利用PermutationImportance挑选变量
我们在构建树类模型(XGBoost、LightGBM等)时,如果想要知道哪些变量比较重要的话。可以通过模型的feature_importances_方法来获取特征重要性。例如LightGBM的feature_importances_可以通过特征的分裂次数或利用该特征分裂后的增益来衡量。一般情况下,不同的衡量准则得到的特征重要性顺序会有差异。我一般是通过多种评价标准来交叉选择特征。博主认为,若一个特征在不同的评价标准下都是比较重要的,那么该特征对label有较好的预测能力。
为大家介绍一种评价特征重要性的方法:PermutationImportance。文档对该方法介绍如下:eli5 provides a way to compute feature importances for any black-box estimator by measuring how score decreases when a feature is not available; the method is also known as “permutation importance” or “Mean Decrease Accuracy (MDA)”.我的理解是:若将一个特征置为随机数,模型效果下降很多,说明该特征比较重要;反之则不是。
下面为大家举一个简单的例子,我们利用不同模型来挑选变量(RF、LightGBM、LR)。并挑选出来重要性排在前30的变量(总变量200+)进行建模。
import eli5
from eli5.sklearn import PermutationImportance
from sklearn.feature_selection import SelectFromModel
def PermutationImportance_(clf,X_train,y_train,X_valid,X_test):
perm = PermutationImportance(clf, n_iter=5, random_state=1024, cv=5)
perm.fit(X_train, y_train)
result_ = {'var':X_train.columns.values
,'feature_importances_':perm.feature_importances_
,'feature_importances_std_':perm.feature_importances_std_}
feature_importances_ = pd.DataFrame(result_, columns=['var','feature_importances_','feature_importances_std_'])
feature_importances_ = feature_importances_.sort_values('feature_importances_',ascending=False)
#eli5.show_weights(perm, feature_names=X_train.columns.tolist(), top=500) #结果可视化
sel = SelectFromModel(perm, threshold=0.00, prefit=True)
X_train_ = sel.transform(X_train)
X_valid_ = sel.transform(X_valid)
X_test_ = sel.transform(X_test)
return feature_importances_,X_train_,X_valid_,X_test
#PermutationImportance
model_1 = RandomForestClassifier(random_state=1024)
feature_importances_1,X_train_1,X_valid_1,X_test_1 = PermutationImportance_(model_1,X_train,y_train,X_valid,X_test)
model_2 = lgb.LGBMClassifier(objective='binary',random_state=1024)
feature_importances_2,X_train_2,X_valid_2,X_test_2 = PermutationImportance_(model_2,X_train,y_train,X_valid,X_test)
model_3 = LogisticRegression(random_state=1024)
feature_importances_3,X_train_3,X_valid_3,X_test_3 = PermutationImportance_(model_3,X_train,y_train,X_valid,X_test
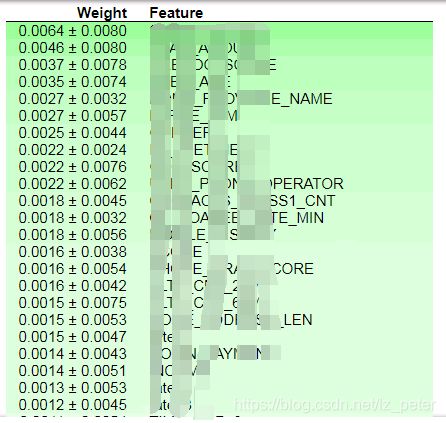
下图建模特征分别为:全部特征、RF前30特征、LightGBM前30特征、LR前30特征。可以看到LightGBM通过PermutationImportance选出来的30个特征的模型的泛化性要好于用全部变量建模。
train auc: 0.737572501101 valid auc: 0.707917079532 test auc: 0.698453842775
train auc: 0.728547026706 valid auc: 0.694552089056 test auc: 0.674431794411
train auc: 0.737740963444 valid auc: 0.711832783676 test auc: 0.702665571919
train auc: 0.721754352344 valid auc: 0.694629157213 test auc: 0.679796146766官方文档:
https://eli5.readthedocs.io/en/latest/blackbox/permutation_importance.html