不需要mask
- 将计算结果转换成带window的四维张量格式
- 复杂度对比:
- MHSA: 4 L C 2 + 2 L 2 C 4LC^2+2L^2C 4LC2+2L2C
- W-MHSA: 4 L C 2 + 2 L W 2 C 4LC^2+2LW^2C 4LC2+2LW2C
3.3 基于窗口的多头自注意力
# 基于windows的多头自注意力
def window_multi_head_self_attention(patch_embedding,mhsa,window_size=4,num_head=2):
# 定义有多少个patch
num_patch_in_window=window_size*window_size
# 得到相关大小参数
bs,num_patch,patch_depth = patch_embedding.shape
# 将三维拆分成四维数据,一般图片的高宽可以冲num_patch里面拆分得到
image_height =image_width = int(math.sqrt(num_patch))
#[bs,num_patch,patch_depth] -> [bs,patch_depth,num_patch]
patch_embedding = patch_embedding.transpose(-1,-2)
# [bs,patch_depth,num_patch] -> [bs,patch_depth,image_height,image_width]
patch = patch_embedding.reshape(bs,patch_depth,image_height,image_width)
# 经过卷积中的卷得到window后,再将最后一维和倒数第二维度进行切换
# window.shape=[bs,windows_depth,num_window] ->[bs,num_window,windows_depth]
window = F.unfold(patch,kernel_size=(window_size,window_size),
stride=(window_size,window_size)).transpose(-1,-2)
bs,num_window,patch_depth_times_num_patch_in_window = window.shape
window = window.reshape(bs*num_window,patch_depth,num_patch_in_window).transpose(-1,-2)
attn_prob,output = mhsa(window)
output = output.reshape(bs,num_window,num_patch_in_window,patch_depth)
return output
4. Shift window MHSA及其Mask
4.1 构建步骤如下:
- 将上一步的W-MHSA的结果转换成图片格式
- 假设已经做了新的window划分,这一步叫做shfit-window
- 为了保持window数目不变从而有高效的计算,需要将图片的patch往左和往上各自滑动半个窗口大小的步长,保持patch所属window类别不变
- 将图片patch还原成window的数据格式
- 由于shift-window后,每个window岁软形状规整,但部分window中存在原本不属于统一窗口的patch,所以需要生成mask
- 如何生成mask?
- 首先构建一个shift-window的patch所属的window类别矩阵
- 对该矩阵进行同样的往左和往上各自滑动半个窗口大小的步长的操作
- 通过unfold操作得到[bs,num_window,num_patch_in_window]形状的类别矩阵
- 对该矩阵进行扩维成[bs,num_window,num_patch_in_window,1]
- 将该矩阵与其转置矩阵进行作差,得到同类关系矩阵(为0的位置上的patch属于同类,否则属于不同类)
- 对同类关系矩阵中非零的位置用负无穷数进行填充,对于零的位置上用0去填充,这样就构建好了MHSA所需要的mask
- 此mask的形状为[bs,num_window,num_patch_in_window,num_patch_in_window]
- 将window转换成三维的格式,[bs*num_window,num_patch_in_window,patch_depth]
- 将三维格式的特征连同mask一起送入MHSA中计算得到注意力输出
- 将注意力输出转换成图片patch格式,[bs,num_window,num_patch_in_window,patch_depth]
- 为了恢复位置,需要将图片的patch往右和往下各自滑动半个窗口大小的步长,至此,SW-MHSA计算完毕

4.2 代码
def window2image(msa_output):
bs,num_window,num_patch_in_window,patch_depth=msa_output.shape
window_size=int(math.sqrt(num_patch_in_window))
image_height = int(math.sqrt(num_window))*window_size
image_width = image_height
msa_output = msa_output.reshape(bs,int(math.sqrt(num_window)),
int(math.sqrt(num_window)),
window_size,
window_size,
patch_depth)
msa_output = msa_output.transpose(2,3)
image = msa_output.reshape(bs,image_height*image_width,patch_depth)
image = image.transpose(-1,-2).reshape(bs,patch_depth,image_height,image_width)
return image
def shift_window(w_msa_output,window_size,shift_size,generate_mask=False):
bs,num_window,num_patch_in_window,patch_depth=w_msa_output.shape
w_msa_output = window2image(w_msa_output)
bs,patch_depth,image_height,image_width = w_msa_output.shape
rolled_w_msa_output = torch.roll(w_msa_output,shifts=(shift_size,shift_size),dims=(2,3))
shifted_w_msa_input = rolled_w_msa_output.reshape(bs,patch_depth,
int(math.sqrt(num_window)),
window_size,
int(math.sqrt(num_window)),
window_size)
shifted_w_msa_input = shifted_w_msa_input.transpose(3,4)
shifted_w_msa_input = shifted_w_msa_input.reshape(bs,patch_depth,num_window*num_patch_in_window)
shifted_w_msa_input = shifted_w_msa_input.transpose(-1,-2)
shifted_window = shifted_w_msa_input.reshape(bs,num_window,num_patch_in_window,patch_depth)
if generate_mask:
additive_mask = build_mask_for_shifted_wmsa(bs,image_height,image_width,window_size)
else:
additive_mask = None
return shifted_window,additive_mask
def build_mask_for_shifted_wmsa(batch_size,image_height,image_width,window_size):
index_matrix = torch.zeros(image_height,image_width)
for i in range(image_height):
for j in range(image_width):
row_times = (i+window_size//2)//window_size
col_times = (j+window_size//2)//window_size
index_matrix[i,j] = row_times*(image_height//window_size)+col_times+1
rolled_index_matrix = torch.roll(index_matrix,shifts=(-window_size//2,-window_size//2),dim=(0,1))
rolled_index_matrix = rolled_index_matrix.unsqueeze(0).unsqueeze(0)
c = F.unfold(rolled_index_matrix,kernel_size=(window_size,window_size),
stride=(window_size,window_size)).transpose(-1,-2)
c = c.tile(batch_size,1,1)
bs,num_window,num_patch_in_window = c.shape
c1 = c.unsqueeze(-1)
c2=(c1-c1.transpose(-1,-2)) == 0
valid_matrix = c2.to(torch.float32)
additive_mask = (1-valid_matrix)*(-1e-9)
additive_mask = additive_mask.reshape(bs*num_window,num_patch_in_window,num_patch_in_window)
return additive_mask
def shift_window_multi_head_self_attention(w_msa_output,mhsa,window_size=4,num_head=2):
bs,num_window,num_patch_in_window,patch_depth = w_msa_output.shape
shifted_w_msa_input,additive_mask = shift_window(w_msa_output,window_size,
shift_size=-window_size//2,
generate_mask=True)
shifted_w_msa_input = shifted_w_msa_input.reshape(bs*num_window,num_patch_in_window,patch_depth)
attn_prob,output = mhsa(shifted_w_msa_input,additive_mask=additive_mask)
output = output.reshape(bs,num_window,num_patch_in_window,patch_depth)
output,_ = shift_window(output,window_size,shift_size=window_size//2,generate_mask=False)
return output
4.3 Patch_Merging
- 将window格式的特征转换成图片patch格式
- 利用unfold操作,按照merge
class PatchMerging(nn.Module):
def __init__(self,model_dim,merge_size,output_depth_scale=0.5):
super(PatchMerging,self).__init__()
self.merge_size = merge_size
self.proj_layer= nn.Linear(
model_dim*merge_size*merge_size,
int(model_dim*merge_size*merge_size*output_depth_scale))
def forward(self,input):
bs,num_window,num_patch_in_window,patch_depth = input.shape
window_size = int(math.sqrt(num_patch_in_window))
input = window2image(input)
merged_window = F.unfold(input,kernel_size=(self.merge_size,self.merge_size),
stride=(self.merge_size,self.merge_size)).transpose(-1,-2)
merge_window = self.proj_layer(merged_window)
return merged_window
5. 构建swinTransformerBlock
- 每个block包含LayerNorm,W-MHSA,MLP,SW-MHSA,残差连接等模块
- 输入是patch_embedding格式
- 每个MLP包含两层,分别是4*model_dim和model_dim的大小
- 输出的是window的数据格式,[bs,num_window,num_patch_in_window,patch_depth]
- 需要注意残差连接对数据形状的要求
class SwinTransformerBlock(nn.Module):
def __init__(self,model_dim,window_size,num_head):
super(SwinTransformerBlock, self).__init__()
self.layer_norm1 = nn.LayerNorm(model_dim)
self.layer_norm2 = nn.LayerNorm(model_dim)
self.layer_norm3 = nn.LayerNorm(model_dim)
self.layer_norm4 = nn.LayerNorm(model_dim)
self.wsma_mlp1 = nn.Linear(model_dim,4*model_dim)
self.wsma_mlp2 = nn.Linear(4*model_dim,model_dim)
self.swsma_mlp1 = nn.Linear(model_dim,4*model_dim)
self.swsma_mlp2 = nn.Linear(4*model_dim,model_dim)
self.mhsa1 = MultiHeadSelfAttention(model_dim,num_head)
self.mhsa2 = MultiHeadSelfAttention(model_dim,num_head)
def forward(self,input):
bs,num_patch,patch_depth = input.shape
input1 = self.layer_norm1(input)
w_msa_output = window_multi_head_self_attention(input,self.mhsa1,window_size=4,num_head=2)
bs,num_window,num_patch_in_window,patch_depth = w_msa_output.shape
w_msa_output=input+w_msa_output.reshape(bs,num_patch,patch_depth)
output1 = self.wsma_mlp2(self.wsma_mlp1(self.layer_norm2(w_msa_output)))
output1 = w_msa_output
input2 = self.layer_norm3(output1)
input2 = input2.reshape(bs,num_window,num_patch_in_window,patch_depth)
sw_msa_output = shift_window_multi_head_self_attention(input2,self.mhsa2,window_size=4,num_head=2)
sw_msa_output=output1+sw_msa_output.reshape(bs,num_patch,patch_depth)
output2 = self.swsma_mlp2(self.swsma_mlp1(self.layer_norm4(sw_msa_output)))
output2 +=sw_msa_output
output2 = output2.reshape(bs,num_window,num_patch_in_window,patch_depth)
return output2
6. 构建Swin-Transformer-Model
- 输入是图片
- 首先对图片进行分块并得到Patch-Embedding
- 经过第一个stage
- 进行patch-merging,再进行第二个stage
- 以此类推
- 对最后一个block的输出转换成patch-embedding的格式,[bs,num_patch,patch_depth]
- 对patch_embedding在时间维度进行平均池化,并映射到分类层得到分类的logits,完毕
class SwinTransformerModel(nn.Module):
def __init__(self,input_image_channel=1,patch_size=4,model_dim_C=8,num_classes=10,
window_size=4,num_head=2,merge_size=2):
super(SwinTransformerModel, self).__init__()
patch_depth = patch_size*patch_size*input_image_channel
self.patch_size = patch_size
self.model_dim_C=model_dim_C
self.num_classes = num_classes
self.patch_embedding_weight = nn.Parameter(torch.randn(patch_depth,model_dim_C))
self.block1 = SwinTransformerBlock(model_dim_C,window_size,num_head)
self.block2 = SwinTransformerBlock(model_dim_C*2,window_size,num_head)
self.block3 = SwinTransformerBlock(model_dim_C*4,window_size,num_head)
self.block4 = SwinTransformerBlock(model_dim_C*8,window_size,num_head)
self.patch_merging1 = PatchMerging(model_dim_C,merge_size)
self.patch_merging2 = PatchMerging(model_dim_C*2,merge_size)
self.patch_merging3 = PatchMerging(model_dim_C*4,merge_size)
self.final_layer = nn.Linear(model_dim_C*8,num_classes)
def forward(self,image):
patch_embedding_naive = image2embed_naive(image,self.patch_size,self.patch_embedding_weight)
# block1
patch_embedding = patch_embedding_naive
print(patch_embedding.shape)
sw_msa_output = self.block1(patch_embedding)
print("block1_output",sw_msa_output.shape)
merged_patch1=self.patch_merging1(sw_msa_output)
sw_msa_output1 = self.block2(merged_patch1)
print("block2_output",sw_msa_output1.shape)
merged_patch2 = self.patch_merging2(sw_msa_output1)
sw_msa_output2 = self.block3(merged_patch2)
print("block3_output",sw_msa_output2.shape)
merged_patch3 = self.patch_merging3(sw_msa_output2)
sw_msa_output3=self.block4(merged_patch3)
print("block4_output",sw_msa_output3.shape)
bs,num_window,num_patch_in_window,patch_depth = sw_msa_output3.shape
sw_msa_output3=sw_msa_output3.reshape(bs,-1,patch_depth)
pool_output = torch.mean(sw_msa_output3,dim=1)
logits = self.final_layer(pool_output)
print("logits",logits.shape)
return logits